webpack原理简述
1.1 核心概念
JavaScript 的 模块打包工具 (module bundler)。通过分析模块之间的依赖,最终将所有模块打包成一份或者多份代码包 (bundler),供 HTML 直接引用。实质上,Webpack 仅仅提供了 打包功能 和一套 文件处理机制,然后通过生态中的各种 Loader 和 Plugin 对代码进行预编译和打包。因此 Webpack 具有高度的可拓展性,能更好的发挥社区生态的力量。
- Entry: 入口文件,
Webpack会从该文件开始进行分析与编译; - Output: 出口路径,打包后创建
bundler的文件路径以及文件名; - Module: 模块,在
Webpack中任何文件都可以作为一个模块,会根据配置的不同的Loader进行加载和打包; - Chunk: 代码块,可以根据配置,将所有模块代码合并成一个或多个代码块,以便按需加载,提高性能;
- Loader: 模块加载器,进行各种文件类型的加载与转换;
- Plugin: 拓展插件,可以通过
Webpack相应的事件钩子,介入到打包过程中的任意环节,从而对代码按需修改;
1.2 工作流程 (加载 - 编译 - 输出)
- 读取配置文件,按命令 初始化 配置参数,创建
Compiler对象; - 调用插件的
apply方法 挂载插件 监听,然后从入口文件开始执行编译; - 按文件类型,调用相应的
Loader对模块进行 编译,并在合适的时机点触发对应的事件,调用Plugin执行,最后再根据模块 依赖查找 到所依赖的模块,递归执行第三步; - 将编译后的所有代码包装成一个个代码块 (
Chunk), 并按依赖和配置确定 输出内容。这个步骤,仍然可以通过Plugin进行文件的修改; - 最后,根据
Output把文件内容一一写入到指定的文件夹中,完成整个过程;
1.3 模块包装
(function(modules) {
// 模拟 require 函数,从内存中加载模块;
function __webpack_require__(moduleId) {
// 缓存模块
if (installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// 执行代码;
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag: 标记是否加载完成;
module.l = true;
return module.exports;
}
// ...
// 开始执行加载入口文件;
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})({
"./src/index.js": function (module, __webpack_exports__, __webpack_require__) {
// 使用 eval 执行编译后的代码;
// 继续递归引用模块内部依赖;
// 实际情况并不是使用模板字符串,这里是为了代码的可读性;
eval(`
__webpack_require__.r(__webpack_exports__);
//
var _test__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("test", ./src/test.js");
`);
},
"./src/test.js": function (module, __webpack_exports__, __webpack_require__) {
