【预训练语言模型】BERT原理解析、常见问题
一、BERT原理
1、概述
背景:通过在大规模语料上预训练语言模型,可以显著提高其在NLP下游任务的表现。
动机:限制模型潜力的主要原因在于现有模型使用的都是单向的语言模型(例如GPT),无法充分了解到单词所在的上下文结构(主要是在判别性任务上,分类、抽取等)。
Idea: 受完形填空的启发,BERT通过使用 Masked Language Model(MLM) 的预训练目标来缓解单向语言模型的约束。
实现:引入Masked Language Model + Next sentence prediction 两个预训练任务
1) Masked Language Model任务会随机屏蔽(masked)15%的token,然后让模型根据上下文来预测被Mask的token(被Mask的变成了标签)。
最后,将masked token 位置输出的最终隐层向量送入softmax,来预测masked token。
2) Next sentence prediction任务预训练针对文本对,预测句子间的关系(从 token-level 提升到 sentence-level,以应用不同种类的下游任务)。
如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

2、BERT模型
BERT:分为pre-training 和 fine-tuning,两个阶段。
- pre-training 阶段,BERT 在无标记的数据上进行无监督学习;
- fine-tuning 阶段,BERT利用预训练的参数初始化模型,并利用下游任务标记好的数据进行有监督学习,并对所有参数进行微调。
所有下游任务都有单独的 fine-tuning 模型,即使是使用同样的预训练参数。
下图是对 BERT 的一个概览:
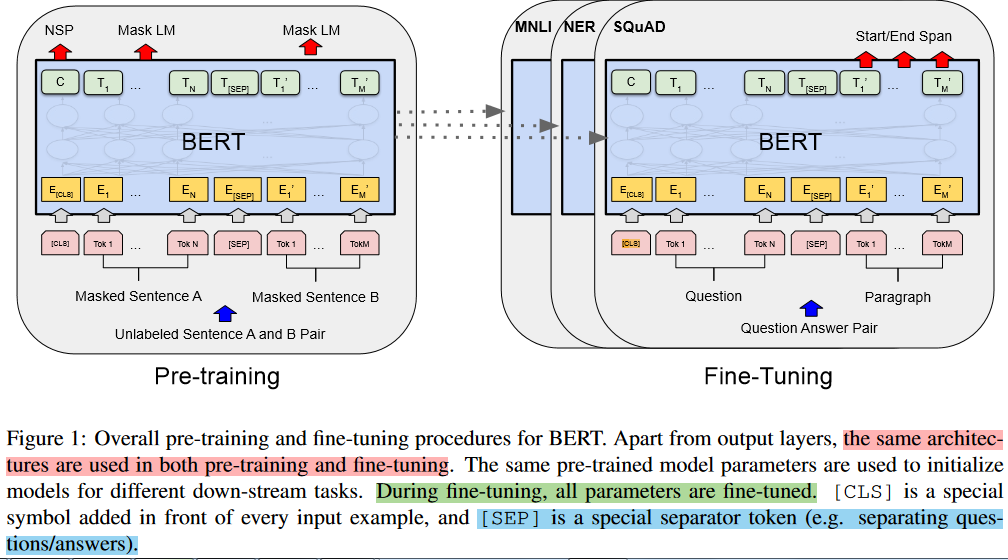
2.1、模型架构
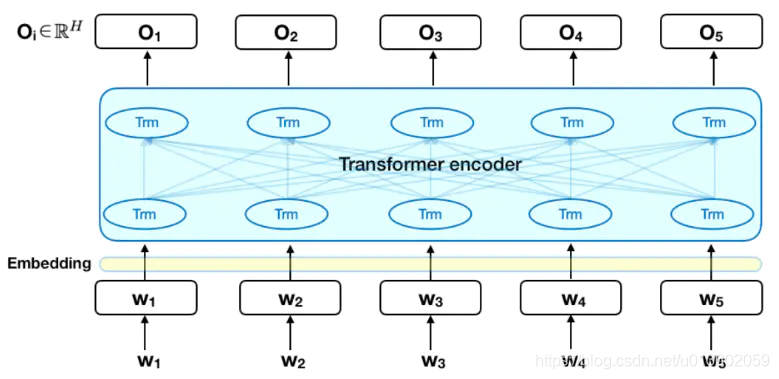
