实时分析都靠它→揭秘YashanDB列式存储引擎的技术实现

01 概述
YashanDB列式存储引擎,又称为LSC(Large-scale Storage Columnar Table)。其通过自研的CBO优化器、向量化执行、原生列存格式等技术,达到业界领先的查询分析能力。
YashanDB LSC是专为海量数据的实时分析场景而设计,致力于实现简单操作、极速分析、实时导入、低成本四个目标。
简单操作
YashanDB LSC基于YashanDB统一平台,在一定程度上降低用户的使用和维护难度;同时LSC具备完善的事务能力,支持MVCC、HA同步,支持同行表方式进行备份恢复等。
极速分析
YashanDB LSC依次通过块级过滤、行级过滤减少数据量;然后针对不同数据量和查询需求,智能选择缓存策略、支持小切片合并以提升查询效率,或是灵活采用多种索引和排序技术来加速数据访问。
实时导入
YashanDB LSC支持批量导入、流式导入以及全实时导入三种方式。最高可达到单DN 300MB/S的导入速度,且支持可变列存结构,实现毫秒级的数据导入。
低成本
YashanDB LSC通过列存压缩编码,以及存算分离等技术实现海量数据的低成本分析。
下面我们将深入探讨LSC技术实现原理,并围绕其四大目标以及未来的发展规划进行阐述。
02 融合架构
本章采用整体至局部的叙述方式详细介绍LSC结构,依次介绍LSC整体架构、LSC的表结构、LSC的切片文件格式。
统一存储结构
YashanDB存储引擎在接口、元数据管理、存储结构、空间管理等方面都是高度融合的。同时在存储引擎的基础组件上是高度统一的,比如事务机制、备份恢复、HA等等。

存储引擎对外有统一的接口,如支持DDL的create/alter/drop等操作表结构的接口、DML等插入、修改、删除记录的接口。行表由于操作主要是单行的,所以接口传递的数据主要是Row结构;列表侧重批量处理,其传递的数据是列式的DataSet结构。但是不论行表还是列表,我们都提供了单条/批量查询的能力,这为行列混合处理奠定了基础。
在元数据管理上,列表使用了行表同样的系统表来表达,包括分区、索引等的表示都是高度统一的。同时YashanDB行表支持采用列式索引来加速,列表也可以使用Btree索引,列表的部分列还可以用Heap结构来存储。
在数据缓存上,LSC根据其数据特征扩展实现了变长块缓存。此外实现了本地磁盘缓存来加速存算分离下的数据访问。
在空间管理上,列表扩展了Tablespace能力,支持采用databucket来管理列表的空间,databucket是通过目录和文件来进行空间管理的。这与行表DataFile基于Segment/Page的管理有较大差异。
YashanDB LSC表支持完善的事务能力,保证事务ACID特性,支持MVCC,支持行表一样的方式来进行备份恢复,支持HA同步。
