【论文通读】Diagnosing and Remedying Knowledge Deficiencies in LLMs via LaMer
Diagnosing and Remedying Knowledge Deficiencies in LLMs via Label-free Curricular Meaningful Learning
- 前言
- Abstract
- Background
- Motivation
- LaMer
- Knowledge Retrieval
- Label-free Knowledge Deficiency Diagnosis
- Curricular Meaningful Learning
- Experiments
- Case Study
- Further Analysis
- Comparisons to Label-reliant Methods
- Effectiveness in Remedying Decificiencies
- Effect of Curricular Deficiency Remedy
- Causes for the Advantages of LaMer
- Sign
- Conclusion
前言
一篇很有意思的工作,通过相对熵判断LLM在知识上的缺陷,从而合成新数据来修复模型的知识缺口。方法简单,效果不错,简洁易懂,虽然在应用场景上有很大的限制,但是也是给LLM的知识诊断与修复带来了新的思考方向。| Paper | https://arxiv.org/pdf/2408.11431 |
|---|
Abstract
大模型从大量无标注数据中学习,展现广泛的用途。然而大模型仍会面临推理错误和知识缺失的问题,影响其可靠性。虽然多样的query可以改善该问题,但是获得充分有效反馈是困难的。此外,受限于有限的标签,难以全面评估LLM,因此通过丰富的无标签查询来诊断和修复LLM 的缺陷成为一项挑战。为此,本文提出一个无标签课程有意义学习框架LaMer,LaMer 首先首先采用相对熵来自动诊断量化无标签环境中LLM的知识缺陷。接下来,为了弥补诊断出的知识缺陷,我们应用课程有意义学习:首先,我们采用有意义学习根据缺陷的严重程度自适应地合成增强数据,然后设计课程缺陷补救策略来逐步弥补LLM的知识缺陷。实验表明,LaMer 高效诊断和弥补了LLM 的知识缺陷,改进了七个分布外 (OOD) 推理和语言理解基准的各种LLM,仅用 40% 的训练数据就取得了与基线相当的结果。 LaMer 甚至超越了依赖标记数据集进行缺陷诊断的方法。在应用中,作者的无标签方法可以为高效LLM应用提供有效的知识缺陷诊断工具。
Background
当前LLM有如下局限:
- 推理错误。
- 难以获得用户有效的反馈。
这对基于大量无标签数据训练的LLM造成巨大的阻碍。
Motivation
现有的解决方案主要采用两种方式:
- 无监督语言建模
- 监督微调
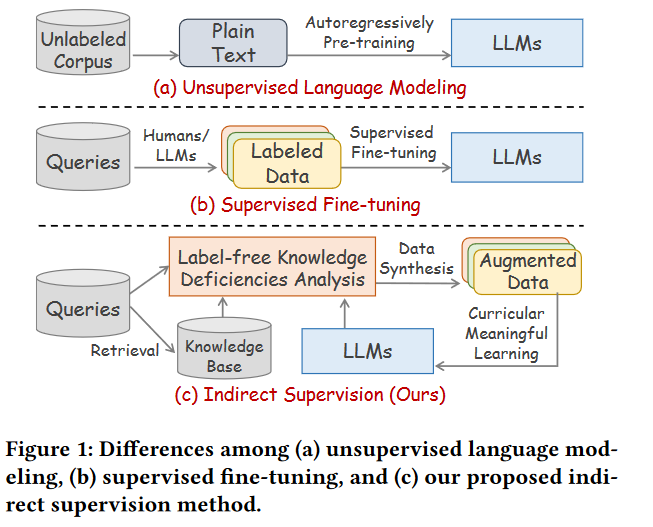
但是这两种方法都有局限性:
- 效率低下,难以解决LLM的推理错误。
- 对LLM缺乏全面了解,难以进行针对性的改进。
- 为用户查询标注虽然可以缓解推理错误,但是成本高且数据不够。
作者考虑到上述的局限性,又发现LLM推理错误往往是因为缺乏相关知识,因此希望在无需任何标注的情况下,诊断LLM中知识的缺失并对其进行修复。这种方式可以帮助LLM持续更新迭代。
LaMer
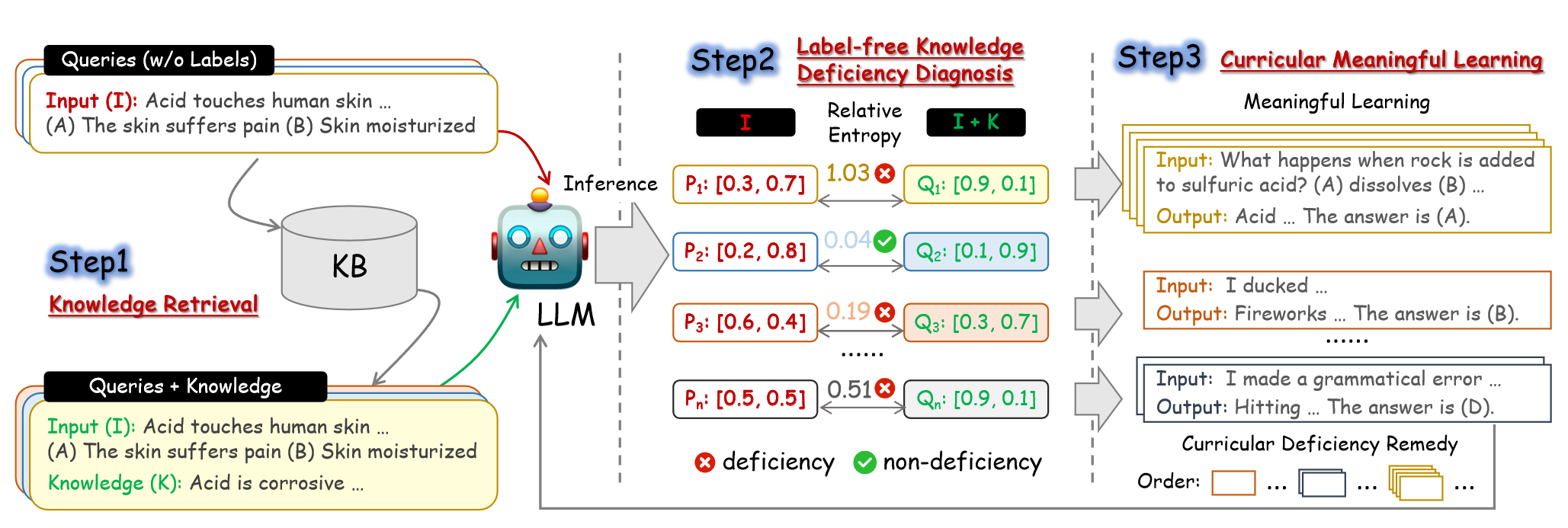
因此,正如上图c中所示,作者提出了无标签课程有意义学习方法LaMer:
- 检索用户查询的知识(Knowledge Retrieval)。