BERT 是由多层双向的 Transformer Encoder 结构组成,区别于 GPT 的单向的 Transformer Decoder (自回归)架构。
2.2、输入
为了能应对下游任务,BERT 给出了 sentence-level 级别的 Representation,包括句子和句子对。在 BERT 中 sequence 并不一定是一个句子,也有可能是任意的一段连续的文本;而句子对主要是因为类似 QA 问题。
BERT 的输入:
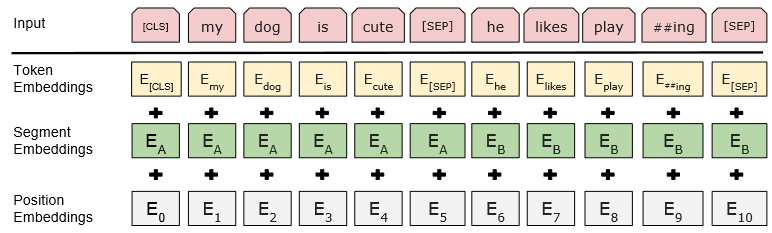
分为三块:Token Embeddings、Segment Embeddings 和 Position Embeddings
- Token Embeddings 采用的 WordPiece Tokenizer进行分词,词表数量为30000。每个 sequence 会以一个特殊的 classification token [CLS] 开始,同时这也会作为分类任务的输出;句子间会以 special seperator token [SEP] 进行分割。
- Segment Embedding也可以用来分割句子,但主要用来区分句子对。Embedding A 和 Embedding B 分别代表左右句子,如果是普通的句子就直接用 Embedding A。
- Position Embedding 是用来给词元Token定位的,学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
BERT 最终的 input 是三种不同的 Embedding 直接相加。
WordPiece Tokenizer分词器:采用 BPE 双字节编码,在单词进行拆分,比如 “loved” “loving” ”loves“ 会拆分成 “lov”,“ed”,“ing”,“es”。
2.3、预训练Pre-training
