比 GPT-4 便宜 187 倍的Mistral 7B (非广告)

Mistral 7B 是一种设计用来快速处理较长文本的人工智能模型。它采用了一些特别的技术来提高速度和效率,比如“分组查询注意力(grouped-query attention)”和“滑动窗口注意力(sliding-window attention)”。
这些技术帮助模型在生成输出时保持较高的质量和速度,同时还能处理更多的上下文信息(最多 8,000 个单词左右)。相较于一些更大的模型,Mistral 7B 的运算速度更快,内存要求更低,也更节省成本,而且它是免费提供的,使用没有限制。
为了得出 Mistral AI mistral-7b-instruct 模型与 ChatGPT 3.5 或 4 模型之间的成本差异,我们进行了以下实验:
- 使用了一个 NVIDIA A100 40GB 的显卡来运行模型,这种显卡比较适合处理复杂的 AI 模型。
- 模型运行了 50 个并行请求(请求的数量可能会受到硬件配置的影响)。
- 在实验中,模型处理了大约 1420 万个输入标记和 120 万个输出标记。
- 实验持续了 40 分钟,期间处理了大约 1520 万个标记。
- 使用 NVIDIA A100 40GB 的成本大约是每小时 4 美元。
成本计算:
我将使用以下数据:
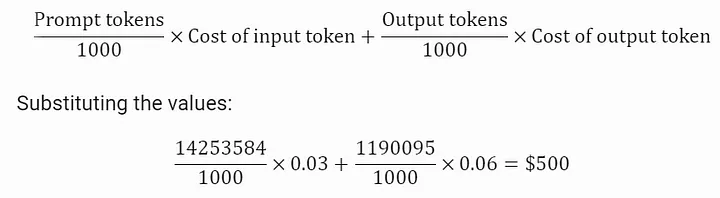
- Prompt Tokens:14,253,584
- Output Tokens:1,190,095
- 每个Input Token的成本:ChatGPT 3.5 4K 模型为每 1K tokens 0.0015 美元,ChatGPT 4 为每 1K tokens 0.03 美元
- 每个Output Token成本:ChatGPT 3.5 4K 模型为每 1K tokens 0.002 美元,ChatGPT 4 为每 1K tokens 0.06 美元
GPT 3.5 成本计算:
计算 GPT 3.5 的成本

GPT 4成本计算:
计算 GPT 4 的成本
Mistral AI 的费用:
使用 NVIDIA A100 40GB 显卡来运行 Mistral AI,成本约为每小时 4 美元。在 40 分钟内可以处理所有 1520 万个tokens,总成本为 2.67 美元。
下图是Mistral AI 与 ChatGPT 的成本比较
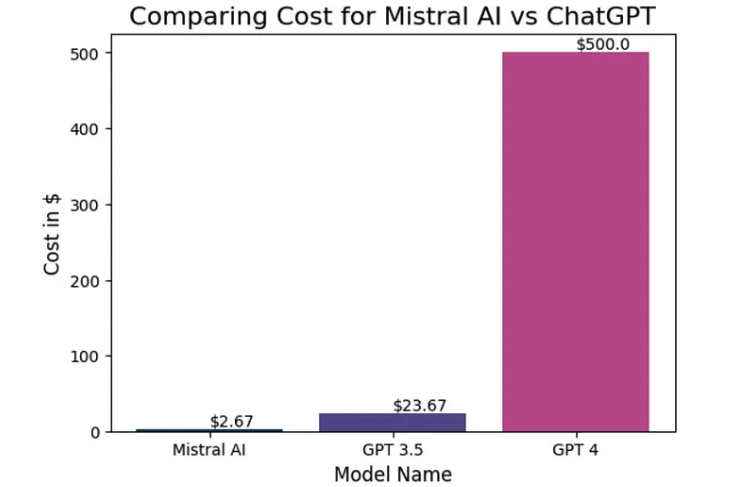
观察结果:
- Mistral AI 比 GPT-4 便宜约 187 倍,比 GPT-3.5 模型便宜约 9 倍。
- 通过增加并行处理,可以进一步降低 Mistral AI 的成本。
- 通过量化模型,我们可以减少 GPU 的利用率,从而提高效率。
结论:
- Mistral AI 是一个非常有前途的替代方案,尤其是与 GPT-3.5 相比。
- 它特别适用于需要高吞吐量、更快处理速度且成本较低的场景。
- Mistral AI 也可以作为一种预筛选工具,用于先筛选数据,再交给 GPT-4 进行更详细的处理,从而进一步降低总成本。
重复实验:
下面是示例代码:
- 此代码将使用ThreadPoolExecutor并行处理
- 并行线程数设置为 250,但您可以根据需要调整此数字。并行请求数取决于您的机器和 CPU 核心。
- 这是一个示例代码,它不会在任何地方保存结果,因此您可能需要修改它以满足您的需要
def check_answer(i):
try:
messages = [
{
"role": "user",
"content": "You are an assistant"
},
{
"role": "user",
"content":"""
"In the context provided in ```
- Carefully create complete summary from above definitions and context provided in ```to provide your answer.
- Lets think step by step."
"""
},
{
"role": "user",
"content": "```context: " + context + "```"
}
]
chat_completion = openai.ChatCompletion.create(
model="mistralai/Mistral-7B-Instruct-v0.1",
messages=messages,
temperature=0,
max_tokens=4000
)
except:
return None
return chat_completion
def worker(i):
try:
result = check_answer(i)
print(f"Completed index {i}")
except concurrent.futures.TimeoutError:
print(f"check_answer({i}) timed out. Moving on to the next index.")
num_processes = 250
with concurrent.futures.ThreadPoolExecutor(max_workers=num_processes) as executor:
futures = [executor.submit(worker, i) for i in range(len(temp_result['content']))]
concurrent.futures.wait(futures)