阿里云函数计算 x NVIDIA 加速企业 AI 应用落地
作者:付宇轩
前言
阿里云函数计算(Function Compute, FC)是一种无服务器(Serverless)计算服务,允许用户在无需管理底层基础设施的情况下,直接运行代码。与传统的计算架构相比,函数计算具有高灵活性和弹性扩展的特点,用户只需专注于业务逻辑的开发,系统自动处理计算资源的分配、扩展和维护。同时,函数计算作为阿里云云产品的粘合剂,可以让用户轻松的和多种阿里云服务集成,构建复杂的应用程序。加之函数计算除了提供 CPU 算力以外,还提供 GPU 算力,所以这种无缝的计算体验,使得函数计算非常适合需要弹性扩展的 AI 任务,如模型推理和图像生成,能够大幅提高效率并降低计算成本。
NVIDIA TensorRT 是英伟达为深度学习推理优化的高性能库,广泛应用于计算机视觉、语音识别等领域。TensorRT 通过一系列优化手段,如权重量化、层融合和内存优化,极大提升了模型的推理速度,同时减少了资源消耗。它支持从多种框架(如 TensorFlow、PyTorch)导出的模型,比如文生图/图生图模型和 Bert 类等语言模型。并在多种硬件平台上进行加速,使得开发者能够充分利用 GPU 的计算能力,快速部署 AI 应用。
NVIDIA TensorRT-LLM 是专为加速大语言模型(LLM,Large Language Models)推理设计的高性能深度学习推理库,旨在大幅提升推理效率、降低延迟并优化 GPU 利用率。它是 TensorRT 的扩展版本,主要针对大语言模型,具备自动优化、内存管理和量化的功能,能够在保持高精度的同时实现极低的推理延迟和高吞吐量。通过 TensorRT-LLM,开发者可以在英伟达的硬件平台上更高效地运行大语言模型,DiT 类模型,多模态视觉语言大模型等。
阿里云函数计算与 NVIDIA TensorRT/TensorRT-LLM 的合作基于双方在提效降本方面的共同目标。阿里云函数计算作为无服务器架构,凭借其高灵活性、弹性扩展能力以及对 GPU 算力的支持,为 AI 任务如模型推理和图像生成提供了高效的计算平台。而 NVIDIA TensorRT/TensorRT-LLM 则通过针对大模型的优化,显著提升推理效率、降低延迟,并优化 GPU 利用率。在这种背景下,双方的合作可谓一拍即合,通过结合阿里云的无缝计算体验和 NVIDIA 的高性能推理库,开发者能够以更低的成本、更高的效率完成复杂的 AI 任务,加速技术落地和应用创新。
Stable Diffusion 的推理效率革新
Stable Diffusion 是一种基于扩散模型的深度学习架构,广泛应用于生成高质量图像的任务中。其工作原理是通过逐步将随机噪声转化为清晰的图像,模型在反复推理过程中将潜在的低质量图像逐渐“清晰化”,直至生成高分辨率的最终输出。与传统生成模型不同,Stable Diffusion 通过在潜在空间进行扩散过程建模,有效减少了计算资源的消耗,同时提升了图像生成的质量和多样性。
