RAPIDS AI 加速制造业预测性维护效率

根据国际自动化协会(ISA)报告,每年有5%的工厂生产因机时间而受到损失。在另一种情况下,各行各业的制造商在全球范围内放弃了大约647亿美元,而相应的部分在生产中则接近13万亿美元。当前的挑战是预测这些机器的维护需求,以最大限度地减少机时间、降低运营成本并优化维护计划。
这种问题在提供 Desktop as a Service (DaaS) 服务的公司中尤为普遍,这些公司租用计算设备用于商业用途,并需要满足严格的 SLAs 要求。DaaS 行业的价值高达 3 亿美元,预计将增长 12%。
在本文中,我们将讨论一个案例:我们构建了一个预测模型,以根据各种操作参数、传感器数据和历史维护记录来估计计算资产的剩余使用寿命(RUL)。
LatentView Analytics
LatentView Analytics 支持多个 DaaS 客户端,并通过商业智能、数据分析和科学、数据工程、机器学习和 AI 等领域的高级数据分析咨询服务,提供运营复杂的服务。
我们发现,企业组织可以使用预测性维护算法在设备故障发生之前进行检测,从而节省宝贵的停机时间。数据科学的进步使得预测和预测在企业中得到广泛应用。与常规或基于时间的预防性维护等标准操作程序相比,预测性维护能够提前解决问题。
LatentView 构建了一种名为 PULSE 的解决方案,这是一种先进的预测性维护解决方案,旨在重新定义制造效率。通过连接支持 IoT 的资产,PULSE 使用先进的分析来提供实时见解,使您的团队能够采取前瞻性的措施。
PULSE 有助于减少和消除计划外机时间、过高的维护成本和运营低效。你可以精确预测机器故障,消除机时间麻烦,并提高制造效率。
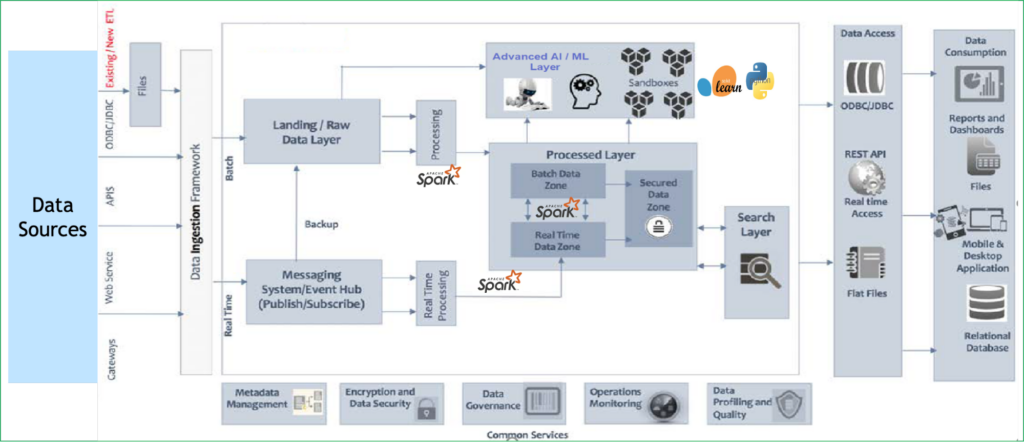
图 1.LatentView ML 工作流程
剩余使用寿命用例
一家领先的计算设备制造客户希望实施有效的预防性维护。数百万台租赁计算设备发生部件故障,导致客户流失和不满足。如果能够及早发现故障并提出维修和更换建议,将减少客户流失,提高客户忠诚度和盈利率。
为了解决客户的痛点,我们决定使用预测性维护模型来预测每台机器的RUL。该模型有助于确定每台机器在需要维修或更换之前的运行时间,从而消除机器交付给客户时的部件故障。
为构建这种适用于计算设备的预测性维护模型,我们首先需要聚合来自关键热感、电池、风扇、磁盘和 CPU 传感器的数据,这些传感器测量了机器的温度、周期和多个方面。然后,将这些数据聚合并应用于预测模型中。
以下各节将介绍我们的初步尝试、学习,以及GPU加速的数据科学如何帮助我们加快实施速度,从而为客户成功交付项目。