- 利用相对熵(可以估计从一个分布变为另一个分布所需的额外信息)和检索的知识诊断LLMs知识的缺陷(Label-free Knowledge Deficiency Diagnosis)。
- 利用课程有意义学习,根据缺陷程度自适应合成各种场景数据,利用采集的数据修复缺陷(Curricular Meaningful Learning)。
Knowledge Retrieval
部署GenericsKB作为外部知识库,包含3.4M+自然事实。使用FlagEmbedding对事实进行表征,并对每个查询同样做表征计算余弦相似度,从而检索m条知识。检索出来的知识和原始的查询用于在第二步诊断LLM知识的缺失。
Label-free Knowledge Deficiency Diagnosis
为了诊断LLM在无标签场景知识的缺失,作者使用相对熵(KL散度)来量化从一个分布到另一个分布所需要的附加信息。因此通过计算LLM在引入知识之前和引入知识之后分布的相对熵,就可以估计知识传给LLM的信息量。如果相对熵很高,说明LLM缺乏相关知识,或者无法将其有效整合去解决问题,从而可以诊断出知识的缺失。
具体来说:
- 对于一个包含问题和n个选项的查询d,作者首先将d喂入大模型中获取每个选项的负对数似然,此后获得LLM在选项上的先验分布:
p
i
=
L
(
y
i
∣
x
,
O
)
p_i =\mathcal{L}\left(y_i \mid x, O\right)
pi=L(yi∣x,O)
P
=
Softmax
(
[
p
1
,
⋯
,
p
n
]
)
P =\operatorname{Softmax}\left(\left[p_1, \cdots, p_n\right]\right)
P=Softmax([p1,⋯,pn])
- 对于每个检索到的知识k,同样喂入LLM中获取LLM在选项上的后验分布:
q
i
=
L
(
o
i
∣
k
,
x
,
O
)
