【论文】FunAudioLLM:一个旨在增强人类与大型语言模型(LLMs)之间自然语音交互的模型家族
研究背景
1.研究问题:这篇文章要解决的问题是如何增强人类与大型语言模型(LLMs)之间的自然语音交互。具体来说,研究集中在语音识别、情感识别和音频事件检测(多语言)以及语音生成(多语言、零样本学习、跨语言语音克隆和指令跟随能力)两个方面。
2.研究难点:该问题的研究难点包括:实现低延迟的多语言语音识别;在多语言环境中进行高精度的语音识别;生成自然且具有情感表达的多语言语音;以及在零样本情况下进行语音克隆和指令跟随。
3.相关工作:该问题的研究相关工作包括GPT-4o、Gemini-1.5等高性能语言模型的发展,以及高精度语音识别、情感识别和语音生成技术的进步。
研究方法
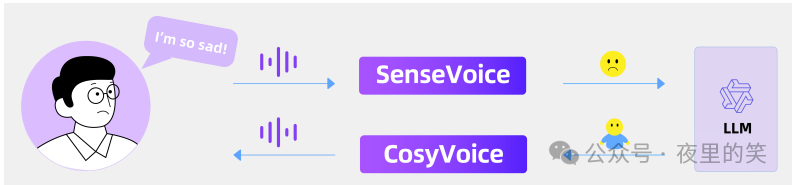
这篇论文提出了FunAudioLLM框架,用于解决人类与LLMs之间的自然语音交互问题。具体来说,
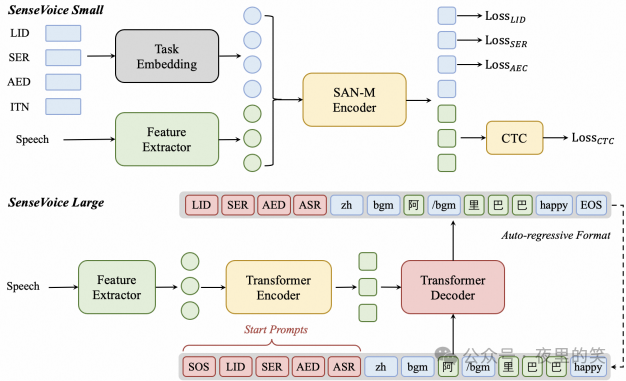
1.SenseVoice模型:SenseVoice模型用于语音理解,支持多语言语音识别、情感识别和音频事件检测。SenseVoice-Small是一个非自回归的编码器模型,适用于快速语音理解,支持五种语言(中文、英语、粤语、日语和韩语),推理延迟小于80ms,速度比Whisper-small快5倍以上,比Whisper-large快15倍以上。SenseVoice-Large是一个自回归的编码器-解码器模型,支持超过50种语言的语音识别,特别在中文和粤语上表现优异。
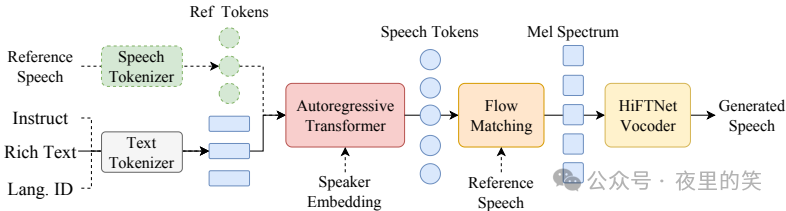
2.CosyVoice模型:CosyVoice模型用于语音生成,支持多语言语音生成,具有零样本学习、跨语言语音克隆、情感共振语音生成和指令微调等功能。CosyVoice-base-300M模型专注于准确表示说话人身份、零样本学习和跨语言语音克隆。CosyVoice-instruct-300M模型通过指令文本生成情感丰富的语音,并允许对说话人身份、说话风格等进行细致调整。CosyVoice-sft-300M模型在七个多语言说话人上进行微调,准备立即部署。
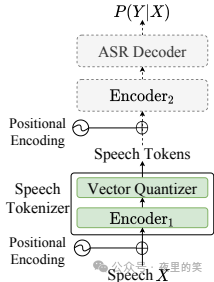
3.语义语音分词器:为了提高系统性能和减少对高质量数据的需求,论文提出了一种监督语义语音分词器S3S3。该分词器基于预训练的SenseVoice-Large模型,在编码器的初始六层之后引入一个向量量化器,增强了时间信息。
