DataLight(V1.4.5) 版本更新,新增 Ranger、Solr
DataLight(V1.4.5) 版本更新,新增 Ranger、Solr
DataLight 迎来了重大的版本更新,现已发布 V1.4.5 版本。本次更新对平台进行了较多的功能拓展和优化,新增了对 Ranger 和 Solr 服务组件的支持,同时对多项已有功能进行了改进,旨在提升更好的使用体验。
一. 更新日志
-
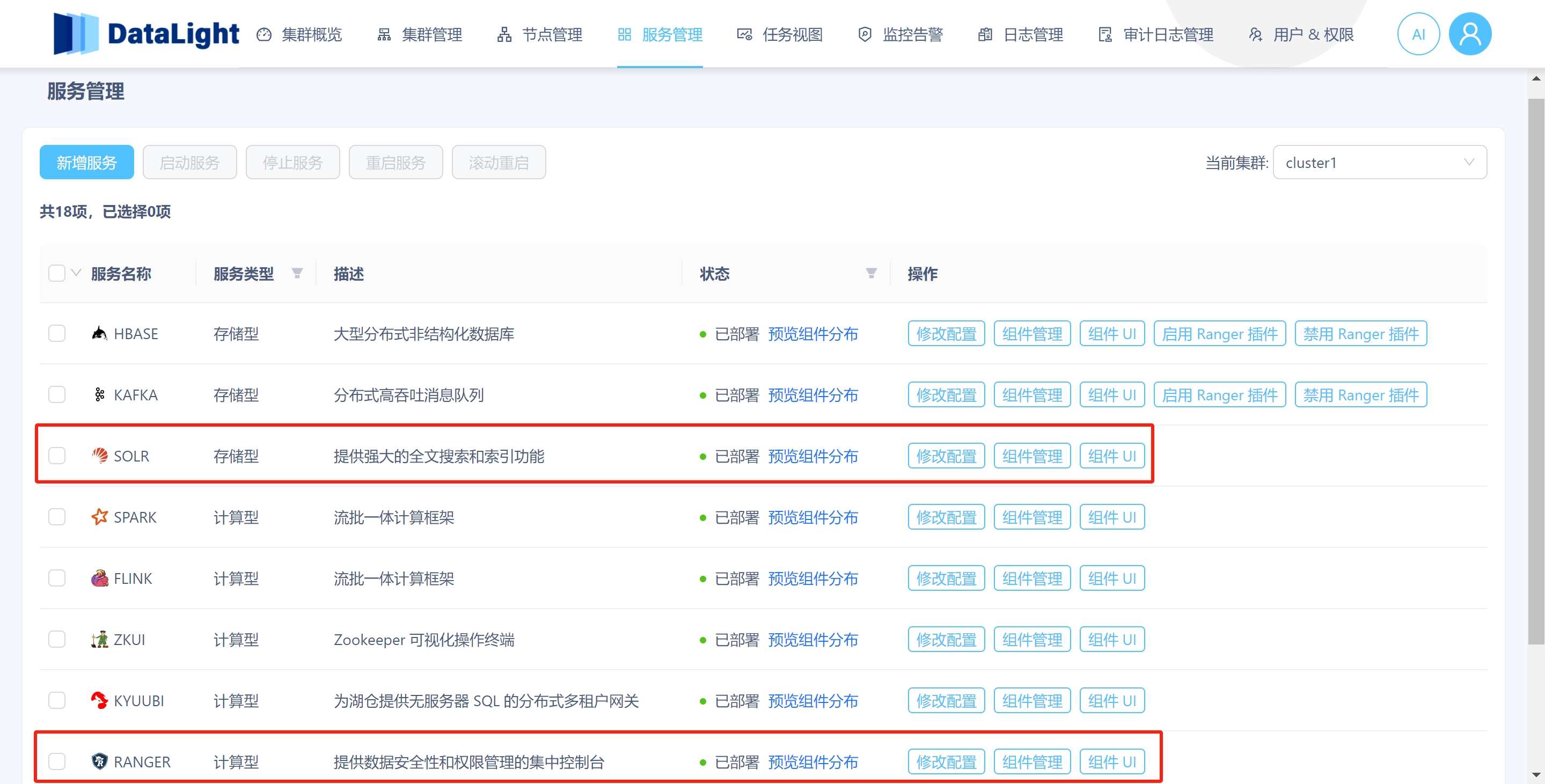
新增 SOLR 服务:
- 支持 Solr 服务的部署与维护,为用户提供强大的全文搜索和索引功能,方便对大数据集进行高效检索。
-
新增 RANGER 服务:
- 支持 RangerAdmin、RangerUserSync、RangerTagSync 的部署与管理,实现集中的权限控制和安全审计。
新增 RANGER 插件:
- RANGER-HDFS 插件:
- 支持文件和目录级别的权限控制。
- 提供详细的访问审计日志,满足合规性要求。
- RANGER-YARN 插件:
- 管理作业提交和队列级别的访问权限。
- 防止资源滥用,确保资源的公平分配和安全性。
