Django学习实战篇六(适合略有基础的新手小白学习)(从0开发项目)
前言:
上一章中,我们完成了页面样式的配置,让之前简陋的页面变得漂亮了些。
整理一下目前已经完成的系统,从界面上看,已经完成了以下页面:
- 首页
- 分类列表页
- 标签列表页口博文详情页
这离我们的需求还有些距离,还差几个页面:
- 搜索结果页
- 作者列表页
- 侧边栏的热门文章
- 文章访问统计
- 友情链接页面
- 评论模块
在这一节中,我们来完善剩下的页面。有了前面的基础结构,增加新的页面十分简单。Let’s do it!
第六章:完成整个博客系统
6.1 增加搜索和作者过滤
按照惯例,在看到新的需求时(我们可以把这个假想为产品经理新抛过来的需求),首先要明确需求的本质是什么,以及这个需求跟之前实现的功能有何关联。
这一节中,我们需要做的是两个需求:根据关键词搜索文章和展示指定作者的文章列表。这两个需求跟之前已经完成的首页、分类列表页和标签列表页属于同一类页面,它们做的事情都是根据某种条件过滤文章。
基于之前已经写好的class-basedview,很容易就可以完成这一需求。
6.1.1 增加搜索功能
我们先来看搜索功能,根据关键字搜索对应文章。我们在最早的需求分析中已经提到了,搜索需求是一个模糊的需求,那么更明确的需求应该根据哪些数据来搜索,是标题、内容,还是分类?
这里可以根据title和desc(标题和摘要)搜索,这样的话需要怎么做呢?
其实现很简单,依然需要继承IndexView。根据我们的分析,只需控制好数据源就行了。而在IndexView中,控制数据源的部分由get_queryset 方法实现。
因此,我们在blog/views.py中新增如下代码:
# blog/views.py
from django.db.models import Q #这一句放到文件的第一行
# 省略其他代码
class SearchView(IndexView):
def get_context_data(self):
context = super().get_context_data()
context.update({
'keyword': self.request.GET.get('keyword', '')
})
return context
def get_queryset(self):
queryset = super().get_queryset()
keyword = self.request.GET.get('keyword')
if not keyword:
return queryset
return queryset.filter(Q(title__icontains=keyword) | Q(desc__icontains=keyword))
其主要逻辑是重写数据源,但是对于搜索来说,我们还需要将用户输入的关键词展示在输入框中。
在上面的代码中,我们引入了新的内容Q,这是Django 提供的条件表达式(conditional-expression),用来完成复杂的操作。这在前面的Model部分也介绍过,这里不做过多解释。我们只需要知道,通过Q表达式实现了类似这样的SQL语句:SELECT * FROM post WHERE title LIKE '%<keyword>%' or desc ILIKE '%<keyword>%'。
可以看到,上面的代码跟之前写的没有太大区别,只需要控制数据源,控制context 的内容就能完成类似需求。
接着配置urls.py,在url中引人Searchview,然后将下面代码增加到urlpatterns 配置中。
path('search/', SearchView.as_view(), name='search'),
接下来,需要做的就是修改搜索部分的模板。在上一章中,我们只关注样式,并未关注搜索功能部分。现在修改搜索部分的模板,只需要把base.html中nav中的form部分(原来代码如下:)
<!-- base.html -->
<form class="form-inline my-2 my-lg-0" method='GET'>
<input class="form-control mr-sm-2" type="search" placeholder="Search" aria-label="Search">
<button class="btn btn-outline-success" type="submit">搜索</button>
</form>
修改为:
<form class="form-inline" action='/search/' method='GET'>
<input class="form-control" type="search" name="keyword" placeholder="对文章标题或摘要进行搜索"
aria-label="Search" value="{{ keyword }}">
<button class="btn btn-outline-success" type="submit">搜索</button>
</form>
form 的作用是提交数据到服务端。action 用来指定提交数据到哪个URL上,这既可以是相对路径,也可以是绝对路径。methoa用来指定以哪种方法发数据,是GET还是POST。这里可以对比一下之前介绍的class-based view的处理逻辑。
在提交数据时,form中input 标签的内容会被发送到服务端。类型为submit的标签是用来完成数据提交的按钮,它可以是input 标签或者是button标签。
6.1.2 增加作者页面
有了上面的逻辑,作者页面的处理就更加容易了。你其实可以不看这部分而自行完成需求。在blog/views.py中增加下面的代码:
# blog/views.py
# 省略其他代码
class AuthorView(IndexView):
def get_queryset(self):
queryset = super().get_queryset()
author_id = self.kwargs.get('owner_id')
return queryset.filter(owner_id=author_id)
相对于搜索来说,只需控制数据源。如果需要调整展示的逻辑,可以通过重写get_context_data 来完成。
接下来,还要修改urls.py,引入新增加的AuthorView,然后在urlpatterns中增加新的规则:
path('author/<int:owner_id>', AuthorView.as_view(), name='author'),
这么配置完成后,重新启动程序,看看最终结果。

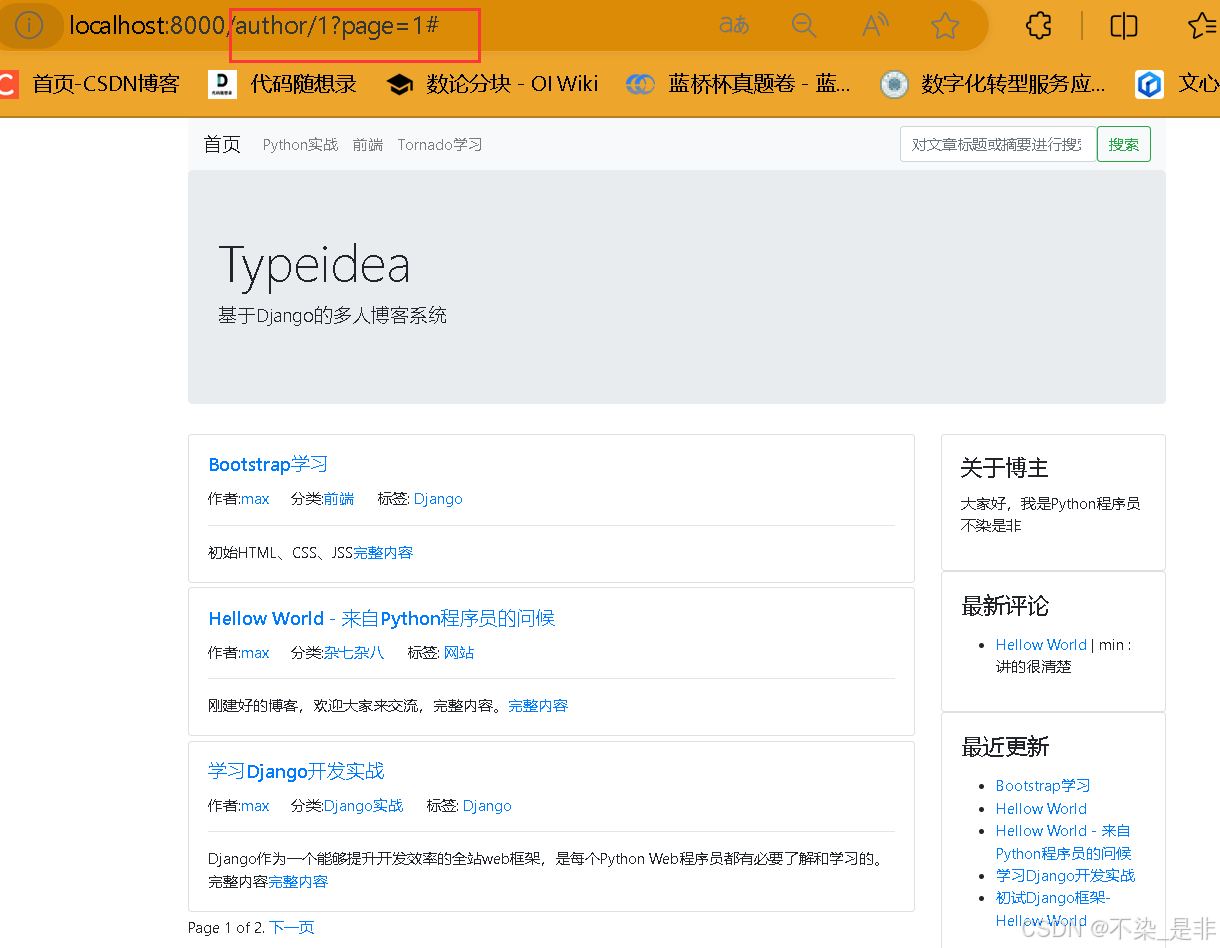
6.1.3 总结
到此,我们就完成了搜索页面和作者页面。不过上一章还有些遗留内容,那就是模板中需要渲染为作者链接的部分,前面并未做处理,你可以自行处理。
6.2 增加友链页面
上一节的篇幅很短,这主要是因为基于已经完成的代码,只需要直接复用已有的代码就可以实现大部分功能。在日常开发中也是如此,如果之前的基础结构设计合理,后续开发会非常容易,反之,开发每一个新功能都会很“痛苦”。
这一节中,我们需要做一个独立的功能,跟文章没关系,是用来展示友情链接的。在博客世界中,各博主相互交换友链是一种很常见的方式。通过这种方式,我们可以结识很多朋友。你可以把这个理解为现在相互加QQ或者微信。友链的另外一个作用是可以帮各位博主把自己的博客都串联起来,而避免成为“网络孤岛”。
前面已经把Model写好了,后台录入内容的部分是可以用的,这里只需要把数据拿出来展示即可。处理逻辑跟之前一样,我们只需要继承ListView即可,但要基于同一套模板,因此共用的数据还是需要的,所以也要同时继承CommonViewMixin。
config/views.py 中的代码如下:
# config/views.py
from django.views.generic import ListView
from blog.views import CommonViewMixin
from .models import Link
class LinkListView(CommonViewMixin, ListView):
queryset = Link.objects.filter(status=Link.STATUS_NORMAL)
template_name = 'config/links.html'
context_object_name = 'link_list'
接着修改 urls.py:
urlpatterns =[
#省略其他代码
path('links/', LinkListView.as_view(), name='links'),
]
然后新增模板config/links.html:
{% extends "blog/base.html" %}
{% block title %}友情链接{% endblock %}
{% block main %}
<table class="table">
<thead>
<tr>
<th scope="col">#</th>
<th scope="col">名称</th>
<th scope="col">网址</th>
</tr>
</thead>
<tbody>
{% for link in link_list %}
<tr>
<th scope="row">{{ forloop.counter }}</th>
<td>{{ link.title }}</td>
<td><a href="{{ link.href }}">{{ link.href }}</a></td>
</tr>
