【论文速读】| SEAS:大语言模型的自进化对抗性安全优化

本次分享论文:SEAS: Self-Evolving Adversarial Safety Optimization for Large Language Models
基本信息
原文作者: Muxi Diao, Rumei Li, Shiyang Liu, Guogang Liao, Jingang Wang, Xunliang Cai, Weiran Xu
作者单位: 北京邮电大学, 美团
关键词: 大语言模型(LLM),对抗安全,红队,模型优化,自我进化
原文链接: https://arxiv.org/pdf/2408.02632
开源代码: https://github.com/LeonDiao0427/SEAS
论文要点
论文简介:本文提出了一种名为SEAS(自我进化的对抗安全优化)的新框架,旨在提升大语言模型(LLMs)的安全性。随着LLMs在各个领域的广泛应用,保障其输出的安全性变得至关重要。SEAS框架通过三个阶段的迭代过程——初始化、攻击和对抗优化,不断生成和利用对抗性数据来优化模型的安全性能。
实验结果显示,经过三轮迭代,目标模型的安全性达到了与GPT-4相当的水平,同时红队模型的攻击成功率显著提高。SEAS框架的核心优势在于减少了对人工测试的依赖,提供了一种自动化的、安全性持续提升的解决方案,为LLMs的安全部署提供了强有力的支持。
研究目的:本研究的主要目标是应对当前对抗性方法在面对日益复杂的LLMs时所遇到的挑战。传统方法通常无法有效揭示模型的潜在漏洞,因此,SEAS框架旨在通过自我进化的方式,迭代提升红队模型和目标模型的能力,从而在无需人工干预的情况下增强LLMs的安全性能。最终目标是建立一个能够不断适应新威胁的安全优化框架,以提高LLMs的整体安全性。
研究贡献:该研究的主要贡献包括以下几点。
1. 提出了一个自我进化的对抗安全优化框架,通过多轮迭代,提升了红队模型和目标模型的安全性。
2. 构建了一个综合性的安全数据集,涵盖了多种对抗性和模棱两可的无害提示,支持LLMs的安全开发与部署。
3. 实验表明,经过三轮迭代,目标模型的安全性已接近GPT-4水平,同时红队模型的攻击成功率提升了50.66%。
引言
近年来,大语言模型(LLMs)在多个领域展示了强大的能力,但其在实际应用中的安全性问题也日益凸显,特别是在防止有害输出方面。现有的对抗性测试方法,如红队测试,通常依赖人工生成的攻击数据,这种方式虽然有效但耗时且成本高昂。为了克服这些问题,研究者们提出了自动生成对抗性提示的方法。然而,随着LLMs性能的提升,这些方法在发现和利用模型新漏洞方面的有效性受到限制。因此,本文提出了SEAS框架,通过自动生成和优化对抗性数据,增强LLMs的安全性,并减少对人工测试的依赖。