在图像生成领域,Stable Diffusion 的重要性体现在其广泛的应用和出色的生成能力。它不仅可以生成逼真的图像,还能够在风格化图像、艺术创作、设计和广告等多个领域中提供创意支持。此外,Stable Diffusion 以其开放性和高效性,成为生成模型中的一大创新,推动了 AI 驱动的创作和设计行业的发展。
基于函数计算大幅降低部署 Stable Diffusion 应用的复杂性
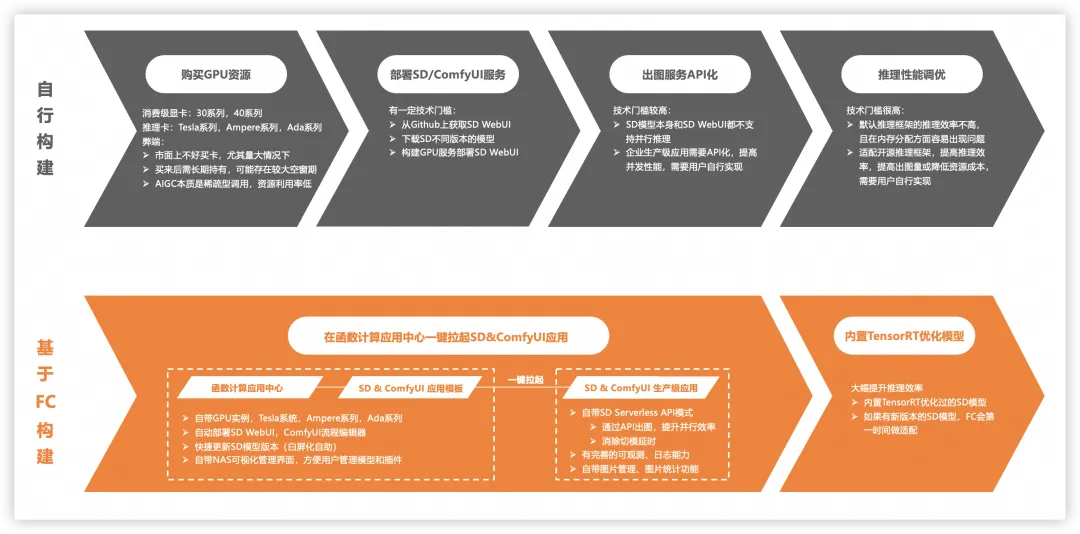
通常用户自己构建一套 Stable Diffusion 应用一般需要四个大的步骤,在每一个步骤中都有不小的工作量和技术门槛。
-
购买 GPU 资源: 众所周知,SD 模型推理是需要使用 GPU 运行的,所以首先用户需要先购买 GPU 卡,除了消费级的 30 系,40 系,还有 Ampere 系列,Ada 系列的专业推理卡,但无论哪种卡,其持有成本都不低。
- 企业用户,在需求量较大的情况下,目前市面上并不好买卡。
- GPU 买来后需长期持有,可能存在较大的使用率空窗期。
- AIGC 本质是稀疏调用场景,GPU 的资源利用普遍偏低。
-
部署 Stable Diffusion 推理服务: 虽然现在有 Stable Diffusion WebUI 这种简化使用的前端 UI,但是整体部署还是有一定的技术门槛。
- 从 Github 获取 Stable Diffusion WebUI。
- 下载 Stable Diffusion 不同版本的模型,不同版本的插件。
- 构建 GPU 服务,部署 Stable Diffusion WebUI。
-
出图服务 API 化: Stable Diffusion WebUI 虽然足够方便,但是在企业用户面向 C 端用户的场景,出图服务 API 化是刚需。
- Stable Diffusion 模型本身不支持并行推理,Stable Diffusion WebUI 也不支持多租户管理能力。
- 企业生产级应用需要 API 化,提高并发性能,需要用户自行实现。
-
推理性能调优: 推理性能的好坏直接影响单位时间内的出图效率,GPU 卡数量固定前提下的总出图数量,所以都需要用户对默认的推理框架进行优化。
- 默认推理框架的推理效率不高,且在内存分配方面容易出现问题(当有任务排队时,内存会持续增加,直到 OOM)。
- 适配开源推理框架,提高推理效率,提高出图量或降低资源成本,需要用户自行实现。
如何使用函数计算构建 Stable Diffusion 应用,只需一步。在函数计算应用中心找到 Stable Diffusion 应用模板 [ 1] ,一键部署即可自动完成上述那些复杂的步骤。
-
GPU 资源: 函数计算自带 GPU 资源,包含 Tesla 系列(函数计算提供的 T4 GPU),Ampere 系列,Ada 系列。
- GPU 实例分日间夜间计费,夜间时间为北京时间每日 0 时~6 时,夜间单价是日间单价的 5 折,即使需要长时间持有 GPU,成本也会有大幅降低。