{% endfor %}
</tbody>
</table>
{% endblock %}
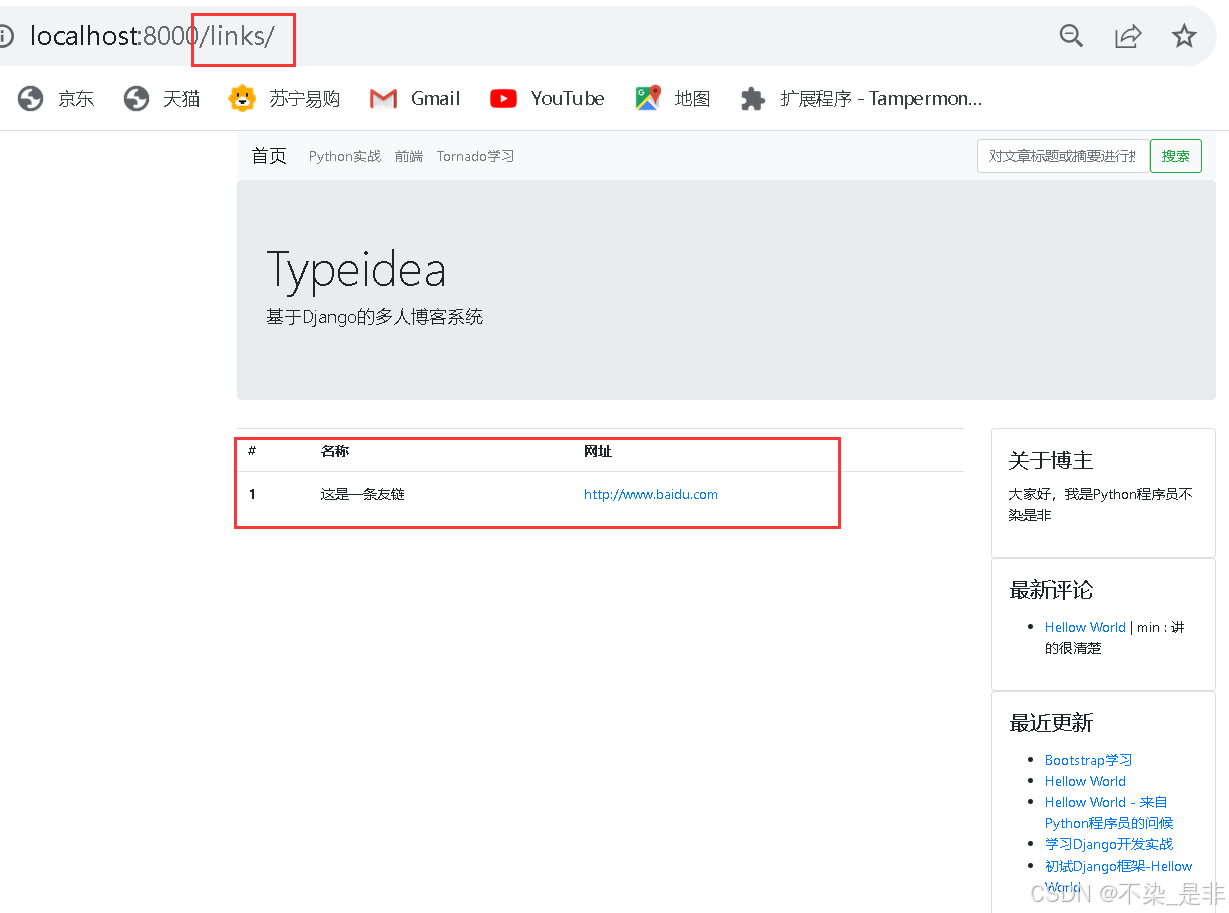
模板同样继承自blog/base.html,这可以保证整体风格一致。在友情链接模板中,我们通过表格的样式来展示友链。
写完这些代码之后,友情链接的展示页面就出来了。此外,还需要做的是提供一个友情链接申请页面,这个我们放到后面的评论中来做。
6.3 增加评论模块
评论是网站重要的功能之一,这一节中我们就来添加该功能。
如果把博客(网站)比作一个装在盒子里的系统,我们之前完成的admin后台就是用来给系统输入数据的,这些数据是内部数据。而最近这几章在做的事情其实是输出(展示)内部数据。评论则是提供给用户的输入接口,让用户能够把数据输入到系统中。
6.3.1 评论提交的方式
从我的经验来说,网站评论的实现方式有以下几种:
- JavaScript异步提交数据
- 当页提交
- 单独页面提交
后面两个其实是一类,只是在不同的页面完成数据提交而已,差别在于是否有独立的URL和View。
第一种是比较流行的方式,基于前端的交互完成评论的提交。这样就可以在不刷新页面的情况下提交数据并展示数据,避免了无效的页面请求。如果是大型网站,建议采用这种方式。
这几种方法在后端实现上没有本质的区别。就像前面我说到网站的输出格式既可以是HTML,也可以是JSON,只是展示形式不同,这里也一样,只是接收到的数据格式不同。
这里我们使用最后一种:单独页面提交。
6.3.2 评论模块通用化改造
在开发评论功能之前,我们需要做一件事,那就是增加评论的范围。上一节中我们说到,可以通过评论来完成友链的申请,这意味着可以在友情链接页面下增加评论内容的展示和提交。
而我们的模型设计是针对Post 对象的,因此需要稍作调整。具体调整逻辑有两种,我们可以对比一下差异,然后选择一个。
第一种方式是把Comment 中的target 改为CharField,里面存放着被评论内容的网址。就像很多其他社交化评论所做的那样,只需要有一个能够唯一标识当前页面地址的标记即可。但这种方式存在的问题是,在admin后台无法处理权限,因为是多用户系统,理论上只有文章的作者才能删除当前文章下的评论。
第二种方式是使用GenericForeignKey,这种方式值得一说。我们在前面知道Model中ForeignKey的作用一一关联两个模型(表),通过名字可以猜测GenericForeignkey 意味着更通用的外键,什么意思呢?通常来说,外键只能针对一个表(模型),但有时我们有针对多个表的需求。比方说,现在有一个Comment 模型,它能关联Post,同时也能关联Link(这里其实也是伪需求,但是不妨碍理解GenericForeignKey的用法)。
怎么做到关联多种模型呢?在解释之前,我们先来思考这个问题,在Django中,通过外键关联Model是怎么关联上的呢?答案是外键字段,比方说Post 模型中的category字段。这个字段是存储在Post上的,存储的内容是Category模型的主键(primary key,简称pk),这样在使用时,就可以通过这个主键找到跟当前Post 关联的category了。
所以,这是通过一个字段来存储指定模型的主键,那么这个模型能不能通过另外一种方式来
指定呢?因为在使用ForeignKey时,所指定的模型就已经固定了。
答案是可以通过增加一个字段content_type 来存储对应的模型类型,这里拿Comment来举例。在Comment 模型中,我们定义了 object_id来存储对应模型(表)的主键值,定义了content_type 来存储当前记录对应的是哪个模型(表)。这样,就可以动态存放数据,存放多种数据了。
用一个图来表示的话,详见下图。

从上图中可以一目了然地看到,如何通过多增加一个字段来实现通用外键。
但是这又新增了一个问题,那就是content_type 里面存放的字符串是由谁来定义并且写入的?总不能每新增一条数据,都要自己写入’link’或者’post’这样的字符串吧。因此,在Django中提供了一个这样的Model一一一 ContentType,用它来实现。如果你注意过settings中INSTALLED_APPS 里面的内容,就会发现存在一个这样的App一’django.contrib.contenttypes’,它的作用就是维护Model和我们要用到的content_type 之间的关系。
比方说,在ContentType 表里,Post 模型对应1,Link 模型对应2,那么在Comment中如果要写入一条post id为1的记录,那就是content_type =1,object_id = 1。
到这里,不知道你是否能明白上面的内容。简单来说,就是为了实现通用外键,需要多维护一个字段和一张表(模型)。既然Django 为我们提供了GenericForeignKey 这样的字段,那么肯定是把麻烦的操作都已经封装好了。不过在实际使用中,唯一的问题是,我们需要操作两个模型(表),这多少会对性能有些影响,因此我们往往会想办法自己来实现对应的逻辑。这其实也是基于通用性和特殊性之间的考虑,通用性能够得到更易用的逻辑,但是性能上会有损耗,而特殊性的处理逻辑在性能上会有一些优势,却降低了易用性。
具体的实现也比较清晰,因为实际的业务开发往往是很有针对性的,比如像上面,Comment既可以关联Post,也可以关联Link。因此,我们可以不使用Django提供的方法,毕竟它要做更通用的处理,会带来复杂度,我们只需要在代码中建立Model和对应的content_type 的映射即可。
第二种方式说了这么多,主要是为了解释通用外键这个字段类型,理解它能够帮助你更好地设计某些业务下的模型关系。
那么,选择哪一种呢?上面说的关于Comment 和Link的部分其实是伪需求,因为只需要对友链页面可以评论即可,不需要对每一条友链都进行评论。因此,我们可以采用第一种方法。如果确实需要处理评论部分的权限,我们可以在业务层来处理。简单来说,就是通过target中存储的path来处理来获取文章id,然后判断用户。
6.3.3 实现评论
理解了上面的两种方案以及选择之后,我们来修改模型。需要修改comment/models.py中target 的字段类型:
# comment/models.py
target = models.CharField(max_length=100, verbose_name='评论目标')
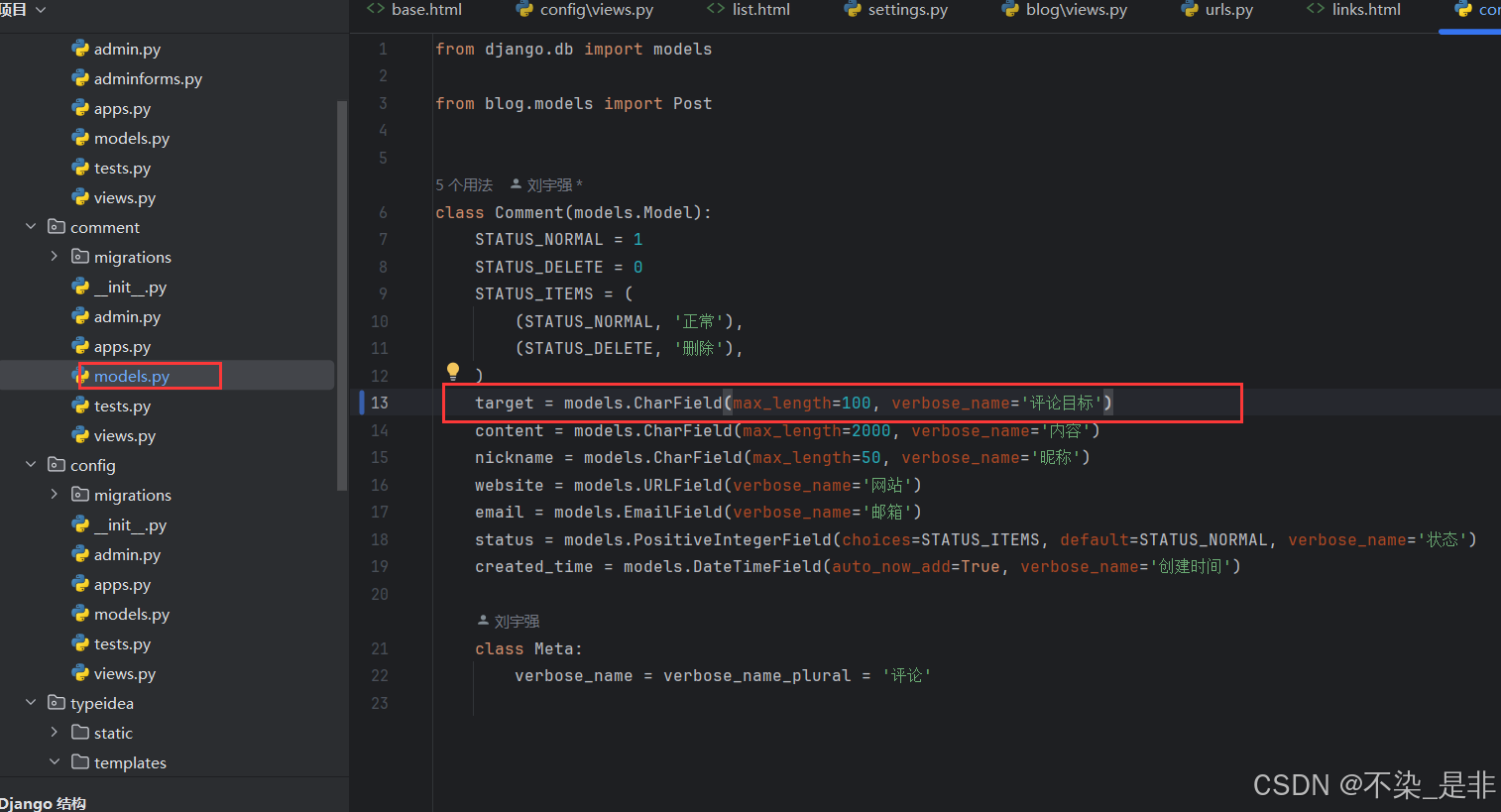
这样里面就可以存放任意字符了,也能兼容更多的场景。
前面我们讲过migrate的作用,这里需要再次使用它(在终端中输入):
python manage.py makemigrations
python manage.py migrate
完成字段修改之后,就可以开发评论功能了。
首先,我们需要在文章页面下方添加一个评论的form,这样用户才能添加评论。那么,这个form怎么处理呢?有两种方式,第一种是我们写原生的HTML代码,但这样无法利用Django的优势。第二是使用Django 的form,并且用它来渲染成HTML。
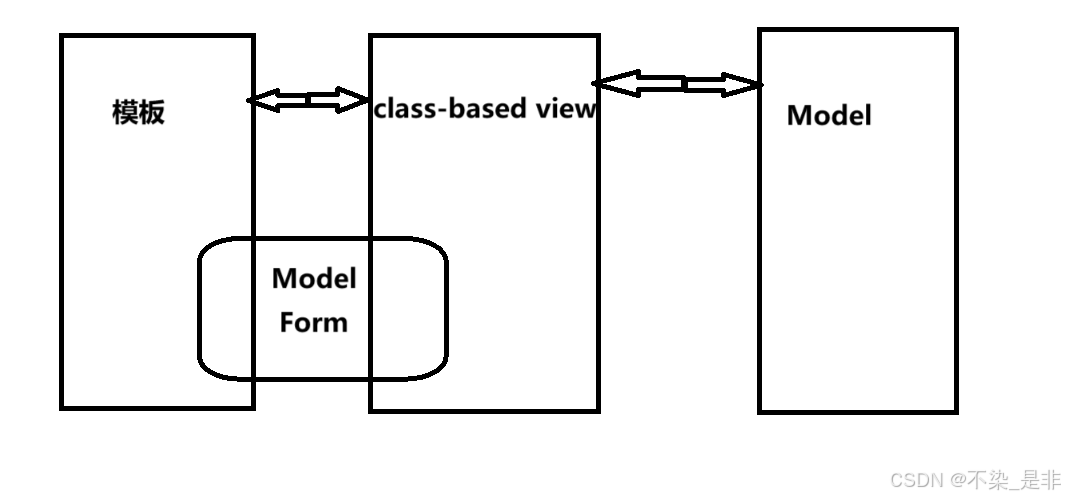
显然,我们应该使用第二种。下面来梳理一下这种方式的数据流程和所需组件。
下图表示了大体流程,我们再用文字说明具体要做的工作:
- 展示评论内容和评论框。
- 用户提交评论后,可以保存评论并且展示结果页。
展示评论显然需要在博文详情页来做,也就是PostDetailView中。不过在此之前,需要先完成Form 层的逻辑,毕竟 View需要操作Form,然后在模板中渲染Form。
我们在comment 这个 App下新建一个文件 forms.py,它用来放置 Form相关的代码。在其中增加评论的Form:
# comment/forms.py
from django import forms
from .models import Comment
class CommentForm(forms.ModelForm):
nickname = forms.CharField(
label='昵称',
max_length=50,
widget=forms.widgets.Input(
attrs={'class': 'form-control', 'style': "width: 60%;"}
)
)
email = forms.CharField(
label='Email',
max_length=50,
widget=forms.widgets.EmailInput(
attrs={'class': 'form-control', 'style': "width: 60%;"}
)
)
website = forms.CharField(
label='网站',
max_length=100,
widget=forms.widgets.URLInput(
attrs={'class': 'form-control', 'style': "width: 60%;"}
)
)
content = forms.CharField(
label="内容",
max_length=500,
widget=forms.widgets.Textarea(
attrs={'rows': 6, 'cols': 60, 'class': 'form-control'}
)
)
def clean_content(self):
content = self.cleaned_data.get('content')
if len(content) < 10:
raise forms.ValidationError('内容长度怎么能这么短呢!!')