LSC表结构
LSC表通过分布/分区/切片(Slice)三层来组织其数据。首先通过分布将数据打散到不同的数据节点,分布实质上是一个一级分区;然后在数据节点内通过分区进一步划分数据,LSC表支持Range/List/Hash等分区方式;在分区内数据由切片组成,切片又可以分为可变切片,内存切片,以及稳态切片。

-
可变切片:支持原地更新,小事务操作,主要针对实时导入等场景。
-
内存切片:主要用于快速导入,导入完成后生成稳态切片。
-
稳态切片:生成后不可修改,采用列式存储,且其数据经过排序,编码,压缩等处理,查询性能非常好,支持标记删除。
切片文件格式
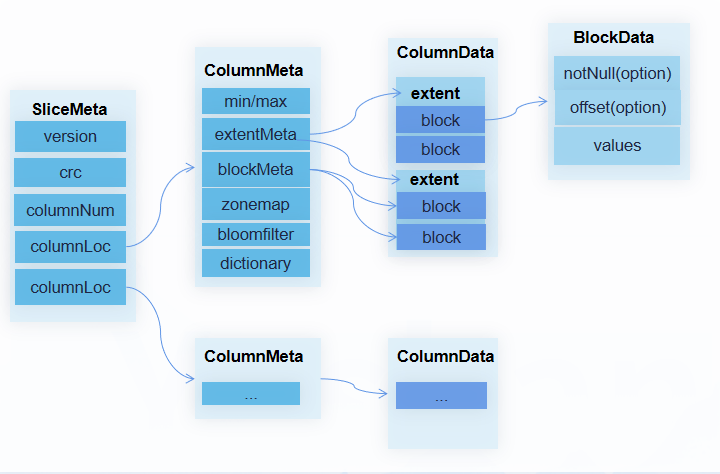
那么切片的数据如何组织呢?这里我们重点介绍下稳态切片的存储格式。稳态切片从逻辑结构展开主要由SliceMeta、ColumnMeta、ColumnData、BlockData组成。
-
SliceMeta:其中包含切片的格式版本、元数据的CRC校验信息,以及每列Meta的位置信息。
-
ColumnMeta:其中包含切片/块粒度的MIN/MAX统计信息、Extent元数据(Block的集合)、Block元数据、布隆过滤器、字典元数据等。
-
ColumnData:其中包含某列的所有Block。
-
BlockData Block:数据由NotNull、Offset、Values三个向量组成。其中NotNull向量和Offset向量是可选的,NotNull向量用于表示列的空值信息,Offset向量用于记录变长数据的长度信息,以及完成某行数据的快速定位。
切片的物理结构有多种形式,可以根据需要将不同的逻辑部分组合存储。
方式1:Slice所有数据一起存储。
方式2:Slice的每列单独存储。
方式3:Slice的每列的元数据和数据独立存储。
YashanDB默认采用方式3,列的元数据和数据独立存储。一个Slice存储的例子如下图:
业界已经有很多开源格式了,为什么YashanDB还要引入自己的文件格式呢?主要有以下两方面的原因:
一是YashanDB的数据格式是专门设计的,与开源格式存在差异,写入和查询时有额外转换的开销,没法做零拷贝等极致优化。
二是方便扩展新的类型和编码,尤其是在一些特定业务场景下,可以结合数据特征达到极致的编码效果。
03 极速分析
在本地三节点测试中,TPC-H 100G首次执行35秒,二次执行接近22秒,达到了业界领先的水平。接下来我们将展开介绍LSC如何实现快速的查询分析。
在列存的基础下,要实现快速的查询分析,首先需要尽可能的过滤数据,减少需要处理的数据量;其次在加载数据量确定的情况下,考虑如何以最快的速度把数据加载到内存向执行层返回;再次需要考虑在实际导入过程中如何快速的查询;最后还需要考虑分析中的点查场景。下面依次展开介绍具体如何实现。
