【深度】为GPT-5而生的「草莓」模型!从快思考—慢思考到Self-play RL的强化学习框架
原创 超 超的闲思世界 2024年09月11日 19:17 北京
9月11日消息,据外媒The Information昨晚报道,OpenAI的新模型「草莓」(Strawberry),将在未来两周内作为ChatGPT服务的一部分发布。
「草莓」项目是OpenAI盛传已久的神秘Q*模型,据传是此前OpenAI政变大戏的关键原因之一。这个秋天,它将带来推理能力的飞跃,助力GPT-5更上一层楼。想象一下,一个能给出产品营销策略建议,甚至还能能轻松解决复杂数学题、编程难题的人工智能,是不是很酷?
「草莓」模型不是简单的升级版AI,它在处理各种复杂问题上展现出了惊人的实力。而且,它还能在处理问题时“深思熟虑”,给出更准确的答案。这与我们常说的“快思考”和“慢思考”有点像。传统的AI像是“快思考”,反应迅速但有时会犯错;而「草莓」则更像是“慢思考”,虽然反应稍慢,但答案往往更靠谱。
本文将带大家一探究竟,「草莓」模型是如何助力GPT-5的?它又是如何在“快思考”与“慢思考”之间找到平衡的?
01「草莓」?GPT-5?
在最新的大模型进展中,OpenAI的「草莓」模型无疑是备受关注。与其说「草莓」是一个模型,不如说它是OpenAI在追求更高智能道路上的一块里程碑。「草莓」并非单一的模型,而是OpenAI研发团队倾注心血,旨在大幅强化推理能力并生成高质量数据的一系列技术集合。
「草莓」模型的核心特点在于其强大的推理能力。与现有的生成式智能相比,「草莓」能够解决更为复杂的问题,尤其是那些之前从未见过的数学难题。此外,它在编程领域也展现出了不俗的实力。但「草莓」的能力远不止于此,经过适当的“思考”时间,它同样能够应对一些主观性更强、需要深度理解的问题,如产品营销策略等。

而「草莓」与GPT-5之间的关联,则体现在数据生成方面。「草莓」通过自我对弈强化学习(self-play RL)的方式,不断与自己博弈,生成高质量的合成数据。这些数据不仅用于训练「草莓」自身,更重要的是,它们也被用来训练OpenAI的下一代旗舰大语言模型——“猎户座”(Orion),进而间接提升GPT-5的性能。
值得一提的是,「草莓」模型在模拟人类的慢思考过程方面也取得了显著成果。与传统的快速响应模型不同,「草莓」在回答问题前会进行一段“思考”时间,这个过程通常持续10到20秒。虽然这看似增加了响应时间,但实际上,「草莓」”正是在这段时间里进行更为深入、全面的推理,从而提供更有逻辑性、更为准确的答案。这种慢思考的方式,使得「草莓」在处理复杂或多步骤查询时更具优势,也更能满足用户在某些场景下的需求。
02 当前大模型范式下的局限
缺失的逻辑和无法避免的幻觉
当下Transformer大模型,以其强大的信息捕捉和处理能力,在当下风光无限。然而,正如我们在探讨OpenAI的「草莓」模型时所揭示的,即便是这些先进的模型,也存在着不容忽视的局限性。