- RANGER-HBASE 插件:
- 实现表、列族、列级别的权限管理。
- 保障数据的读写安全,防止未经授权的操作。
- RANGER-KAFKA 插件:
- 设置主题和消费组的访问权限。
- 保护消息的生产和消费环节,确保数据传输安全。
- RANGER-HIVE 插件:
- 提供行、列、单元格级别的访问控制。
- 具备数据脱敏功能,保护敏感信息。
- RANGER-SOLR 插件:
- 控制查询和索引的访问权限。
- 防止未经授权的搜索和数据泄露。
-
优化日志管理的滚动效果:
新增用户身份判定机制,解决了除
root用户外其他普通用户无法登录的问题,提升了系统的安全性和用户友好性。 -
优化配置文件联动机制:
当 Ranger 服务部署或发生变动时,系统将自动联动修改相关服务的配置文件,减少手动操作的繁琐,降低错误发生的可能性。
-
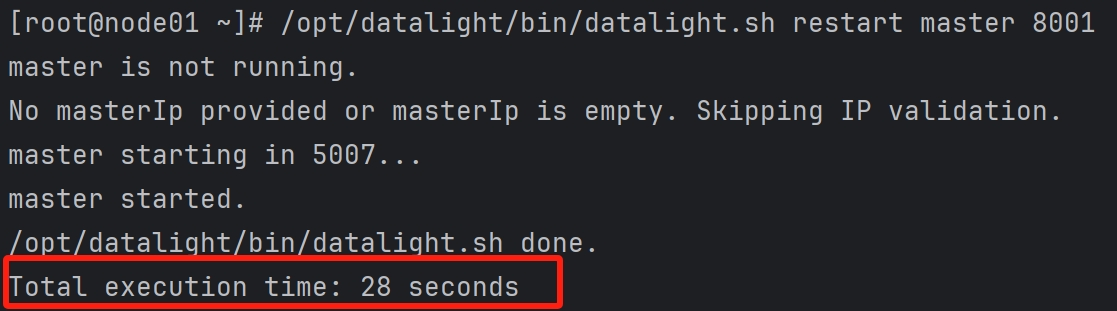
新增脚本耗时显示:
在执行
datalight.sh操作 Master 和 Worker 进程时,增加了耗时打印功能,方便用户了解操作执行时间,优化性能调试流程。
