c++基础入门二
C++基础入门(二)
一、函数重载
在自然语言中,一句话或者一个词有不同的意思。例如:国乒和别人比赛是“谁也赢不了”,而国足和别人比赛是“谁也赢不了”
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
类型
一、参数类型不同
//函数名相同,参数不同
void ADD(int a, int b) {
cout << a + b << endl;
}
void ADD(double a, double b) {
cout << a + b << endl;
}
int main() {
ADD(1, 3);
ADD(2.3, 4.5);
return 0;
}

二、参数个数不同
//参数个数不同
void Fun() {
cout << "Fun()" << endl;
}
void Fun(int a) {
cout << "Fun(int a)" << endl;
}
三、参数的类型顺序不同
//参数顺序不同
void Add(int a, char b) {
cout <<a<<b<< endl;
}
void Add(char b, int a) {
cout << a<<b<< endl;
}
int main() {
Add(1, 'a');
Add('a', 1);
return 0;
}
实现原理
为什么C++支持函数重载,C不支持呢?
C/C++运行一个程序,需要经历几个阶段:预处理,编译,汇编,链接
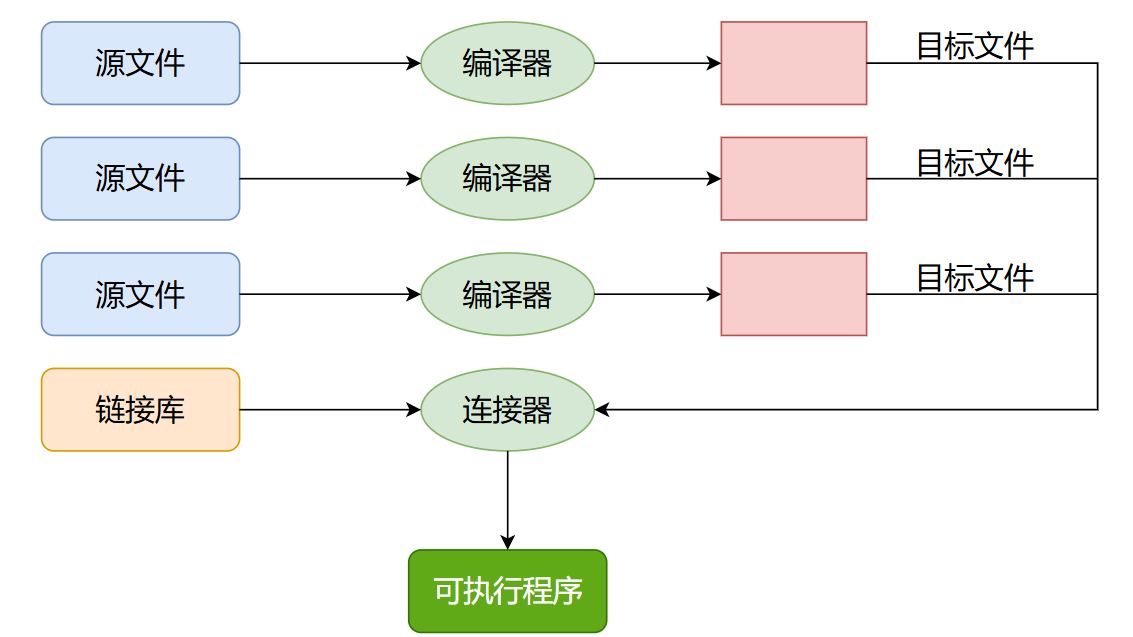
程序执行的过程

程序处理过程
在处理程序的过程中,为了识别重载的函数,编译时会给函数修饰规则,在不同系统环境下,对应的修饰规则也不同,因为Windous下的修饰规则太过于复杂,这里就演示Linux下的规则。
Linux下修饰规则*