return content
class Meta:
model = Comment
fields = ['nickname', 'email', 'website', 'content']
如果不考虑样式,只需要配置model和fields就行。但是为了样式,我们还要重新定义各字段的组件。自定义部分的内容不难理解,都是样式方面的。另外,我们要在代码中使用clean_content 方法(用来处理对应字段数据的方法)来控制评论的长度,如果内容太少,则直接抛出异常。
Form 定义完成之后,我们需要在Model层提供接口,用来返回某篇文章下的所有有效评论。
下面在comment/models.py中的Comment类中增加类方法:
# comment/models.py
from django.db import models
from blog.models import Post
class Comment(models.Model):
STATUS_NORMAL = 1
STATUS_DELETE = 0
STATUS_ITEMS = (
(STATUS_NORMAL, '正常'),
(STATUS_DELETE, '删除'),
)
target = models.CharField(max_length=100, verbose_name='评论目标')
# target = models.ForeignKey(Post, verbose_name='评论目标', on_delete=models.CASCADE) # 外键是Post中的id
aim = models.ForeignKey(Post, verbose_name='评论文章', on_delete=models.CASCADE)
content = models.CharField(max_length=2000, verbose_name='内容')
nickname = models.CharField(max_length=50, verbose_name='昵称')
website = models.URLField(verbose_name='网站')
email = models.EmailField(verbose_name='邮箱')
status = models.PositiveIntegerField(choices=STATUS_ITEMS, default=STATUS_NORMAL, verbose_name='状态')
created_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
class Meta:
verbose_name = verbose_name_plural = '评论'
# 新增代码如下!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
@classmethod
def get_by_target(cls, target):
return cls.objects.filter(target=target, status=cls.STATUS_NORMAL)
这些都完成之后,素材就准备好了,接下来需要通过 View 层把CommentForm 和评论的数据传递到模板层。我们需要在PostDetailview中重写get_context_data方法:
# blog/views.py
from comment.form import CommentForm
from comment.models import Comment
# 省略其他代码
class PostDetailView(CommonViewMixin, DetailView):
queryset = Post.objects.filter(status=Post.STATUS_NORMAL)
template_name = 'blog/detail.html'
context_object_name = 'post'
pk_url_kwarg = 'post_id'
# 新增代码如下!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context.update({
'comment_form': CommentForm,
'comment_list': Comment.get_by_target(self.request.path),
})
return context
# 省略其他代码
这样就可以在blog/detail.html 模板中拿到comment_form 和comment_list变量了,我们需要做的就是把它们渲染出来。
对于Form来说,渲染起来很简单,可以直接使用。列表的展示需要多写点代码。
我们需要在detail.html模板中增加代码
<!-- detail.html -->
{% extends "blog/base.html" %}
{% block title %} {{ post.title }} {% endblock %}
{% block main %}
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:<a href="{% url 'category-list' post.category_id %}">{{ post.category.name }}</a></span>
<span>作者:<a href="#">{{ post.owner.username }}</a></span>
<span>创建时间:{{ post.created_time }}</span>
</div>
<hr/>
<p>
{{ post.content }}
</p>
{% endif %}
<!-- 新增代码如下!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! -->
<hr/>
<div class="comment">
<form class="form-group" action="/comment/" method="POST">
{% csrf_token %}
<input name="target" type="hidden" value="{{ request.path }}"/>
{{ comment_form }}
<input type="submit" value="写好了!"/>
</form>
<!-- 评论列表 -->
<ul class="list-group">
{% for comment in comment_list %}
<li class="list-group-item">
<div class="nickname">
<a href="{{ comment.website }}">{{ comment.nickname }}</a>
<span>{{ comment.created_time }}</span>
</div>
<div class="comment-content">
{{ comment.connect }}
</div>
</li>
{% endfor %}
</ul>
</div>
<!-- !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! -->
{% endblock %}
启动项目,然后就能看到评论功能了。不过还不能提交评论。上面form标签中action定义为/comment/,这是一个新的URL。因此我们需要在comment/views.py中对应创建一个新的View。完整代码如下:
# comment/views.py
from django.shortcuts import redirect
from django.views.generic import TemplateView
from comment.form import CommentForm
class CommentView(TemplateView):
http_method_names = ['post']
template_name = 'comment/result.html'
def post(self, request, *args, **kwargs):
comment_form = CommentForm(request.POST) # 创建一个CommentForm实例,并使用POST请求中的数据填充它。
target = request.POST.get('target') # 从POST请求中获取target参数的值,这个值可能是一个URL,表示评论提交后要重定向到的页面。
if comment_form.is_valid(): # 检查表单数据是否有效。
instance = comment_form.save(commit=False) # 如果表单有效,保存表单数据到一个模型实例中,但不立即提交到数据库。
instance.target = target # 设置模型实例的target属性。
instance.save() # 将模型实例保存到数据库。
succeed = True # 设置succeed变量为True,表示评论提交成功。
return redirect(target) # 重定向到target指定的URL。
else:
succeed = False # 如果表单无效,设置succeed变量为False。
context = {
'succeed': succeed,
'form': comment_form,
'target': target,
}
return self.render_to_response(context) # 使用context中的数据渲染模板,并返回渲染后的页面。
这里直接使用TemplateView来完成,这个View 只提供了POST方法。其逻辑是通过CommentForm 来处理接收的数据,然后验证并保存。最后渲染评论结果页,如果中间有校验失败的部分,也会展示到评论结果页。
接下来,我们需要在typeidea/templates中创建comment目录,在新建好的comment目录下创建result.html文件,然后填入如下代码:
<!-- result.html -->
<!DOCTYPE HTML>
<html lang="en">
<head>
<title>评论结果页 - typeidea</title>
<style>
body {TEXT-ALIGN: center;}
.result {
text-align: center;
width: 40%;
margin: auto;
}
.errorlist {color: red;}
ul li {
list-style-type: None;
}
</style>
</head>
<body>
<div class="result">
{% if succeed %}
评论成功!
