力扣题解2306
大家好,欢迎来到无限大的频道。
今日继续给大家带来力扣题解。
题目描述(困难):
公司命名
给你一个字符串数组 ideas 表示在公司命名过程中使用的名字列表。公司命名流程如下:
-
从 ideas 中选择 2 个 不同 名字,称为 ideaA 和 ideaB 。
-
交换 ideaA 和 ideaB 的首字母。
-
如果得到的两个新名字 都 不在 ideas 中,那么 ideaA ideaB(串联 ideaA 和 ideaB ,中间用一个空格分隔)是一个有效的公司名字。
-
否则,不是一个有效的名字。
返回 不同 且有效的公司名字的数目。
解题思路:
分析
-
目标:从给定的字符串数组 ideas 中选择两个不同的名字 ideaA 和 ideaB,交换它们的首字母,如果生成的新名字都不在 ideas 中,则计数为有效的公司名字。
-
有效性条件:对于两个名字 ideaA 和 ideaB,如果交换首字母后得到的新名字 newIdeaA 和 newIdeaB 都不在 ideas 中,则它们是有效的。
-
思路:
-
我们可以将 ideas 按首字母进行分组。
-
对于每个组中的名字,我们尝试用其他组的首字母来生成新名字。
-
使用哈希表来快速检查生成的新名字是否已经存在于 ideas 中。
-
思路
-
分组:将所有名字按首字母分组。例如,ideas 中的名字可以分成以 'c' 开头的,'d' 开头的等。
-
生成新名字:对于每个组中的名字,尝试用其他组的首字母交换生成新名字。
-
检查有效性:使用哈希表存储 ideas,以便快速检查生成的新名字是否存在。
-
计数:如果生成的新名字都不在 ideas 中,则计数为有效。
参考代码如下:
#define ALPHABET_SIZE 26
typedef struct Node {
char *word;
struct Node *next;
} Node;
typedef struct {
Node *buckets[ALPHABET_SIZE];
} HashSet;
unsigned int hash(const char *str) {
return str[0] - 'a';
}
HashSet* createHashSet() {
HashSet *set = (HashSet *)malloc(sizeof(HashSet));
for (int i = 0; i < ALPHABET_SIZE; i++) {
set->buckets[i] = NULL;
}
return set;
}
void addWord(HashSet *set, const char *word) {
unsigned int index = hash(word);
Node *newNode = (Node *)malloc(sizeof(Node));
newNode->word = strdup(word);
newNode->next = set->buckets[index];
set->buckets[index] = newNode;
}
bool containsWord(HashSet *set, const char *word) {
unsigned int index = hash(word);
Node *current = set->buckets[index];
while (current != NULL) {
if (strcmp(current->word, word) == 0) {
return true;
}
current = current->next;
}
return false;
}
void freeHashSet(HashSet *set) {
for (int i = 0; i < ALPHABET_SIZE; i++) {
Node *current = set->buckets[i];
while (current != NULL) {
Node *temp = current;
current = current->next;
free(temp->word);
free(temp);
}
}
free(set);
}
long long distinctNames(char **ideas, int ideasSize) {
HashSet *set = createHashSet();
for (int i = 0; i < ideasSize; i++) {
addWord(set, ideas[i]);
}
long long groups[ALPHABET_SIZE][ALPHABET_SIZE] = {0};
for (int i = 0; i < ideasSize; i++) {
char firstChar = ideas[i][0];
for (char c = 'a'; c <= 'z'; c++) {
if (c != firstChar) {
ideas[i][0] = c;
if (!containsWord(set, ideas[i])) {
groups[firstChar - 'a'][c - 'a']++;
}
}
}