// ...
},
})
总结:
- 模块机制:
webpack自己实现了一套模拟模块的机制,将其包裹于业务代码的外部,从而提供了一套模块机制; - 文件编译:
webpack规定了一套编译规则,通过Loader和Plugin,以管道的形式对文件字符串进行处理;
1.4 webpack的打包原理
初始化参数:从配置文件和Shell语句中读取与合并参数,得出最终的参数开始编译:用上一步得到的参数初始化Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译确定入口:根据配置中的entry找出所有的入口文件编译模块:从入口文件出发,调用所有配置的Loader对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理完成模块编译:在经过第4步使用Loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的Chunk,再把每个Chunk转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
1.5 webpack的打包原理详细
相关问题
webpack工作流程是怎样的webpack在不同阶段做了什么事情
webpack 是一种模块打包工具,可以将各类型的资源,例如图片、CSS、JS 等,转译组合为 JS 格式的 bundle 文件
webpack 构建的核心任务是完成内容转化和资源合并。主要包含以下 3 个阶段:
- 初始化阶段
- 初始化参数:从配置文件、配置对象和 Shell 参数中读取并与默认参数进行合并,组合成最终使用的参数
- 创建编译对象:用上一步得到的参数创建
Compiler对象。 - 初始化编译环境:包括注入内置插件、注册各种模块工厂、初始化
RuleSet集合、加载配置的插件等
- 构建阶段
- 开始编译:执行
Compiler对象的run方法,创建Compilation对象。 - 确认编译入口:进入
entryOption阶段,读取配置的Entries,递归遍历所有的入口文件,调用Compilation.addEntry将入口文件转换为 Dependency 对象。 - 编译模块(make): 调用
normalModule中的build开启构建,从entry文件开始,调用loader对模块进行转译处理,然后调用 JS 解释器(acorn)将内容转化为AST对象,然后递归分析依赖,依次处理全部文件。 - 完成模块编译:在上一步处理好所有模块后,得到模块编译产物和依赖关系图
- 生成阶段
- 输出资源(seal):根据入口和模块之间的依赖关系,组装成多个包含多个模块的
Chunk,再把每个Chunk转换成一个Asset加入到输出列表,这步是可以修改输出内容的最后机会。 - 写入文件系统(emitAssets):确定好输出内容后,根据配置的
output将内容写入文件系统
知识点深入
1. webpack 初始化过程
从 webpack 项目 webpack.config.js 文件 webpack 方法出发,可以看到初始化过程如下:
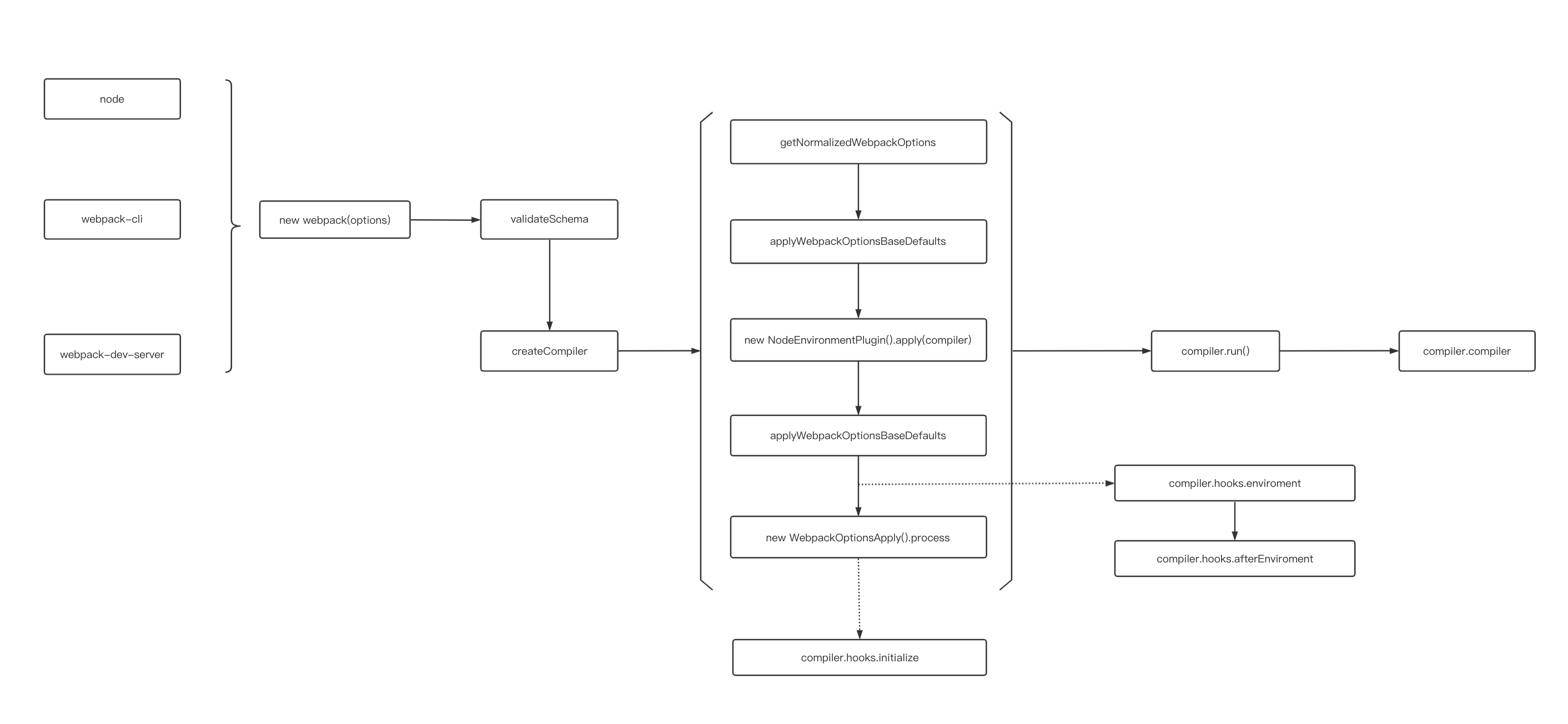
- 将命令行参数和用户的配置文件进行合并
- 调用
getValidateSchema对配置进行校验 - 调用
createCompiler创建Compiler对象- 将用户配置和默认配置进行合并处理
- 实例化
