Chroma 向量数据入门

Chroma 是 AI 原生的开源矢量数据库。Chroma 使知识、事实和技能可插入 LLM,从而可以轻松构建 LLM 应用程序。Chroma 是 AI 原生的开源矢量数据库。Chroma 使知识、事实和技能可插入 LLM,从而可以轻松构建 LLM 应用程序。
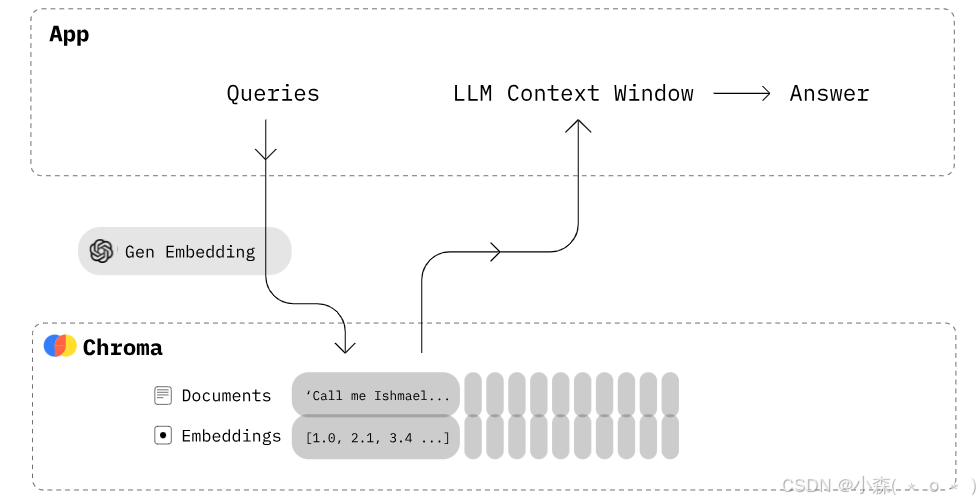
🌟Chroma是一个文档检索系统,它存储了一组文档以及它们相应的嵌入向量。当接收到嵌入向量后,Chroma会根据其内部的索引结构快速查找最相关的文档。
尝试
import chromadb
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(name="my_collection")
collection.add(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
results = collection.query(
query_texts=["This is a query document about hawaii"],
n_results=2
)
print(results)💥 输出:
{'ids': [['id1', 'id2']], 'distances': [[1.0404009819030762, 1.2430802583694458]], 'metadatas': [[None, None]], 'embeddings': None, 'documents': [['This is a document about pineapple', 'This is a document about oranges']], 'uris': None, 'data': None, 'included': ['metadatas', 'documents', 'distances']}import chromadb
# 创建 ChromaDB 客户端实例
chroma_client = chromadb.Client()
# 获取一个集合
collection = chroma_client.get_or_create_collection(name="my_collection")
# 插入或更新文档
collection.upsert(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)
# 查询:
results = collection.query(
query_texts=["This is a query document about florida"],
n_results=2
)
print(results)💥输出:

-
'ids': 返回的文档 ID 列表。
['id2', 'id1']表示查询结果中最相关的两个文档是id2和id1。 -
'distances': 每个查询文本与其对应结果之间的距离(相似度)。数值越小表示相似度越高。
[1.1462138891220093, 1.3015375137329102]表示id2的相似度高于id1 -
Chroma 将存储文本并自动处理嵌入和索引,我们也可以自定义嵌入模型。
-
默认情况下,Chroma 使用Sentence Transformers
all-MiniLM-L6-v2模型来创建嵌入。
也可以通过docker下载chroma:
docker pull chroma/chroma
# 拉取 ChromaDB 镜像
docker run -p 8000:8000 chroma/chroma