ideas[i][0] = firstChar;
}
long long count = 0;
for (int i = 0; i < ALPHABET_SIZE; i++) {
for (int j = 0; j < ALPHABET_SIZE; j++) {
count += groups[i][j] * groups[j][i];
}
}
freeHashSet(set);
return count;
}代码结构和功能概述
这个代码的目的是计算可以通过交换候选名字的首字母生成的有效公司名字的数量。它使用了哈希表来高效地存储候选名字,并通过双重循环来计算有效的名字组合。
主要结构
-
哈希表结构:
-
Node:链表的节点,存储一个单词和指向下一个节点的指针。
-
HashSet:哈希表,包含一个数组 buckets,每个元素是一个链表,用于处理哈希冲突。
-
函数分析
1. unsigned int hash(const char *str)
-
功能:计算给定字符串的哈希值。这里的哈希值是通过字符的 ASCII 值减去字符 'a' 来得到的,确保值在 0 到 25 之间(对应于字母表的 26 个字母)。
-
返回值:返回字符串首字母的哈希值,用于确定在哈希表中的桶索引。
2. HashSet* createHashSet()
-
功能:创建一个新的哈希表实例,并初始化所有桶为 NULL。
-
返回值:返回一个指向新创建的 HashSet 的指针。
3. void addWord(HashSet *set, const char *word)
-
功能:向哈希表中添加一个单词。首先计算该单词的哈希索引,然后将新节点插入到对应的桶中。
-
参数:
-
set:指向哈希表的指针。
-
word:要添加的单词。
-
-
实现细节:
-
创建一个新的 Node,存储单词并将其插入到对应的桶的头部(链表的前端)。
-
4. bool containsWord(HashSet *set, const char *word)
-
功能:检查哈希表中是否包含指定的单词。
-
参数:
-
set:指向哈希表的指针。
-
word:要查找的单词。
-
-
返回值:如果找到单词,返回 true,否则返回 false。
-
实现细节:
-
根据单词计算哈希索引,然后遍历该桶的链表,查看是否有匹配的单词。
-
5. void freeHashSet(HashSet *set)
-
功能:释放哈希表的内存,清理所有存储的单词和节点。
-
参数:
-
set:指向哈希表的指针。
-
-
实现细节:
-
遍历每个桶,释放桶中的每个节点和它们存储的单词,最后释放哈希表本身。
-
6. long long distinctNames(char **ideas, int ideasSize)
-
功能:计算可以通过交换首字母生成的有效公司名字的数量。
-
参数:
-
ideas:指向候选名字数组的指针。
-
ideasSize:候选名字的数量。
-
-
返回值:返回有效公司名字的数量。
-
实现细节:
-
创建哈希表 set 并将所有候选名字添加到哈希表中。
-
使用一个二维数组 groups 来记录每对不同首字母的有效名字组合的数量。
-
对于每个候选名字,尝试将其首字母替换为其他字母,并检查替换后的名字是否存在于哈希表中。如果不存在,则增加对应的计数。
-
最后,计算有效名字的总数,返回结果。
-
总体逻辑
-
哈希表创建:首先创建一个哈希表,用于存储所有候选名字。
-
名字处理:遍历所有候选名字,尝试用其他字母替换首字母,并检查替换后的名字是否已经存在于哈希表中。
-
结果计算:通过计算有效组合的数量,最终得到可以生成的有效公司名字的总数。
时间复杂度和空间复杂度分析
-
时间复杂度:O(n * m),其中 n 是 ideas 中的名字数量,m 是每个名字的平均长度。我们需要遍历每个名字,并对每个名字尝试 25 次不同的首字母替换检查。
-
空间复杂度:O(n * m),用于存储所有名字和哈希表。哈希表的存储需求与 ideas 的大小成正比。
理论上来说这个代码的实现没有问题,包括测试单个用例的时候也完全符合,但是对于力扣的测试用例却超出了时间限制,所以,我们必须想办法优化这个代码。
为了更高效地解决这个问题,我们可以按照交换 candidate idea 名字首字母后的方案计算有效的公司名字。
解题思路
-
分组:首先,我们按照首字母将所有的候选名字分组。
-
哈希映射:对于每一个首字母,我们维护一个哈希映射 names,其中键是首字母,而值是去除首字母后的每个候选名字的所有可能的剩余部分(即 suffix)。
-
双重循环:我们对于每一个不同的首字母组合 (preA, preB) 进行评估,检查哪些名字可以交换得到有效的组合。对于任意两个不同的首字母,我们检查其对应的姓名后缀集合,识别哪些后缀是唯一的(只在一个首字母组中存在)。
-
计算差异集合:使用集合的交集和差集来计算集合 names[preA] 和 names[preB] 的差异,并由此计算可生成的有效公司名字对的数量。
-
计算结果:每次通过集合操作,我们根据公式计算有效名字组合的数量,公式为:
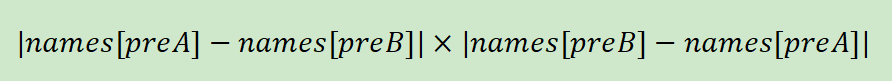