Compiler - 实例化
NodeEnvironmentPlugin - 处理用户配置的
plugins,执行plugin的apply方法。 - 触发
environment和afterEnvironment上注册的事件。 - 注册
webpack内部插件。 - 触发
initialize事件
// lib/webpack.js 122 行 部分代码省略处理
const create = () => {
if (!webpackOptionsSchemaCheck(options)) {
// 校验参数
getValidateSchema()(webpackOptionsSchema, options);
}
// 创建 compiler 对象
compiler = createCompiler(webpackOptions);
};
// lib/webpack.js 57 行
const createCompiler = (rawOptions) => {
// 统一合并处理参数
const options = getNormalizedWebpackOptions(rawOptions);
applyWebpackOptionsBaseDefaults(options);
// 实例化 compiler
const compiler = new Compiler(options.context);
// 把 options 挂载到对象上
compiler.options = options;
// NodeEnvironmentPlugin 是对 fs 模块的封装,用来处理文件输入输出等
new NodeEnvironmentPlugin({
infrastructureLogging: options.infrastructureLogging,
}).apply(compiler);
// 注册用户配置插件
if (Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === "function") {
plugin.call(compiler, compiler);
} else {
plugin.apply(compiler);
}
}
}
applyWebpackOptionsDefaults(options);
// 触发 environment 和 afterEnvironment 上注册的事件
compiler.hooks.environment.call();
compiler.hooks.afterEnvironment.call();
// 注册 webpack 内置插件
new WebpackOptionsApply().process(options, compiler);
compiler.hooks.initialize.call();
return compiler;
};
2. webpack 构建阶段做了什么
在 webpack 函数执行完之后,就到主要的构建阶段,首先执行 compiler.run(),然后触发一系列钩子函数,执行 compiler.compile()
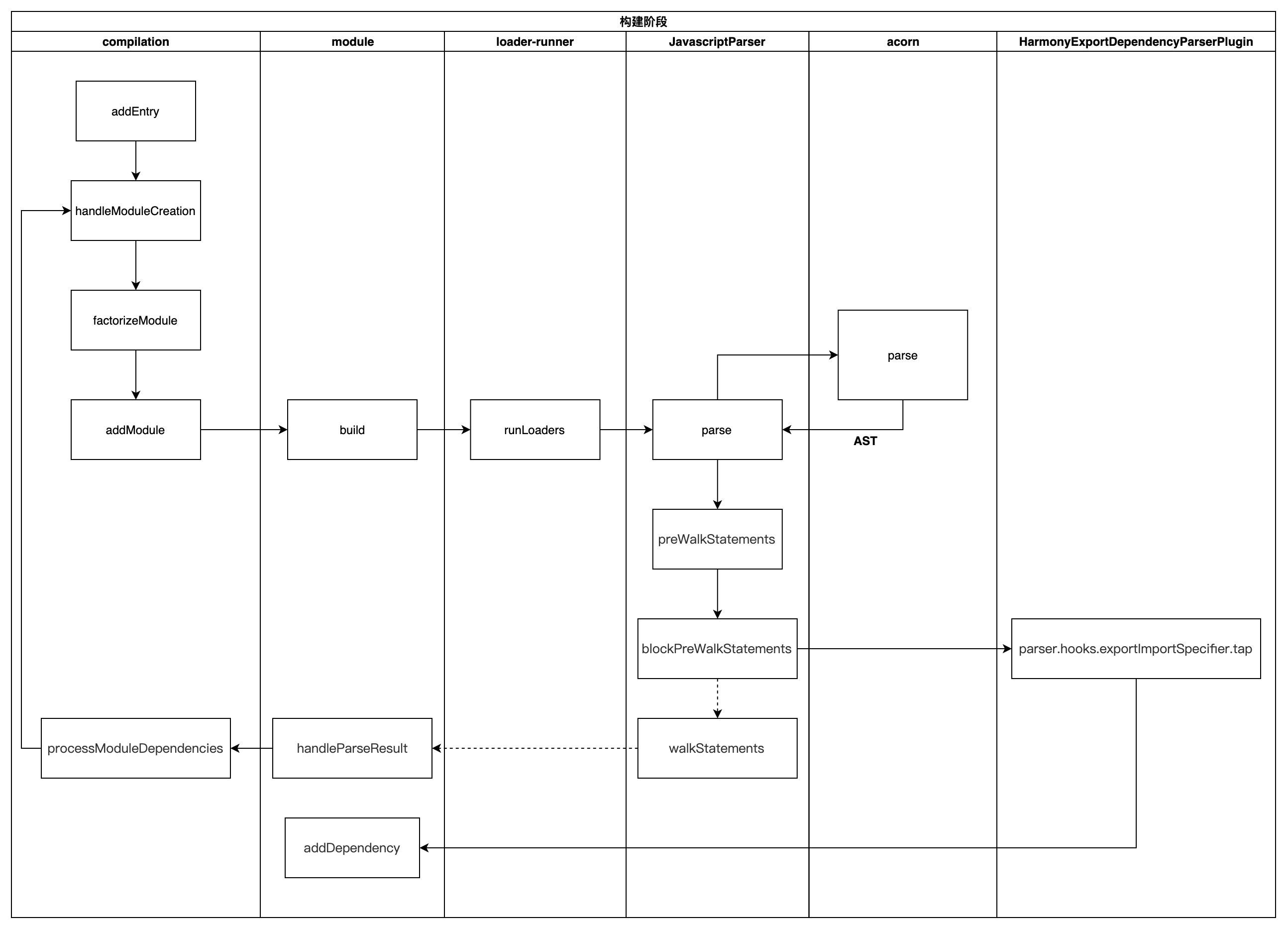
- 在实例化
compiler之后,执行compiler.run() - 执行
newCompilation函数,调用createCompilation初始化Compilation对象 - 执行
