新闻文本分类识别系统Python+卷积神经网络算法+人工智能+深度学习+计算机毕设项目+TensorFlow+Django网页界面
一、介绍
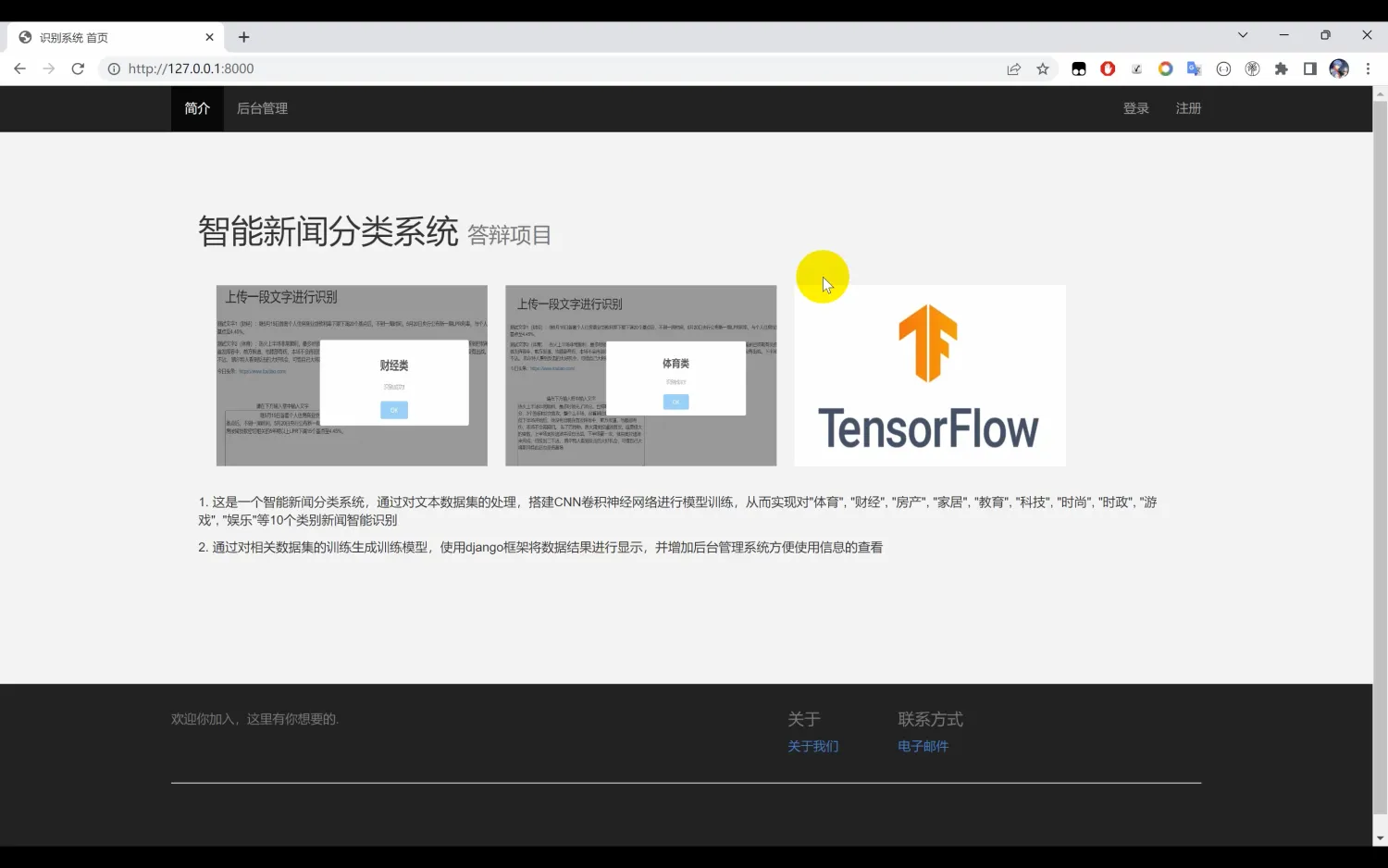
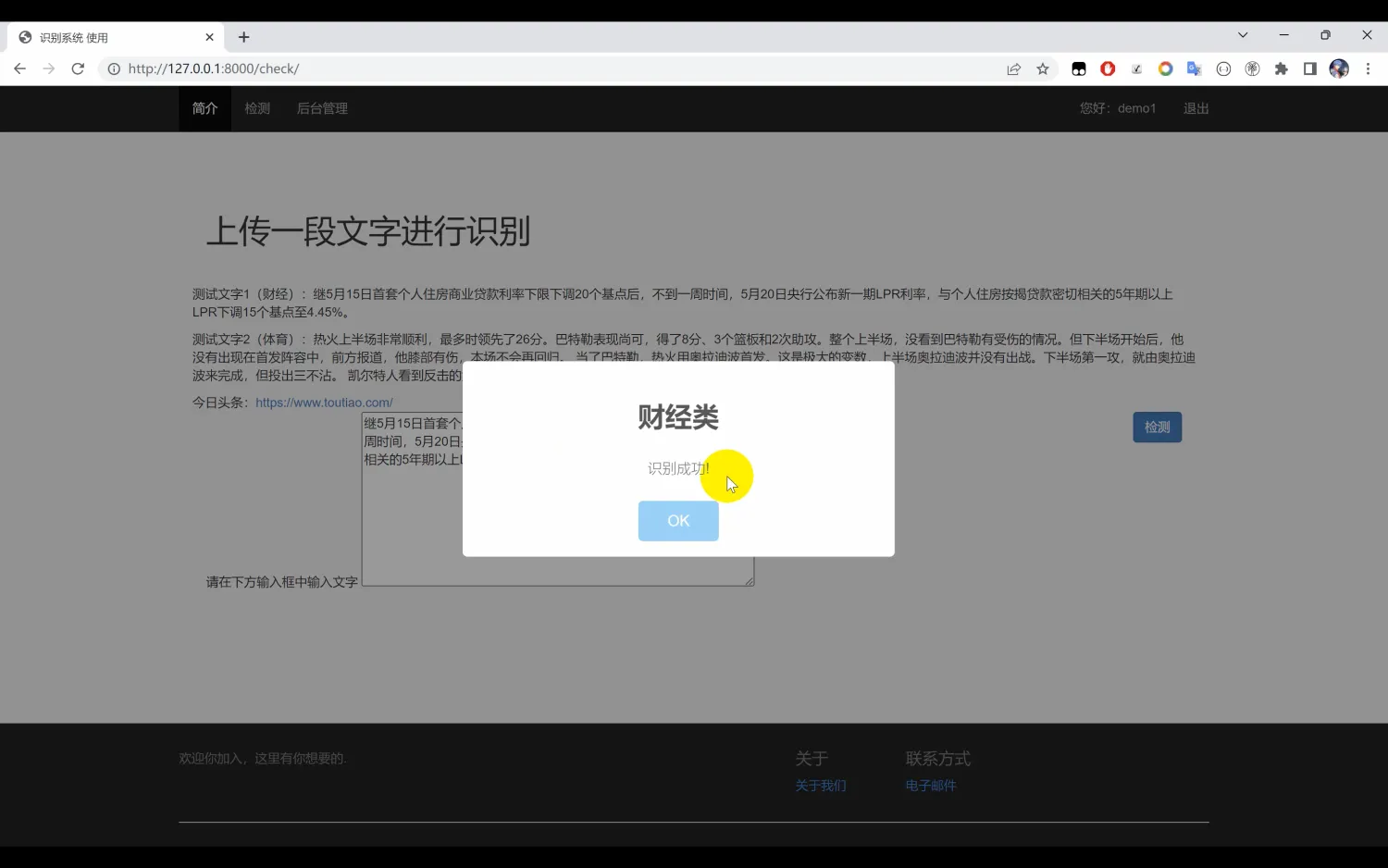
文本分类识别系统。本系统使用Python作为主要开发语言,首先收集了10种中文文本数据集(“体育类”, “财经类”, “房产类”, “家居类”, “教育类”, “科技类”, “时尚类”, “时政类”, “游戏类”, “娱乐类”),然后基于TensorFlow搭建CNN卷积神经网络算法模型。通过对数据集进行多轮迭代训练,最后得到一个识别精度较高的模型,并保存为本地的h5格式。然后使用Django开发Web网页端操作界面,实现用户上传一段文本识别其所属的类别。
随着信息技术的迅猛发展,文本数据的生成和传播呈现出指数级增长。这使得从海量文本中提取有价值信息的需求愈发迫切。文本分类作为自然语言处理(NLP)中的一个重要任务,旨在自动识别和分类文本内容,使得用户能够快速获取所需信息并提高信息检索的效率。本项目旨在开发一个中文文本分类识别系统,通过构建高效的模型来实现对不同类别文本的准确识别。