BERT 采用两种无监督任务来进行预训练,两个任务同时训练,所以 BERT 的损失函数是两个任务的损失函数相加:
1) token-level 级别的 Masked LM;
2) sentence-level 级别的 Next Sentence Prediction。
2.3.1、任务一:Masked LM
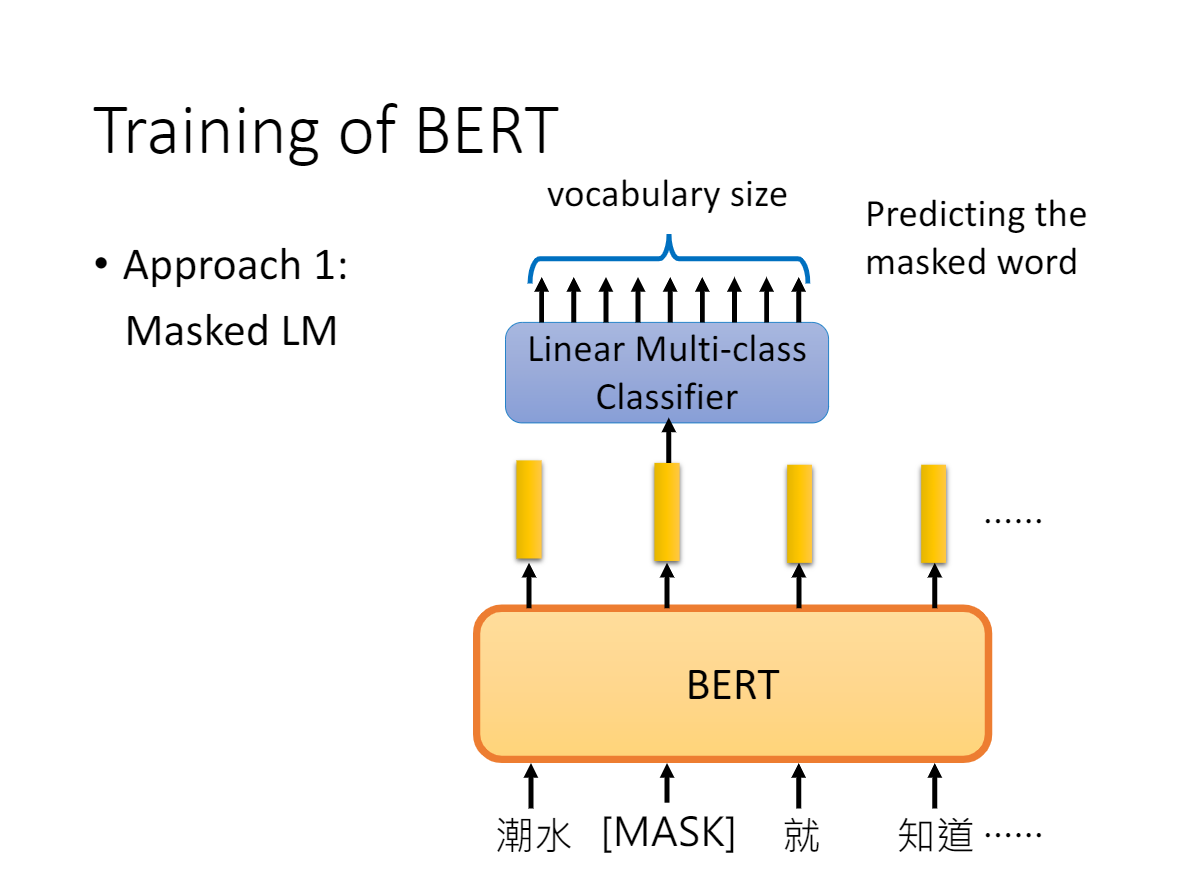
为解决双向模型的数据泄漏的问题,Masked LM:随机屏蔽一些token 并通过上下文预测这些 token。
在实验中,BERT 会随机屏蔽每个序列中的 15% 的 token,并用 [MASK] token 来代替。这会带来一个问题:[MASK] token 不会出现在下游任务中。
为了和后续任务保持一致,采用以下三种方式来代替 [MASK] token:如:my dog is hairy
- 80% 的 [MASK] token 会继续保持 [MASK];—my dog is [MASK]
- 10% 的 [MASK] token 会被随机的一个单词取代;my dog is apple
- 10% 的 [MASK] token 会保持原单词不变(但是还是要预测)my dog is hairy
最终 Masked ML 的损失函数是只由被 [MASK] 的部分来计算:
-
在 encoder 的输出上添加一个前馈神经网络,将其转换为词汇的维度
-
softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值(所以对训练语料的利用率实际并不如GPT)。
2.3.2、任务二:Next Sentence Prediction
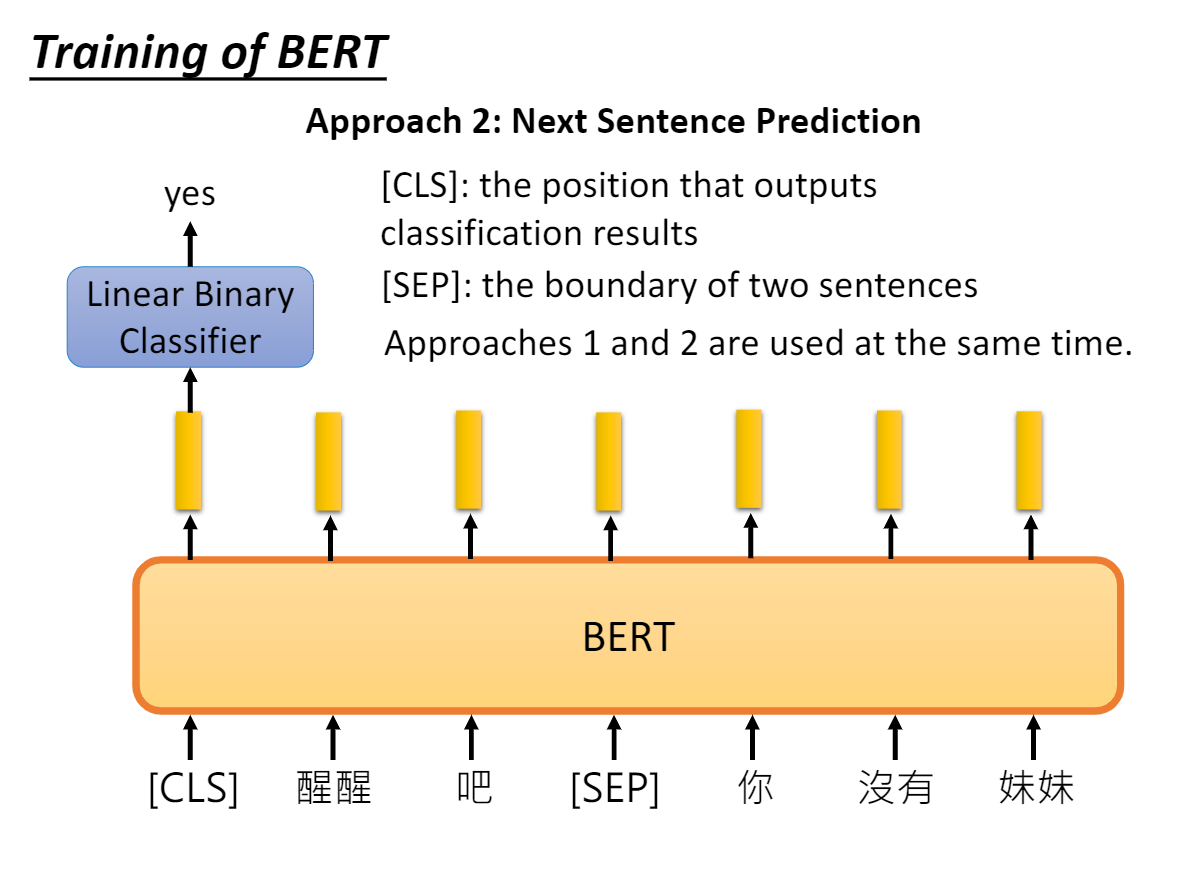
由于语言模型只能捕捉 token-level 级别的关系,为了捕捉 sentence-level 级别的关系,训练了一个 sentence-level 的分类任务。
具体来说,训练的输入是句子A和B (句子级负采样):