二. 部分更新内容预览
2.1 新增 Ranger、Solr 服务
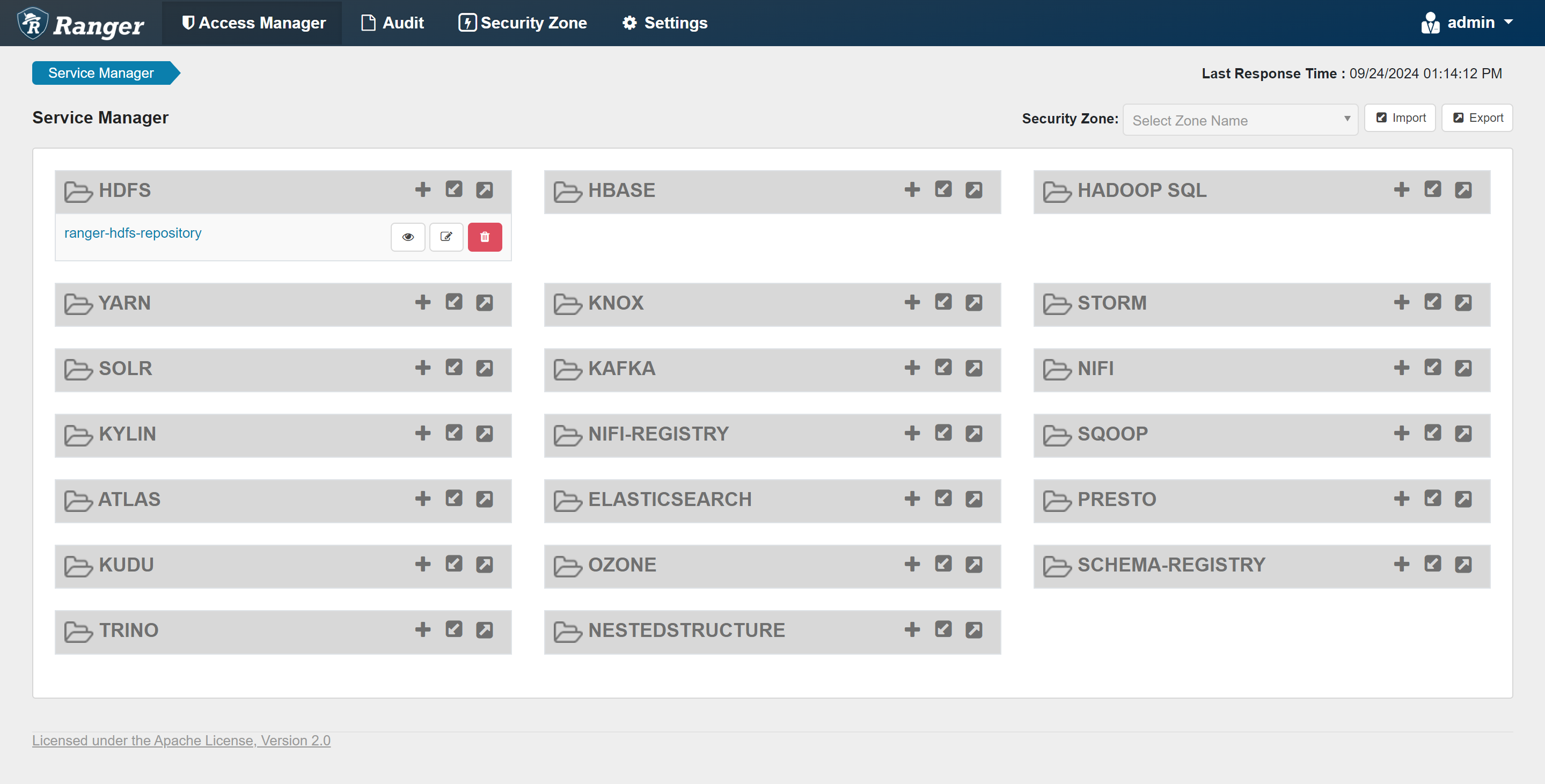
2.2 RangerAdmin
提供友好的 Web 界面,可以方便地创建、修改和查看权限策略。
2.3 RangerUserSync
支持从 LDAP、Active Directory 或本地 Unix 系统同步用户和组信息,确保权限管理的准确性和同步性。

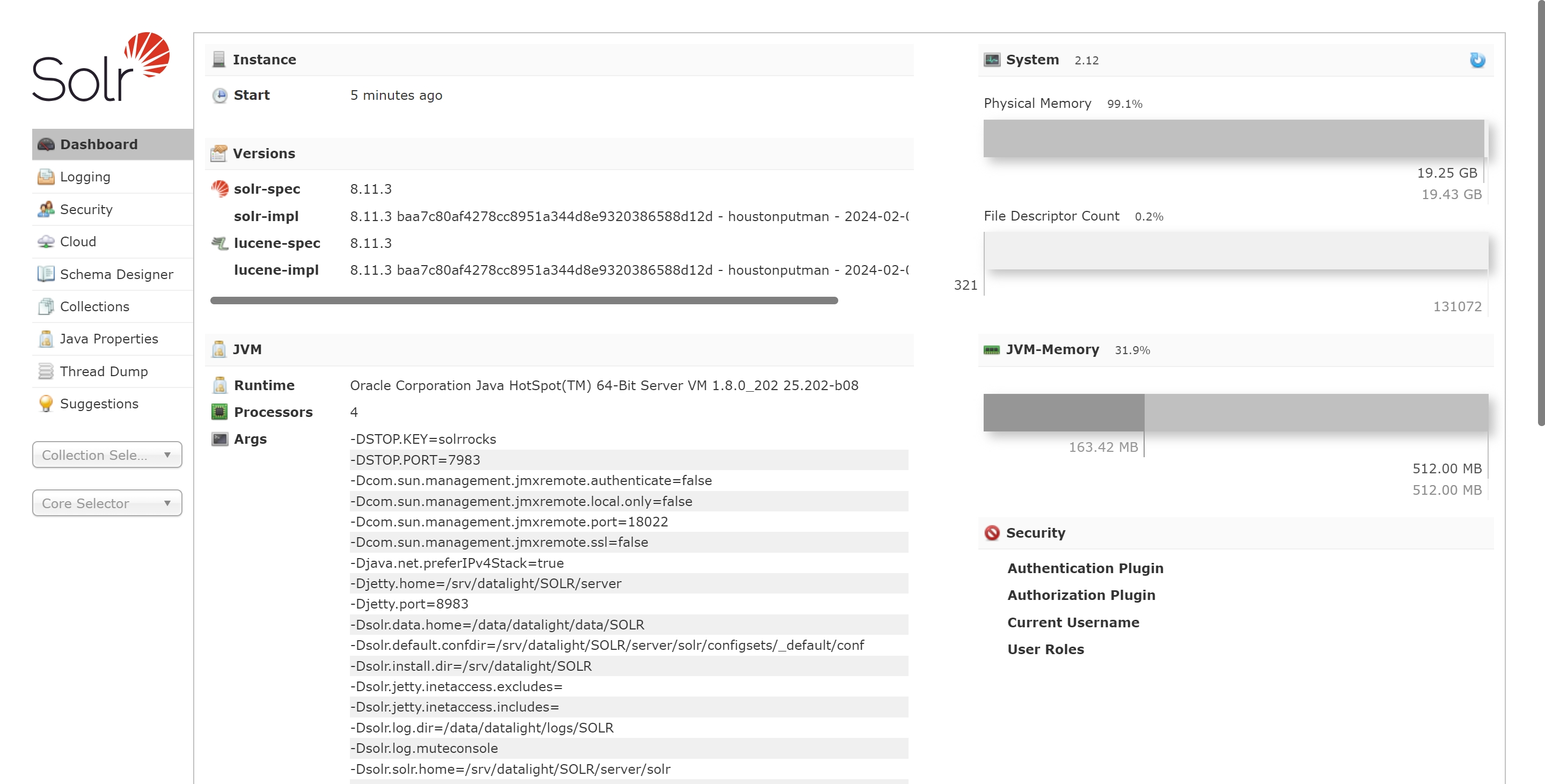
2.4 SolrServer
支持 Solr 集群部署,提供容错和负载均衡能力,且支持全文检索、模糊查询、范围查询等多种查询方式,满足多样化的业务需求。
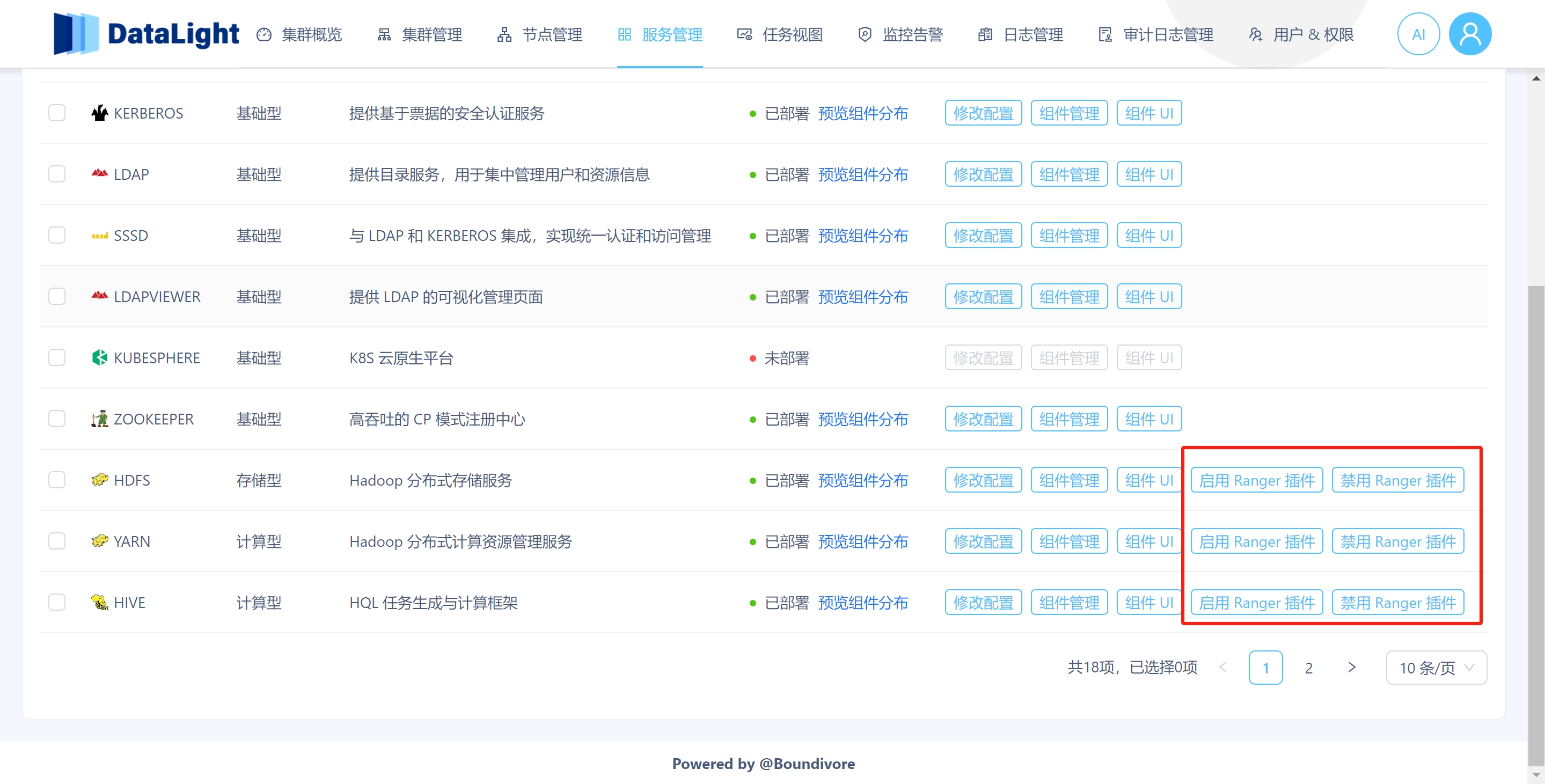
2.5 一键启用、禁用 Ranger 插件
在 DataLight 平台上,可以一键启用或禁用各服务的 Ranger 插件,灵活控制权限管理功能。
2.6 Ranger 插件审计
详细记录各服务的访问和操作日志,帮助管理员监控用户行为,防范安全风险。

2.7 Ranger 插件状态