相关工作
在LLMs安全性研究中,红队测试是发现模型潜在漏洞的重要手段。传统的红队测试依赖于人工生成对抗性提示,虽然能够有效发现高质量的安全问题,但在覆盖模型全部漏洞方面存在局限性。
近年来,研究者开始探索自动化方法,通过模型自动生成对抗性提示,以提高测试效率和覆盖范围。例如,MART框架采用多轮迭代的方式,逐步更新红队模型和目标模型,从而提升模型的安全性能。然而,这些方法在应对模型性能提升带来的新型漏洞时,适应性仍然不足。
本文提出的SEAS框架在此基础上进行了改进,通过自我进化和持续优化,更全面地发现和利用LLMs的潜在漏洞,从而显著提升模型的安全性。
研究方法
SEAS框架包括三个主要阶段:初始化、攻击和对抗优化。在初始化阶段,红队模型和目标模型分别使用不同的数据集进行微调,以增强红队模型生成对抗性提示的能力和目标模型的指令遵循能力。在攻击阶段,红队模型生成对抗性提示,这些提示输入到目标模型中生成响应,随后通过安全分类器评估这些响应的安全性。在对抗优化阶段,成功的攻击提示用于进一步优化红队模型,而未成功的提示则用于优化目标模型。通过多轮迭代,两个模型在不断的对抗和优化过程中逐步提升各自的能力,最终显著增强了模型的整体安全性能。
研究实验
实验细节:实验使用SEAS数据集进行模型的微调和优化。红队模型和目标模型在不同的数据集上分别进行初始化,确保红队模型生成的提示具有多样性,同时增强目标模型的指令遵循能力。在攻击阶段,红队模型生成的对抗性提示输入到目标模型中,并通过安全分类器对生成的响应进行安全性评估。通过多轮迭代,红队模型的攻击成功率不断提高,而目标模型的安全性能也得到了显著增强。
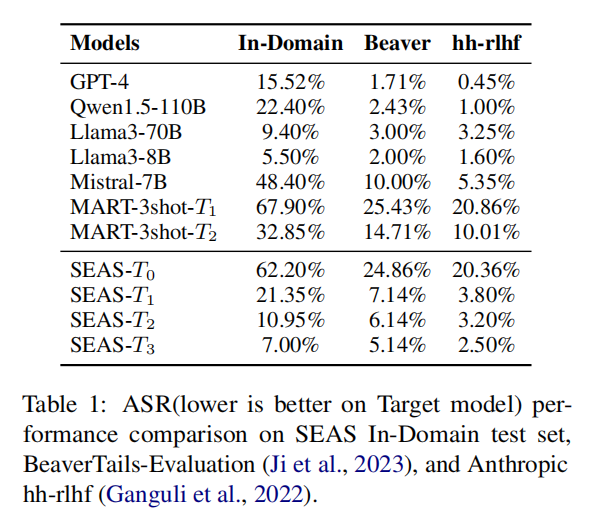
实验结果:实验结果表明,经过三轮迭代,SEAS框架显著提升了目标模型的安全性,使其在对抗性测试中的表现接近GPT-4水平。同时,红队模型的攻击成功率随着迭代次数的增加而显著提升,达到了50.66%的增长。此外,实验还发现,SEAS框架能够在保持模型通用能力的同时,显著增强其抵御攻击的能力。通过多轮次的优化,目标模型在面对复杂对抗性提示时展现出了更强的鲁棒性,证明了SEAS框架在提高LLMs安全性方面的有效性和可行性。
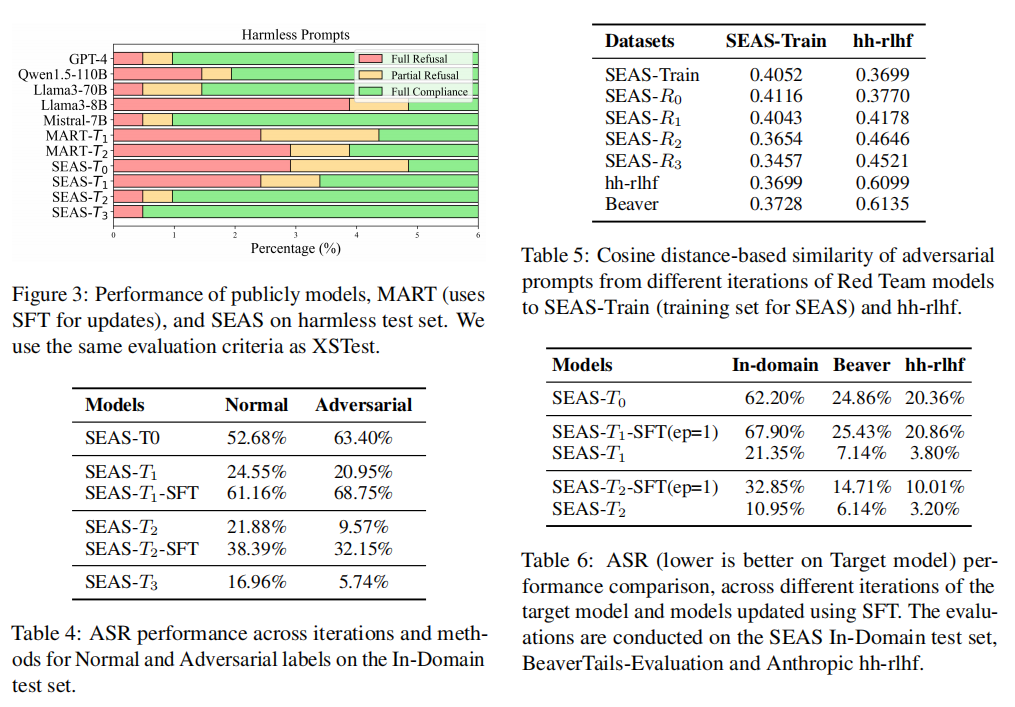
论文结论
本文提出的SEAS框架通过自我进化的方式,显著提升了LLMs的安全性能。与传统红队测试方法相比,SEAS框架减少了对人工干预的依赖,能够自动生成并优化对抗性提示。
实验结果显示,经过多轮迭代,SEAS框架不仅提升了模型的安全性,还保持了模型的通用能力。未来研究可以进一步扩展SEAS框架的应用范围,并探索更多的优化策略,以进一步提升LLMs的安全性和实用性。
原作者:论文解读智能体
校对:小椰风