大模型在捕捉信息时,往往表现出快速思考的特点。它们能够迅速地处理海量的文本数据,通过学习和归纳,高效地把握语言中的模式和相关性。这种能力使得大模型在诸如文本生成、语义理解等任务上表现出色。
然而,这种快速思考的模式并不能很好地捕捉文本之间的因果,也带来了数理推理逻辑上的缺失。今年的一个大模型挑战很火热,问模型“9.11和9.8哪个更大,就这一个简单问题,结果大模型集体翻了车。虽然答案显而易见,但大模型可能会因为缺乏直接的文本相关性而犹豫不决。这并非模型无法理解数字的大小关系,而是其训练方式和数据结构导致的局限性。
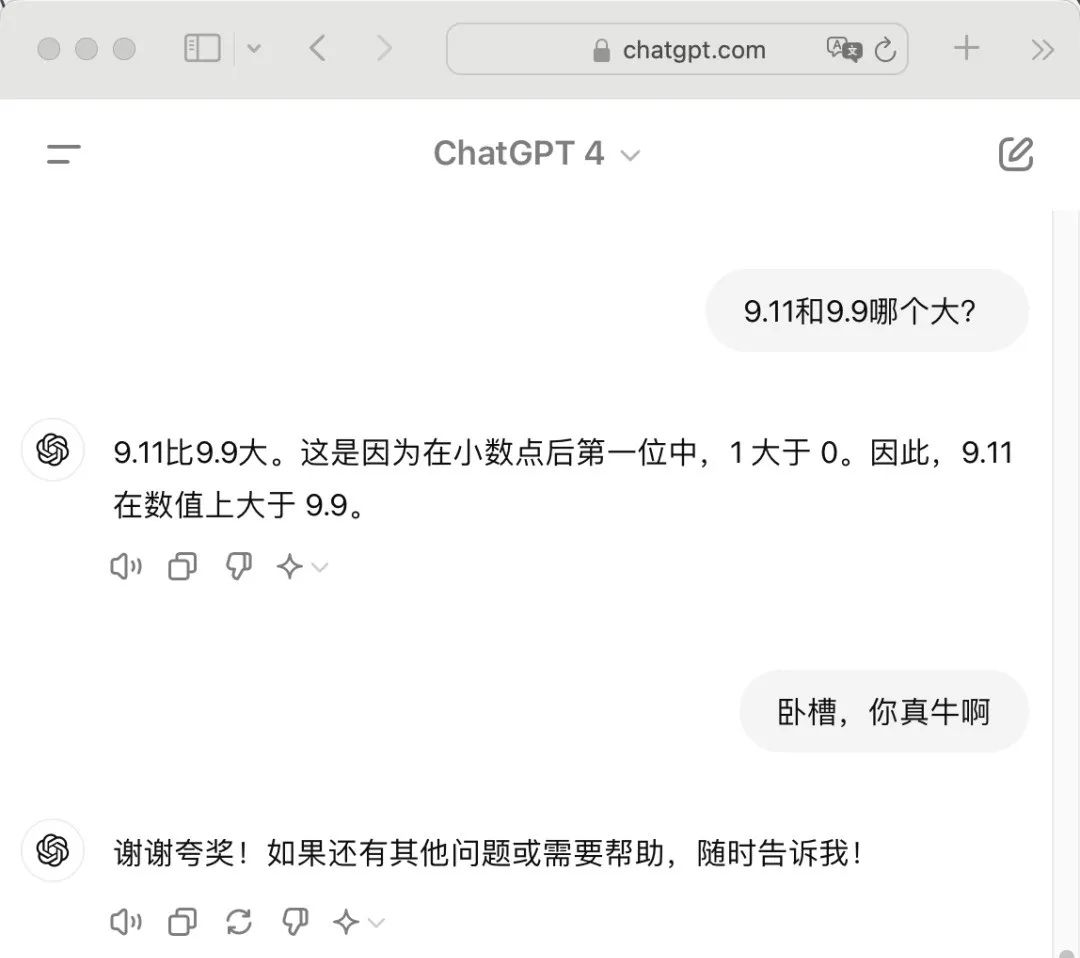
在大语言模型中,Tokenizer会将输入文本拆分转换成更小的部分(词元tokens)供模型处理。而Tokenizer并没有专门为数学设计,这导致数字在分割时可能被拆成不合理的部分,破坏了数字的整体性,使得模型难以理解和计算这些数字。这种局限性在处理更复杂的数理逻辑问题时尤为明显。
这种局限性对大模型的性能和应用产生了深远的影响。一方面,它限制了大模型在需要复杂推理和逻辑判断的任务上的表现。例如,在解决数学问题、编写复杂代码或进行深入的科学分析时,大模型无法像人类专家那样准确和深入。另一方面,这种局限性也影响了大模型在某些领域的实际应用价值。尽管大模型能够生成流畅的文本,但在需要精确和逻辑严密性的场景中,它们的表现可能并不尽如人意。
因此,为了突破这些局限性,研究人员正在探索新的模型架构和学习方法。OpenAI的「草莓」模型就是一个典型的例子,它通过引入自我对弈强化学习(self-play RL)等新范式,试图让大模型在保持快速思考的同时,增强数理推理和逻辑判断的能力。这种创新不仅有望直接提升大模型的性能,同时引入的新的范式中间思考的过程可以再次生成高质量的数据为下一代的GPT-5提供新的数据,切实解决当下的数据困境。
03 快思考与慢思考
在探讨大模型的思维模式时,我们不得不提及认知心理学家、诺贝尔经济学奖得主丹尼尔·卡尼曼的著作《思考快与慢》。卡尼曼在书中提出了人类思维的两种系统:系统一和系统二。系统一代表快速、直觉性思考,而系统二则代表慢速、理性思考。这两种思考方式在人类决策过程中起着不同的作用,而这种区分也为我们理解大模型的运作方式提供了新的视角。
快思考与慢思考的区别
快思考,也称为系统1,是指人类大脑的直觉反应和自动处理过程。它依赖于经验和记忆,能够迅速做出判断,但往往缺乏深度和准确性。
慢思考,即系统2,则是逻辑推理和分析的过程,需要更多的时间和精力,但能够得出更为准确和全面的结论。

把卡尼曼的思考快与慢理论放到到大模型中来看,我们可以看到传统大模型主要依赖于系统一的思考方式。它们快速捕捉信息之间的相关性,就像是一个百科全书,能够迅速给出答案,但往往缺乏深思熟虑的逻辑性。这种快思考的方式在处理简单任务时表现出色,但在面对复杂问题时却显得力不从心。
