【JVM】JVM执行流程和内存区域划分
是什么
Java 虚拟机
- JDK,Java 开发工具包
- JRE,Java 运行时环境
- JVM,Java 虚拟机
JVM 就是 Java 虚拟机,解释执行 Java 字节码
JVM 执行流程
编程语言可以分为:
- 编译型语言:先将高级语言转换成二进制的机器指令,再由 CPU 去直接执行
- 解释型语言:一边去转换,一边去执行
这样的说法放单今天,硬件不适用了
按照上述这种经典的划分方式,可以认为 Java 属于“半编译,半解释”。Java 这么设定,最主要的目的就是为了“跨平台”。
- 像 C++这样的语言是直接编译成了二进制的机器指令,而不同的
CPU支持的指令不一样,而且生成的可执行程序,在不同的系统上也有不同的格式Windows可执行程序:PE格式Linux可执行程序:ELF格式
当前看到的手机操作系统,为什么只有安卓、iOS?
- 因为搞一个新的系统,现有的软件不能兼容,没有生态也就没有市场
- 鸿蒙能直接运行安卓程序,是因为鸿蒙不是新系统,只是安卓套壳
Java 不想重新编译,而是期望能够直接执行
- 先通过
javac把.java文件==>.class文件(字节码文件,包含的就是Java字节码,Java自己搞的一套CPU指令)- 因为如果生成
CPU直接能执行的指令的话,不同的CPU支持的指令就不一样,就不能在所有系统上执行
- 因为如果生成
- 这样先把
java代码转成对应的java字节码文件,然后在某个具体的系统平台上执行,此时通过JVM把上述的字节码转换成对应的CPU能识别的机器指令(JVM就是一个翻译官的角色)
通过上述转换,我们就可以不去重新编译,也能够完成良好的跨平台。因此,我们编写和发布一个 java 程序,其实就只要发布 .class 文件就可以了,JVM 拿到 .class 文件之后,就知道如何转换
Windows上的JVM就可以把.class转换成Windows上能支持的可执行指令了Linux上的JVM就可以把.class转换成 Linux 上可以支持的可执行指令了
不同平台的局面是存在差异的,而不是同一个。对上(给java层面上提供的内容)是统一一致的
内存区域划分
JVM 其实也是一个进程(任务管理器中看到的 java 进程)
进程运行过程中,要从操作系统这里车身轻一些资源(内存就是其中的典型资源),这些内存空间就支撑了后续 java 程序的执行。
- 比如,在
java中定义变量(就会申请内存),内存其实就是JVM从系统这边申请到的内存,然后再交给具体的java程序去使用
JVM 从系统申请了一大块内存,这一大块内存给 java 程序使用的时候,又会根据实际的使用用途,来划分出不同的空间,这就是所谓的“区域划分”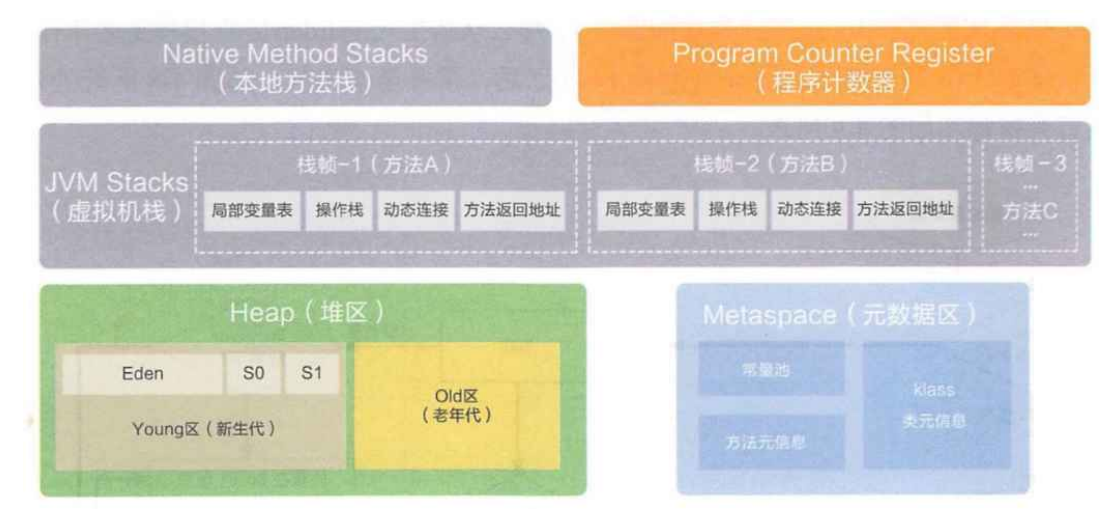
堆
代码中 new 出来的对象,都是在堆里。对象中持有的非静态成员变量,也都在堆里。只有一份
- 静态成员变量在元数据区
栈
本地方法栈/虚拟机栈。包含了方法调用关系和局部变量
- 在代码执行过程中,肯定会涉及到很多方法的调用,调用的关系就通过栈空间记录下来
- 虚拟机栈,记录了
Java代码的调用关系,Java代码的局部变量 - 本地方法栈,记录了