- B有一半的几率是A的下一句,即正例;
- B有一半的几率是随机取一个句子作为负例。
通过 classification token 连接 Softmax 输出B是不是A的下一句。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。Segemet Embeding来表示不同的句子。
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
2.4、微调Fine-tuning
由于BERT的预训练已经完成了句子和句子对的 Representation,所以它的 Fine-tuning 非常简单。
针对不同的NLP下游任务,只需在BERT输出后添加其他模块(如线性层、CNN、CRF等),并将具体的输入和输出输入 BERT 中,并端到端地微调模型参数即可。
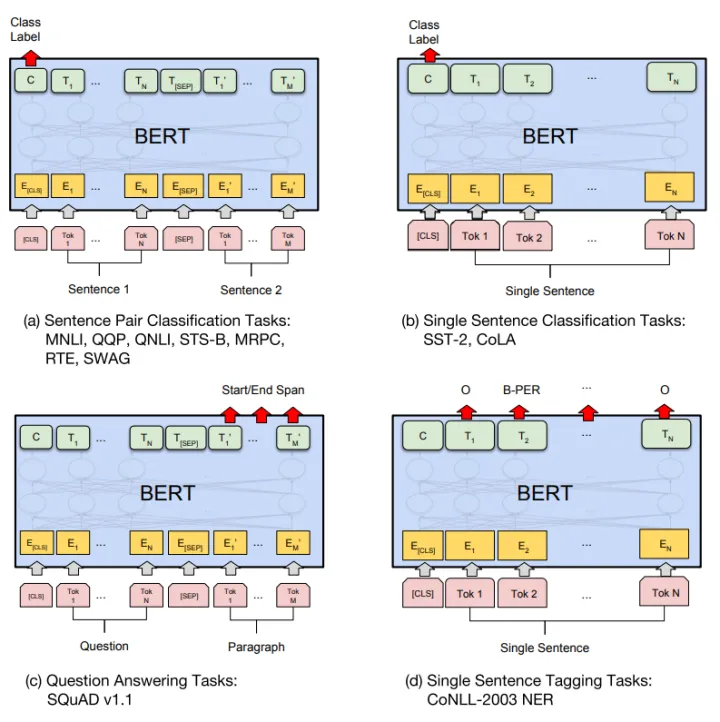
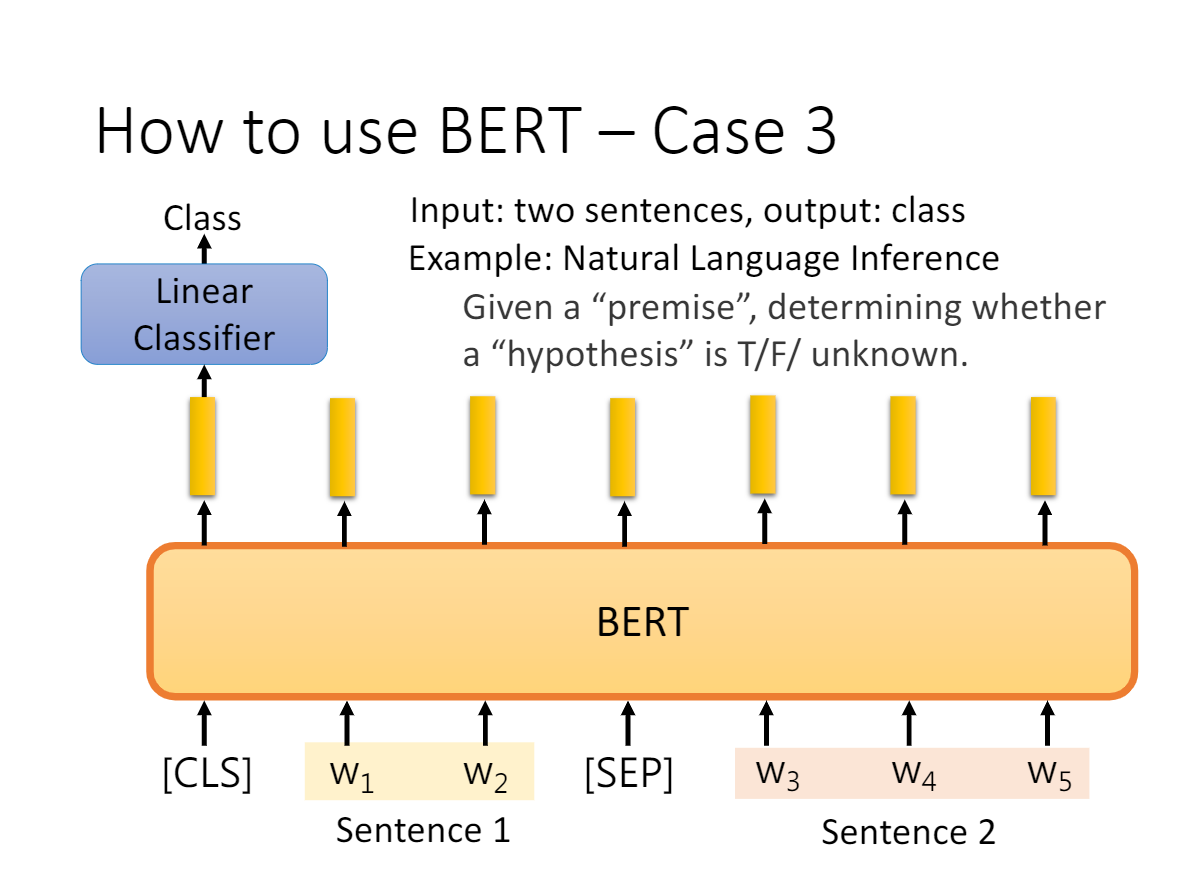
- a、b 是 sentence-level 级别的任务,类似句子分类,情感分析等等,输入句子或句子对,在 [CLS] 位置接入 Softmax 输出 Label;
- c是token-level级别的任务,比如 QA 问题,输入问题和段落,在 Paragraph 对应输出的 hidden vector 后接上两个 Softmax 层,分别训练出 Span 的 Start index 和 End index(连续的 Span)作为 Question 的答案;
- d也是token-level级别的任务,比如命名实体识别问题,接上 Softmax 层即可输出具体的分类。
例如:
在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
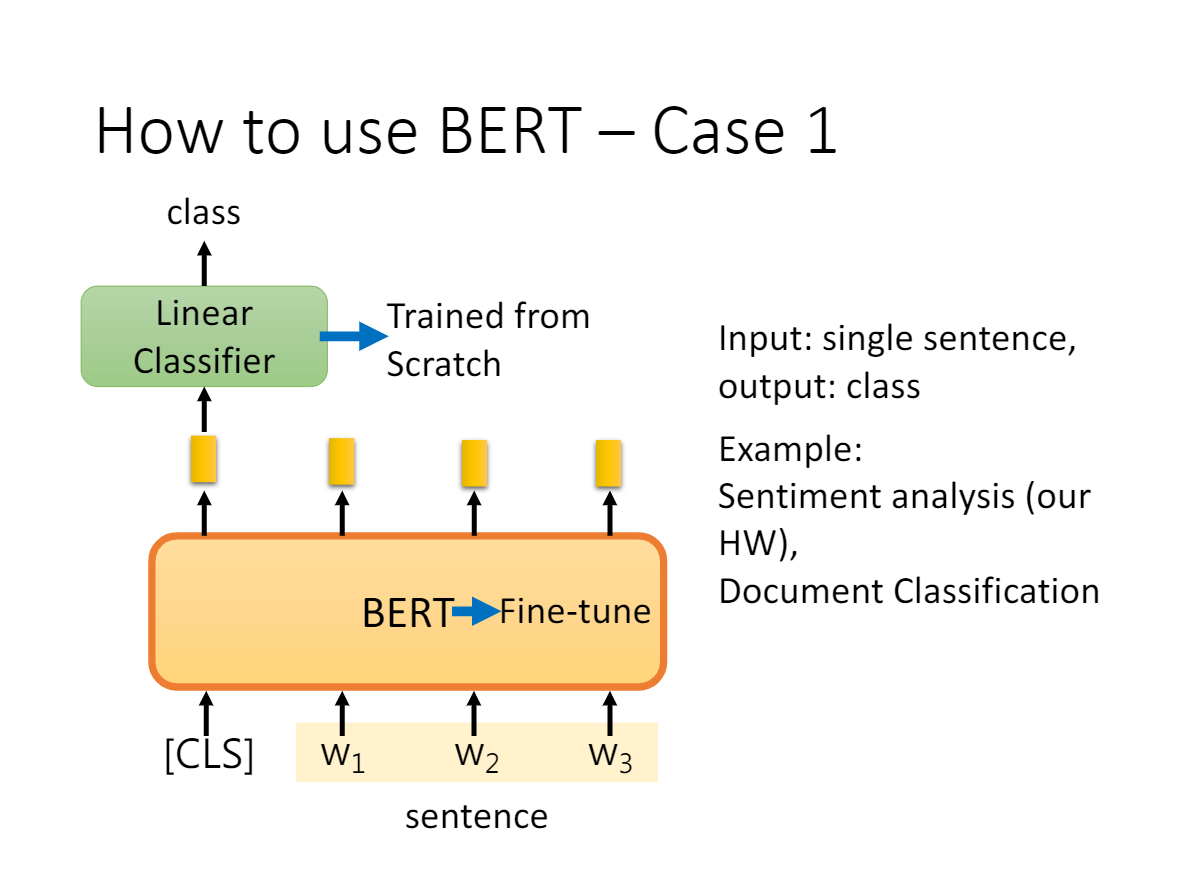