<a href="{{ target }}">返回</a>
{% else %}
<ul class="errorlist">
{% for field, message in form.errors.items %}
<li>{{ message }}</li>
{% endfor %}
</ul>
<a href="javascript:window.history.back();">返回</a>
{% endif %}
</div>
</body>
</html>
完成之后需要实现最后一步,那就是配置URL。在urlpatterns中增加新的规则:
from comment.views import CommentView
urlpatterns =[
#省略其他代码
path('comment/', CommentView.as_view(), name='comment'),
]
配置完成后,可以启动项目,添加一下评论。然后可以考虑改改其中的代码,比如希望评论完成后并不是实时展示的,而需要网站管理员审核通过之后才能展示。
6.3.4 抽象出评论模块组件和Mixin
上面的实现满足了基本功能,但是结构上不太合理,因为我们还需要在blog/views.py中来操作comment的数据。这意味着,如果要在友链页面上增加评论,也得去修改View层的代码。还记得之前说的“开-闭原则”吗?我们需要把评论弄成一个即插即用的组件。
要完成这个需求,就要用到Django的template tag(自定义标签)这部分接口了。可以先说下我们期待的使用方式:在任何需要添加评论的地方,我们只需要使用{% comment_block request.path %}即可。之所以叫comment_block,是因为comment 是Django内置的tag,用来做大块代码的注释。
在开始写代码之前,还是先来看一下Django中的tag。
在前面的模板代码中已经多次用到了,比如说 for 循环和if判断等,这些都是内置的,我们需要自定义tag。
这里就直接使用实际需求来代替演示吧,因为使用起来并不复杂。
第一步需要做的是在comment App下新建templatetags目录,同时在该目录下新增__init__.py和comment_block.py这两个文件。
第二步就是在comment_block.py文件中编写自定义标签的代码:
# comment_block.py
from django import template
from comment.forms import CommentForm
from comment.models import Comment
register = template.Library()
@register.inclusion_tag('comment/block.html')
def comment_block(target):
return {
'target': target,
'comment_form': CommentForm(),
'comment_list': Comment.get_by_target(target),
}
其实现并不复杂,其他类型的方法使用也不复杂。唯一需要注意的是目录结构,这跟静态文件的目录和模板目录一样,Django会进行自动查找,因此需要放到正确的位置。
上面的代码编写完成之后,就可以把PostDetailView 中新增的那个get_context_data去掉了,同时也可以去掉评论相关的引用了。
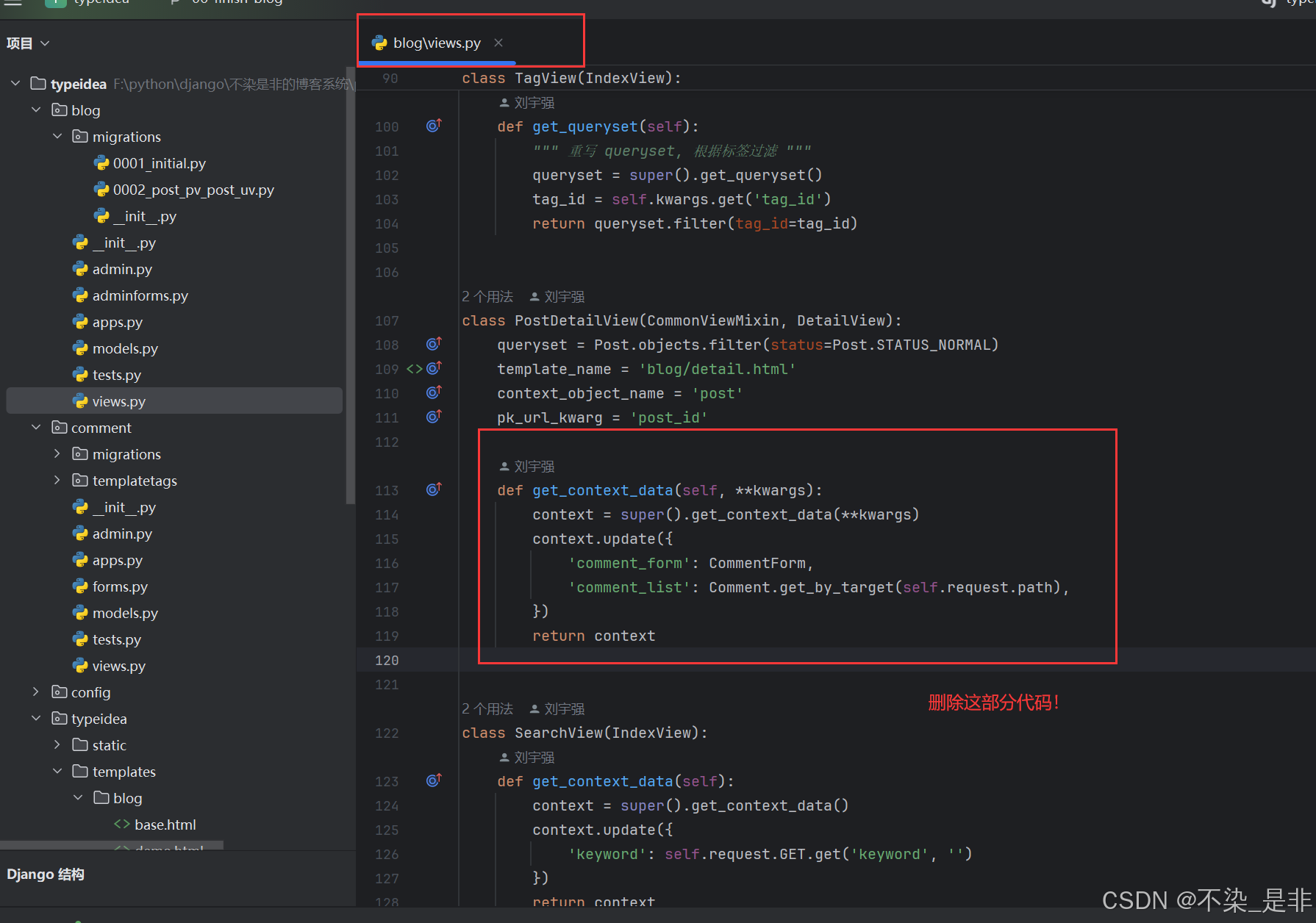
然后再删除blog/detail.html中的评论代码,修改后的的blog/detail.html代码如下:
<!-- blog/detail.html -->
{% extends "blog/base.html" %}
{% block title %} {{ post.title }} {% endblock %}
{% block main %}
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:<a href="{% url 'category-list' post.category_id %}">{{ post.category.name }}</a></span>
<span>作者:<a href="#">{{ post.owner.username }}</a></span>
<span>创建时间:{{ post.created_time }}</span>
</div>
<hr/>
<p>
{{ post.content_html }}
</p>
{% endif %}
{% endblock %}
接着编写模板,也就是上面用到的comment/block.html,这个模板里面的代码直接从blog/detail.html中剪切粘贴过来即可。唯一需要处理的是target部分,因为是自定义标签,默认是没有request对象的。所以上面手动将target 渲染到了页面中。comment/block.html中的完整代码如下:
<!-- comment/block.html -->
<hr/>
<div class="comment">
<form class="form-group" action="/comment/" method="POST">
{% csrf_token %}
<input name="target" type="hidden" value="{{ target }}"/>
{{ comment_form }}
<input type="submit" value="写好了!"/>
</form>
<!-- 评论列表 -->
<ul class="list-group">
{% for comment in comment_list %}
<li class="list-group-item">
<div class="nickname">
<a href="{{ comment.website }}">{{ comment.nickname }}</a> <span>{{ comment.created_time }}</span>
</div>
<div class="comment-content">
{{ comment.content }}
</div>
</li>
{% endfor %}
</ul>
</div>
编写完tag 和模板之后,我们的工作就完成了,现在在文章页面中可增加评论。
因为是自定义的tag,所以需要在config/links.html和blog/detial.html模板的最上面(但是需要在extends下面)增加{% load comment_block %},用来加载我们自定义的标签文件。
然后在需要展示评论的地方增加{% comment_block request.path %}即可。config/links.html代码如下:
<!-- config/links.html -->
{% extends "blog/base.html" %}
{% load comment_block %} <!-- 新增代码!!!!!!!!!!!!!! -->
{% block title %}友情链接{% endblock %}
{% block main %}
<table class="table">
<thead>
<tr>
<th scope="col">#</th>
<th scope="col">名称</th>
<th scope="col">网址</th>
</tr>
</thead>
<tbody>
{% for link in link_list %}
<tr>
<th scope="row">{{ forloop.counter }}</th>
<td>{{ link.title }}</td>
<td><a href="{{ link.href }}">{{ link.href }}</a></td>
</tr>
{% endfor %}
</tbody>
</table>
{% comment_block request.path %} <!-- 新增代码!!!!!!!!!!!!!! -->
{% endblock %}
blog/detial.html代码如下:
<!-- blog/detial.html -->
{% extends "blog/base.html" %}
{% load comment_block %} <!-- 新增代码!!!!!!!!!!!!!! -->