用gcc命令把test.c编译成C语言文件
//test.c
int Add(int a,int b){
return a+b;
}
Fun(double a,int x,int *p){
}
int main(){
Add(1,3);
Fun(3,4,0)
}

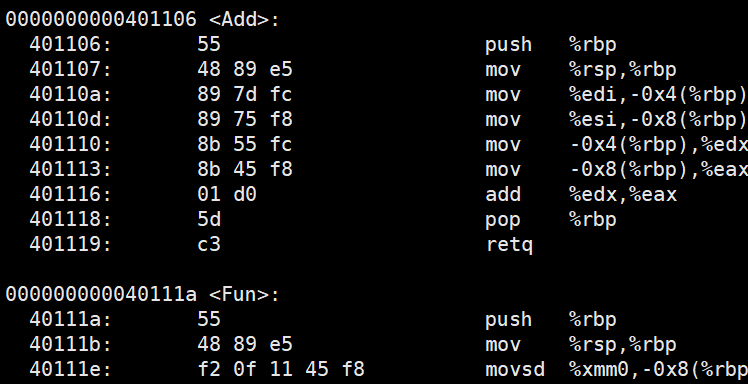
在反汇编状态下,C语言是不支持函数重载的,也没有对应的命名规则。
用g++命令把test.c`编译成**C++**文件
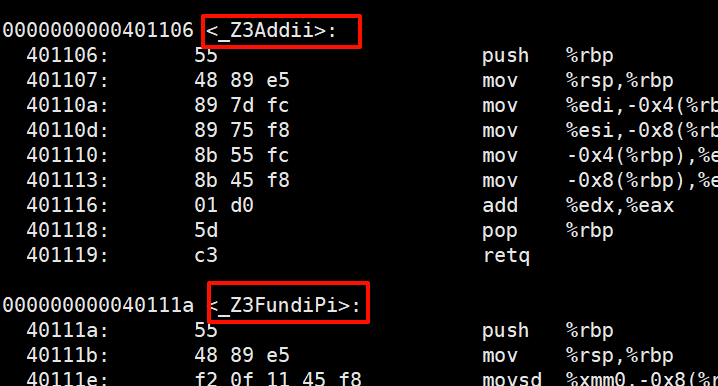
可以看见,在Linux下函数修饰规则是
_Z+字符数+函数名+类型缩写
所以,C++就支持了函数重载。另外如果对Windous下的修饰规则感兴趣,可以查看微软官方的介绍修饰名 | Microsoft Learn
二、引用
引用不是定义一个新变量,而是给已经存在的变量取别名,系统不会为引用开辟新的内存空间,而是和引用的变量公用一个内存空间。
如何理解引用呢。大家都知道,李逵在江湖上人称黑旋风,而在家被称为铁牛。
用法:类型& 引用变量名(对象名)=对象
void Fun() {
int a = 10;
int& b = a;
cout << a << endl;
cout << b << endl;
}
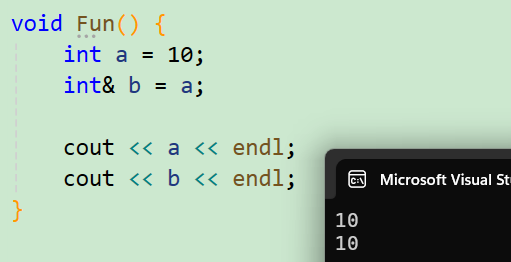
输出结果都是一样的
注意:引用的类型必须是实体的类型
特性
1、引用在定义时就必须初始化
2、一个变量可以有多个引用
3、该引用已经和实体绑定,就不能引用别的实体
int main() {
int a = 10;
//int& b;引用必须初始化
int &b=a;
int &bb=a;
int &bbb=a;
//可以有多个引用
}
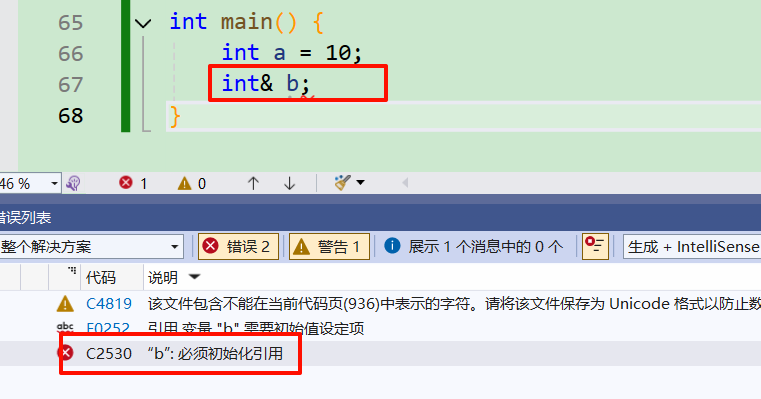