在平台上查看各 Ranger 插件的运行状态,及时发现和处理异常情况,保障系统稳定运行。

2.8 优化脚本耗时显示
增加了 datalight.sh 脚本操作过程的耗时打印,帮助用户分析和优化系统性能,提升运维效率。
三. 如何增量更新到 1.4.5 版本
我们提供了详细的升级指南,帮助您顺利将现有的 DataLight 平台更新到最新版本。
3.1 停止 Master/Worker进程
进入主节点,在所有服役的节点上,执行以下命令,停止并删除所有节点上的 Master、Worker 进程:
# 停止 Master 进程
/opt/datalight/bin/datalight.sh stop master
# 停止 Worker 进程
/opt/datalight/bin/datalight.sh stop worker
# 删除原有的 Master、Worker Jar 包
rm -rf /opt/datalight/app/*.jar
注:Master 进程所在节点称之为主节点,下同
3.2 更新主包
前往百度网盘,下载如下内容,获取最新的主程序包。
下载完成后,将新包覆盖至 /opt/datalight 目录下,替换原有文件。
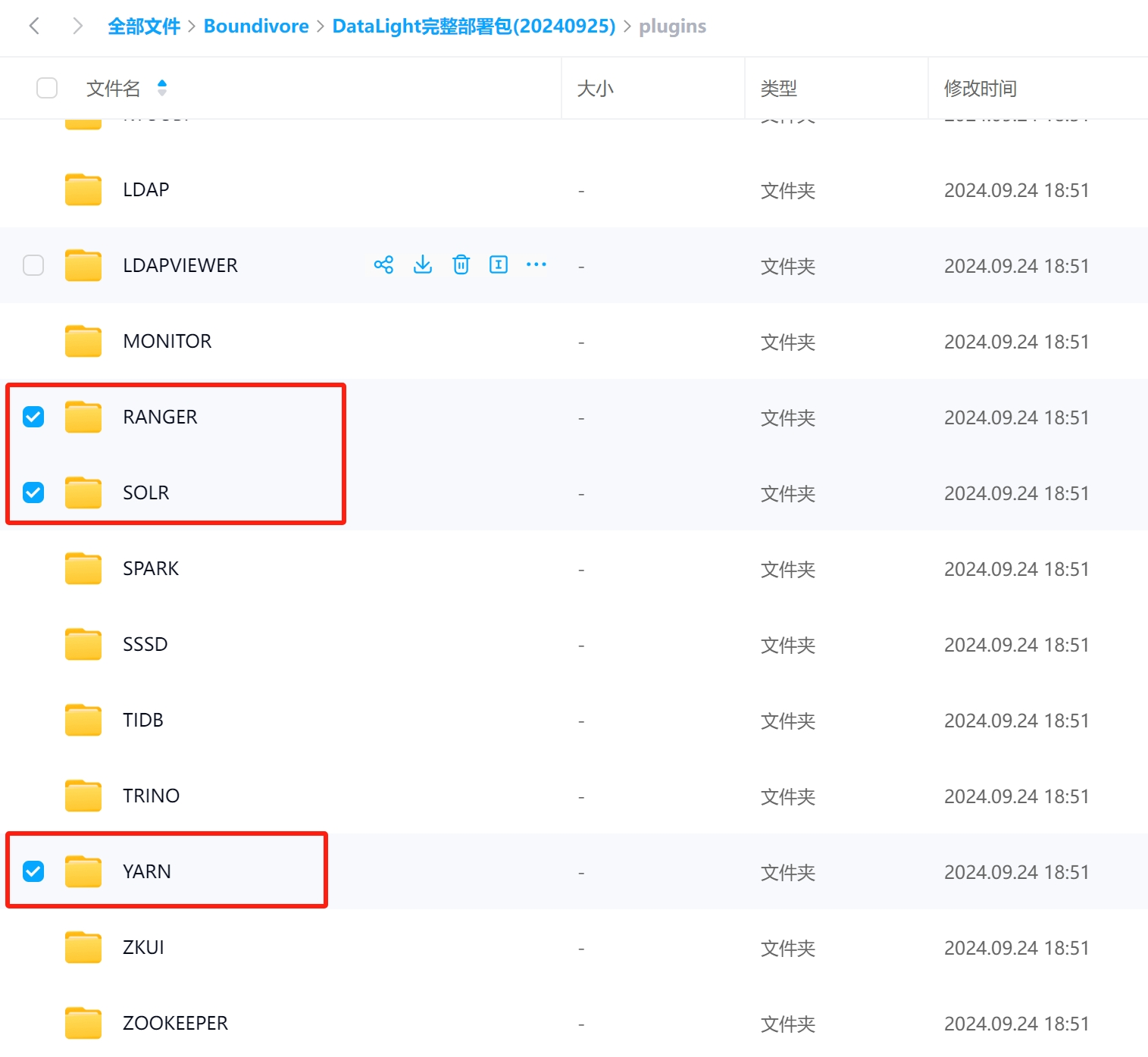
3.3 更新插件包
前往百度网盘,下载如下插件包内容,将其覆盖更新至 /opt/datalight/plugins 目录下的相应位置,确保插件版本与主程序一致。

3.4 手动分发到所有节点
将更新后的 DataLight 目录从 主节点 推送至所有 从节点。可以使用 scp 或其他同步命令进行分发。例如,将更新内容推送至节点 node02:
# 以推送至 node02 节点为例
scp -r /opt/datalight node02:/opt
3.6 重新启动 Master 进程
进入主节点,通过以下命令启动 Master 进程,Master 进程重启后,稍等片刻,Master 将自动拉起所有节点上的 Worker 进程。
/opt/datalight/bin/datalight.sh start master 8001
四. Ranger 的功能与场景
DataLight 平台现已支持与 Ranger 深度集成,实现对各大数据组件的统一权限管理和安全审计。
-
4.1 Ranger 与 HDFS
使用场景:数据分层存储