{% block title %} {{ post.title }} {% endblock %}
{% block main %}
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:<a href="{% url 'category-list' post.category_id %}">{{ post.category.name }}</a></span>
<span>作者:<a href="#">{{ post.owner.username }}</a></span>
<span>创建时间:{{ post.created_time }}</span>
</div>
<hr/>
<p>
{{ post.content_html }}
</p>
{% endif %}
{% comment_block request.path %} <!-- 新增代码!!!!!!!!!!!!!! -->
{% endblock %}
这里我们也可以在友链页面增加评论,它使用的是同样的逻辑。
6.3.5 修改最新评论模板
之前我们写过最新评论的模板,是基于外键关联Post的方式,现在修改为通用的方法。针对某个URL,我们需要修改config/sidebar_comments.html的代码为:
<!-- config/sidebar_comments.html -->
<ul>
{% for comment in comments %}
<li><a href="{{ comment.target }}">{{ comment.target.title }}</a> | {{ comment.nickname }} : {{ comment.content }}
{% endfor %}
</ul>
6.3.6 总结
到目前为止,我们完成了评论模块的改造,不过只采用了其中一种实现方式。你可以尝试其他实现方式,在实际工作中有些东西是可以通过技术来定,但很多东西还需要考虑场景和效果。
页面展示:
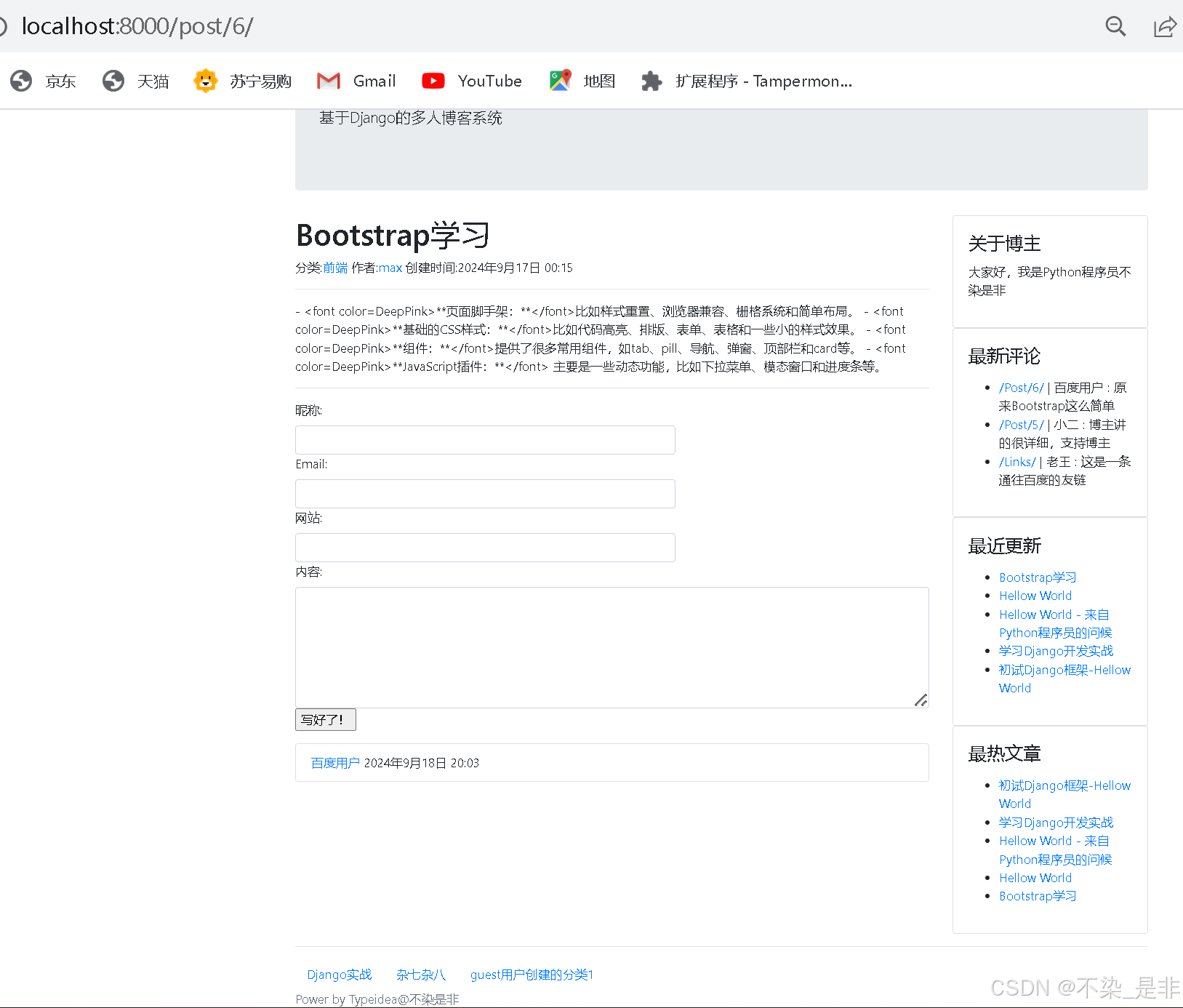
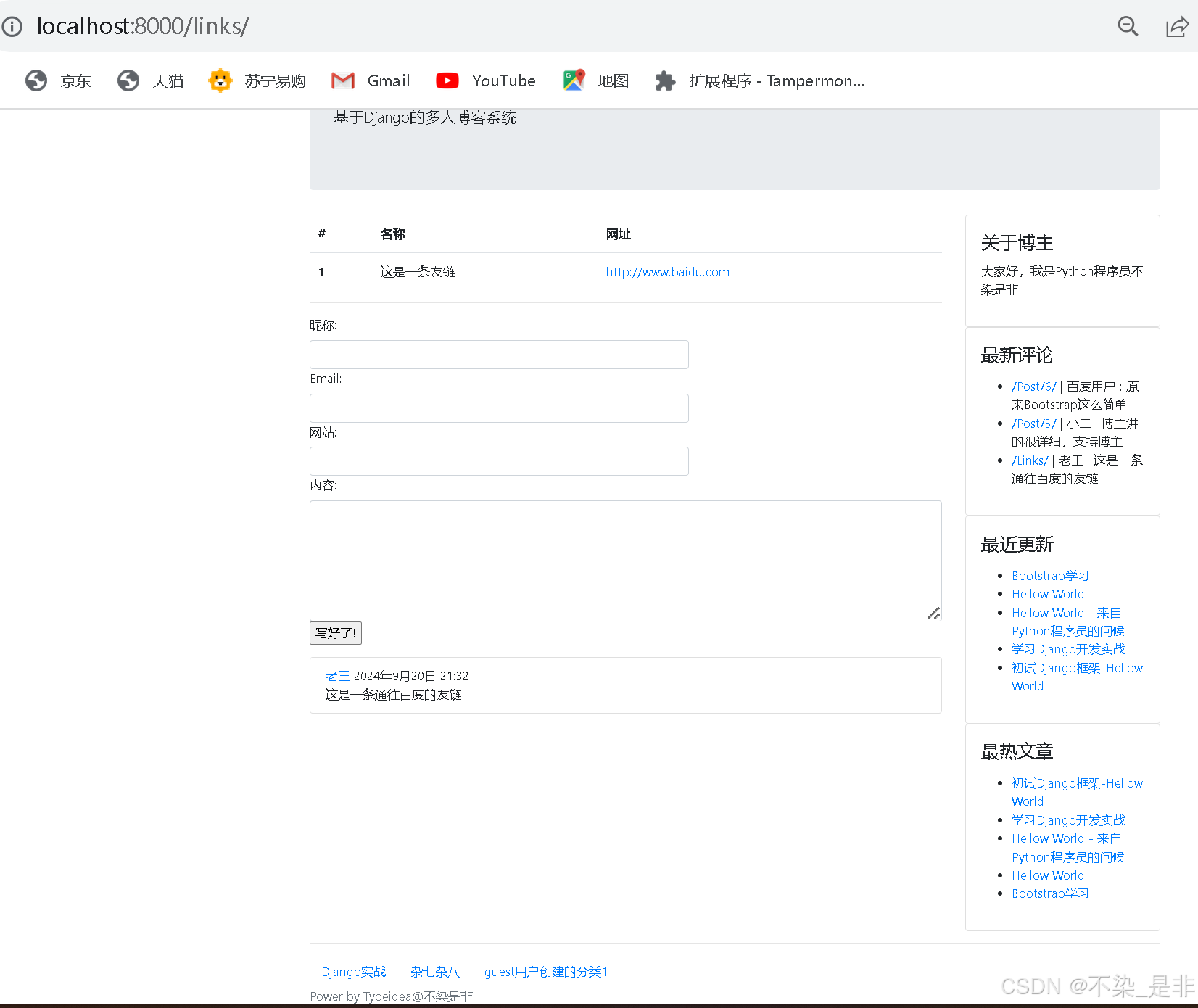
6.3.7 参考资料
Django CSRF 配置:
https://docs.djangoproject.com/zh-hans/4.2/ref/csrf/
Django Form 初始化:
https:/docs.djangoproject.com/zh-hans/4.2/ref/forms/api/#dynamic-initial-values
Django 模板:
https://docs.djangoproject.com/zh-hans/4.2/ref/templates/builtins/#include
6.4 配置Markdown编写文章的支持
如果你是一步一步跟着本书走的话,现在应该得到一个功能基本完整的博客系统了,其中包含一开始说到的大部分功能。
但是体验上还有些差距,比如说我编写文章,没有任何格式可以使用:既没有可视化的编辑器,也没有Markdown这样的格式可供选择。这显然不够友好。在这一节中,我们就来增加对Markdown的处理。
6.4.1 Markdown 第三方库
Markdown的处理主要依赖于Python第三方库。相关库有很多,这里我们选择mistune这个库,其他库用起来类似。
Markdown的格式就不过多介绍了,它现在已经算是比较流行的文档格式了,无论是写文档,还是开源项目都会用到。mistune 这个库的使用非常简单,只需要传入写好的 Markdown 格式文本,就会返回格式化好的HTML代码:
import mistune
html = mistune.markdown(your_text_string)
当然,在使用之前需要先安装该库:
pip install mistune
6.4.2 评论内容支持
我们先来对评论内容增加Markdown的处理,那么在什么位置处理合适呢?要找到合适的位置,必须了解数据的传递流程。用户提交评论到评论展示的流程如下:
用户填写评论,提交表单→CommentForm 处理表单→验证通过→保存数据到instance→instance.save 方法把数据保存到数据库→用户刷新页面→通过comment_block模板自定义标签获取并展示数据
从这个流程中看,我们发现几个点可以用来对内容的格式进行处理。
- 在form层保存数据之前,我们对数据进行转换,让保存到数据库中的数据(content)是Markdown处理之后的。
- 给Comment 模型新增属性content_markdown,这个属性的作用是将原content 内容进行Markdown处理,然后在模板中不使用comment.content 而使用 comment.content_markdown。
显然,对于博客这种读大于写的系统来说,我更倾向于在写数据时进行转换,因为这种业务下大部分只有一次写操作。
所以我们在comment/forms.py中修改clean_content方法,在returncontent 之前增加一句content=mistune.markdown(content)。当然,别忘了在文件最上面加上语句 import mistune。具体代码如下:
# comment/forms.py
import mistune
class CommentForm(forms.ModelForm):
# 省略其他代码
def clean_content(self):
content = self.cleaned_data.get('content')
if len(content) < 10:
raise forms.ValidationError('内容长度怎么能这么短呢!!')
content = mistune.markdown(content)
return content
修改完成之后,建议你启动项目,然后添加评论试试。此时你会遇到新的问题,那就是我们的HTML代码直接展示在页面上了,没有被浏览器渲染。这其实是Django的安全措施。我们需要手动关闭Django模板的自动转码功能。
在comment/block.html代码中的{{comment.content }}位置上下增加 autoescape off的处理,完整代码如下:
<!-- comment/block.html -->
<hr/>
<div class="comment">
<form class="form-group" action="/comment/" method="POST">
{% csrf_token %}
<input name="target" type="hidden" value="{{ target }}"/>
{{ comment_form }}
<input type="submit" value="写好了!"/>
</form>
<!-- 评论列表 -->
<ul class="list-group">
{% for comment in comment_list %}
<li class="list-group-item">
<div class="nickname">
<a href="{{ comment.website }}">{{ comment.nickname }}</a> <span>{{ comment.created_time }}</span>
</div>
<div class="comment-content">
{% autoescape off %}
{{ comment.content }}
{% endautoescape %}
</div>
</li>
{% endfor %}
</ul>
</div>
此外,侧边栏评论展示模板config/sidebar_comments.html也需要关闭自动转码。
<!-- config/sidebar_comments.html -->
<ul>
{% for comment in comments %}
<li><a href="{{ comment.target }}">{{ comment.target.title }}</a> |
{% autoescape off %}
{{ comment.nickname }} : {{ comment.content }}
{% endautoescape %}
{% endfor %}
</ul>
6.4.3 文章正文使用Markdown
