云栖实录 | 阿里云 OpenLake 解决方案重磅发布:多模态数据统一纳管、引擎平权联合计算、数据共享统一读写
新一轮人工智能浪潮正在重塑世界,以生成式 AI 为代表的技术快速应用,推动了数据与智能的深化融合,同时也给数据基础设施带来了全新的变革与挑战。面向 AI 时代的数据基础设施如何构建?底层数据平台架构在 AI 时代如何演进? 9月20日,2024云栖大会 OpenLake 解决方案专场带来了全方位的解读。
行业技术趋势迫切需要融合的数据平台
全球权威研究机构 Forrester 和阿里云在云栖大会 OpenLake 专场联合发布了《数据+AI 联合趋势洞察暨阿里云 OpenLake 解决方案》。Forrester VP、首席分析师戴鲲表示:加速转型企业数据管理与人工智能战略,切实推动企业业务成长迫在眉睫。AI 时代数据管理包含五个方面:
-
构建互联智能框架,提升数据基础设施的人工智能就绪度;
-
拥抱全局数据管理和 DataOps,简化数据运维;
-
聚焦端到端数据管理,加速用例落地;
-
优先考虑 AI 赋能的数据管理,实现智能与敏捷;
-
用例驱动的数据管理解决方案将进一步演进。
融合数据平台将在数据基础设施中发挥关键作用。数据湖仓将为企业带来显著战略价值:快速构建一体化数据分析平台,加速获取 AI 赋能的业务洞察,有效降低数据基础设施与管理成本。
OpenLake:构建大数据、搜索、AI 一体化能力体系
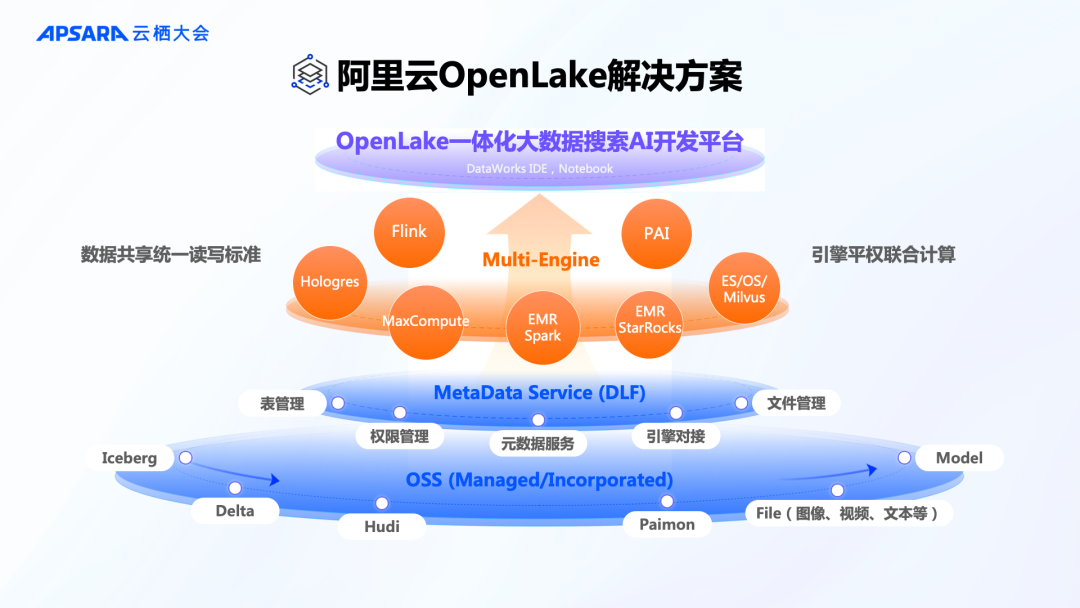
面对 AI 时代的现代企业数据管理,阿里云智能集团研究员、阿里云计算平台产品负责人徐晟正式对外发布了 OpenLake 解决方案,构建大数据、搜索、AI 一体化的能力体系,实现多模态数据统一纳管、多种计算引擎平权计算、大数据 AI 一体化开发,助力企业基于数据资产构筑竞争力。
-
OpenLake 建立在 OSS 开放的公共数据湖仓基础之上,使用元数据管理平台 DLF 统一管理结构化、半结构化和非结构化数据,提供湖仓数据的安全访问机制、文件增删查改能力和 I/O 加速能力。
-
在引擎层,包含 PAI、MaxCompute、Hologres、Flink、EMR StarRocks、EMR Spark、AI 搜索引擎在内的各类计算引擎,可以访问同一份数据并进行协同计算,消除数据壁垒和存储冗余。
-
在开发层,DataWorks 提供一体化的 IDE+Notebook 模式,实现多引擎 SQL 和 Python 统一开发,并提供多任务可视化调度保障。

当被问到为什么是阿里云有信心做 OpenLake 方案?
徐晟表示:
首先,OpenLake 包含的每个产品至少经过四至五年以上的迭代,而且有足够大的客户群体,每个产品都是经过不同行业需求的客户的打磨;
其次,阿里云有专业的团队,OpenLake 包含的所有产品都具有足够专业性和技术领先性,对于真正的用户来说,他需要专业的支持和服务,市场上只是把一些开源的引擎搭到一起做一个整合,这个是远远不够的;
最后,我们会做到的性价比最优,大幅降低客户的使用成本。
OpenLake 的应用场景非常广泛,包括:统一湖存储、基于 Flink 新一代流式湖仓、基于 Hologres/StarRocks 的新一代实时查询湖仓、基于 MaxCompute 和 Hologres 的经典流批查询湖仓、基于 AI 搜索的多模态 RAG 检索增强、以 DataWorks 为核心的大数据 AI 多引擎协同开发等。
阿里云 OpenLake 解决方案免费试用活动已于9月20日正式上线,企业用户可以一键开通体验,欢迎对 OpenLake 感兴趣的客户开通测试。