q_i =\mathcal{L}\left(o_i \mid k, x, O\right)
qi=L(oi∣k,x,O)
Q
=
Softmax
(
[
q
1
,
⋯
,
p
n
]
)
Q =\operatorname{Softmax}\left(\left[q_1, \cdots, p_n\right]\right)
Q=Softmax([q1,⋯,pn])
接着根据计算二者的相对熵来评估LLM在k上的知识缺陷:
$ \mathrm{RE}=-\sum_{i=0}^m P_i \times\left(\log \left(Q_i\right)-\log \left(P_i\right)\right) $
对于超出阈值的知识会被视作一个单元,代表LLM中知识的缺陷。RE值即是知识缺乏的量化。
当然这也会遇到两种情况:
- 检索的知识是有用的,可以帮助正确选项置信度更高。
- 检索知识是有误导性的,导致错误选项置信度更高。
作者认为这两种情况都是知识缺陷的表现,前者说明LLM没有掌握到相关知识或者不能很好应用,后者表明虽然模型理解了知识但是容易被误导。
Curricular Meaningful Learning
作者结合有意义学习和课程学习,设计有意义的课程,以有效弥LLM的知识缺陷。
- 根据知识缺陷的严重程度,利用ChatGPT为不同场景生成不同的example。
- 根据相应知识缺陷的严重程度进行排序,以课程学习的方式依次输入到模型中训练。
Experiments
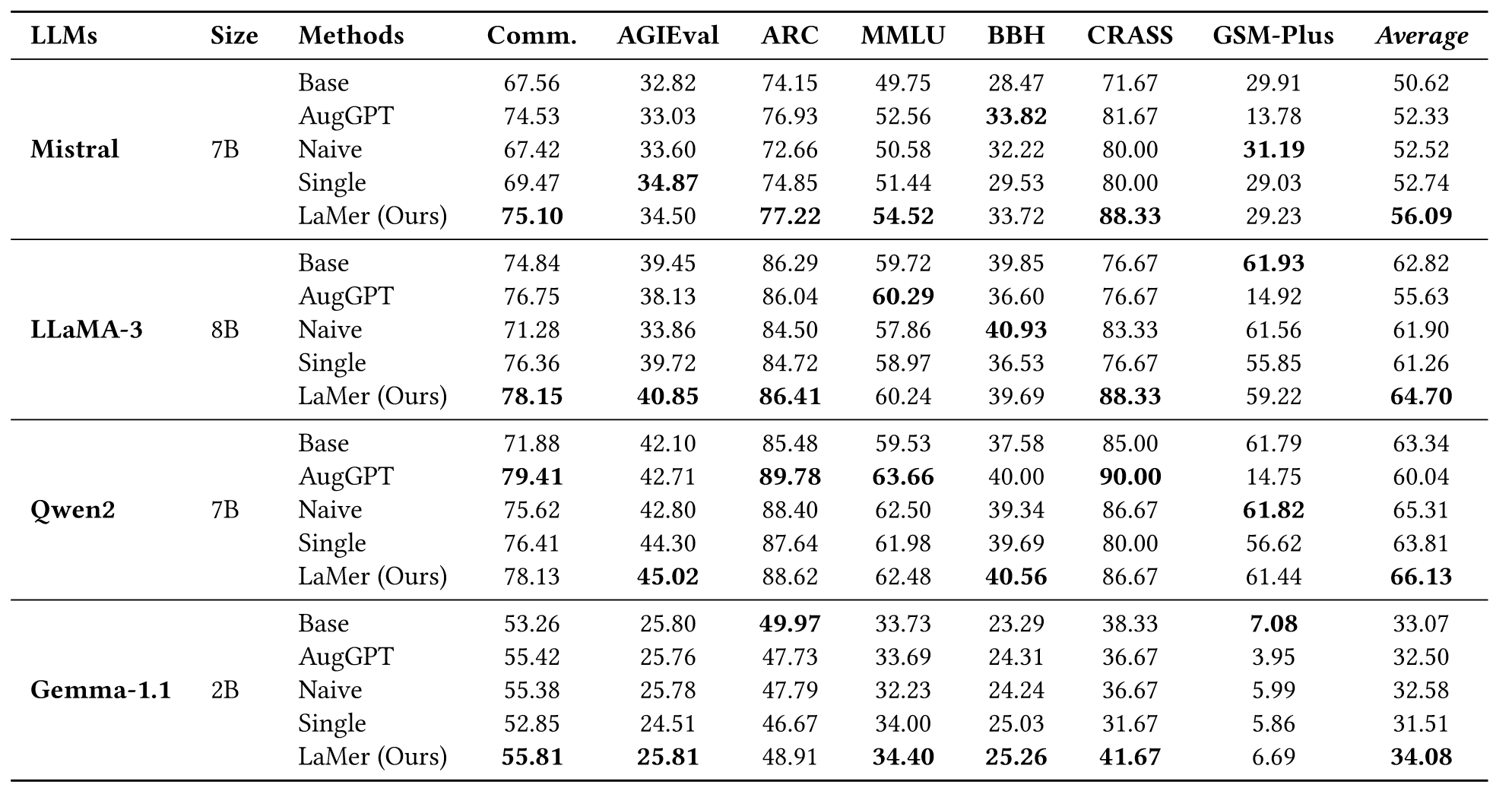
作者在4个不同的基座模型,5种不同的方法,以及7个OOD的数据集上进行了实验。作者在Mistral、Qwen2、Gemma-1.1上合成了3750个样本,在LLama3.1上合成了1250个样本进行训练。
Base:base模型直接推理。
AugGPT:从GenericsKB随机检索3750个事实生成与LaMer相同数量训练示例。