在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
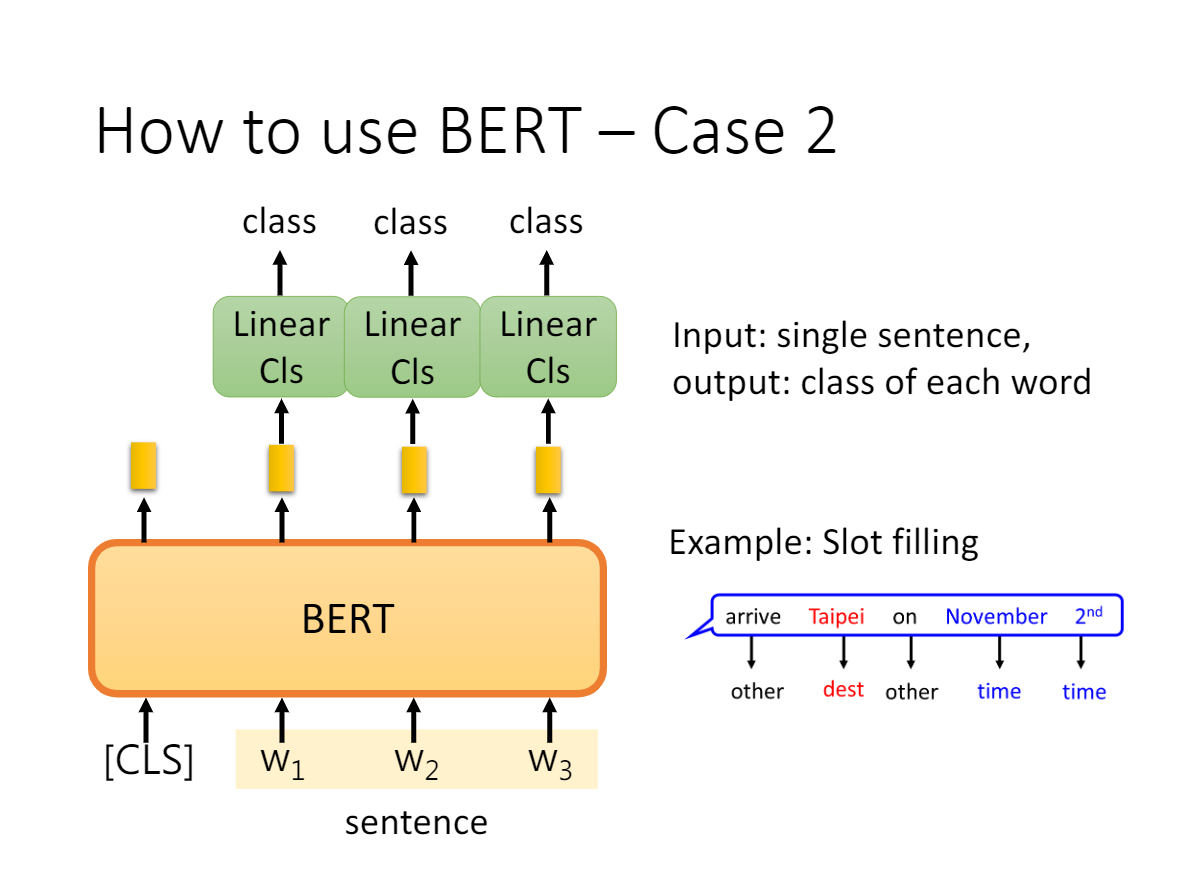
在句子关系蕴含(自然语言推断任务)或相似匹配任务中,构造输入sentence1和sentence1,以及lable即可。
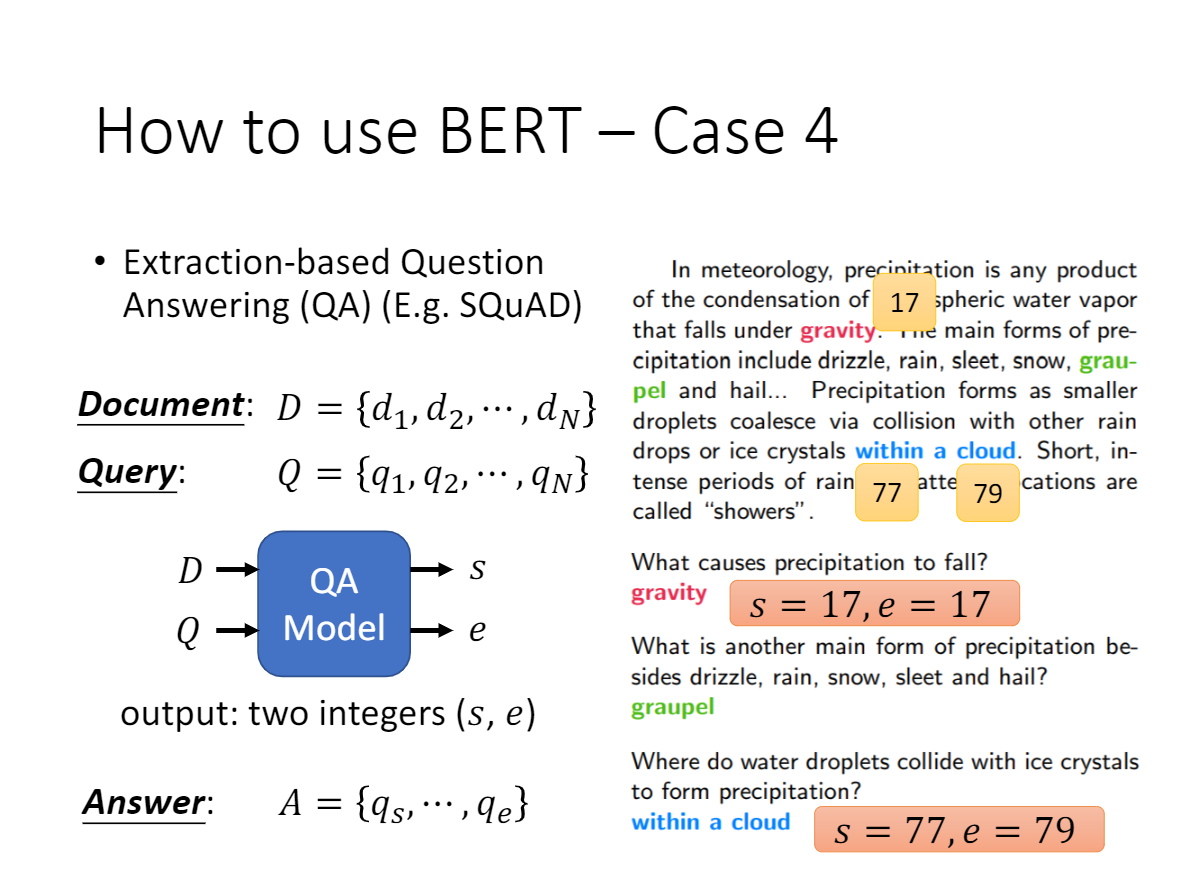
在QA任务中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。
可以使用 BERT 学习两个标记 answer 开始和结尾的向量(指针网络,预测span)来训练Q&A模型。
3. 结论
BERT采用Pre-training和Fine-tuning两阶段训练任务(源于GPT):
1)在Pre-training阶段使用多层双向Transformer Encoder进行训练,并采用Masked LM 和 Next Sentence Prediction两种训练任务解决 token-level 和 sentence-level 的问题,为下游任务提供了一个通用的模型框架;
2)在 Fine-tuning 阶段会针对具体 NLP 任务进行微调以适应不同种类的任务需求,并通过端到端的训练更新参数从而得到最终的模型。
BERT优点:
- BERT的Transformer Encoder的Self-Attention结构能较好地建模上下文,而且在经过在语料上预训练后,能获取到输入文本较优质的语义表征。
- BERT的MLP和NSP联合训练,让其能适配下游多任务(Token级别和句子级别)的迁移学习
BERT缺点:
- [MASK] token在推理时不会出现,因此训练时用过多的[MASK]会影响模型表现(需要让下游任务去适配预训练语言模型,而不是让预训练语言模型主动针对下游任务做优化)
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(BERT对语料的利用低。而GPT对语料的利用率更高,它几乎能利用句子的每个token);