接着,再来处理文章的内容,其逻辑跟上面一致,我们同样可以在adminform中来处理。但是有一个问题,评论的内容目前没有设置可修改功能。但是文章正文我们可能随时都会修改,如果直接把content 转为HTML格式然后存储,不便于下次修改。因此,我们需要新增一个字段content_html,用来存储Markdown处理之后的内容。而对应地,在模板中我们也需要使用content_html 来替代之前的content。
我们在Post 模型中新增如下字段:
# blog/models.py
content_html = models.TextField(verbose_name='正文html代码', blank=True, editable=False)
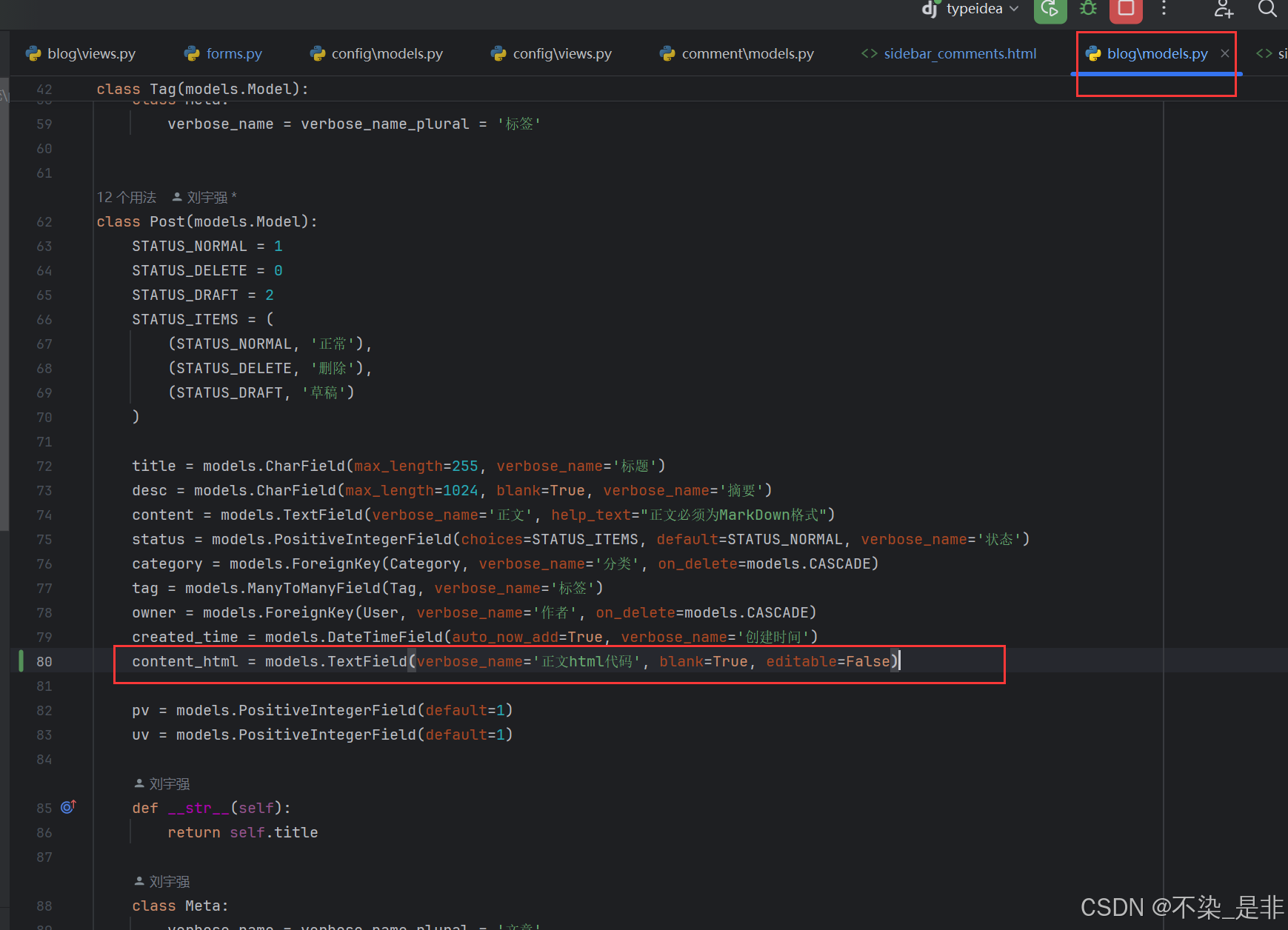
这里之所以配置 editable=False,是因为这个字段不需要人为处理。编写完代码后,需要进行迁移操作:
python manage.py makemigrations
python manage.py migrate
接着需要重写save方法,因为在form中处理这种类型的转换已经不合适了:
# blog/models.py
class Post (models.Model):
#省略其他代码(添加如下代码即可)
def save(self, *args, **kwargs): # 将content_html中的内容与content同步
self.content_html = mistune.markdown(self.content)
super().save(*args, **kwargs)
最后,调整模板中展示的部分。修改后blog/detail.html中的代码为:
<!-- blog/detail.html -->
{% extends "blog/base.html" %}
{% load comment_block %}
{% block title %} {{ post.title }} {% endblock %}
{% block main %}
{% if post %}
<h1>{{ post.title }}</h1>
<div>
<span>分类:<a href="{% url 'category-list' post.category_id %}">{{ post.category.name }}</a></span>
<span>作者:<a href="#">{{ post.owner.username }}</a></span>
<span>创建时间:{{ post.created_time }}</span>
</div>
<hr/>
<p>
{% autoescape off %}
{{ post.content_html }}
{% endautoescape %}
</p>
{% endif %}
{% comment_block request.path %}
{% endblock %}
再次运行,然后在后台新增Markdown 格式的内容。如果不知道Markdown格式,那么可以搜索一下,找篇文章看看。
6.4.4 配置代码高亮
在上面的代码中,我们已经完成了对Markdown文本的处理,但是对于程序员来说,写的内容大部分都会包含代码。默认情况下,Markdown只是帮我们把代码放到了<code>标签中,没做特殊处理,因此需要借助另外的工具。
做代码高亮需要依赖前端的库,这里有几种选择,一个是Google 出的code-prettify,另外一个是highlight.js。当然,还有其他选择,不过这里我们选择highlight.js 来做,code-prettify用起来也大同小异。
在此之前,我们需要先来修改 blog/base.html模板,在上面增加一个新的 block块,用来在子模板中实现特定逻辑。你可以理解为开放一个新的 block 给子模板填充数据用:
{% block extra_head %}
{% endblock %}
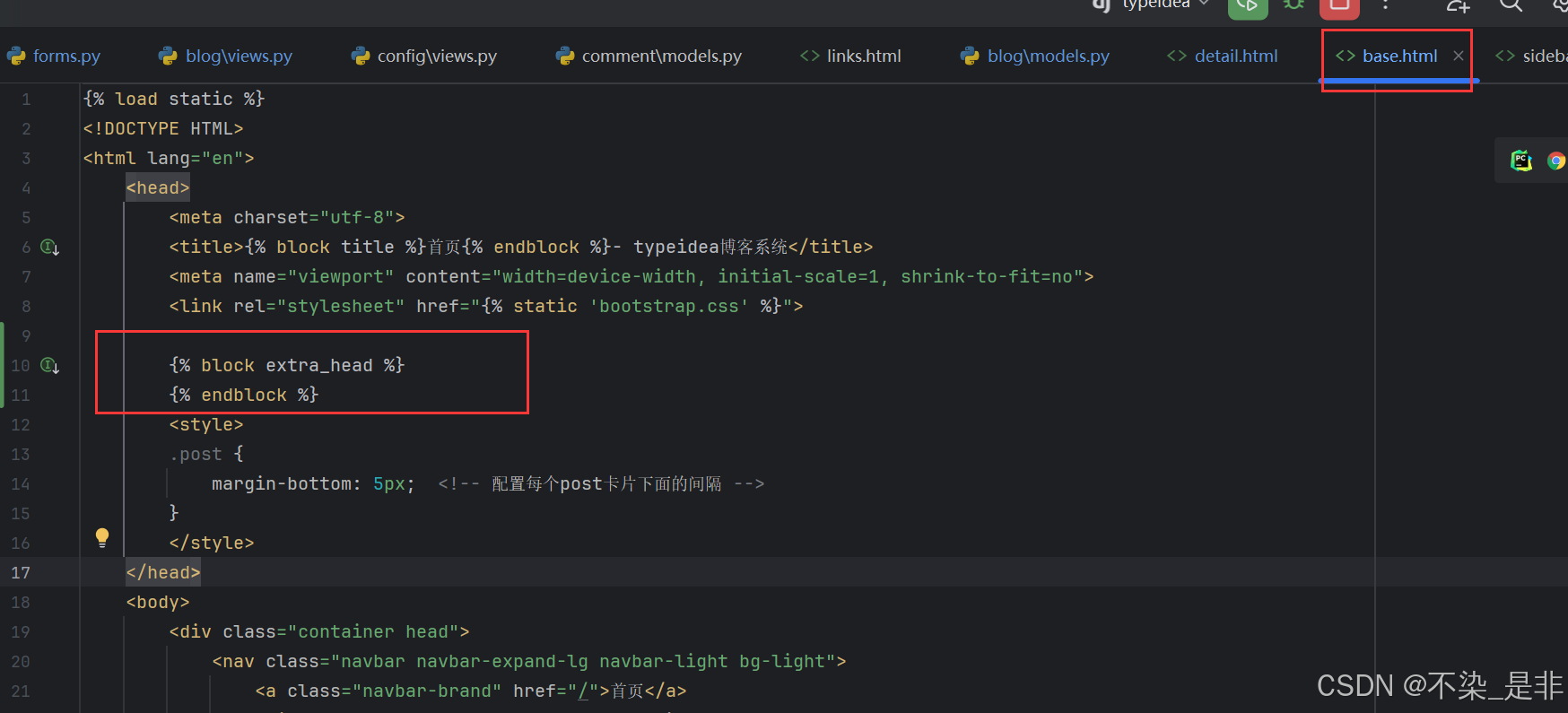
然后在blog/detail.html的{% block main %}上面新增如下代码:
{% block extra_head %}
<link rel="stylesheet" href="https://cdn.bootcss.com/highlight.js/9.12.0/styles/googlecode.min.css">
<script src="https://cdn.bootcss.com/highlight.js/9.12.0/highlight.min.js"></script>
<script>hljs.initHighlightingOnLoad();</script>
{% endblock %}
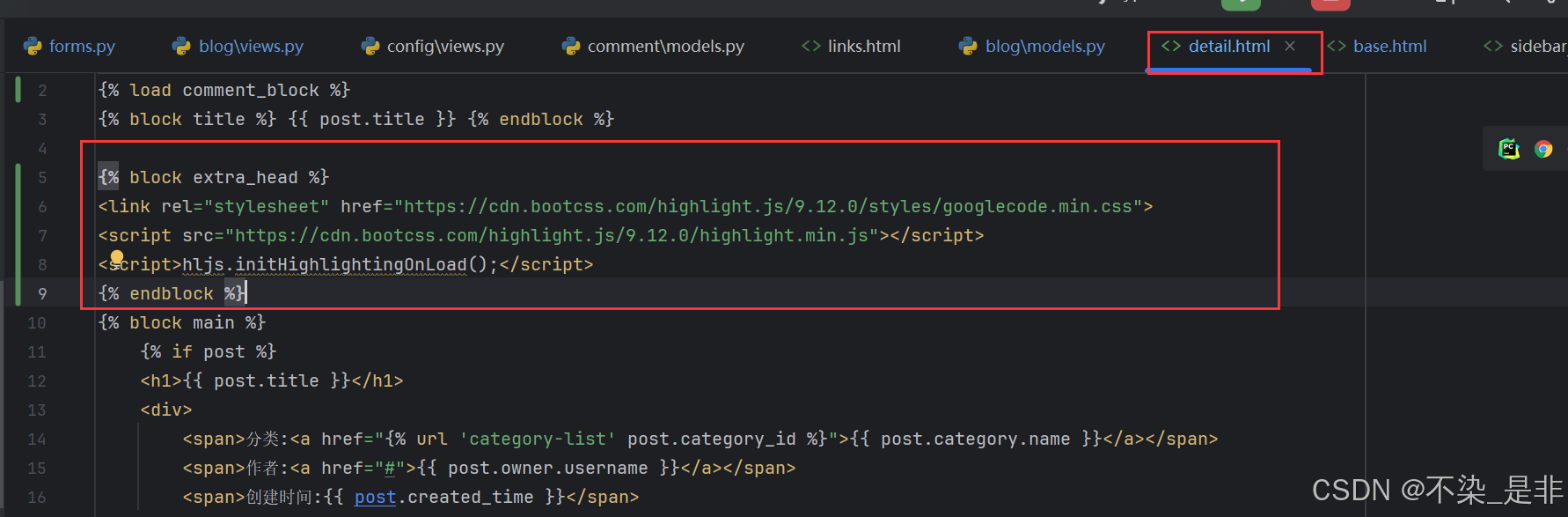
我们既可以直接使用网上开放的CDN来使用highlight突出显示代码,也可以像Bootstrap那样,把内容下载到本地,通过我们自己的静态文件服务来处理。你可以到highlight官网https://highlightjs.org/download/进行定制下载。
通常情况下,<script>标签应该放到页面底部,这是为了防止浏览器在加载JavaScript时页面内容停止渲染,造成用户等待时间过长。但是碍于文章中的编码需要依赖这些样式,所以需要等待 highlight的资源加载完成。CSS也是一样的逻辑,所以在前端性能优化时,需要根据场景来决定资源的放置位置。
说回我们的代码高亮工作,引人上面资源后就基本完成了。其工作原理是,通过Markdown贴的代码,会被渲染到<pre><code></code></pre>标签中,而highlightjs 或者其他前端代码高亮的库,会提取<code>块中的代码,然后进行分析,进而通过不同的标签进行包装,最后通过CSS展示为不同的颜色。
举个例子来说,比如我们在Markdown中写下:
## 背景
刚开始学习《Django企业实战开发》,这是第一篇学习记录
## 内容
'''
import Django
print('Hello Django')
'''
我们Markdown处理完之后会变为:
<h2>背景</h2>
<P>刚开始学习《Django企业实战开发》,这是第一篇学习记录</p>
<h2>内容</h2>
<pre><code>import Django
print('Hello Django')
</code></pre>
为了便于阅读,渲染之后的HTML代码中的\n处理为换行。
接下来,highlight.js处理之后,代码的部分就会变为:
<pre><code class="hljs coffeescript hljs "<span class="hljs-keyword"><span class=
"hljs-reserved">import</span></span> Django
<span class="hljs-built_in"><span class="hljs-built_in">print</span></span> (<span class="hljs-string"><span
class="hljs-string">'Hello Django'</span></span>)</code></pre>
根据最后的标签,可以看到它的分析逻辑。
6.4.5 总结
到此为止,我们就完成了Markdown内容以及代码高亮的处理。没有太多复杂的逻辑,其核心是理解数据的保存流程,在合适的位置使用Markdown的库进行格式化处理。
接下来,我们来处理文章访问统计。
页面展示:

6.4.6 参考资料
Google 代码高亮前端库的用法:
https:/github.com/google/code-prettify/blob/master/docs/getting_started.md
highlight.js 的用法:
https://highlightjs.org/
6.5 增加访问统计
在这一节中,我们来处理访问统计的业务。这是一个企业项目必须具备的功能,新的产品经过多个组的协作、几个月的开发,最终上线了。那上线之后的效果怎么样?有没有用户访问?访问量多大?用户的访问习惯是什么?这些都是我们需要关心的问题。
因此,—定要把开发完成的东西放出来,让大家能看到,接受用户反馈。从商业产品的角度来说,产品发布上线只是一个起点,后面还有很多事情要做。因此,需要理解的是,对于一个产品的生命周期,开发只是其中一部分。
统计也是一个很大的话题,有很多维度的统计,这里只说文章访问量的统计。我们开发博客,然后将其部署上去。想要知道哪篇文章访问量最高,应该怎么做?