在一个企业数据湖中,不同部门需要访问不同的数据集。Ranger 可以为每个部门设置特定的文件夹权限:
- 场景: 财务部门需要访问财务报告,但不应该访问研发数据。
- 解决方案: 使用 Ranger 创建规则,只允许财务部门的用户组访问
/data/finance目录,而/data/research只能由研发部门访问。 - 好处: 确保数据隔离,防止敏感信息泄露。
4.2 Ranger 与 YARN
使用场景:资源公平调度
在共享计算资源的环境中,确保不同用户的公平使用:
- 场景: 数据科学团队和营销团队共享一个 YARN 集群。
- 解决方案: 通过 Ranger 限制每个团队提交的作业数量和资源使用量。
- 好处: 防止某一团队过度占用资源,提升整体资源利用率。
4.3 Ranger 与 HBase
使用场景:客户数据保护
公司需要存储和处理敏感的客户信息,确保数据安全:
- 场景: 客户服务团队需要访问客户联系信息,但不应查看财务数据。
- 解决方案: 使用 Ranger 在 HBase 中设置列级权限,允许访问
contact_info列族,而限制financial_data。 - 好处: 保护敏感数据,符合隐私法规要求。
4.4 Ranger 与 Hive
使用场景:敏感数据分析
在执行大规模数据分析时,保护敏感数据:
- 场景: 分析师需要访问销售数据进行趋势分析,但不应查看具体客户信息。
- 解决方案: 在 Hive 中设置列级权限,允许访问销售数据列,但限制客户信息列。
- 好处: 保证分析的同时,保护个人隐私。
4.5 Ranger 与 Kafka
使用场景:日志数据流管理
管理跨部门的日志数据流:
- 场景: 安全团队和开发团队需要访问不同的日志数据。
- 解决方案: 使用 Ranger 设置 Kafka 主题权限,安全团队可以访问
security_logs主题,而开发团队访问app_logs。 - 好处: 确保数据流的安全性和隐私性。
4.6 Ranger 与 Solr
使用场景:搜索查询控制
在企业搜索平台中,管理不同用户的查询权限:
- 场景: 员工可以搜索公共文档,但只有人力资源可以搜索员工记录。
- 解决方案: 使用 Ranger 控制 Solr 查询权限,限制员工只能搜索公共索引。
- 好处: 防止敏感信息泄露,确保合规性。
关注我们,获取更多最新资讯。
一起见证数据世界的无限可能!