本系统使用Python作为主要开发语言,依托于TensorFlow框架,采用卷积神经网络(CNN)算法模型进行文本分类。我们首先收集了10种不同类型的中文文本数据集,包括体育、财经、房产、家居、教育、科技、时尚、时政、游戏和娱乐等类别。这些数据集为模型的训练提供了丰富的样本,并覆盖了多样化的主题。
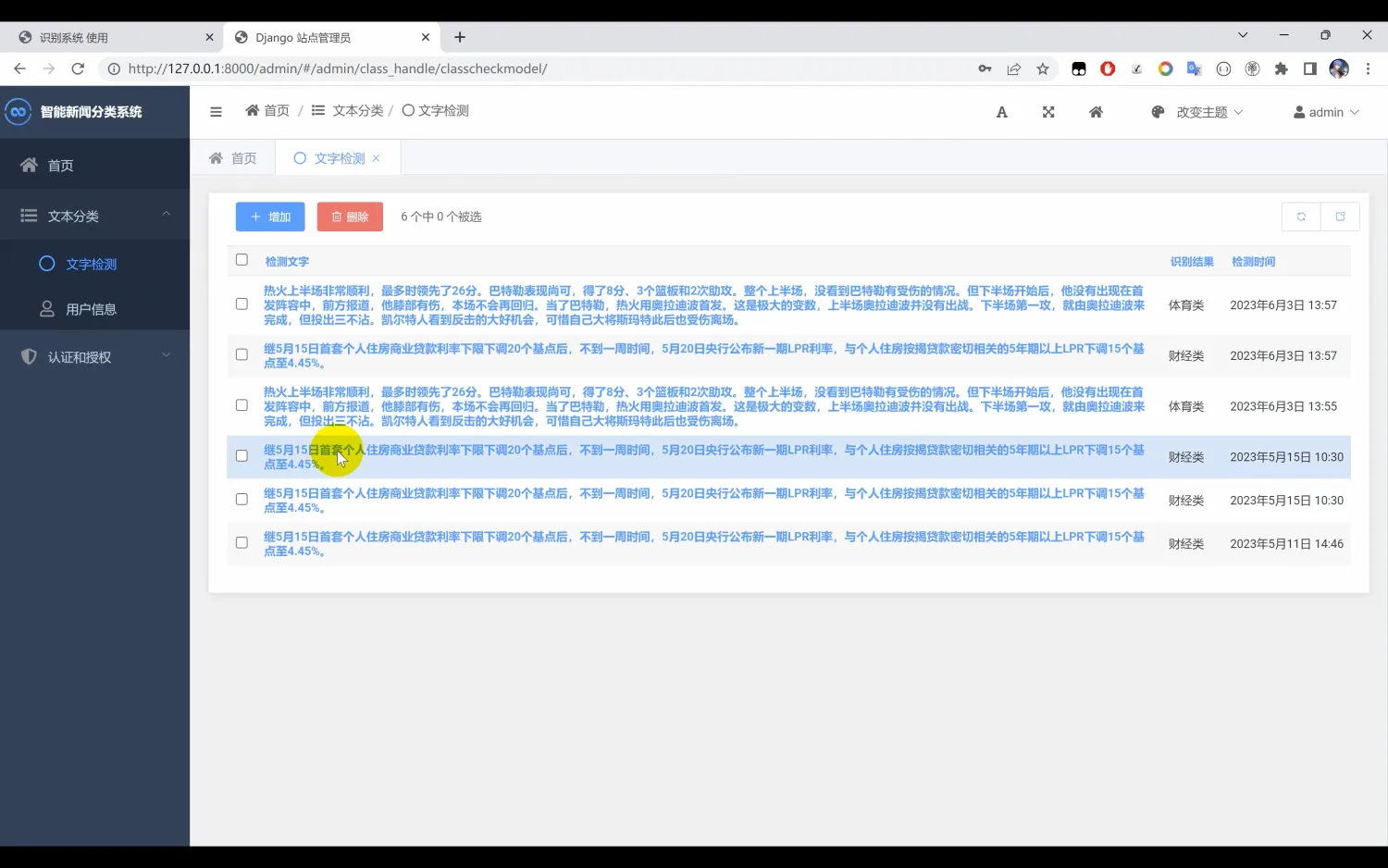
在模型训练过程中,经过多轮的迭代,调整超参数与网络结构,最终得到了一个具有较高识别精度的模型。该模型以h5格式保存,便于后续的调用与部署。此外,为了提升用户体验,我们还使用Django框架开发了Web操作界面,使用户能够方便地上传文本,并实时获得其所属类别的识别结果。
本项目不仅展示了深度学习在文本分类领域的应用潜力,还为未来的智能信息处理和检索系统奠定了基础。通过持续优化模型和扩展数据集,我们希望能够进一步提升分类准确率,以满足更广泛的实际需求。
二、系统效果图片展示
三、演示视频 and 完整代码 and 远程安装
地址:https://www.yuque.com/ziwu/yygu3z/dm2c902i8cckeayy
四、卷积神经网络算法介绍
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像和文本数据的处理。其主要特点包括:
- 局部连接:CNN通过局部感受野的方式连接相邻的神经元,允许网络捕捉局部特征,从而减少参数数量,提高模型的效率。
- 权重共享:在同一卷积层中,使用相同的卷积核(滤波器)处理不同位置的输入,降低了模型复杂度,并增强了模型的泛化能力。
- 多层次特征提取:CNN通过多层结构逐层提取特征,从低级特征(如边缘、角点)到高级特征(如形状、对象),使得模型在面对复杂数据时更具鲁棒性。
- 下采样:通过池化层(如最大池化和平均池化),CNN有效降低了特征图的维度,减少计算量,并增强了模型的平移不变性。
以下是一个使用TensorFlow和Keras构建简单卷积神经网络的代码示例:
import tensorflow as tf
from tensorflow.keras import layers, models
# 构建模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax') # 10个类别
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型摘要
model.summary()
此示例中,我们构建了一个简单的卷积神经网络,包含卷积层、池化层和全连接层,适用于图像分类任务。通过这些特征,CNN能够有效处理各种数据,提高模型的性能。