JVM内部,通过C++写的代码的调用关系和局部变量
一般不会关注本地方法栈,一般来说谈到栈,就默认指的是“虚拟机栈”
这里谈到的“堆“和“栈“,和数据结构中的“堆“和“栈“是不同的。这里的是两块区域
程序计数器
这个区域比较小,专门用来存储下一条要执行的 Java 指令的地址
元数据区
“元数据”是计算机中的一个常见术语(meta data),往往指的是一些辅助性质的,描述性质的属性。只有一份
比如:硬盘上不仅仅要存储数据本体,还要存储一些辅助信息:文件的大小、文件的位置、文件的拥有者、文件的修改时间、文件的权限信息… 这些辅助信息统称为“元数据”
在以前的 Java 版本中,也叫做“方法区”,从 1.8 开始改的名字
云数据区中主要保存:
- 类的信息
- 方法的信息
一个程序,有哪些类、每个类里都有哪些方法、每个方法里面都要包含哪些指令,都会记录在元数据区。
我们写的 Java 代码,if、while、for 等各种逻辑运算,这些操作都会被转换成 Java 字节码
javac就会完成上述代码到字节码的转换- 此时这些字节码在程序运行的时候就会被
JVM加载到内存中,放到元数据区(方法区)里面 - 之后,当前程序要如何执行,要做哪些事情,就会按照上述元数据区里面记录的字节码一次执行了
我们所编写的代码,都会被转换成二进制指令,都会进入到内存中,然后才能执行。
类似于剧本杀
- 剧本杀里面给美格玩家发一个剧本,每个玩家就按照剧本上给出的要求来演
- 此处所谓 Java 字节码,要执行的方法的细节,就像剧本一样,需要把剧本加载到内存中,然后才能执行
堆和元数据区只有一份(所有线程共享一份),栈和程序计数器可能有 n 份(和线程相关,每个线程都有自己的程序计数器和栈(每个线程有自己的执行流))
经典笔试题
在下面代码中,t、n、m 分别处于 JVM 内存中的哪个区域?
class Test() {
private int n;
private static int m;
}
main() {
Test t = new Text();
}
t是一个局部变量(引用类型),在栈上n是Test的成员变量,new出来的Test是在堆上的,所以n作为成员变量也是处于堆上static修饰的变量,称为“类属性”;static修饰的方法,称为“类方法”- 非
static修饰的变量,称为“实例属性”;非static修饰的方法,称为“实例方法” - 所以这里的
m是长在类上的成员,和new不new实例没有关系。上述带有static修饰的变量,就是在类对象中,也就是在元数据区中(方法区)
类对象,
Test.class
JVM把.class文件加载到内存之后,就会把这里的信息使用对象来表示,此时这样的对象就是类对象- 类对象里就包含了一系列的信息,包括但不限于:
- 类的名称
- 类继承自那个类
- 实现了哪些接口
- 都有哪些成员,都叫什么,都是什么类型,都是什么权限
- 都有哪些方法,都叫什么,都是什么参数,都是什么权限
.java文件中涉及到的信息都会在.class中有所体现(注释是不会包含的)
区分一个变量在哪个内存区域中,最主要的就是看变量的形态
- 局部变量
- 成员变量
- 静态成员变量
- …