- BERT的上下文长度固定为512,输入过长需要阶段(对长文本不友好)
二、BERT答疑
1、三个Embedding怎么来的
在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的,pytorch代码中它们是这样的:
self.word_embeddings = Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = Embedding(config.type_vocab_size, config.hidden_size)
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。
那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
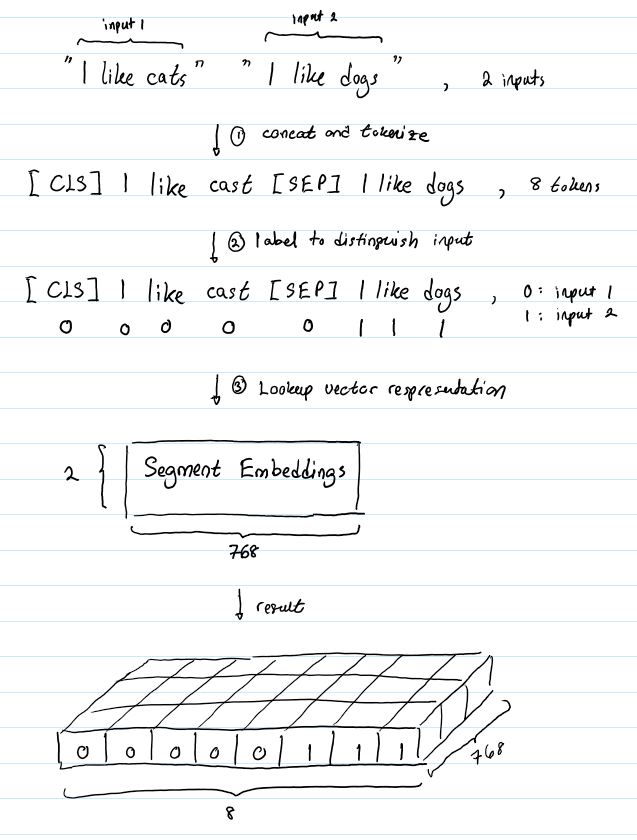
https://www.cnblogs.com/d0main/p/10447853.html#token-embeddings
1 from transformers import AutoTokenizer
2
3 checkpoint = “bert-base-uncased”
4 tokenizer = AutoTokenizer.from_pretrained(checkpoint)
5 tokenized_sentences_1 = tokenizer(raw_datasets["train"]["sentence1"])
6 tokenized_sentences_2 ``=` `tokenizer(raw_datasets["train"]["sentence2"])
7 nputs ``=` `tokenizer("This is the first sentence.", "This is the second one.")