通常来说,有以下几种方式:
- 基于当次访问后端实时处理。
- 基于当次访问后端延迟处理——Celery(分布式任务队列)。
- 前端通过JavaScript埋点或者img标签来统计。
- 基于Nginx日志分析来统计。
下面挨个来说。第一种方式中,当用户访问文章正文时,会经过我们编写的PostDetailView,因此可以在这里“做手脚”。当用户请求文章时,对当前文章的PV和UV进行+1操作,对应到代码就是:
# blog/views.py
class PostDetailView(CommonViewMixin, DetailView):
# 省略其他代码
def get(self, request, *args, **kwargs):
response = super().get(request, *args, **kwargs)
Post.objects.filter(pk=self.object.id).update(pv=F('pv') + 1, uv=F('uv') + 1)
from django.db import connection
print(connection.queries)
return response
# 这样写sql语句会较短
这样就完成了用户访向一次就+1的操作。有人可能会问,为什么你不使用这样的代码:
self.object.pv = self.object.pv + 1
self.object.uv = self.object.uv + 1
self.object.save()
# 这样写sql语句会很长很长
因为在竞争条件下,这种方式会出现很大的误差,整个+1操作不够原子性。因此,采用F这样的表达式来实现数据库层面的+1。你可以把上面的代码运行一次,看看print出来的SQL语句。
这种方式存在一个比较大的问题,那就是每次访问都会造成一次写入操作。写入一些数据库的成本远高于读一次数据,因此写入的耗时会影响页面的响应速度。
于是就引出第二种方式了,通过异步化的方式来处理访问统计。所谓异步化,就是当前需要执行某种操作,但是我自己不执行,让别人帮忙执行,这样我的时间就可以省出来了。异步化的方式有多种选择,Celery 就是其中之一,不过这并不是本书需要涉及的内容。Celery 集成到Django项目中是非常容易的事情,只需要跟着文档一步一步走就行。
第三种方式和第四种方式是大规模系统很常用的统计方法,毕竟每天大量的访问量,不可能在业务代码里面来处理统计逻辑。因此就需要有一个独立的系统来完成一系列统计业务。
第三种方式类似于百度统计这样的系统。通过在你的页面配置JavaScript代码,就可以帮你统计页面的访问量,但是带来的问题是统计数据跟业务相分离。拿我们的博客系统来说,在博客系统中拿不到访问数据,需要调用统计系统的接口才能拿到数据,这也是正常逻辑。在实际环境下会更复杂,业务系统需要拿统计系统的数据做展示,统计系统需要拿业务系统的数据做分析。
第四种方式跟第三种方式很类似,只是这种情况下统计系统可以拿到业务系统的前端Nginx的访问日志(这里的前端是指系统架构上的前端,不是指HTML这些)。其他的流程跟第三种方式没什么差别。只是第三种可以做得更加独立。
了解了这么多统计方式之后,我们来实现最简单的一种——基于当次访问后端实时处理,也是对于小型系统成本最低的一种。
6.5.1 文章访问统计分析
在实现之前,我们还得再说一下第一种方式实现的问题,除了性能问题外,还有被刷的问题。如果有人连续刷页面,不应该累计 PV,因为这种情况是无效访问。另外,对于 UV来说,我们需要根据日期来处理,一个用户每天访问某一篇文章,始终应该只能增加一个UV。不然 UV的统计就没意义了。
那么,问题又来了,怎么区分用户呢?怎么知道用户 A已经访问过某篇文章了呢?你可以思考一下这个问题。面试中很常见的一个问题就是,Web系统是如何针对不同用户提供服务的。当然,这个问题只是引子。
对于我们的需求,有下面几种方法来做。
-
根据用户的IP和浏览器类型等一些信息生成MD5来标记这个用户。
-
系统生成唯一的用户id,并将其放置到用户cookie中。
-
让用户登录。
第一种方式有一个很大的问题,那就是用户会重合,同一个下可能有非常多用户。
第二种方式也是基于浏览器的,可以生成唯一的 id 来标识每个用户。但问题是如果用户换浏览器,那就会产生一个新用户。
第三种方式最合理,但是实施难度最大。对于内容型网站来说,没人会登录之后才来看文章。因此,我们采用第二种方式,通过生成用户id来标记一个用户。接着就是来做具体控制了。我们需要在用户访问时记录用户的访问数据,这些数据应该放到缓存中,因为都是临时数据,并且特定时间就会过期。
方案定了,就需要考虑具体实现了,有几个点需要考虑:
- 如何生成唯一的用户id。
- 在哪一步给用户配置id。
- 使用什么缓存。
我们一个一个来解决。针对第一个问题,可以使用Python内置的uuid这个库来生成唯一id:
import uuid
uid = uuid.uuid4().hex
对于第二个问题,在一个Web系统中,显示是在请求的越早阶段鉴定/标记用户越好。因此,对于Django系统,我们放到middleware中来做。
对于第三个问题,我们可以直接使用Django 提供的缓存接口。Django缓存在后端支持多种配置,比如memcache、MySQL、文件系统、内存。当然,还有很多第三方插件来对Redis 做支持。
6.5.2 实现文章访问统计
上面分析得已经很清楚了,接下来只需要完成代码即可。首先需要新建一个 middleware,在blog App 下新建如下结构:
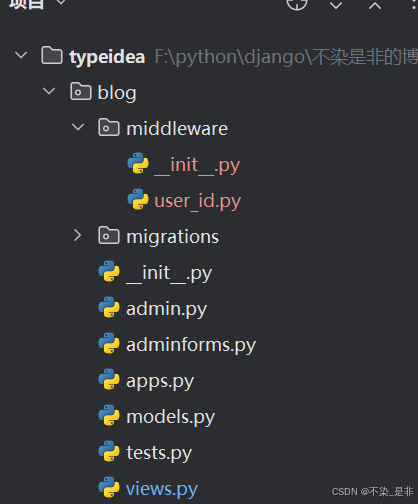
然后在user_id.py中增加如下代码:
# blog/middleware/user_id.py
import uuid
USER_KEY = 'uid'
TEN_YEARS = 60 * 60 * 24 * 365 * 10
class UserIDMiddleware:
def __init__(self, get_response):
self.get_response = get_response # 类的初始化方法,接收一个get_response参数,这是一个函数,用于获取响应对象。
def __call__(self, request):
uid = self.generate_uid(request) # 调用generate_uid方法生成或获取UID,然后将这个UID存储在请求对象的uid属性中
request.uid = uid
response = self.get_response(request) # 调用get_response函数获取响应对象
# 通过set_cookie方法设置cookie,其中cookie的键为USER_KEY,值为UID,最大有效时间为10年,且设置了httponly=True,表示只在服务端能访问。
response.set_cookie(USER_KEY, uid, max_age=TEN_YEARS, httponly=True)
return response
def generate_uid(self, request):
# 尝试从请求的cookie中获取UID,如果cookie中不存在UID,则使用uuid.uuid4().hex生成一个新的UUID字符串作为UID。
try:
uid = request.COOKIES[USER_KEY]
except KeyError:
uid = uuid.uuid4().hex
return uid
大概说一下上面的逻辑,Django的middleware在项目启动时会被初始化,等接受请求之后,会根据settings中的MIDDLEWARE 配置顺序挨个调用,传递request作为参数。
上面的逻辑在接受请求之后,先生成uid,然后把uid赋值给request 对象。因为request是一个类的实例,可以动态赋值。因此,我们动态给其添加uid属性,这样在后面的 View中就可以拿到uid并使用了。最后返回response时,我们设置cookie,并且设置为httponly(即只在服务端能访问)。这样用户再次请求时,就会带上同样的uid信息了。
接着,需要把我们开发的middleware配置到settings.py中。根据middleware的路径,在配置MIDDLEWARE的第一行增加如下代码:
MIDDLEWARE = [
'blog.middleware.user_id.UserIDMiddleware',
#省略其他代码
]
这样进来的所有请求会先经过middleware,在后面的流程中request对象上就多了一个uid属性。
接着,我们再来完善 View层的逻辑,在PostDetailView 中新增一个方法来专门处理PV和UV统计。我们可以直接使用Django的cache接口,使用其默认配置:
# blog/views.py
from datetime import date
from django.core.cache import cache
#省略其他代码
class PostDetailView(CommonViewMixin, DetailView):
queryset = Post.objects.filter(status=Post.STATUS_NORMAL)
template_name = 'blog/detail.html'
context_object_name = 'post'
pk_url_kwarg = 'post_id'
def get(self, request, *args, **kwargs):
""" 重写了DetailView的get方法。在调用父类的get方法后(负责渲染页面),调用了自定义的
handle_visited方法来处理访问量的增加。"""
response = super().get(request, *args, **kwargs)
self.handle_visited()
return response
def handle_visited(self):
increase_pv = False # 用于标记是否需要增加页面浏览量(PV)。
increase_uv = False # 用于标记是否需要增加独立访客数(UV)。
uid = self.request.uid # 从请求对象(self.request)中获取uid
# pv_key 和 uv_key: 分别用于缓存PV和UV的键,它们由用户ID、日期(对于UV)和请求路径组成,以确保缓存的唯一性。
pv_key = 'pv:%s:%s' % (uid, self.request.path) # 构造uv_key,用于缓存当前用户在当前页面的UV访问情况。这里还包含了日期信息,以确保UV是按天计算的。
uv_key = 'uv:%s:%s:%s' % (uid, str(date.today()), self.request.path)
if not cache.get(pv_key):
"""
使用cache.get(uv_key)检查缓存中是否已存在该键。
如果不存在,说明用户尚未在今天内访问过该页面,
因此将increase_uv设置为True,并设置缓存(有效期为24小时),表示用户已访问。
"""
increase_pv = True
cache.set(pv_key, 1, 1 * 60) # 1分钟有效
if not cache.get(uv_key):
increase_uv = True
cache.set(uv_key, 1, 24 * 60 * 60) # 24小时有效
if increase_pv and increase_uv:
Post.objects.filter(pk=self.object.id).update(pv=F('pv') + 1, uv=F('uv') + 1)
elif increase_pv:
Post.objects.filter(pk=self.object.id).update(pv=F('pv') + 1)
elif increase_uv:
Post.objects.filter(pk=self.object.id).update(uv=F('uv') + 1)
上面的逻辑很直观,用于判断是否有缓存,如果没有,则进行+1操作,最后的几个条件语句是避免执行两次更新操作。
Django的缓存在未配置的情况下,使用的是内存缓存。如果是单进程,这没有问题;如果是多进程,就会出现问题。因为内存缓存是进程间独立的。
因此,可以暂时这么使用。或者,你可以尝试进行其他配置(对于小型系统,直接用文件系统或者数据库表缓存即可;对于大型系统,推荐使用 memcached 或者Redis)。
6.5.3 更加合理的方案
上述的统计方案针对小型项目和个人项目来说问题不大,在访问量不高的情况下,读数据的请求中同时写数据不会有太大的影响。但是我们需要意识到的是,对于所有的数据库来说,写操作都是一件成本很高的事情。因此,在实际项目中会尽量避免用户在请求数据过程中进行写操作,所以合理的方案应该是:独立的统计服务,通过前面给出的第三种方式或者第四种方式来统计。这也是我们日常业务中在用的方案。
6.5.4 总结
有了上面的统计,接下来要做的就是根据统计进行排序,可以选择PV或者UV。第4章已经封装好了一个hot_posts方法,因此我们只需要在后台新建一个侧边栏,然后在类型中选择热门文章即可。