_addEntryItem将入口文件存入this.entries(map对象),遍历this.entries对象构建chunk。 - 执行
handleModuleCreation,开始创建模块实例。 - 执行
moduleFactory.create创建模块- 执行
factory.hooks.factorize.call钩子,然后会调用ExternalModuleFactoryPlugin中注册的钩子,用于配置外部文件的模块加载方式 - 使用
enhanced-resolve解析模块和loader的真实绝对路径 - 执行
new NormalModule()创建module实例
- 执行
- 执行
addModule,存储module - 执行
buildModule,添加模块到模块队列buildQueue,开始构建模块, 这里会调用normalModule中的build开启构建- 创建
loader上下文。 - 执行
runLoaders,通过enhanced-resolve解析得到的模块和loader的路径获取函数,执行loader。 - 生成模块的
hash
- 创建
- 所有依赖都解析完毕后,构建阶段结束
// 构建过程涉及流程比较复杂,代码会做省略
// lib/webpack.js 1284行
// 开启编译流程
compiler.run((err, stats) => {
compiler.close(err2 => {
callback(err || err2, stats);
});
});
// lib/compiler.js 1081行
// 开启编译流程
compile(callback) {
const params = this.newCompilationParams();
// 创建 Compilation 对象
const Compilation = this.newCompilation(params);
}
// lib/Compilation.js 1865行
// 确认入口文件
addEntry() {
this._addEntryItem();
}
// lib/Compilation.js 1834行
// 开始创建模块流程,创建模块实例
addModuleTree() {
this.handleModuleCreation()
}
// lib/Compilation.js 1548行
// 开始创建模块流程,创建模块实例
handleModuleCreation() {
this.factorizeModule()
}
// lib/Compilation.js 1712行
// 添加到创建模块队列,执行创建模块
factorizeModule(options, callback) {
this.factorizeQueue.add(options, callback);
}
// lib/Compilation.js 1834行
// 保存需要构建模块
_addModule(module, callback) {
this.modules.add(module);
}
// lib/Compilation.js 1284行
// 添加模块进模块编译队列,开始编译
buildModule(module, callback) {
this.buildQueue.add(module, callback);
}
3. webpack 生成阶段做了什么
构建阶段围绕
module展开,生成阶段则围绕chunks展开。经过构建阶段之后,webpack 得到足够的模块内容与模块关系信息,之后通过Compilation.seal函数生成最终资源