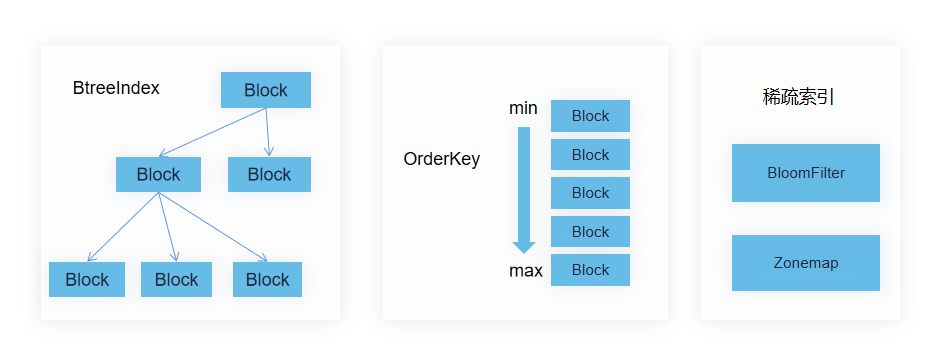
块级过滤
查询语句的条件下推到存储层,存储可以通过如下方式完成Block粒度的过滤。
首先过滤列在 Slice粒度的MIN/MAX统计信息。如果不满足,则说明没有Block满足条件,可快速跳过该条件;其次过滤列在Block粒度的MIN/MAX统计信息,将条件与MIN/MAX向量做比较,得到满足条件的Block位图;最后过滤列上的布隆过滤器,用于等值条件快速过滤。
MIN/MAX统计信息也叫Zonemap,其和布隆过滤器都属于稀疏索引。稀疏索引作为元数据存储在ColumnMeta中。
下图展示了一条语句块级过滤过程:

语句“SELECT C1,C3 FROM TABLE WHERE (C1 < 30 OR C1 > 100) AND (C2 = 2 OR C2 = 3)” ,其中C1上的条件可以通过Slice/Block粒度的MIN/MAX统计信息来过滤。C2列除了用MIN/MAX过滤外,还可以使用布隆过滤器来过滤。
另外C2列并未出现在最终结果中,所以实际不必向执行层返回其数据。基于稀疏索引的块级过滤,提前将不满足条件的Block过滤掉,降低了IO/解压/解码/行级过滤/结果集生成等步骤的开销,极大的提升了查询性能。
行级过滤
在完成块级过滤后,就可以按照过滤结果将块加载到内存。这时的数据是尚未解码的,在这里可以做不解码数据的行级过滤。对比执行层的过滤,其好处非常明显,一方面降低了解码开销,另外还减少了数据拷贝。
这里以字典编码为例,来说明实现不解码过滤。
字典编码后列数据被转换为字典元数据和编码数据,其中字典元数据包含字典值、字典号、排序号。编码数据中存储的是字典号。

等值条件过滤
等值条件过滤可以基于字典号比较完成。通过字典元数据将条件转为字典号,然后与编码数据的字典号比较,就可以得到满足条件的行位图。
范围条件过滤
由于字典号之间并无大小关系,因而范围条件无法通过字典号比较完成,需要将范围条件通过字典元数据转为排序号,将编码数据也转换为排序号,通过排序号之间的比较就能完成范围条件的比较。
缓存与IO
那过滤之后,如何将数据快速载入缓存?
在块级过滤时,就需要加载ColumnMeta,块级过滤完成后加载ColumnData。最快的加载方式就是数据本身在我们的应用缓存中。
YashanDB LSC表可根据查询计划自动选择缓存策略,也支持多层次的缓存,如下图:
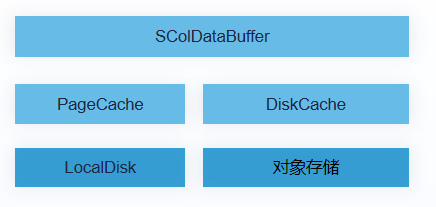
其中操作系统的PageCache可对本地文件系统的数据加速,DiskCache可针对对象存储等远端数据进行加速,SColDataBuffer可根据业务场景来缓存数据。