参考代码如下:
#define MAX_STR_SIZE 16
typedef struct {
char key[MAX_STR_SIZE];
UT_hash_handle hh;
} HashItem;
HashItem *hashFindItem(HashItem **obj, const char* key) {
HashItem *pEntry = NULL;
HASH_FIND_STR(*obj, key, pEntry);
return pEntry;
}
bool hashAddItem(HashItem **obj, const char* key) {
if (hashFindItem(obj, key)) {
return false;
}
HashItem *pEntry = (HashItem *)malloc(sizeof(HashItem));
sprintf(pEntry->key, "%s", key);
HASH_ADD_STR(*obj, key, pEntry);
return true;
}
void hashFree(HashItem **obj) {
HashItem *curr = NULL, *tmp = NULL;
HASH_ITER(hh, *obj, curr, tmp) {
HASH_DEL(*obj, curr);
free(curr);
}
}
size_t get_intersect_size(const HashItem *a, const HashItem *b) {
size_t ans = 0;
for (HashItem *pEntry = a; pEntry; pEntry = pEntry->hh.next) {
if (hashFindItem(&b, pEntry->key)) {
++ans;
}
}
return ans;
}
long long distinctNames(char** ideas, int ideasSize) {
HashItem *names[26] = {NULL};
for (int i = 0; i < ideasSize; i++) {
hashAddItem(&names[ideas[i][0] - 'a'], ideas[i] + 1);
}
long long ans = 0;
for (int i = 0; i < 26; i++) {
if (names[i] == NULL) {
continue;
}
int lenA = HASH_COUNT(names[i]);
for (int j = i + 1; j < 26; j++) {
if (names[j] == NULL) {
continue;
}
int lenB = HASH_COUNT(names[j]);
int intersect = get_intersect_size(names[i], names[j]);
ans += 2 * (lenA - intersect) * (lenB - intersect);
}
}
for (int i = 0; i < 26; i++) {
hashFree(&names[i]);
}
return ans;
}
关于两种思路的分析
两种思路大差不差,只是第一种使用了手动链表哈希表,第二种使用了uthash库来实现,分析一下优缺点:
手动链表哈希表
优点
-
自包含:
-
不依赖外部库,所有代码都是自包含的,便于在任何环境下编译和运行。
-
-
灵活性:
-
手动实现的哈希表提供了更大的灵活性,可以根据具体需求进行调整和优化。
-
缺点
-
效率较低:
-
查找和插入操作的时间复杂度为 O(n),因为需要遍历链表来查找元素,效率不如使用 uthash 的实现。
-
-
代码复杂性:
-
手动管理链表和哈希冲突增加了代码复杂性,容易引入错误。
-
-
内存使用:
-
需要为每个节点分配额外的内存来存储指针,这可能会导致更高的内存使用。
-
使用 uthash
优点
-
高效的哈希操作:
-
使用 uthash 库提供的哈希表实现,哈希查找和插入操作的时间复杂度平均为 O(1),这使得查找和插入操作非常高效。
-
-
简洁的代码:
-
uthash 提供了一组简单的宏来处理哈希表操作,如 HASH_ADD_STR 和 HASH_FIND_STR,使得代码简洁且易于维护。
-
-
内存管理:
-
uthash 自动管理哈希表的大小调整,不需要手动处理哈希冲突或链表管理。
-
-
空间效率:
-
哈希表仅存储必要的键值对,不需要像链表一样存储指针,节省了一定的内存。
-
缺点
-
外部依赖:
-
需要依赖 uthash 库,如果在某些环境中没有安装该库,可能会导致编译问题。
-
-
复杂性:
-
对于不熟悉 uthash 的开发者,可能需要额外学习如何使用这个库。
-
总结
-
第一段代码 更适合在对外部库依赖敏感的环境中使用,或者在需要完全控制哈希表实现细节的情况下。
-
第二段代码 更适合在需要高效查找和插入操作的场景下使用,尤其是在处理大量数据时。uthash 提供的高效哈希表实现能够显著提高性能。