相比之下,「草莓」模型则更接近系统二的思考方式。它注重深度和逻辑性思考,能够在响应之前花费10到20秒的时间进行深思熟虑。这种慢思考的方式使得「草莓」模型在处理复杂问题时更加得心应手,特别是在数理推理和逻辑性思考方面。
大模型如何结合快思考与慢思考的优势
为了更好地结合快思考与慢思考的优势,大模型需要借鉴自我对弈强化学习(self-play RL)的方法。这种学习方式类似于一个孩子通过不断和自己下棋来提升棋艺。通过自我对弈,模型能够在不断尝试和反馈中,从相关性学习转向因果性学习,从而提升推理能力和准确性。
具体来说,大模型可以通过以下方式结合快思考与慢思考的优势:
快速响应与深度推理的结合:在处理简单问题时,模型可以利用快思考迅速生成初步回答;在处理复杂问题时,则可以通过慢思考进行深度推理,确保回答的准确性和全面性。
自我对弈强化学习:通过自我对弈,模型能够在不断尝试和反馈中优化推理过程,提升因果性理解能力。这种学习方式不仅能够减少错误和偏见,还能够生成高质量的训练数据,助力模型的持续进化。
思维链提示:在回答问题时,模型可以生成多个可能的思路,并对这些思路进行评估和选择。这种思维链提示的方式能够让模型在推理过程中不断学习和改进,从而提升整体推理能力。
大模型通过结合快思考与慢思考的优势,能够在快速响应和深度推理之间找到平衡点,提升整体的推理能力和准确性。这不仅有助于模型更好地解决复杂问题,还能够为用户提供更为智能和个性化的服务。
04 解决之道
Self-Play Reinforcement Learning
在探讨了强化学习(RL)对大型语言模型(LLM)范式的潜在影响后,我们不禁思考:如何才能真正实现这一技术突破?答案或许就隐藏在Self-Play Reinforcement Learning(自我对弈强化学习,简称Self-Play RL)之中。
Self-play RL本质上是通过让模型不断与自己对弈,生成和评估多个可能的思路,最终选择最佳的一个。这种方法的核心在于从相关性学习到因果性学习的飞跃,从而大幅提升模型的推理能力。
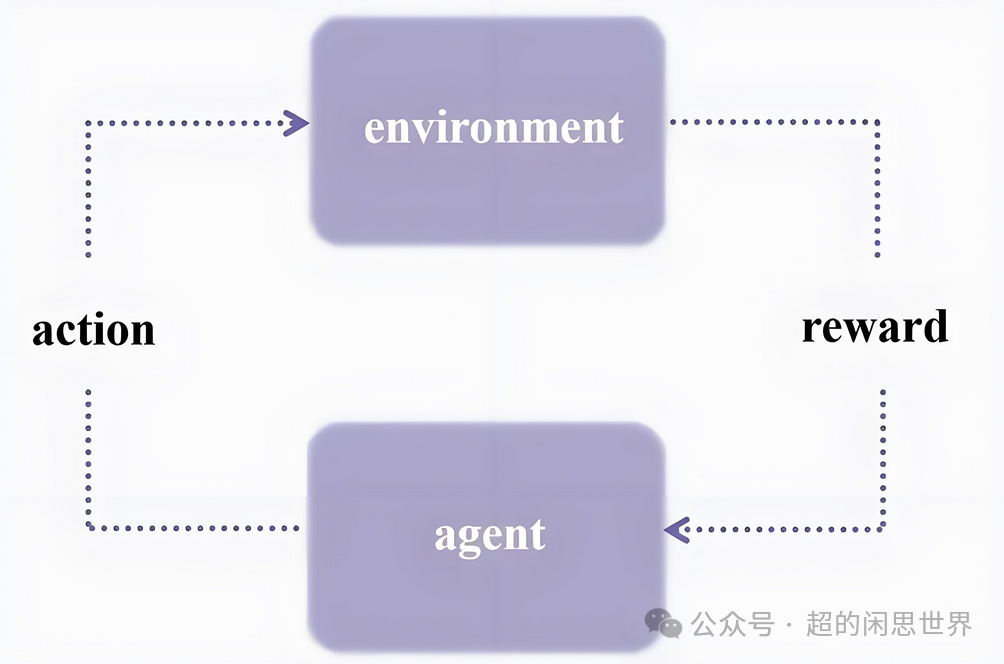
想象一下,一个孩子学习下围棋。传统的学习方式是看棋谱,记住开局布置,背诵一些固定的战术。这种方式虽然能够快速掌握一些基本技巧,但在面对复杂局面时却显得力不从心。而Self-play RL则像是让孩子不停地和自己下棋。刚开始可能下得很糟糕,但通过不断尝试不同的走法,观察每步棋的结果,孩子会逐渐发现哪些策略更有效,哪些走法会输。这个过程中,孩子不仅仅是在记住棋谱,而是在真正理解棋局的变化,理解每一步棋为什么要这样走。
这种从相关性学习到因果性学习的飞跃,使得模型在处理复杂问题时更加得心应手,特别是在数理推理和逻辑性思考方面。
Self-Play策略