统计方式有很多种,不同的业务场景、不同的团队规模所使用的都不同,我们需要理解的是其中的统计逻辑。
页面展示:

6.5.5 参考资料
Django 缓存相关文档:
https://docs.djangoproject.com/zh-hans/4.2/topics/cache/
6.6 配置RSS和sitemap
在前面的章节中,我们已经完成了博客所有的功能,这一节就来提供一个RSS和sitemap输出的接口。RSS(Really Simple Syndication,简易信息聚合)用来提供订阅接口,让网站用户可以通过RSS阅读器订阅我们的网站,在有更新时,RSS阅读器会自动获取最新内容,网站用户可以在RSS阅读器中看到最新的内容,从而避免每次都需要打开网站才能看到是否有更新。
sitemap(站点地图)用来描述网站的内容组织结构,其主要用途是提供给搜索引擎,让它能更好地索引/收录我们的网站。
这两个组件在Django中都是现成的,我们可以直接使用。
6.6.1 实现 RSS输出
这里我们直接使用 Django的 RSS 模块 django.contrib.syndication.views.Feed来实现RSS输出。下面还是直接来看代码,在blog目录下新增rss.py文件:
# blog/rss.py
from django.contrib.syndication.views import Feed
from django.urls import reverse
from django.utils.feedgenerator import Rss201rev2Feed
from .models import Post
class LatestPostFeed(Feed):
feed_type = Rss201rev2Feed
title = "Typeidea Blog System"
link = "/rss/"
description = "typeidea is a blog system power by django"
def items(self):
return Post.objects.filter(status=Post.STATUS_NORMAL)[:5]
def item_title(self, item):
return item.title
def item_description(self, item):
return item.desc
def item_link(self, item):
return reverse('post-detail', args=[item.pk])
其中feed_type 可以不写,默认使用Rss201rev2Feed,这里写出来是标明这个地方可以被赋值为其他类型。我们可以进行定制。
上面的代码并没有输出正文部分,我们可以通过自定义feed_type 来实现:
# blog/rss.py
from django.contrib.syndication.views import Feed
from django.urls import reverse
from django.utils.feedgenerator import Rss201rev2Feed
from .models import Post
class ExtendedRSSFeed(Rss201rev2Feed):
def add_item_elements(self, handler, item):
super(ExtendedRSSFeed, self).add_item_elements(handler, item)
handler.addQuickElement('content:html', item['content_html'])
class LatestPostFeed(Feed):
feed_type = ExtendedRSSFeed
title = "Typeidea Blog System"
link = "/rss/"
description = "typeidea is a blog system power by django"
def items(self):
return Post.objects.filter(status=Post.STATUS_NORMAL)[:5]
def item_title(self, item):
return item.title
def item_description(self, item):
return item.desc
def item_link(self, item):
return reverse('post-detail', args=[item.pk])
def item_extra_kwargs(self, item):
return {'content_html': self.item_content_html(item)}
def item_content_html(self, item):
return item.content_html
6.6.2 实现 sitemap
sitemap 的实现跟Feed类似,都是输出文章列表,但是格式和内容均不相同。在blog目录下新增sitemap.py,其内容如下:
# blog/sitemap.py
from django.contrib.sitemaps import Sitemap
from django.urls import reverse
from .models import Post
class PostSitemap(Sitemap):
changefreq = "always"
priority = 1.0
protocol = 'https'
def items(self):
return Post.objects.filter(status=Post.STATUS_NORMAL)
def lastmod(self, obj):
return obj.created_time
def location(self, obj):
return reverse('post-detail', args=[obj.pk])
这段代码中我们实现了3个方法:items 返回所有正常状态的文章,lastmod返回每篇文章的创建时间(或者最近更新时间),location返回每篇文章的URL。
编写好sitemap数据处理的代码后,再来编写对应的模板,新增文件templates/sitemap.xml
其内容可以直接从Django文档贴过来。<news:news>部分根据我们的Model进行调整。其内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<urlset
xmlns="https://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
{% spaceless %}
{% for url in urlset %}
<url>
<loc>{{ url.location }}</loc>
{% if url.lastmod %}<lastmod>{{ url.lastmod|date:"Y-m-d" }}</lastmod>{% endif %}
{% if url.changefreq %}<changefreq>{{ url.changefreq }}</changefreq>{% endif %}
{% if url.priority %}<priority>{{ url.priority }}</priority>{% endif %}
<news:news>
{% if url.item.created_time %}<news:publication_date>{{ url.item.created_time|date:"Y-m-d" }}</news:publication_date>{% endif %}
{% if url.item.tags %}<news:keywords>{{ url.item.tags }}</news:keywords>{% endif %}
</news:news>
</url>
{% endfor %}
{% endspaceless %}
</urlset>
这里大概解释一下代码,上面的{% spaceless %}标签的作用是去除多余的空行,因为在Django 模板中使用for循环会产生很多空行,我们在前面的模板中并未使用它,你可以查看网页源码观察到这一结果。配置好spaceless之后,可以方便地去掉多余的空行。
后面的for 循环就是遍历上面PostSitemap输出的结果,只是做了包装而已。
这里用到的url.item.tags需做下支持,因为我们的Post 模型有tag这样一个多对多的关联,所以可以在模型中增加一个属性来输出配置好的tags。接着修改blog/models.py中Post的部分:
# blog/models.py
from django.utils.functional import cached_property # 在合适的位置引入
# 省略其他代码
class Post (models.Model):
# 省略其他代码
@cached_property
def tags(self):
return ','.join(self.tag.values_list('name', flat=True))
这里面用到了 Django 提供的一个工具cached_property,它的作用是帮我们把返回的数据绑到实例上,不用每次访问时都去执行tags 函数中的代码。关于这点,你可以对比Python内置的property。
配置好这些后,RSS和sitemap就配置完成了,接下来配置urls.py让其生效。
6.6.3 配置RSS 和sitemap的urIs.py
这里还是直接看代码:
from django.contrib.sitemaps import views as sitemap_views
from blog.rss import LatestPostFeed
from blog.sitemap import PostSitemap
urlpatterns = [
# 省略其他代码
re_path(r'^rss|feed/', LatestPostFeed(), name='rss'),
path('sitemap.xml', sitemap_views.sitemap, {'sitemaps': {'posts': PostSitemap}}, name='sitemap'),
]
这样配置完成后,可以启动项目,访问 http://127.0.0.1:8000/rss/ 以及 http://127.0.0.1:8000/sitemap.xml 来查看效果。
对于网页特别多的系统来说,sitemap还需要进一步拆分。毕竟如果存在上万或者上百万的文章,生成单一的sitemap.xml也是一个挑战,况且 sitemap单个文件也有条数和文件大小的限制。
因此,可以使用sitemap index的方式(即 sitemap中的loc部分不是网页地址,而是另外一个sitemap地址)来拆分sitemap。
6.6.4 总结
如果前面的章节你都能够理解并掌握,其实会发现,在基于Django开发的过程中,我们除了理解需要做什么之外,还需要知道 Django 给我们提供了哪些能力,比方说 RSS和 sitemap这两个功能。如果完全自己开发或许也不难,但是有现成的并且扩展性很好的基础组件,岂不是更好。
页面效果:
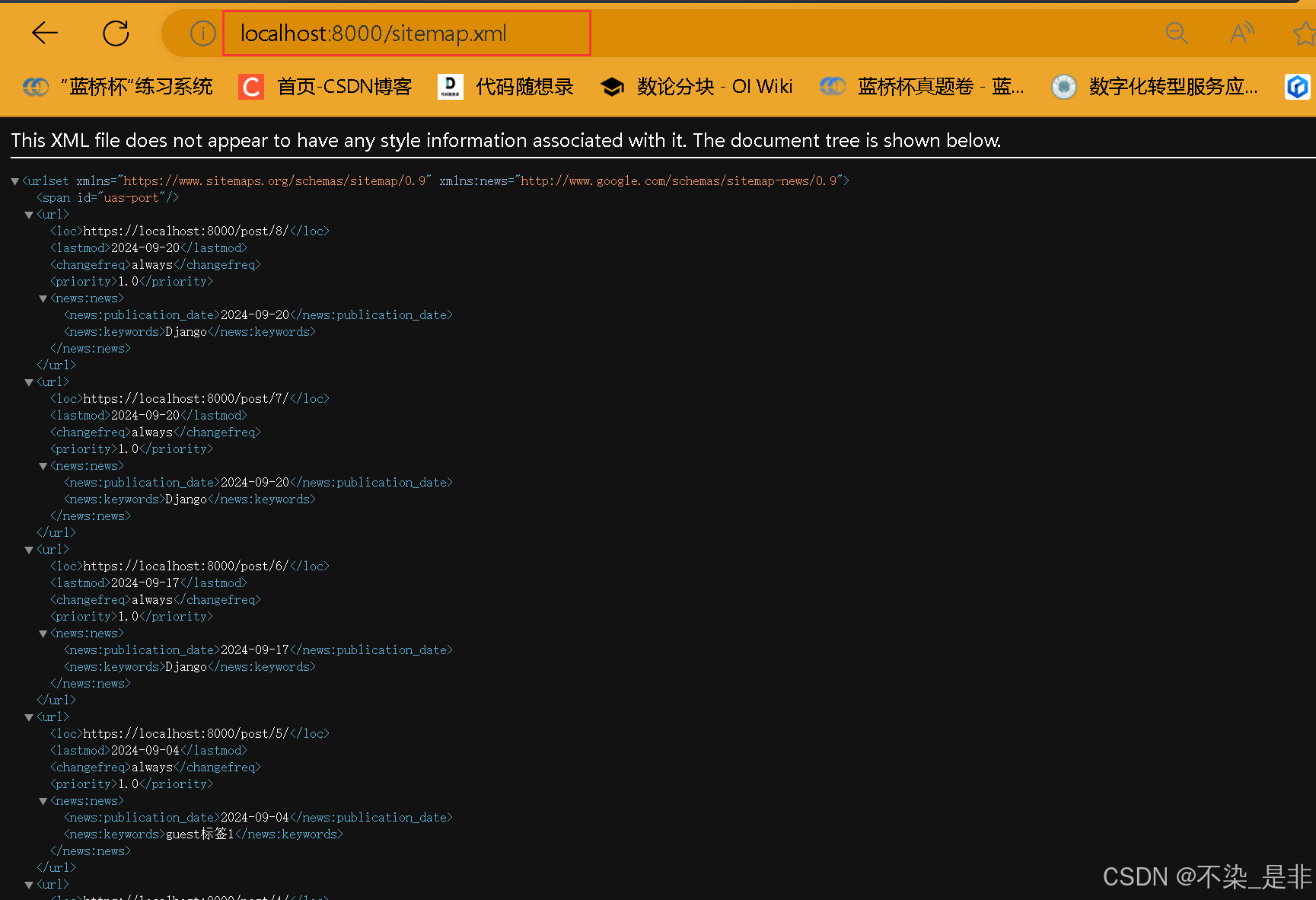
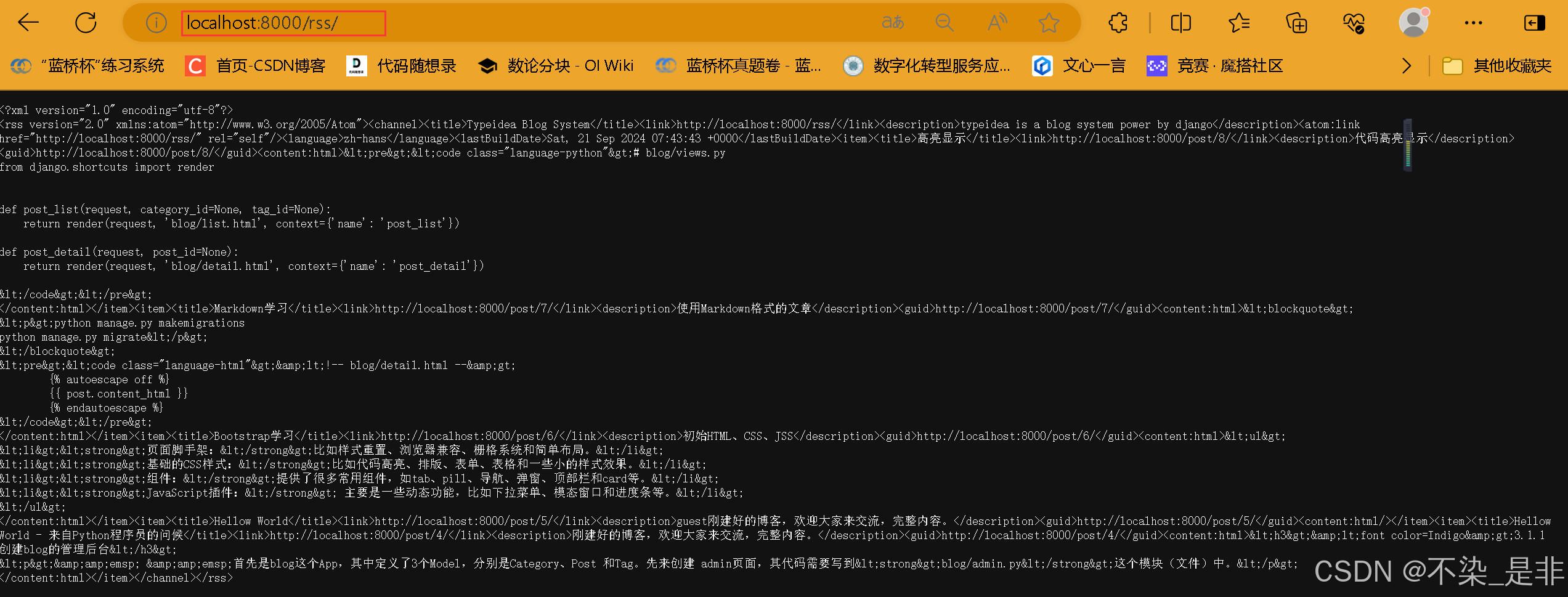
6.7 本章总结
截至目前,我们已经完成了博客系统的基础功能开发,如果你一直是随着本书的内容编写代码,应该能得到如下图所示的界面。

通过本章,我们能够直观地感受到,当基于一个成熟的框架构建好一套流程之后,新增功能时会非常方便。这得益于Django的优势——内置了很多对网站开发有用的功能。如果能够很好地掌握这些内置模块,就能够极大地提高开发速度。
结尾:
到此为止,我们的博客系统开发完毕,基础功能都已实现,大家可以使用第三方插件来继续完善博客系统,丰富其内容和页面。本系列博客就跟大家暂时告一段落了,后续可能会继续完善其功能。
本博客借鉴了《Django企业开发实战》一书,在书中的基础上更新了python和Django版本(书中的版本有点太老了,很多第三方插件都不支持了),但是博主学艺欠缺,后期的知识点没能融会贯通,所以也没有继续开发博客系统了,后期再继续深造一下。
最后,本博客所涉及的项目源码会开源在GitHub上:https://github.com/1273055646/typeidea 。每个章节都有对应的分支,比如03-admin就是对应第3章的内容,读者可以自行切换分支来查看对应代码。
祝好!
链接:
项目开源代码GitHub:https://github.com/1273055646/typeidea
Django学习实战篇一(适合略有基础的新手小白学习)(从0开发项目)
Django学习实战篇二(适合略有基础的新手小白学习)(从0开发项目)
Django学习实战篇三(适合略有基础的新手小白学习)(从0开发项目)
Django学习实战篇四(适合略有基础的新手小白学习)(从0开发项目)
Django学习实战篇五(适合略有基础的新手小白学习)(从0开发项目)