Naive:同理AugGPT。
Single:每个缺陷检索一个示例,一共1500条。
结果分析如下:
- LaMer平均下来超过所有baseline的结果。
- 所有增强后的模型都超过base模型,而Single和Naive在 LLaMA-3 and Gemma-1.1上表现略差,因为补充的知识可能会让其忘记更多的知识。
- Single利用40%的数据就可以实现与Naive差不多的性能,效率高,成本低。
- LaMer在所有LLM上都优于Single,这说明严重的知识缺陷需要更多example来弥补。
- AugGPT在GSM-Plus上表现最差,因为数据问题需要多步推理。而在单步推理的任务上表现好。
- Qwen2优于LLaMA-3,可能是因为后训练工作完备。
Case Study

上图例子可以说明通过知识诊断和缺陷修复,LLM可以生成正确的答案。
Further Analysis
Comparisons to Label-reliant Methods

作者基于Mistral和e-CARE进行分析,以揭示不同方法在诊断缺陷方面的效率。结果如上表所示,无标签的RE方法通过获取更多LLM知识缺陷信息而显著优于困惑度方法。此外还采用依赖标签的LLM2LLM方法进行比较。

结果表明,LAMer在不同的模型上都优于LLM2LLM,这是因为LLM2LLM特定于错误的数据,而LAMer学习的是缺陷的知识。
Effectiveness in Remedying Decificiencies
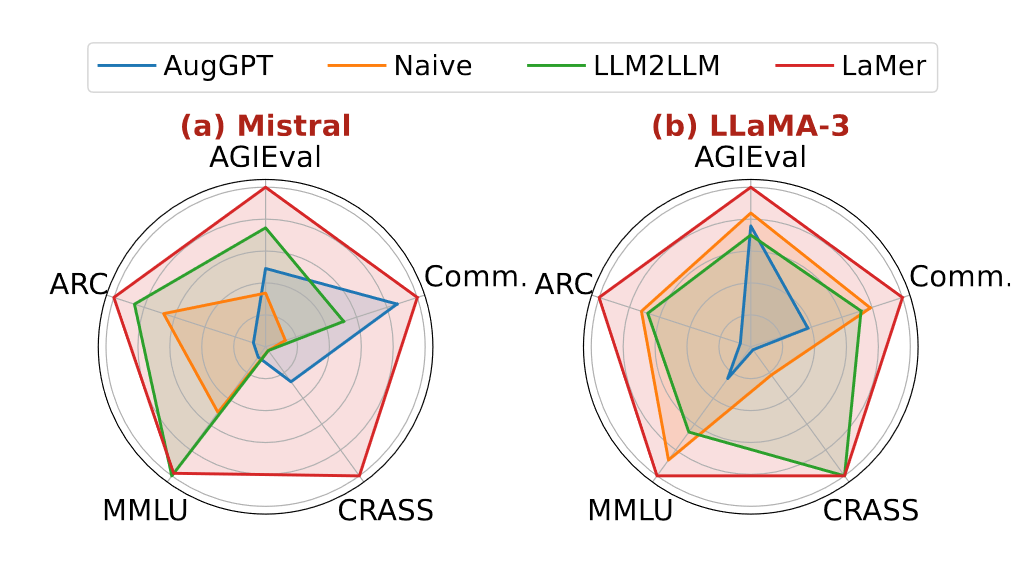
作者对每种方法增强后正确的示例进行了统计,来检验LaMer是否可以有效更正错误示例。结果如上面雷达图所示:
- LaMer通过相对熵可以诊断更多缺陷,并通过课程有意义学习来弥补。