# 运行 ChromaDB 容器验证 ChromaDB 服务是否正在运行
curl http://localhost:8000启动持久 Chroma 客户端
import chromadb
client = chromadb.PersistentClient(path="/home/ma-user/work/chroma_ku")💯使用 PersistentClient 创建的客户端会将所有的数据(包括集合、文档、嵌入等)持久化到磁盘上。这意味着即使你关闭了应用程序并重新启动,之前添加的数据仍然会被保留。
# client是持久的客户端
collection = client.create_collection(name="my_collection")path是 Chroma 将其数据库文件存储在磁盘上并在启动时加载它们的地方- client.reset() 重置数据库
在客户端-服务器模式下运行Chroma
🧊Chroma 客户端连接到在单独进程中运行的 Chroma 服务器。
🧊上面我们创建了客户端,现在可以启动 Chroma 服务器:
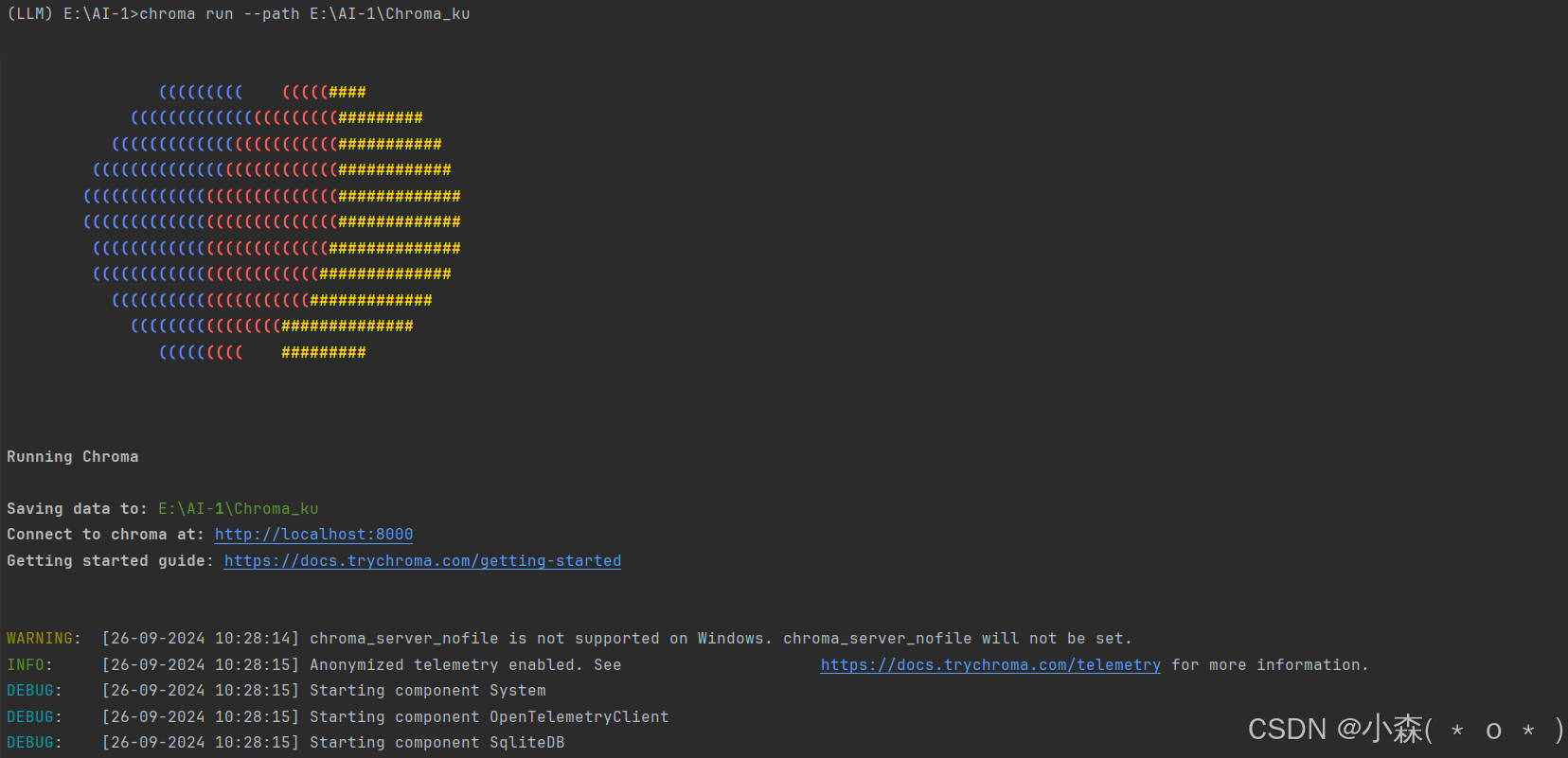
🧊我们在浏览器输入http://localhost:8000 :

- 会看到一个错误页面(404 Not Found),因为 ChromaDB 服务器默认不提供静态页面,而是提供 API 端点
🌟 然后使用 Chroma HTTP 客户端连接到服务器:
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)然后就可以操作了~~
操作集合
import chromadb
path = "E:\\AI-1\\Chroma_ku"
client = chromadb.PersistentClient(path=path)
# PersistentClient 会从指定的路径加载现有的数据库文件
from sentence_transformers import SentenceTransformer
# 加载预训练的句子嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 定义嵌入函数
def emb_fn(texts):
return model.encode(texts, convert_to_tensor=True).cpu().numpy()
collection = client.get_collection(name="my_collection", embedding_function=emb_fn)
collection.upsert(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
ids=["id1", "id2"]
)我们可以使用 按照名称检索现有集合.get_collection,并使用 删除集合.delete_collection。还可以使用.get_or_create_collection获取集合(如果存在)或创建集合(如果不存在)。
collection = client.get_collection(name="test")
collection = client.get_or_create_collection(name="test")
client.delete_collection(name="my_collection")集合有一些实用的便捷方法:
collection.peek() # 返回集合中前十的列表
