对时间序列SOTA模型Patch TST核心代码逻辑的解读
前言
Patch TST发表于ICLR23,其优势在于保留了局部语义信息;更低的计算和内存使用量;模型可以关注更长的历史信息,Patch TST显著提高了时序预测的准确性,Patch可以说已成为时序模型的基本操作。我在先前的一篇文章对Patch TST做了比较细致的论文解读,各位朋友可参考。
但是最近很多朋友私信问我:Patch TST到底好在哪里?Transformer模型也对时序数据进行了切分,和Patch TST的切片有何区别?其实在我没有阅读Patch TST的代码之前,我也一直没想明白:对时间序列数据进行Patch操作之后,数据是怎么放入到Transformer的编码器?
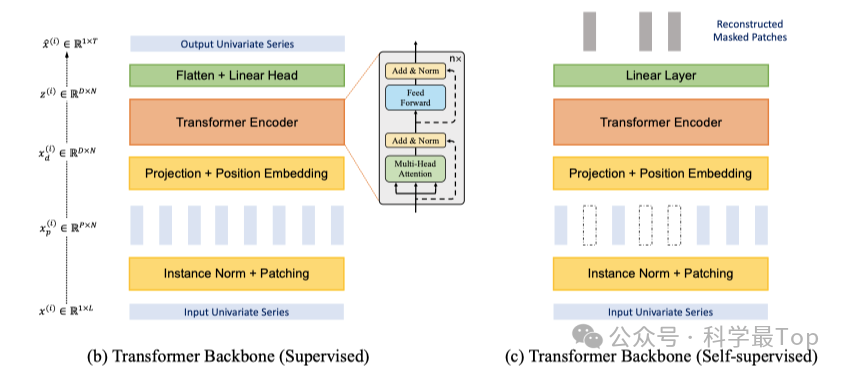
只看论文,确实很难对patch有深刻的理解,最佳的方法还是打断点走一遍代码。今天我这篇文章就梳理了Patch TST代码中几个关键的节点,并标注了数据的维度信息,掌握了Transformer和Patch TST维度变化上的差异,也就解答了上面所有的问题,对Patch的好处也就有了更深刻的理解。
Patch TST与Transformer输入特征的对比
01. Transformer的数据输入维度
我们首先统一基本的符号表示,batch_size表示batch的维度;seq_len表示输入时序数据的长度;Channel表示时序特征的数量;patch_len表示patch的长度;patch_num表示分段后patch的数量;d_model表示模型的维度。
好了,我们现在统一了符号表示,思考第一个问题:原始transformer中时序特征输入到编码器时的特征维度是怎样的?
答案其实是:[batch_size,seq_len,d_model]!
02. Patch TST的数据输入维度
那么切换到Patch TST模型,经过patch处理后,它输入到encoder编码器之前的特征维度是怎么样的?
答案其实是:[(batch_size*channel),patch_num,d_model]
我们对比transformer和Patch TST的输入数据维度可以发现,两者的第三个维度d_model是一致的。但是,序列长度由seq_len变为patch_num,batch的大小由batch_size变为(batch_size*channel)。
经过切分后,patch_num的大小肯定是远远小于seq_len的,相当于输入序列变短了,正是因为如此,patch TST的在计算Attention的时候计算效率大幅提升。同时,我们可以看到Patch TST的第一个维度变为(batch_size*channel)。整个过程(我个人)理解为通过patch降低了序列长度,但增加了batch数量。就是通过这种方式,实现了计算量的减少。
核心代码解读
Patch TST代码下载地址:https://github.com/yuqinie98/PatchTST
以上的分析其实已经给出了本篇文章想说的结论,即为什么Patch效果要比原始模型好。但是,从代码解读的角度来看,我们仍有两个问题没有搞清楚:1、Patch TST是如何把输入到Transformer模型的数据维度变为[(batch_size*channel),patch_num,d_model]的;2、Patch TST的代码逻辑是怎么样的?