3.1 生成产物
执行 Compilation.seal 进行产物的封装
- 构建本次编译的
ChunkGraph对象,执行buildChunkGraph,这里会将import()、require.ensure等方法生成的动态模块添加到chunks中 - 遍历
Compilation.modules集合,将module按entry/动态引入 的规则分配给不同的Chunk对象。 - 调用
Compilation.emitAssets方法将assets信息记录到Compilation.assets对象中。 - 执行
hooks.optimizeChunkModules的钩子,这里开始进行代码生成和封装。- 执行一系列钩子函数(
reviveModules,moduleId,optimizeChunkIds等) - 执行
createModuleHashes更新模块hash - 执行
JavascriptGenerator生成模块代码,这里会遍历modules,创建构建任务,循环使用JavascriptGenerator构建代码,这时会将import等模块引入方式替换为webpack_require等,并将生成结果存入缓存 - 执行
processRuntimeRequirements,根据生成的内容所使用到的webpack_require的函数,添加对应的代码 - 执行
createHash创建chunk的hash - 执行
clearAssets清除chunk的files和auxiliary,这里缓存的是生成的chunk的文件名,主要是清除上次构建产生的废弃内容
- 执行一系列钩子函数(
3.2 文件输出
回到 Compiler 的流程中,执行 onCompiled 回调。
- 触发
shouldEmit钩子函数,这里是最后能优化产物的钩子。 - 遍历
module集合,根据entry配置及引入资源的方式,将module分配到不同的chunk。 - 遍历
chunk集合,调用Compilation.emitAsset方法标记chunk的输出规则,即转化为assets集合。 - 写入本地文件,用的是 webpack 函数执行时初始化的文件流工具。
- 执行
done钩子函数,这里会执行compiler.run()的回调,再执行compiler.close(),然后执行持久化存储(前提是使用的filesystem缓存模式)
1.6 总结
- 初始化参数:从配置文件和
Shell语句中读取并合并参数,得出最终的配置参数。 - 开始编译:从上一步得到的参数初始化
Compiler对象,加载所有配置的插件,执行对象的run方法开始执行编译。 - 确定入口:根scope据配置中的
entry找出所有的入口文件。 - 编译模块:从入口文件出发,调用所有配置的
loader对模块进行翻译,再找出该模块依赖的模块,这个步骤是递归执行的,直至所有入口依赖的模块文件都经过本步骤的处理。 - 完成模块编译:经过第
4步使用loader翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系。 - 输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的
chunk,再把每个chunk转换成一个单独的文件加入到输出列表,这一步是可以修改输出内容的最后机会。 - 输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。