如果数据不在缓存中,那么就需要实际发起IO了。这里我们支持根据块过滤的结果,一次性将连续的Block读取。尤其在对象存储场景下,可极大提升读取速度。

删除合并
上面都是正常场景下的查询加速手段,那么在导入期间,在有删除的情况下,如何保证快速的分析呢?这里首先就涉及到如何表示删除的问题了。
我们知道行表是每行都有删除事务信息的,其读取时每行都需要做可见性判断。这对于列表是不可接受的,一方面分析场景下删除比较少,通常不需要处理行可见性;另外列表通常批量读取,每列进行事务判断会带来离散IO,效率非常低下。
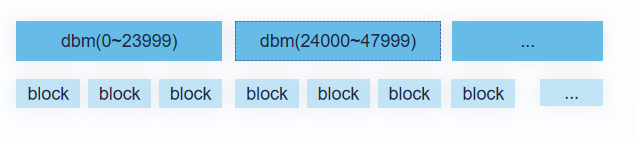
YashanDB LSC表的稳态切片将多个Block的删除信息使用一个位图来存储,并且通过roaring bitmap来存储,这样读取时只需要一次IO就能完成多个Block的删除位图读取。如下图:
随着导入的进行,删除的增多,LSC表会产生一些保护删除空洞的切片,以及一些小切片。这些小切片编码压缩效果差,无法快速批量过滤,且产生很多小IO。YashanDB支持小切片合并来提升查询性能,合并是在后台进行的,并且支持资源管控来降低对业务的影响。
点查优化
在实际业务场景中,除了分析常见的批量查询外,还有一些少量数据查询的场景。比如查询明细数据,以及导入或业务执行的DML操作。YashanDB支持多种方式来加速点查:
方式1:基于Btree的主键和索引。
方式2:用排序键。切片数据按照排序键组织,可以在块和行级别进行快速的二分查找。
方式3:用稀疏索引。若查找条件不在主键、索引和排序键中,可以采用该方式。
04 实时导入
实时分析对导入的基本诉求是快和实时,下面看看我们如何实现这两个目标。
批量导入
YashanDB LSC表支持两种批量导入方式:
方式1:Yasldr工具导入。用于离线导入场景,通过客户端分批,直连DN(数据节点)等技术,可达到单DN 300MB/S的导入速度。
方式2:DataX等工具导入 。用于在线批量导入场景,通过连接CN(协调节点)来导入,支持完善的事务能力。单DN可达到50MB/S的导入速度。
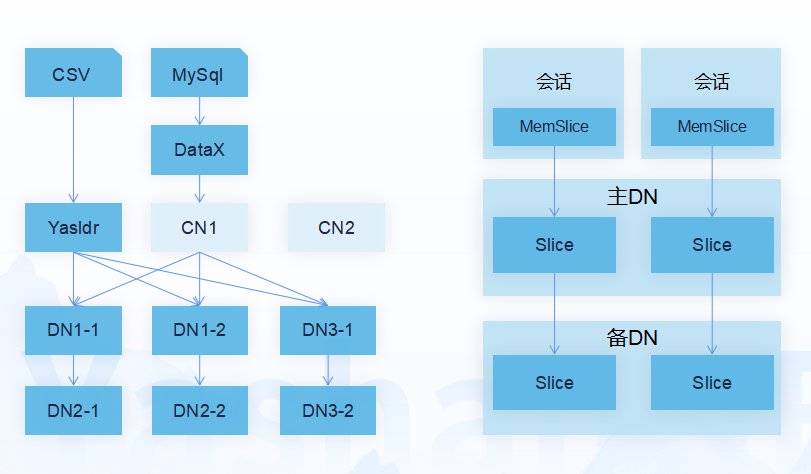
在导入时,我们先将数据写入到内存切片进行攒批,然后按批生产稳态切片格式,同时将数据发送给备机,实现了全流程的批量化,并行化处理。
流式导入
YashanDB LSC表支持通过Flink等导数工具来进行流式导入,流式导入关键点是如何高效删除和去重。LSC表通过Upsert索引去重技术和延迟合并删除,可以实现非常高效的删除去重。如下图:
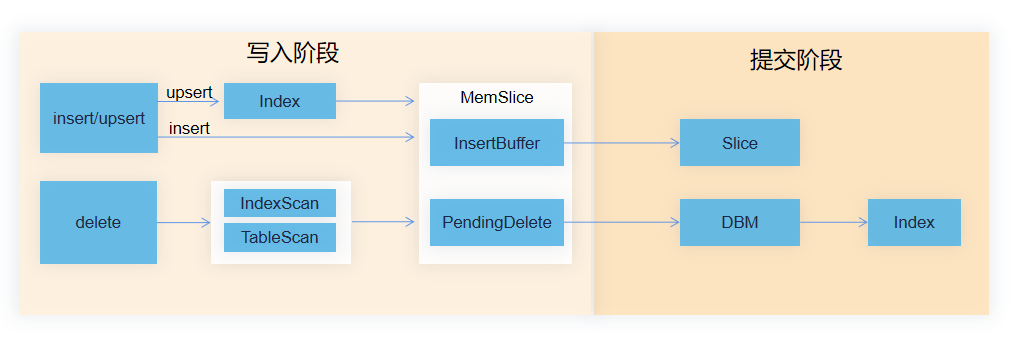