8
9 inputs
结果:input_ids为token ids, token_type_ids用于区分两个toke序列(对应segment embeddings)
{'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012,102, 2023, 2003, 1996, 2117, 2028, 1012, 102], <br>``'token_type_ids'``: [``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``0``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``], <br>``'attention_mask'``: [``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``, ``1``]<br>}
反tokenize
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
结果
1 ['[CLS]',
2 'this',
3 'is',
4 'the',
5 'first',
6 'sentence',
7 '.',
8 '[SEP]',
9 'this',
10 'is',
11 'the',
12 'second',
13 'one',
14 '.',
15 '[SEP]']
2、不考虑多头的原因,self-attention中词向量不乘QKV参数矩阵,会有什么问题?
Self-Attention的核心是用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。
self-attention中,sequence中的每个词都会和sequence中的每个词做点积去计算相似度,也包括这个词本身。
3、为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
BERT采用的Masked LM,会选取语料中所有词的15%进行随机mask。论文表示受到完形填空任务的启发,但与CBOW也有异曲同工之妙。 从CBOW的角度,有一个比较好的解释是:在一个大小为w的窗口中随机选一个词,类似CBOW中滑动窗口的中心词,区别是这里的滑动窗口是非重叠的。 从CBOW的滑动窗口角度,10%~20%都是还ok的比例。
4、为什么BERT在第一句前会加一个[CLS]标志?
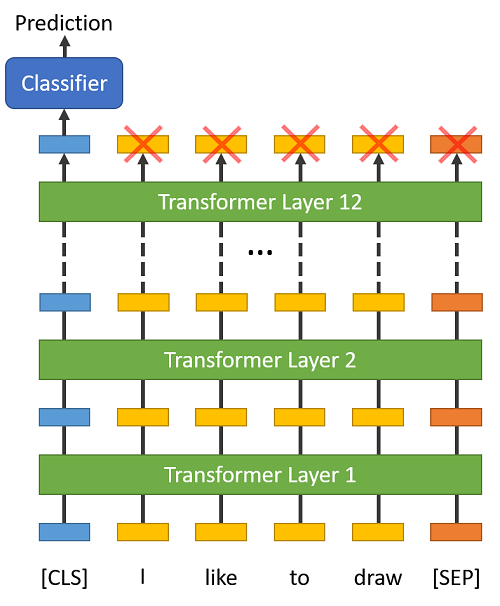
BERT在第一句前会加一个CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义
5、Self-Attention 的时间复杂度是怎么计算的?
O(n^2 d) 相加的
6、Transformer在哪里做了权重共享,为什么可以做权重共享?
Transformer在两个地方进行了权重共享:
(1)Encoder和Decoder间的Embedding层权重共享;
(2)Decoder中Embedding层和FC层权重共享。
解码的词,要有embedding,同时也可作为分类器权重。,Embedding层可以说是通过onehot去取到对应的embedding向量,FC层可以说是相反的,通过向量(定义为 x)去得到它可能是某个词的softmax概率,取概率最大。
FC层的每一行量级相同的前提下,理论上和 x 相同的那一行对应的点积和softmax概率会是最大的(内积)。 通过这样的权重共享可以减少参数的数量,加快收敛。
7、BERT非线性的来源在哪里?