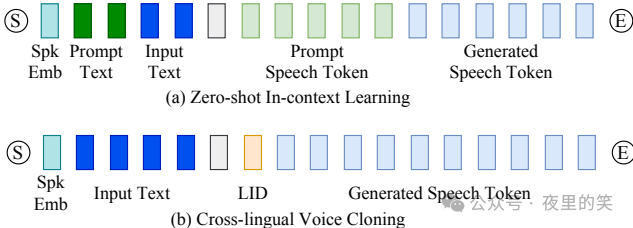
4.零样本上下文学习和指令微调:CosyVoice模型展示了零样本上下文学习能力,允许通过简短的参考语音样本复制任意声音。此外,CosyVoice-instruct模型通过指令文本进一步增强了可控性,支持说话人身份、说话风格和细粒度副语言特征的控制。
实验设计
1.数据集:SenseVoice模型的训练数据集包括约300,000小时的音频数据,覆盖五种语言(中文、粤语、英语、日语和韩语)。为了进一步提升SenseVoice-Large的多语言能力,额外整合了100,000小时的多语言数据。CosyVoice模型的训练数据集包括多种语言,使用内部工具进行语音检测、信噪比估计、说话人分离和分离。
2.评估指标:多语言语音识别使用字符错误率(CER)和词错误率(WER)进行评估。情感识别使用未加权平均准确率(UA)、加权平均准确率(WA)、宏平均F1分数(F1)和加权平均F1(WF1)进行评估。音频事件检测使用F1分数进行评估。
3.实验设置:在A800机器上进行推理效率评估,解码批处理大小为1。对于编码器-解码器模型,使用束搜索解码,束大小为5。
结果与分析
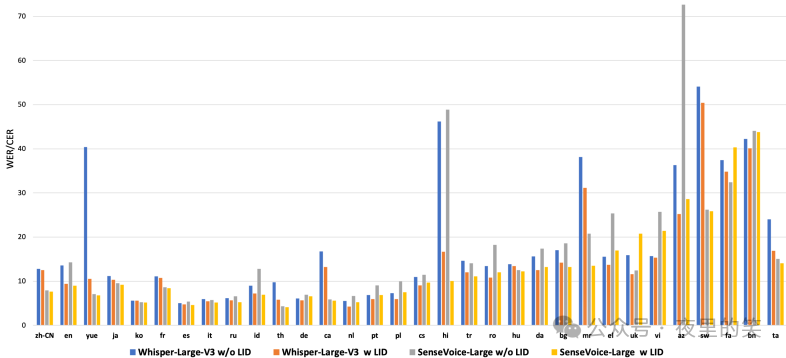
1.多语言语音识别:SenseVoice-S和SenseVoice-L在大多数测试集上显著优于Whisper模型,特别是在粤语、加泰罗尼亚语和马哈拉施特拉语上表现优异。SenseVoice-S的推理延迟比Whisper-small快5倍以上,比Whisper-large快15倍以上。
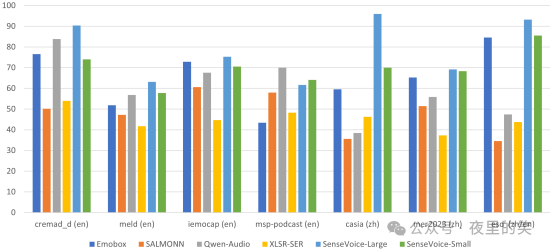
2.情感识别:SenseVoice-Large在所有测试集和所有指标上表现最佳,SenseVoice-Small在大多数数据集上也优于其他基线模型。
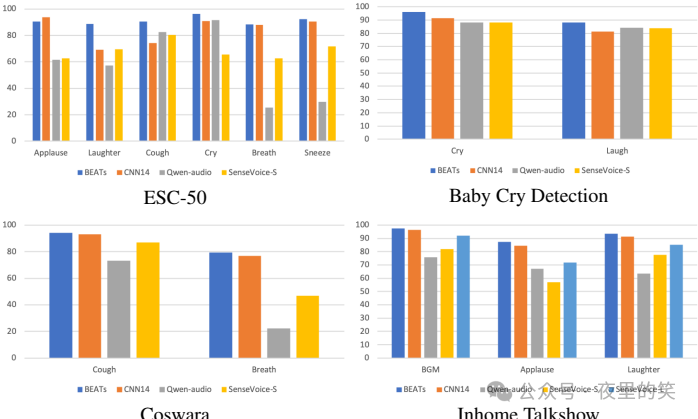
3.音频事件检测:SenseVoice模型在音频事件分类或检测方面表现良好,尽管BEATS和PANNs可能在某些任务上具有更高的F1分数。
4.语义信息保留:S3分词器在中文和英语测试集上展示了强大的识别性能,在Common Voice zh-CN集上,S3分词器比Whisper-Large V3模型的错误率降低了4.14%。
5.生成质量:CosyVoice在英语和中文生成质量评估中表现出色,内容一致性和说话人相似性均达到人类水平。通过ASR重排序,CosyVoice的WER显著降低。
6.情感控制:CosyVoice-instruct在情感控制方面表现优异,情感指令输入下的情感识别准确率显著提高。
