PostgreSQL维护——解决索引膨胀和数据死行
注意: 本文内容于 2024-09-16 00:40:33 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:PostgreSQL维护——解决索引膨胀和数据死行。感谢您的关注与支持!
我有一张表,为了保障查询的快速响应,我是在必要的字段上建立了索引。该表的数量基数不变,只是每分钟会更新过来一批数据,如此运行了一年之久,目前即使走索引查询,依旧特别慢。
排查主要是由两个现象导致的。
- 索引膨胀
- 数据死行
这两个现象是如何出现的呢?频繁的进行insert/update/delete就会出现。
一、复现
下面来简单复现一下。
复现步骤
- 创建新表、关闭自动vacuum。vacuum如果开启,就会导致死行问题不复现。
- 录入样本数据、并创建索引,默认采用btree。我设置的样本数据为2000行。
- 执行insert/update/delete操作,执行10000次,并保持最后的数据总量仍然为2000条。
- insert && delete:删除的数据作为新数据插入
- update:更新其他数据字段
- 分别比较执行前与执行后的索引总量、死行数量。
以上复现步骤,我已经编写了一套脚本。开箱即用。
脚本地址
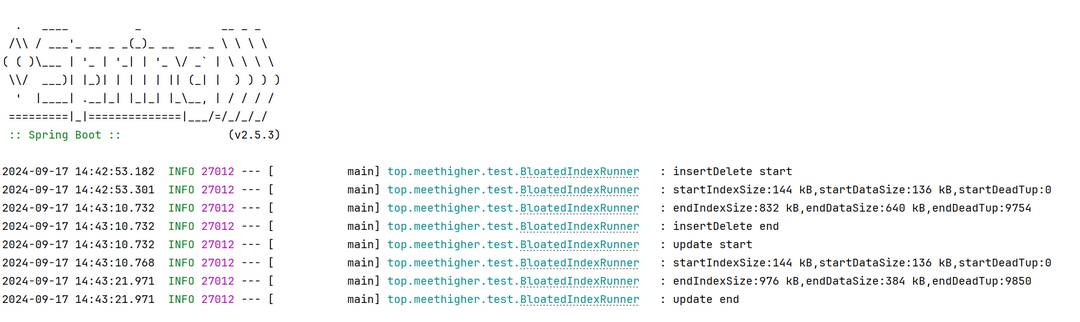
取其中一套运行结果,如下
| 大小/操作阶段 | insert && delete 前 | insert && delete 后 | update 前 | update 后 |
|---|---|---|---|---|
| 索引 | 144KB | 832KB | 144KB | 976KB |
| 数据 | 136KB | 640KB | 136KB | 384KB |
| 死行 | 0行 | 9754行 | 0行 | 9850行 |
2000条数据在频繁进行insert/delete/update之后,就会导致索引异常膨胀,是原数据大小的几倍之多。即使数据的总数未变,占用的数据空间仍然变大,因为数据死行导致的。
这两个问题,都会直接或者间接影响到数据库的查询速率。如果
二、临时解决方案
数据死行与索引膨胀,根源在于PostgreSQL的MVCC(Multi-Version Concurrency Control),有兴趣可以查阅官方文档。
2.1 数据死行
在 PostgreSQL 中,UPDATE 操作不会直接修改原有行,而是生成一条新的行记录,同时将原有行标记为“死行”,但并不会立即删除它。类似于 UPDATE,DELETE 操作不会立即删除数据行,而是将其标记为“死行”,并等待后续的 VACUUM 操作来真正回收空间。因此,频繁的 DELETE 操作也会导致死行积累。
临时解决方式:vaccum
VACUUM 是 PostgreSQL 中的垃圾收集机制,用于回收那些不再使用的“死”行空间,但不会释放表文件大小。它会标记那些不再使用的行,可以被新数据覆盖,操作过程中不会锁表。
-- vacuum整个库
vacuum;
-- vacuum单个表
vacuum 表名;
其中涉及到的查询死行的SQL如下
select n_dead_tup from pg_stat_user_tables where n_dead_tup>0 and relname='test_data';
2.2 索引膨胀
在 PostgreSQL 中,每次执行 UPDATE 或 DELETE 操作时,并不会直接修改或删除原有的记录。
相反,旧的版本(元组)会被标记为“死行”,而新的数据将作为一个新的行版本插入表中。
对于索引字段,原有的索引条目不会立即被删除,而是新建一个指向新数据的索引条目。因此,频繁的 UPDATE 和 DELETE 会导致索引包含大量的过时条目,引发索引膨胀、查询效率降低。
临时解决方式:重建索引
最简单的方式是先删再增。
比较方便的方式是reindex,但是该方式会在重建的过程中锁表。
reindex table 表名;
reindex index 索引名;
自从PostgreSQL12开始,reindex支持并行重建索引,不会锁表,但比直接reindex要慢。
reindex table concurrently 表名;
reindex index concurrently 索引名;
其中涉及到的一些查询索引大小的SQL如下
-- 查询表内总数据大小
select pg_table_size('test_data'),pg_size_pretty(pg_table_size('test_data'));
-- 查询表内总索引大小
select pg_indexes_size('test_data'),pg_size_pretty(pg_indexes_size('test_data'));
-- 查询表的总大小,包含数据和索引
select pg_total_relation_size('test_data'),pg_size_pretty(pg_total_relation_size('test_data'));
三、设计层面规避该问题
单表数据量大,创建索引来加速查询效率,同时又要进行增删改数据。使用单表的做法在短时间内,是个轻量快速的好做法,适合敏捷式开发。但是长时间来看,还需要经常的人工维护,或者配置数据库的定时清理机制(又会存在锁表等问题),这并不好。
在大型项目上,以上做法就不太适合了。因此在设计上,可以做读写分离,实现一劳永逸。
-
专门的写表,不创建索引,用来快速增删改。
-
专门的读表,创建索引,用来快速查询。读表数据来源于写表,这之间需要设计一套适应当前需求的同步机制。
这套同步机制,根据我当前的需求,主要有两种同步方式。
- 批量增量同步:程序上定期将写表中增量的数据,一次性批量更新到读表。周期根据需求设定。
- 全量同步:读表增量同步也会存在膨胀的问题,因此可以定期的将备份一张新的全量读表,替换掉原来的读表。
在PostgreSQL中,如果数据量不是特别大,读表不需要单独建表去维护,直接使用物理视图即可,根据周期定时刷新。
物理视图跟逻辑视图的区别
逻辑视图需要在查询视图时,根据视图逻辑实时查询,与原数据表相比不存在数据差异性问题。
物理视图相当于创建了一张临时表并存储到了磁盘,不会自动更新,需要人工维护。
举例物理视图用法
-- 重建物理视图
drop materialized view if exists view_name;
create materialized view view_name AS
select * from test_data;
-- 锁表更新物理视图
refresh materialized view view_name;
-- 并行更新物理视图,首先需要物理视图有唯一键
create unique index unique_id_index ON view_name (id);
refresh materialized view concurrently view_name;