FFN的gelu激活函数, Self-Attention的多头融合, 多层Transformer Encoder堆叠
8. BERT参数量
https://blog.csdn.net/weixin_43922901/article/details/102602557
Bert采用的vocab_size=30522,hidden_size=768,max_position_embeddings=512
LN参数,gamma和beta的维度均为768。因此总参数为768 * 2 + 768 * 2 * 2 * 12(层数)
模型参数Bert模型的版本如下:
- BERT-BASE-Uncase (L=12, H=768, A=12, Total Parameters=110M)
- BERT-LARGE-Uncase (L=24, H=1024, A=16, Total Parameters=340M)
L指TransformerEncoder层数,即LayerNum, H指自注意力的表示维度,即HeadDim, A指注意力的头数
三、BERT调包和微调
BERT有两个约束条件。
- \1. 所有的句子必须被填充或截断成一个固定的长度。
- \2. 最大的句子长度是512个tokens。
填充是通过一个特殊的"[PAD]"token来完成的,它在BERT词汇表中的索引0。下面的插图演示了填充到8个token的 “MAX_LEN”。
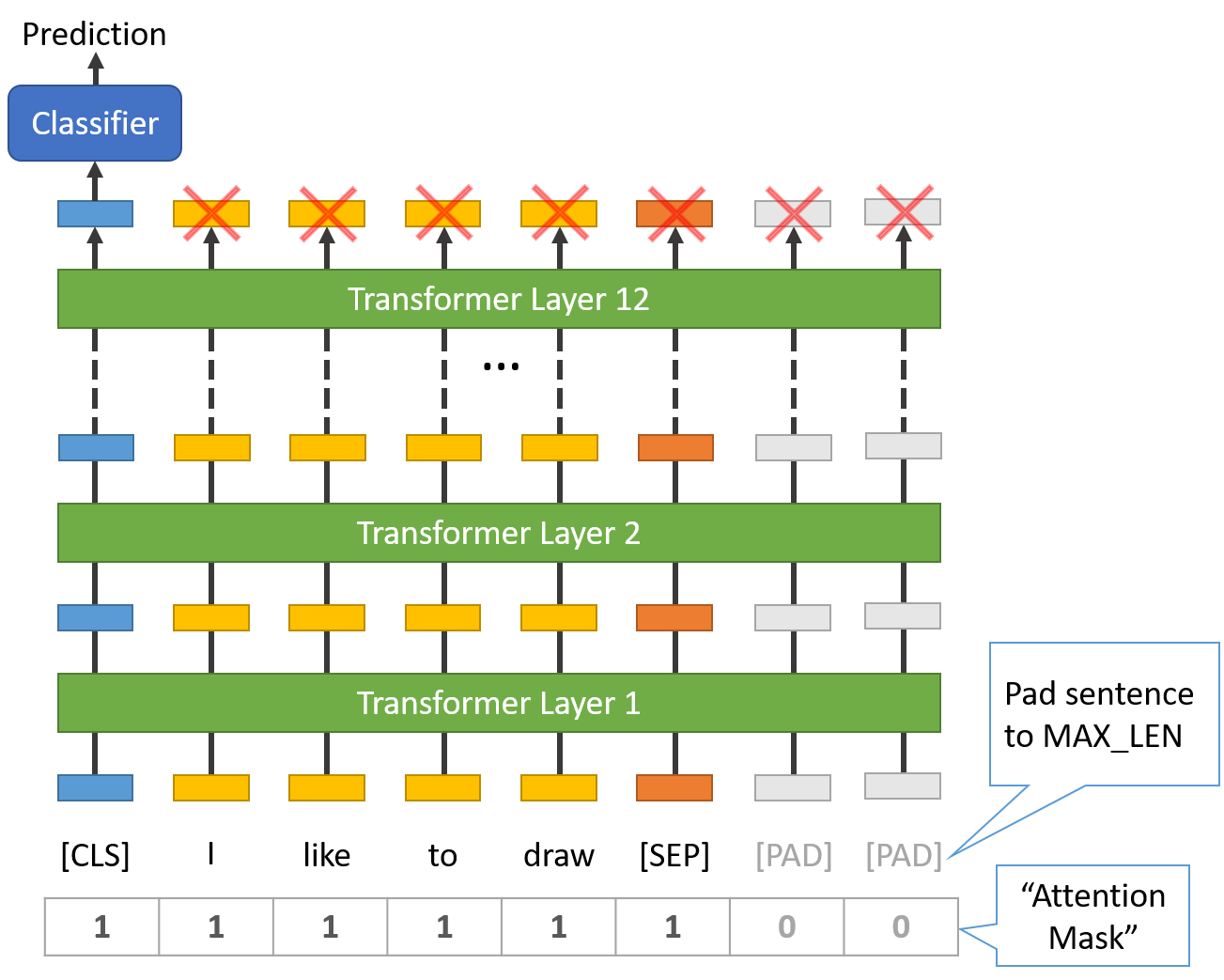
"注意力遮盖"只是一个1和0的数组,表示哪些标记是padding,哪些不是。
这个掩码告诉BERT中的"自我关注"机制,不要将这些pad标记纳入它对句子的解释中。
(还有点类似Decoder,不过这是为了对其句子用,而不是为了自回归)
不过,最大长度确实会影响训练和评估速度。例如,用特斯拉K80。
MAX_LEN = 128 --> 训练一个 epoch 需要 5:28
MAX_LEN = 64 --> 训练一个 epoch 需要 2:57。
现在我们准备好执行真正的 tokenization 了。tokenizer.encode_plus函数为我们结合了多个步骤。
- 将句子分割成token。
- 添加特殊的[CLS]和[SEP]标记。
- 将这些标记映射到它们的ID上。
- 把所有的句子都垫上或截断成相同的长度。
- 创建注意力Masl,明确区分真实 token 和[PAD]token。
以下是HuggingFace目前提供的类列表,供微调。
- BertModel
- BertForPreTraining
- BertForMaskedLM(预测Mask Token类别)
- BertForNextSentencePrediction(下一个句子预测)
- BertForSequenceClassification(分类任务)
- BertForTokenClassification(Token级别分类,用于实体识别、关键词抽取)
- BertForQuestionAnswering
1 import torch
2 from transformers import AdamW, AutoTokenizer, AutoModelForSequenceClassification
3
4 # Same as before
5 checkpoint = "bert-base-uncased"
6 tokenizer = AutoTokenizer.from_pretrained(checkpoint)
7 model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
8 sequences = [
9 "I've been waiting for a HuggingFace course my whole life.",
10 "This course is amazing!",
11 ]
12 batch = tokenizer(sequences, padding = True, truncation = True, return_tensors="pt")
13
14 # This is new
15 batch["labels"] = torch.tensor([1, 1])
16
17 optimizer = AdamW(model.parameters())
18 loss = model(**batch).loss
19 loss.backward()
20 optimizer.step()
代码源自huggingface Transformer库教程
参考
- 用huggingface.transformers在文本分类任务(单任务和多任务场景下)上微调预训练模型https://blog.csdn.net/PolarisRisingWar/article/details/127365675
- 处理数据 - Hugging Face NLP Course
- 比赛:Datawhale零基础入门NLP赛事 - Task5 基于深度学习的文本分类https://tianchi.aliyun.com/notebook/118258