引用必须初始化
常引用
在引用常量const时,引用的变量也必须是const
就如一句话:权力只能向下兼容,不能以下犯上
int main() {
const int a = 10;
int& b = a;//会报错,因为a是常量类型
const int& rb = a;//正确用法
//向下兼容
int b=100;
const int& rb=b;
}
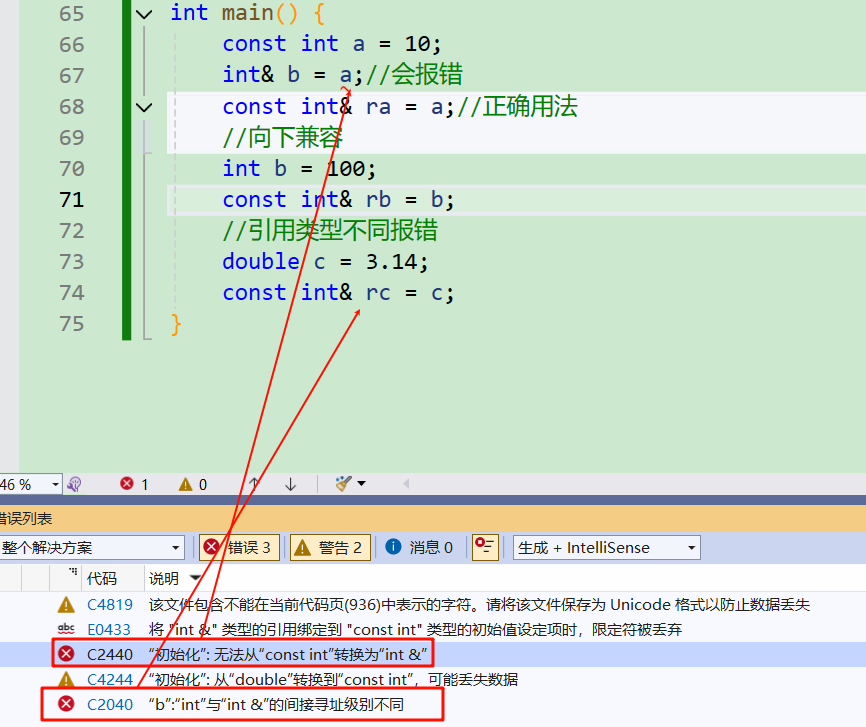
使用场景
一、做参数
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
在以往我们用C语言写一个交换函数是这样的,还需要指针。很不方便,而有了引用之后,比指针方便多了。
void Swap(int* a, int* b) {
int tmp = *a;
*b = *a;
*a = tmp;
}
二、做返回值
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
引用和指针的区别
-
引用概念上定义一个变量的别名,指针存储一个变量地址。
-
引用在定义时必须初始化,指针没有要求
-
引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
-
没有NULL引用,但有NULL指针
-
在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
-
引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
-
有多级指针,但是没有多级引用
-
访问实体方式不同,指针需要显式解引用,引用编译器自己处理
-
引用比指针使用起来相对更安全
三、内联函数