面临的挑战
在我们首次尝试为客户构建概念验证时,我们在使用预测性维护平台产品 PULSE 时面临着许多挑战,这些挑战主要集中在计算瓶颈和延长周期处理时间上。这主要是因为进行有效预测所需的大量数据和源源不断的数据流,反过来又吸引了越来越多的节点和图像来满足计算需求。
虽然这些挑战是问题的整体性,但我们主要希望工具和库与解决方案集成,以便更好地扩展到动态操作条件,该解决方案应尽可能缩短查看结果所需的时间,并优化 TCO(包括基础设施成本)。
我们遇到了以下一些问题:
- 大型实时数据集
- 稀疏和噪声传感器数据
- 多元关系
- 漫长的时间轴
- 成本方面
- 推理挑战
大型实时数据集
由于在多个地点部署了数百万台机器,且每台机器上都有多个传感器,并且每隔 5 分钟就会收集一次数据,因此每天会收集超过 1TB 的数据。这使得数据处理和清洁成为最耗时和繁琐的任务,因为我们花了近 60% 的时间准备数据。
使用最新训练数据对模型进行持续迭代训练、数据清洁、添加新功能,以及试验多个模型以最终确定生产模型,还可以增加总工作量、时间和计算能力。
稀疏和噪声传感器数据
在制造或 DaaS 环境中,从每台机器的传感器数据通常稀疏(大多数值为 0 或为空),以不规则的时间间隔收集,并且容易产生噪音。
多元关系
在该用例的单个模型中必须考虑的传感器类型的数量造成了复杂的多元情况,从而增加了计算需求。
漫长的时间轴
创建准确的预测需要包含大量示例的大型数据集来训练模型。
随着大数据用例的不断增长,CPU 性能成为主要瓶颈,这些限制增加了周期时间和成本,并在我们的 PoC 结果中变得显而易见。
成本方面
必须对基础设施进行扩展以缩短周期时间。大规模 CPU 基础设施会产生巨大的成本,从而降低数据驱动型企业的投资回报。
推理挑战
部署大规模预测过程十分困难。通常需要大量软件重构,有时甚至需要重写针对用例和团队之间的传递进行优化的代码。在这种情况下,insight 生成可能会大幅延迟。
采用 RAPIDS 的加速预测性维护解决方案
PULSE旨在使用PyData生态系统在CPU基础设施上运行。随着 RAPIDS 的推出,我们希望通过RAPIDS为客户提供一个加速的PULSE平台,作为所有PyData库的直接替代品。
我们发现,在 PULSE 系统中使用 NVIDIA RAPIDS 具有以下明显的优势:
- 创建更快的数据管道
- 在已知平台上工作
- 浏览动态操作条件
- 处理稀疏和噪声传感器数据
- 得益于更快的数据加载和预处理,模型训练速度也因此加快了。
创建更快的数据管道
借助 GPU 的强大功能,工作负载实现了并行化,从而减轻了处理大量近乎实时数据对 CPU 基础设施的负担。随着性能的提高,我们预计基础设施将以更少的资源更高效地运行,从而节省成本。
