大模型笔记02--基于fastgpt和oneapi构建大模型应用平台
大模型笔记02--基于fastgpt和oneapi构建大模型应用平台
- 介绍
- 部署&测试
- 部署fastgpt+oneapi服务
- 部署向量模型m3e和nomic-embed-text
- 测试大模型
- 注意事项
- 说明
介绍
随着大模型的快速发展,众多IT科技厂商都开发训练了各自的大模型,并提供了各具特色的AI产品。早期比较常见的做法是提供聊天机器人,如今逐步发展为各类AI智能体,用户可以在平台上选择自己需要能力构建特有的智能体。例如语聚AI,智谱清言,Fastgpt, coze, dify 等平台,它们都具备了较强的智能体定制能力。
如果想快速体验可以直接在平台上注册账号,按需使用即可。若想为自己的团队或者公司提供智能体,那么就可以基于开源产品搭建相关平台,或者二开。
本文基于开源的FastGPT, Ollama, Oneapi搭建一个基于LLM大语言模型的知识库问答平台, 实现知识管理和检索能力。
部署&测试
前提条件需要部署ollama,具体步骤可以参考文档 大模型笔记01–基于ollama和open-webui快速部署chatgpt。
其次需要部署FastGPT和Oneapi, 它们的主要用途如下:
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
Oneapi一个开源的OpenAI 接口管理 & 分发系统,它支持 Azure,Anthropic Claude,Google PaLM 2 & Gemini, Ollama、智谱 ChatGLM、百度文心一言、讯飞星火认知、阿里通义千问、360 智脑以及腾讯混元等大模型,可用于二次分发管理 key.
部署fastgpt+oneapi服务
fastgpt提供了基于docker compose的快速部署方式,此处直接使用docker compose来部署:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
docker compose up -d
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-zilliz.yml
服务正常拉起来后,可以通过docker compose ps 开到如下6个运行的容器:

通过 http://127.0.0.1:3000 访问fastgpt, 默认账号/密码: root / 1234

通过 http://127.0.0.1:3001/ 访问oneapi, 默认账号/密码: root / 123456

在oneapi中按需配置ollama渠道,使用Ollama自己部署模型的时候秘钥可以随意写,使用其它大模型厂商的话要按需填写提供的秘钥

渠道添加完成后记得测试一下,确保可以正常访问ollama

在fastgpt的confg.json中加上对应的模型,按需更改model和name字段,然后重启fastgpt服务即可
vim config.json
"llmModels": [
{
"model": "gemma2:9b", // 模型名(对应OneAPI中渠道的模型名)
"name": "ollama-gemma2-9b", // 模型别名
"avatar": "/imgs/model/openai.svg", // 模型的logo
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为知识库处理模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。目前只有gpt支持)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "qwen2:7b", // 模型名(对应OneAPI中渠道的模型名)
"name": "ollama-qwen2-7b", // 模型别名
......
"defaultConfig": {} // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
},
{
"model": "llama3.1:8b", // 模型名(对应OneAPI中渠道的模型名)
"name": "ollama-llama3.1-8b", // 模型别名
......
}
docker restart fastgpt

部署向量模型m3e和nomic-embed-text
可以通过docker的形式部署m3e, 也可以通过ollama的形式部署
docker:
docker run -d --net=host --name m3e -p 6008:6008 --gpus all -e sk-key=111111admin registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
测试方法
$ curl --location --request POST 'http://0.0.0.0:6008/v1/embeddings' \
--header 'Authorization: Bearer 111111admin' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "m3e",
"input": ["laf是什么"]
}'
ollama:
ollama pull nomic-embed-text:v1.5
ollama pull milkey/m3e:large-f16
测试方法
curl http://localhost:11434/api/embeddings -d '{
"model": "nomic-embed-text:v1.5",
"prompt": "The sky is blue because of Rayleigh scattering"
}'
m3e-large-api测试输出:

nomic-embed-text:v1.5 测试输出:

测试成功后在oneapi中配置上述向量模型。
若使用m3e,其代理填写 http://192.xx.xx.1:6008(按需填写实际m3e服务的ip和端口),秘钥填写上述sk-key对应的内容;
若通过ollama访问向量模型,其代理需要配置为 http://192.x.x.1:11435(前面ip根据实际填写即可,此处使用代理的端口11435),ollama默认使用/api/embeddings提供向量访问,因此我们需要使用代理将/v1/embeddings转发到该接口,具体配置见 注意事项->问题4中的 /etc/nginx/conf.d/ollama.conf ;
配置完成后需要测试可用性, 然后在 config.json 中加上自己的向量模型,具体配置如下:
vim config.json
"vectorModels": [
{
"model": "nomic-embed-text:v1.5", // 模型名(与OneAPI对应)
"name": "nomic-embed-text-v1.5", // 模型展示名
"avatar": "/imgs/model/openai.svg", // logo
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 500, // 默认文本分割时候的 token
"maxToken": 2000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
},
{
"model": "text-embedding-3-small",
"name": "text-embedding-3-small",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100
},
{
"model": "m3e",
"name": "m3e",
"avatar": "/imgs/model/openai.svg",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100
}
]
测试大模型
- 新建数据集
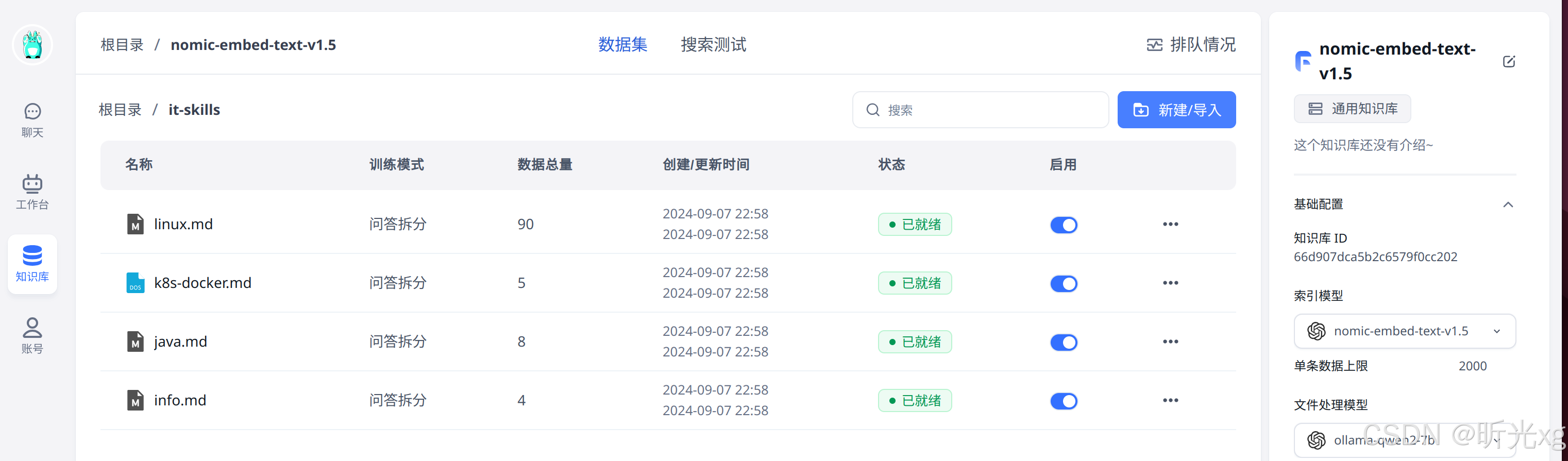
如下图,我们直接新建数据集 nomic-embed-text-v1.5 ,使用nomic-embed-text:v1.5 和 qwen2:7b 两个模型。

在skills目录提前准备好的文档,并按照步骤导入,数据导入到Ready需要大模型发一些时间处理(GPU一般的话就比较慢,笔者P2200 5G显存就有点慢),耐心等待处理完成即可

- 新建大模型应用
参考官方文档在工作台新建一个大模型应用,此处新建agent-qwen2-7b,使用qwen2-7b大模型,关联上知识库 nomic-embed-text-v1.5(搜索模式使用混合检索), 配置完成后测试一下结果,可以发现它有从5个目标参考文档中检索知识,结合检索的目标知识回答我们的问题。

测试完成,点击发布,发布成功后可以直接通过聊天界面进入到agent-qwen2-7b应用了,如下图:

至此,一个具备知识库能力的智能体应用已经完成了; 若需要让其更加智能,我们可以按需补充合适的文档和提示词,让其按照我们的方式检索、回答问题。
注意事项
-
ollama需要配置 OLLAMA_HOST=0.0.0.0 , 否则oneapi容器无法正常访问ollama服务。
-
配置渠道的时候最好每个渠道配置唯一的一个模型,这样使用的时候容易区分。
-
新增知识库导入数据时候报错"当前分组 default 下对于模型 text-embedding-ada-002 无可用渠道"

如果有openai的token的话可以在oneapi配置text-embedding-ada-002这个渠道,没有的话自行部署向量模型,并在oneapi新建对应的渠道,新建知识库的时使用自己新建的渠道即可。
当前分组 default 下对于模型 text-embedding-ada-002 无可用渠道 -
在使用知识库的时候,发现数据一直处于索引中,机器CPU长期处于高负荷状态

发现fastgpt报错503, upstream_error, 如下图所示:

oneapi报错:

因为 ollama向量接口为 /api/embeddings, 而fastgpt调用onepai默认接口为/v1/embeddings, 因此会报错,此时可以在本地通过nginx代理ollama,将oneapi的/v1/embeddings转发到ollama的 /api/embeddings中。
代理配置如下:vim /etc/nginx/conf.d/ollama.conf server { listen 11435; server_name ollama-server; location / { proxy_pass http://127.0.0.1:11434; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location /v1/embeddings { rewrite ^/v1/embeddings$ /api/embeddings break; } location /api/embeddings { proxy_pass http://127.0.0.1:11434; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } }转发成功后可以看到nginx日志请求正常:

oneapi中/v1/embeddings接口也恢复正常:

过一段时间后数据集准备就绪,节点CPU慢慢降下来恢复正常
ollama向量模型知识库上传数据一直卡在索引,docker日志报404 中提到配置host.docker.internal, 笔者测试过几次不行,最后通过nginx代理解决该问题。 -
fastgpt 通过oneapi调用ollama qwen2:2b报错 error unmarshalling stream response
fastgpt提示: LLM api response empty oneapi报错: [SYS] 2024/09/08 - 11:18:57 | error unmarshalling stream response: invalid character '}' after top-level value 解决方法: 将渠道设置为自定义,暂时不用配置为ollama, 调整后重启oneapi就没有继续报错了 参考 [ollama部署qwen2:7b api调用报错](https://github.com/songquanpeng/one-api/issues/1646)
说明
软件:
ubuntu2404 Desktop
oneapi v0.6.8
fastgpt v4.8.10
ollama 0.3.6
参考文档:
fastgpt官方文档
one-api github
ollama + fastgpt搭建本地私有AI大模型智能体工作流(AI Agent Flow)-- windows环境
Fastgpt配合chatglm+m3e或ollama+m3e搭建个人知识库
大模型必备 - 中文最佳向量模型 acge_text_embedding
Ollama 中文文档
奔跑的蜗牛-人工智能案例合集