概念:以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率
int ADD(int a, int b) {
return a + b;
}
int main() {
ADD(1, 4);
return 0;
}
转到反汇编
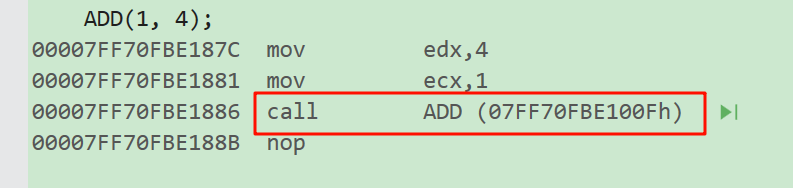
call命令可以理解成建立栈帧
可以看见ADD函数是新建立一个栈帧(消耗内存空间)。
在ADD前面加上inline,再进入反汇编查看
inline int ADD(int a, int b) {
return a + b;
}
int main() {
ADD(1, 4);
return 0;
}
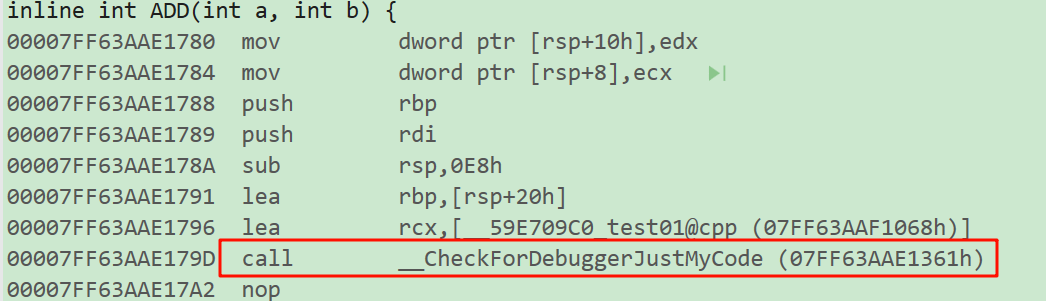
发现怎么还有call命令
1、在debug模式下,进入反汇编模式,是查看不了内联函数的
2、在release模式下,进入反汇编才能查看内联函数的过程
这里给出VS2022查看内联函数的设置
在资源管理器右键当前
cpp文件,查看属性
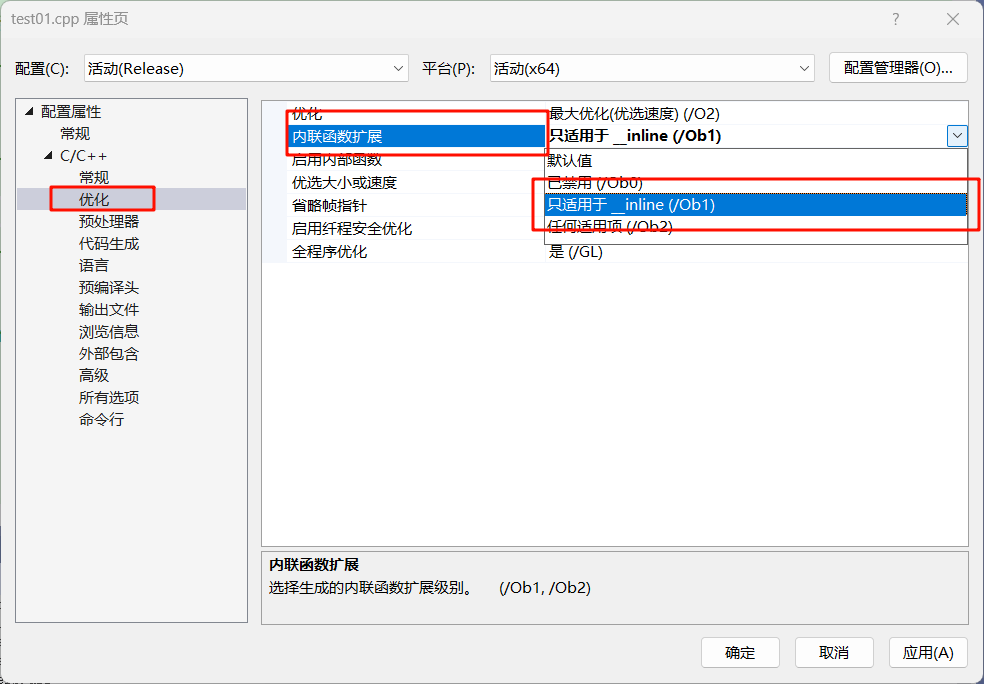
选择优化,然后找到内联函数展开,模式调成以下
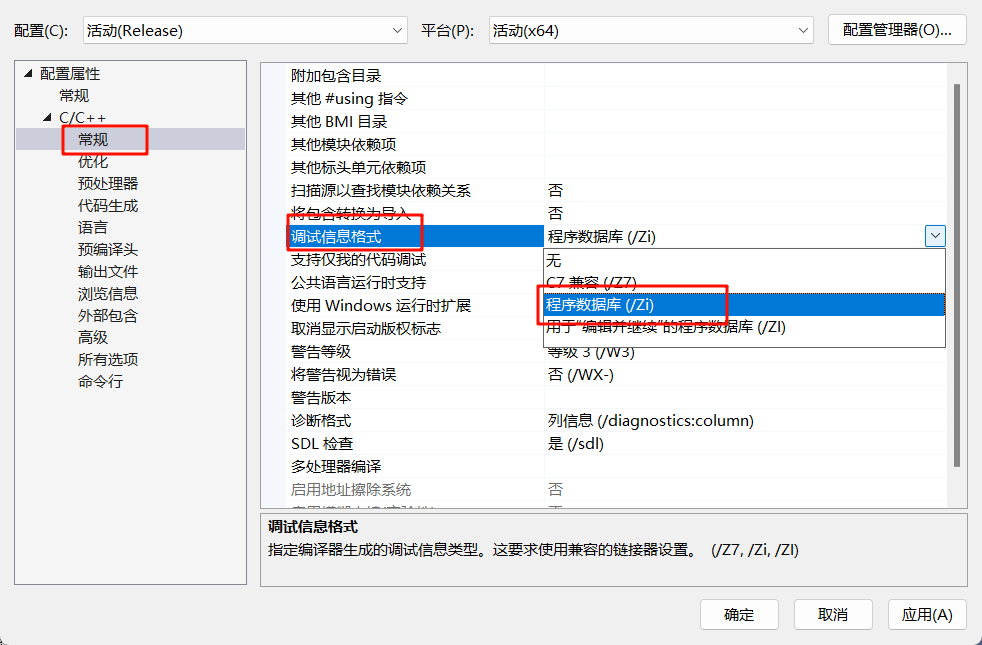
在常规里面,找到调试信息格式,改成程序数据库
最后,我们在重新进入反汇编
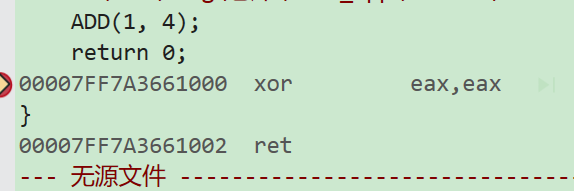
发现call已经神奇的消失了。说明内联函数在底层还是需要开辟空间,而在语法上是不开辟空间,直接在当前函数展开的。
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性

可以看见内联函数对编译器来说,只是一个申请,而且行数也不能超过太多,一般10行以内就好。