在已知平台上工作
我们团队中的数据科学家使用 Python 包 pandas 和 scikit-learn。RAPIDS 提供语法类似或相同的包,以及在 GPU 上运行工作负载的 RAPIDS cuDF 和 cuML 库,这有助于缩短开发时间,而无需开发新的技能。
浏览动态操作条件
借助我们使用的 GPU 加速,该模型可借助额外的训练数据无缝地调整,以适应动态条件,确保其保持稳健,并能响应不断变化的模式和近期趋势。
处理稀疏和噪声传感器数据
事实证明,RAPIDS 在处理复杂的稀疏和噪声传感器数据方面发挥了重要作用。通过使用 GPU 加速的 cuDF 库,我们的数据预处理速度得到了显著提升。我们以前所未有的效率对缺失值进行了估算,并过滤掉了噪声,准确地处理了数据收集中的异常情况。
RAPIDS奠定了清晰可靠的数据集的基础,为更准确的预测模型奠定了基础。
更快的数据加载和预处理、模型培训
RAPIDS 的数据加载、预处理和 ETL 功能基于 Apache Arrow 构建,用于加载、连接、聚合、过滤和其他操作数据,所有这些功能均在类似 pandas 的 API 中实现超过 10 倍的加速。这缩短了模型迭代时间,使我们能够在短时间内尝试多个模型。
图 2. 对 NVIDIA GPU 加速库的使用位置进行了高度代表性描述。我们已在现有的 PULSE 解决方案中集成 RAPIDS 和 RAPIDS Accelerator for SPARK,以加速 AI/ML 层以及数据处理和高级分析。集成无缝,并且可以无代码或低代码更改。
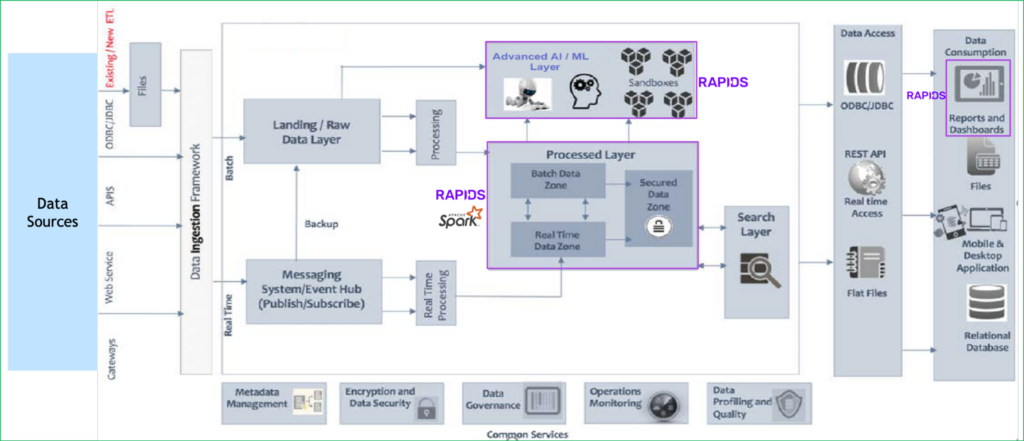
图 2.使用 RAPIDS 的 LatentView ML 工作流程
CPU 和 RAPIDS 性能对比
为了评估项目中的 GPU 加速,我们计划进行概念验证,通过比较我们的 CPU-only 模型与在 GPU 上的 RAPIDS 来对加速性能进行基准测试。这些是我们比较的解决方案:
- 使用 Pandas 对解决方案进行仅 CPU 的测试运行
- 使用 RAPIDS cuDF 进行测试运行,以加速 Pandas
此试点采用本地设置,具有以下 GPU 基础设施:
- CPU 插槽:2
- CPU 型号:AMD EPYC 7742
- CPU 核心:128 个核心 (256 个超线程)
- 系统内存:512GiB
- GPU:NVIDIA A100 PCIe
- GPU VRAM:80GiB
数据集
在此试点项目中,因安全和数据合规性问题,我们无法使用生产数据。这些基准测试是在客户的安全基础设施之外完成的。