- 表2中虽然AugGPT在某些基准上超过LaMer,但是上图并没有,说明它在弥补LLM知识缺陷上还有不足。
Effect of Curricular Deficiency Remedy
为了探索课程学习的优势,作者随机打乱LaMer的数据,方法称之为LaMer*,结果如下所示:
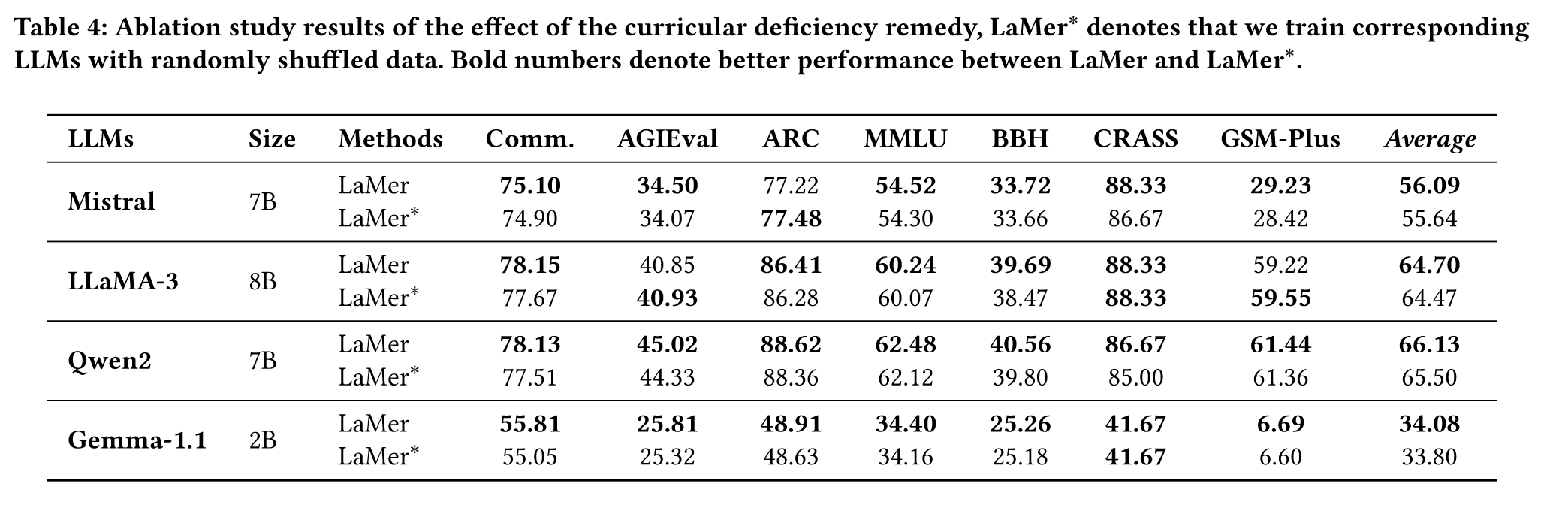
- LaMer在每个LLM上都要优于LaMer*。
- 但是LaMer*性能下降比较小。
- 部分基准上LaMer*要优于LaMer,说明LaMer的核心优势还在于基于相对熵的诊断。
Causes for the Advantages of LaMer
为了探索LaMer优势的潜在原因,作者将基线和LaMer合成的数据可视化到2D空间,使用DBSCAN发现簇并去噪。可视化结果如下:
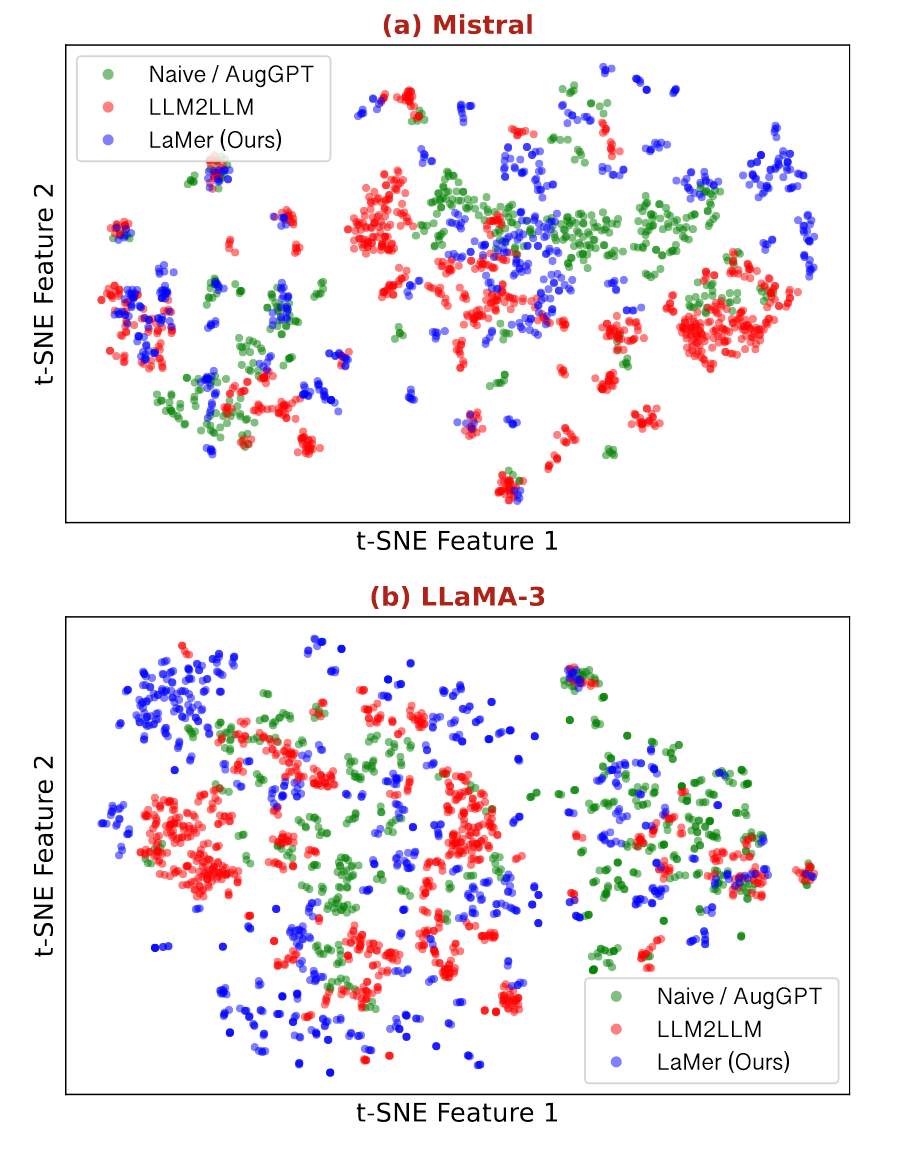
可以看到LaMer合成的数据的分布包围了其他方法的分布,说明因为 LaMer 可以利用相对熵来有效地发现更多缺陷。
Sign
之前提到知识缺陷可能由两种知识引起:
- 有用的知识让结果更好。
- 误导的知识让LLM选错。
作者为了探究这二者的重要性,分别使用基于有用和误导的合成数据来训练模型。结果如下图所示:

- 有用和误导性的知识造成的缺陷都是需要弥补的。
- 误导性知识重要性更大,这是因为误导性知识往往更复杂。
- 知识缺陷越大,二者的重要性越明显。
Conclusion
文章还是很有意思的,以相对熵的来量化LLM在知识上的缺陷,方法简单便捷且新颖。课程有意义学习更像是一个噱头,在这个场景下意义不大,比如模型在有的方面知识缺陷大,但不代表就是难的任务,只是模型之前没有学过罢了。此外我认为这个工作有一个严重的局限性在于场景上,该方法只能依赖于具有选项的问答任务,更多适合benchmark的刷榜,而不适合真实的应用场景。