通过UPSERT索引来判断重复性,这样一次性完成了索引写入和判重逻辑,接下来只要将老记录删除即可。可以用YashanDB Btree专门的Upsert接口来支持该操作,Upsert语义下的导入性能比Insert on duplicate update或Merge Into等实现更加高效。
YashanDB LSC表稳态Slice的删除信息是合并存储的,因而我们在内存中先对删除信息进行分组合并,然后批量进行删除。这样既避免了删除信息的写放大,也避免删除信息合并存储可能引起的死锁问题。
全实时导入
批量导入和流式导入虽然都实现了在线导入,但是为了避免生成很多小切片文件,影响查询性,对时效性有一定的约束。YashanDB LSC表支持可变列存结构实现毫秒级的数据导入。
可变列存是一种可以原地更新的列存结构,支持行级事务,因而可以实现无限制的实时导入。并且支持All in mem的表空间来加速可变列存的导入和查询。
05 低成本
分析场景下数据量通常都很大,且分析业务的执行通常不是持续稳定的。在这种场景下可以通过一些技术来降低业务的成本,提高资源的有效利用率。
编码压缩
编码压缩不仅可以帮助提升查询性能,还可以大幅降低成本。
YashanDB LSC表支持如下编码方式:
-
数值/时间类型,支持Rle/Delta编码。
-
Decimal类型,支持Decimal32/Decimal64/Decimal128/Byte-Packed编码。
-
字符串类型,支持字典/前缀编码。
在切片生成时会自动根据数据特征选择编码类型,无需用户指定。
YashanDB LSC支持ZSTD/LZ4压缩算法,针对每个压缩算法可以配置高/中/低三种压缩等级;支持在数据库、表、列等粒度指定压缩算法;默认采用LZ4(low)压缩方法。
在TPCH场景下测试,ZSTD最大压缩比约为5:1, LZ4也能达到3:1。大幅降低了数据的存储和访问成本。
对象存储
另一个能大幅降低成本的技术是对象存储的使用。
YashanDB LSC表的稳态列存在写入后是不会修改的,非常适合使用对象存储。另外结合数据访问策略,可以将部分热点数据放在本地,非热点数据存入对象存储。对象存储的数据还可以通过本地磁盘缓存来进行加速。
这样从整体上达到性能不下降,存储成本大幅下降的好处。同时还实现了数据的集中管理。
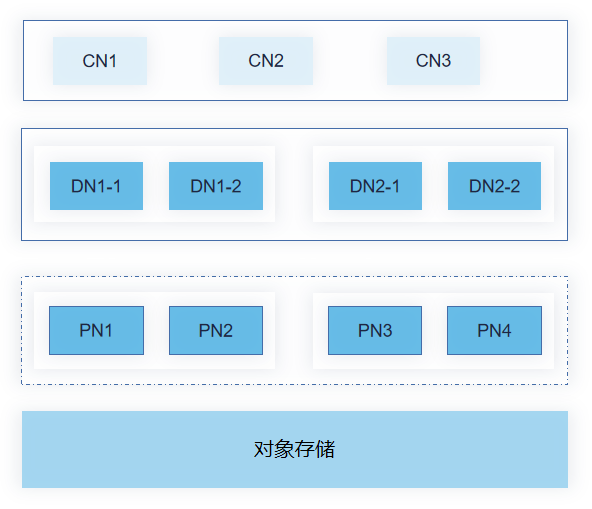
此外通过对象存储分离存储,可实现计算节点的无状态化。如上图中的PN节点,其本身不持久化任何数据,元数据通过DN获取,数据从对象存储获取,因而可以根据业务需要快速的扩缩。从而大幅降低业务成本。
06 展望
YashanDB列式存储引擎未来也将持续提升核心竞争力和产品成熟度,在高并发、低延时、检索等能力上继续完善。其架构会沿着存算分离,湖仓方向持续演进。
本文源自Meetup第16期实时数仓专场直播,相关视频可咨询官方助手号获取视频链接。若有更多想听的、想看的内容,也可以在评论区告诉我们~