我们必须返回到具有备用列的合成数据。当前的生产部署使用 Databricks 和 Microsoft Azure。在测试中,我们希望使合成数据尽可能接近实际数据。我们使用 Databricks 实验室基于 Spark 的 dbldatagen 实用程序生成大小为 12 GB 的数据。
以下示例代码显示了数据集的详细信息:
|
|
代码示例生成由参数 rows 定义的所需大小的合成数据。前面定义的数据生成规范与客户生产数据结合使用。
生成的数据具有多种数据类型,这些数据类型必须经过预处理和特征工程步骤。这有助于从生成的数据中提取和转换变量,这些变量可用于进一步的高级数据分析以及监督式或非监督式学习。
数据处理、转换和特征工程
在当前的 RUL 部署用例中,我们通过从热传感器、电池传感器、风扇传感器、磁盘传感器和 CPU 传感器中收集数据来查看来自机器的各种参数。我们的测试包括以下任务,因为这些是准备数据集来训练机器学习模型的先决条件:
- 读取数据
- Feature engineering
- 删除重复项
- 丢弃不适用
- 一键编码。
- 数据归一化
- 相关性分析
- 按组操作(计算组的均值、标准差和最大值)
我们使用 RAPIDS cuDF 中的 pandas 加速器模式运行这些任务。通过在 Jupyter Notebook 中添加命令 %load_ext cudf.pandas,这种新模式可以在不更改代码的情况下加速 pandas 代码。
|
|
此工作流通过完全无代码更改功能节省了代码迁移工作量。此外,通过计算端到端工作流(包括数据准备、可视化、模型训练和调整)中的四项任务相较于 CPU 的平均改进率,还将性能提升了约 171 倍(图 3)。
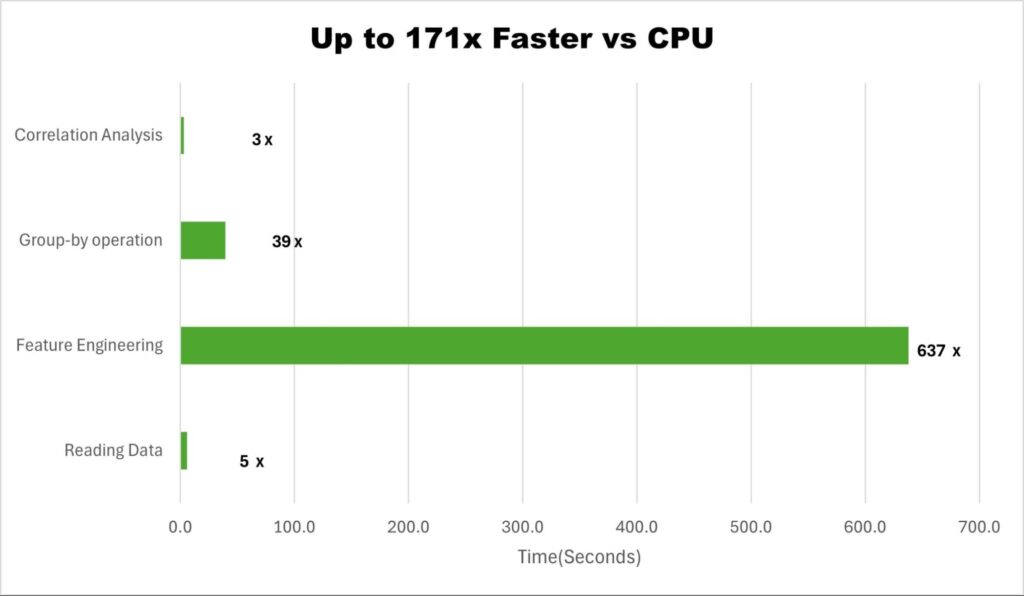
图 3.PyData 与 RAPIDS 加速对比
表 1 提供了图 3 中每个步骤的确切运行时间的更多详细信息。
| 步骤 | CPU | GPU | 提升率 | |
| 数据准备 | 读取数据 | 87 | 14.9 | 5.8 |
| 特征工程 | 382 | 0.6 | 637.7 | |
| 按组操作 | 703 | 17.7 | 39.8 | |
| 相关性 | 相关性分析 | 27.1 | 8.3 | 3.3 |
表 1. 以所用时间(秒)衡量的 GPU 加速 ML 工作流程。
表 1 显示,相较于 Pandas,特征工程和 group-by 操作的计算密集型工作负载分别实现了 639 倍和 39.8 倍的大幅提速。工作流涵盖 10 GB 数据:43780407 行和 23 列。