专属文生图助手——SD3+ComfyUI文生图部署步骤
SD3+ComfyUI文生图部署步骤
我们使用DAMODEL来实现文生图的部署。
根据提供的操作步骤与代码段落,本文旨在介绍如何下载并部署 Stable Diffusion 3 模型,并通过 ComfyUI 架构实现基于 Web 界面的图像生成应用。本文将剖析各个步骤,并详细解释背后原理,以帮助读者理解这些操作的目的和功能。
一、文生图简介与工作流程
“文生图” 指的是通过输入文本(文本提示词)生成图像的技术,通常使用大规模的深度学习模型进行图像合成。这类模型,例如 Stable Diffusion,可以根据用户提供的描述生成高质量、逼真的图像。Stable Diffusion 3(SD3)是该技术的第三代版本,能够更加精准和细致地理解复杂文本,并生成匹配描述的视觉内容。
为了实现文生图的功能,本指南将使用 ComfyUI 作为 WebUI(用户界面),并部署 Stable Diffusion 3 模型,最终使得用户可以通过浏览器界面输入文本并生成相应的图像。
二、准备工作
在开始实际操作之前,我们需要确保系统满足一定的条件,特别是环境中的依赖项和工具。
2.1 系统要求
- 操作系统:Linux 环境(其他系统可能需要进行相应调整)
- Python 环境:确保 Python 已安装并可用
- Git 工具:用于克隆项目代码
- 网络连接:用于下载模型和依赖项
- NVIDIA GPU:建议使用以加速深度学习任务
三、详细操作步骤
3.1 进入 DAMODEL 控制台
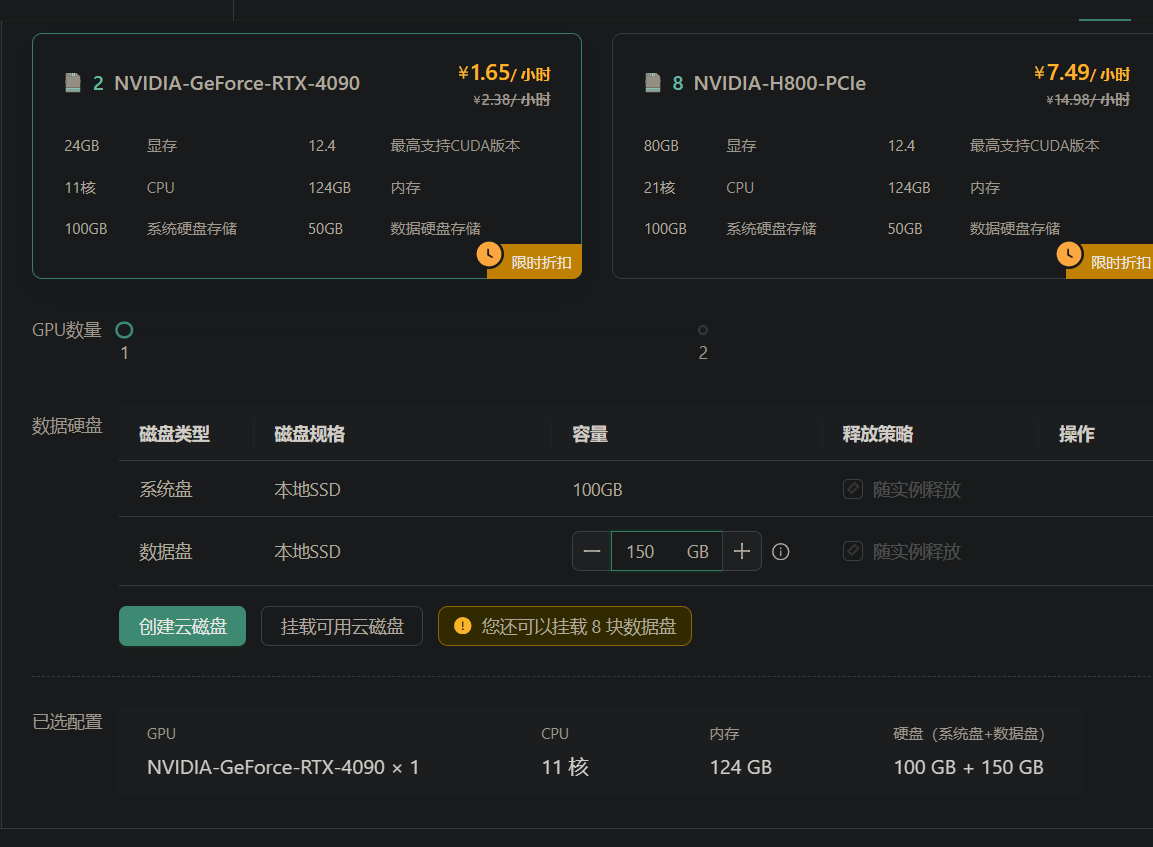
- 登录 DAMODEL 控制台,点击 “资源管理” > “GPU 云实例”。
- 选择 创建实例。在配置页面,选择 GPU 型号,根据任务需求选择如 NVIDIA RTX 4090 等高性能 GPU 实例。
- 配置数据硬盘,推荐150GB 足够使用。也可以根据需求增加存储空间。
- 在镜像配置中,选择带有 PyTorch 框架的镜像,这将自动配置深度学习所需的基础环境,建议使用 PyTorch 2.3.0 或更高版本。
- 创建完成后,等待实例启动。
3.1 从 Hugging Face 镜像下载 Stable Diffusion 3 模型
Hugging Face 是一个提供预训练模型的平台。由于在某些地区直接访问 Hugging Face 可能存在网络问题,本文使用 Hugging Face 镜像站点 hf-mirror 来获取模型文件。下载模型的步骤如下:
首先,确保 Hugging Face 客户端工具 huggingface_hub 已更新到最新版本:
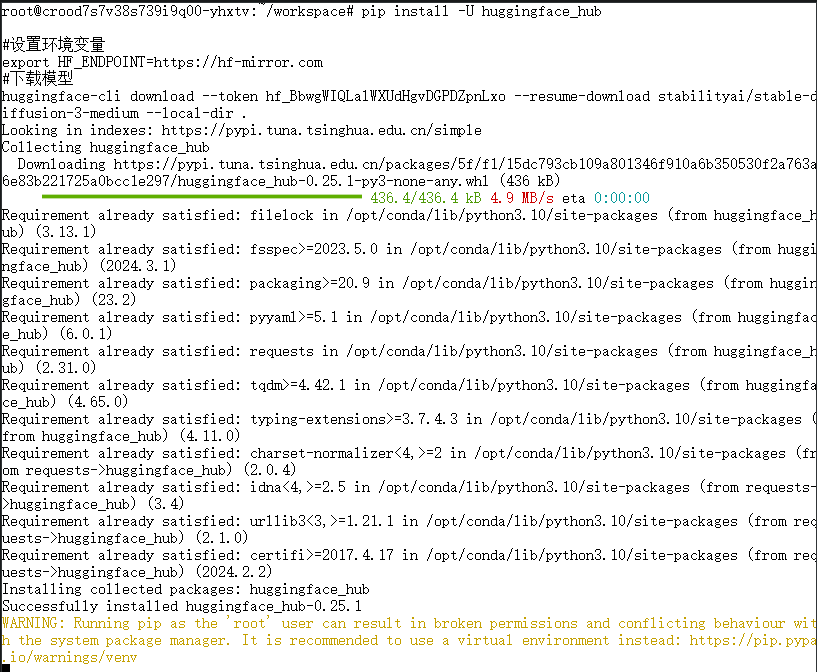
pip install -U huggingface_hub
设置 Hugging Face 镜像站点
为确保下载流畅,我们需要设置环境变量,将 Hugging Face 的镜像站点地址指定为 https://hf-mirror.com:
export HF_ENDPOINT=https://hf-mirror.com
使用 Hugging Face CLI 下载模型
接下来,通过 Hugging Face CLI(命令行接口)工具下载 Stable Diffusion 3 的中等规模模型:
huggingface-cli download --token hf_BbwgWIQLalWXUdHgvDGPDZpnLxo --resume-download stabilityai/stable-diffusion-3-medium --local-dir .
这里的 --token 参数用于提供访问 Hugging Face 的认证令牌,--local-dir . 则将模型下载到当前目录。
注意:下载模型的速度取决于网络连接,模型文件可能比较大,下载过程中请耐心等待。
3.2 安装 Git
Git 是用于版本控制的工具,特别是当我们需要从 GitHub 上克隆项目时,Git 是不可或缺的工具。
安装 Git 的步骤如下:
apt-get update
apt-get install git
该命令首先更新系统的包管理器,然后安装 Git 工具。

3.3 安装 ComfyUI
ComfyUI 是一个为 Stable Diffusion 等模型提供的图像生成用户界面。它通过 WebUI 允许用户直接在浏览器中与模型进行交互。通过 ComfyUI,我们能够输入文本,并得到相应的图像输出。接下来将介绍如何安装并启动 ComfyUI。
克隆 ComfyUI 项目
首先,通过 Git 克隆 ComfyUI 项目:
git clone https://github.com/comfyanonymous/ComfyUI.git
该命令会将 ComfyUI 项目代码下载到本地,供后续使用。

安装依赖
项目克隆完成后,进入 ComfyUI 目录并安装依赖项:
pip install -r requirements.txt --ignore-installed
该命令将安装项目所需的所有 Python 依赖项。--ignore-installed 参数确保强制重新安装依赖项,避免版本冲突或不兼容的问题。
启动 ComfyUI 服务
在依赖项安装完成后,可以通过以下命令启动 ComfyUI 服务:
python main.py --listen
该命令会启动一个本地服务器,ComfyUI 的 Web 界面将可以通过浏览器访问。--listen 参数让服务器监听外部请求,这意味着你可以从本地网络访问该服务。
3.4 访问与测试
当服务启动成功后,你可以在浏览器中输入服务器的地址(如 http://localhost:7860)来访问 ComfyUI 界面。接着你可以在界面上输入文本提示,例如 “a girl running under the starry sky”(一个在星空下奔跑的女孩),ComfyUI 将通过加载的 Stable Diffusion 3 模型生成一张与描述相符的图像。
四、ComfyUI 的优势
ComfyUI 作为文生图生成应用的前端,它有几个显著的优势:
- 简便易用:用户可以通过简洁直观的 Web 界面直接输入文本,生成图像。
- 灵活性高:支持不同的文本提示词,同时允许调整模型的参数以生成不同风格和细节的图像。
- 开源与社区支持:ComfyUI 是一个开源项目,拥有广泛的社区支持和插件扩展,用户可以根据自己的需求进行自定义和优化。
五、总结
。
2. 灵活性高:支持不同的文本提示词,同时允许调整模型的参数以生成不同风格和细节的图像。
3. 开源与社区支持:ComfyUI 是一个开源项目,拥有广泛的社区支持和插件扩展,用户可以根据自己的需求进行自定义和优化。