最核心的路径就是如何优化Self-Play策略,多角色模拟是一个值得尝试的方向,不仅让AI与自己对弈,还可以模拟不同角色之间的互动。例如,在编程任务中,可以让AI同时扮演开发者、测试员和用户。此外,采用课程学习的思想,从简单任务开始,逐步增加难度,有助于模型更有效地学习和泛化。在Self-Play过程中,平衡探索新策略和利用已知有效策略也至关重要,可以通过调整温度参数或使用UCB等算法来实现。同时,引入长期记忆机制,使模型能够从过去的经验中学习,而不是每次都从头开始。
Process learning 保证了推理思考过程得到评估,Curriculum learning 为了让思考过程得到由浅入深、循序渐进的引导
跨领域泛化
在Self-Play过程中,模型的数理逻辑推理能力得到了有效的提升,接下来不可避免的就是跨领域泛化的问题。如何让通过Self-Play RL获得的能力在不同领域之间泛化,是实现真正AGI的关键。训练模型学习如何学习,而不仅仅是学习特定任务,可以通过设计特殊的Self-Play任务来实现,例如让模型在短时间内适应新的游戏规则。
鼓励模型在Self-Play过程中形成抽象概念,有助于知识在不同领域之间迁移。在Self-Play过程中交替进行不同类型的任务,也能促进模型建立跨领域的联系。此外,培养模型进行类比推理的能力,这是人类智能的一个关键特征,也是实现跨领域泛化的重要途径。
优势与成本
Self-play RL的优势显而易见。它能够显著提升模型的推理能力,特别是在数理推理和逻辑性思考方面。通过不断生成和评估多个可能的思路,模型能够选择最佳的一个,从而提供更加准确和可靠的答案。
然而,这种优势并非没有代价。Self-play RL的推理成本非常高,每次推理回答可能消耗100K token,约6美元。这种高成本也使得Self-play RL在实际应用中面临很大的阻力,特别是在大规模部署时。
05 未来何在?
在通向通用人工智能AGI之路上,我们看到了OpenAI「草莓」模型带来的新希望,也看到了目前切实存在的问题。
一方面,Self - Play Reinforcement Learning 等新技术的出现为大模型的发展开辟了新的道路。虽然它目前推理成本较高,但随着技术的不断优化与创新,我们有理由相信成本问题会逐步得到缓解。或许会探索出更高效的算法,或者找到新的计算架构来降低成本,使这种强大的学习方式能够在更广泛的领域中得到应用。
另一方面,大模型在快思考与慢思考的结合上还有很大的发展空间。如何更加智能地判断何时使用快思考迅速响应,何时启动慢思考进行深度推理,将是未来研究的重点之一。通过不断优化这种结合机制,大模型有望在各种复杂场景中都能发挥出最佳性能,为用户提供更高效、更精准的服务。
从更宏观的角度来看,大模型的发展将推动人工智能领域迈向一个新的阶段。我们正逐渐从简单的信息处理和生成走向更深入的逻辑推理与跨领域智能。最近一年的进展,似乎许多人对AGI的梦想又破灭了,但是人们总是会无限高估一项新技术的诞生,又会低估其在未来长远的影响。或许,随着像「草莓」这样的模型不断涌现以及相关技术的持续进步,真正的通用人工智能(AGI)不再是遥不可及的梦想。