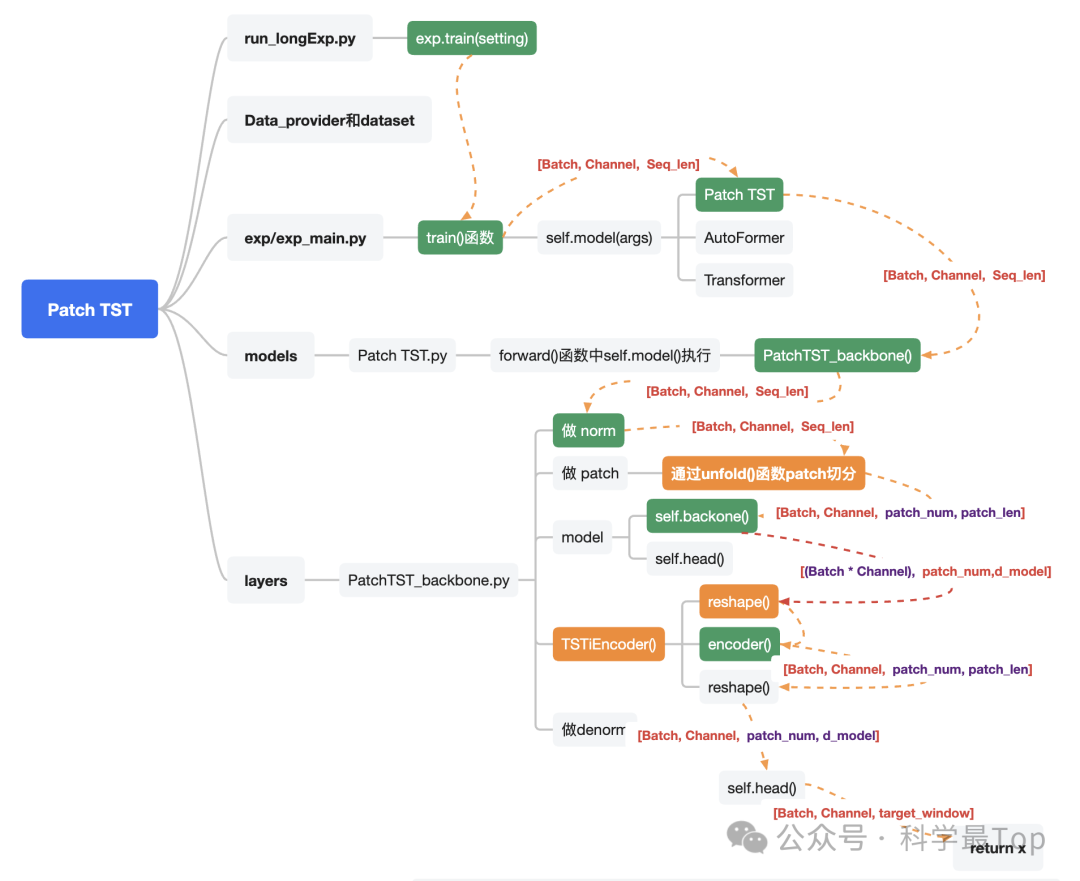
上面这张图是我对照Patch TST的代码整理数据流向,其中关键的节点我用绿色和橘黄色做了标注。
-
我们发现从执行train()函数开始,途经Patch TST类、PatchTST_backbone类、到做Normalization方法,这个过程数据维度一直没变,是[batch_size,channel,seq_len]
-
执行到PatchTST_backbone.py的unfold()方法时,此时维度发生变化,变为:[batch_size,channel,patch_num,patch_len],代码如下所示,经过这一步完成了数据的切分
# do patchingif self.padding_patch == 'end':z = self.padding_patch_layer(z)# unfold函数就是按照步长和patch_len进行切分z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride)z = z.permute(0,1,3,2)
-
然后,经过TSTiEncoder类中的reshape()方法,数据维度变为[(batch_size*channel),patch_num,d_model],代码如下:
def forward(self, x) -> Tensor:n_vars = x.shape[1]# Input encodingx = x.permute(0,1,3,2)u = torch.reshape(x, (x.shape[0]*x.shape[1],x.shape[2],x.shape[3]))u = self.dropout(u + self.W_pos)# Encoderz = self.encoder(u)z = torch.reshape(z, (-1,n_vars,z.shape[-2],z.shape[-1]))z = z.permute(0,1,3,2)return z
-
reshape之后的数据送入到encoder(),encoder输出的仍然是三维的,既[(batch_size*channel),patch_num,d_model],所以我们看到encoder的输出结果再次经过reshape变回四维,然后再经过head()变到与预测序列的维度一致,从而计算损失。
总结
Patch TST的代码推荐大家亲自跑一遍,其实模型结构没有太大变化,重点是对数据数据的前处理,特别是要理解patch切分后,从四维向量到三维的转变过程(batch_size*channel),经过这一步骤,输入序列长度大大减小,同时batch数量增加。
欢迎大家关注我的公众号【科学最top】,专注于时序高水平论文解读。