collection.count() # 返回集合中的项目数
collection.modify(name="new_name") # 重命名距离函数
collection = client.create_collection(
name="collection_name",
metadata={"hnsw:space": "cosine"}
)实例创建一个使用余弦相似度的集合,并插入一些文档:(保证chroma已经运行起来)
import chromadb
from sentence_transformers import SentenceTransformer
# 创建 HttpClient 实例
client = chromadb.HttpClient(host="localhost", port=8000)
# 加载预训练的句子嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 定义嵌入函数
def emb_fn(texts):
return model.encode(texts, convert_to_tensor=True).cpu().numpy()
# 创建一个使用余弦相似度的集合
collection = client.create_collection(
name="my_collection",
metadata={"hnsw:space": "cosine"}
)
# 插入文档
collection.upsert(
documents=[
"This is a document about pineapple",
"This is a document about oranges"
],
metadatas=[{"source": "internet"}, {"source": "local"}],
ids=["id1", "id2"]
)
# 查询文档
results = collection.query(
query_texts=["This is a query document about fruit"],
n_results=2
)向集合添加数据:
collection.add(
documents=["lorem ipsum...", "doc2", "doc3", ...],
metadatas=[{"chapter": "3", "verse": "16"}, {"chapter": "3", "verse": "5"}, {"chapter": "29", "verse": "11"}, ...],
ids=["id1", "id2", "id3", ...]
)
# 每个元数据项是一个字典,其中键值对表示文档的附加信息🌟使用 query 方法来查找与给定查询向量最相似的文档,并且可以附加一些过滤条件:
collection.query(
query_embeddings=[[11.1, 12.1, 13.1], [1.1, 2.3, 3.2], ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains": "search_string"}
)- 查询将按顺序返回
n_results与每个 最接近的匹配项。可以提供可选的过滤词典,以便根据与每个文档关联的 进行过滤。此外,还可以提供可选的过滤词典,以便根据文档的内容进行过滤
从集合中删除数据
删除特定 ID 且元数据中 chapter 为 "20" 的文档
collection.delete(
ids=["id1", "id2", "id3",...],
where={"chapter": "20"}
)