总体结论
这篇论文提出的FunAudioLLM框架通过SenseVoice和CosyVoice两个创新模型,显著提升了人类与LLMs之间的自然语音交互能力。SenseVoice模型在多语言语音识别和情感识别方面表现优异,而CosyVoice模型在多语言语音生成和控制方面具有显著优势。FunAudioLLM框架的应用包括语音翻译、情感语音聊天、互动播客和富有表现力的有声书叙述,推动了语音交互技术的前沿。
论文评价
优点与创新
1.SenseVoice模型:
a.多语言语音识别:SenseVoice-Small支持五种语言的低延迟自动语音识别(ASR),而SenseVoice-Large支持超过50种语言的高精度ASR。
b.情感识别和音频事件检测:SenseVoice不仅支持语音识别,还提供先进的情感识别和音频事件检测功能。
c.非自回归架构:SenseVoice-Small采用非自回归端到端架构,推理延迟极低,比Whisper-small快5倍以上,比Whisper-large快15倍以上。
2.CosyVoice模型:
a.多语言语音生成:CosyVoice支持五种语言的语音生成,能够生成自然听起来的语音。
b.零样本上下文学习:CosyVoice能够在没有训练的情况下进行语音克隆,仅需3秒的提示语音。
c.跨语言语音克隆:CosyVoice可以跨语言复制语音,生成具有不同音色、情感和风格的语音。
d.指令微调:通过指令文本控制说话人身份、说话风格和其他细粒度的副语言特征。
3.开源模型:
a.SenseVoice和CosyVoice的相关模型已在Modelscope和Huggingface上开源,并发布了相应的训练、推理和微调代码。
4.丰富的应用场景:
a.FunAudioLLM通过与LLMs的集成,提供了语音翻译、情感语音聊天、互动播客和富有表现力的有声书叙述等多种应用演示。
不足与反思
1.SenseVoice的局限性:
a.对于资源较少的语言,ASR性能通常较低。
b.SenseVoice不是为流式转录设计的,未来工作可能会专注于开发基于SenseVoice的可流式语音理解模型。
2.CosyVoice的局限性:
a.支持的语言数量有限,虽然可以根据显式指令表达情感和说话风格,但不能根据文本的语义内容推断适当的情感或风格。
b.在唱歌方面表现不佳,需要在保持原始音色的同时实现富有表现力的情感变化。
c.两个创新模型与LLMs的训练不是端到端的,这种管道方法可能会引入错误传播,影响整体性能。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。