- GPU 阶梯定价 [ 2] ,用量越大,成本越低,阶梯 3 单价比 阶梯 1 单价便宜 33%。
- 支持极速模式,既对 GPU 实例做预置快照处理,提前锁定弹性资源,有请求时从预置快照极速拉起弹性实例,避免冷启动影响(CPU 毫秒级,GPU 秒级),客户只需为预置快照付少量成本,兼顾了成本和弹性效率。
-
部署 Stable Diffusion 推理服务: 自动在 GPU 实例中部署 Stable Diffusion 模型推理服务,以及 Stable Diffusion WebUI,同时还会自带模型/插件管理界面,各参数配置界面,图片管理/统计页面,完善的可观测、日志能力等。
-
出图服务 API 化: 自带 Stable Diffusion Serverless API 模式,通过 API 出图提升并行效率,消除切换模型时的时延问题。
-
推理性能调优: 内置 TensorRT 优化过的 Stable Diffusion 模型(支持 Ampere 系列,Ada 系列 GPU),大幅提升推理效率。
基于 TensorRT 大幅提升 Stable Diffusion 推理效率
我们对 Stable Diffusion V1.5 和 Stable Diffusion XL 1.0 两个模型,在 Ampere 系列和 Ada 系列上分别做的测试验证。
- 同卡型对比,无论是 SD1.5 还是 SDXL1.0,TRT 优化模型对比原始模型,平均推理耗时均缩减了 50% 以上。
- 不同卡型对比,无论是 SD1.5 还是 SDXL1.0,L20 对比 A10,平均推理耗时均缩减了 30%~50%。
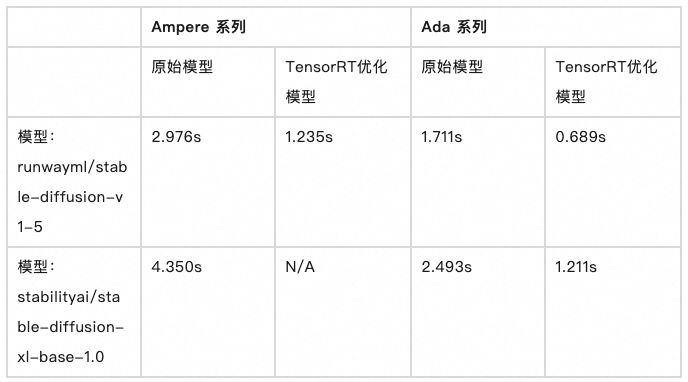
通过以上的数据不难看出,使用 NVIDIA TensorRT 优化后的模型推理效率提升 50%,那就意味着,在相同的时间内,用户的出图量可以多一倍,或者出图服务的 QPS 可以提升一倍。再加上基于函数计算构建 Stable Diffusion 应用的便利性,和函数计算 GPU 计算资源的高利用率特性,真正做到了降本提效,使业务方可以有更多的空间做产品竞争力的提升。
大语言模型的推理效率革新
阿里云 Qwen2 是一款先进的大语言模型,具备强大的理解和生成能力。它通过对海量文本数据的训练,能够在多种 NLP 应用中展现出卓越的性能,包括文本生成、机器翻译、问答系统、文本摘要等。Qwen2 采用了最新的模型架构和优化技术,显著提升了推理速度和生成质量,使其在处理复杂语言任务时表现出色。
在实际应用中,Qwen2 可以帮助企业和开发者自动化处理自然语言数据,广泛应用于智能客服、内容创作、数据分析、对话系统等场景。通过高效的语言理解和生成能力,Qwen2 大幅提升了自然语言处理任务的自动化和准确性,推动了多个行业的数字化转型与创新。
Qwen2 有 200B 的商业版模型,也有像 7B 这种的开源模型,而且在很多场景下,AI 应用的整体流程中,有一些环节用开源的大语言模型完全可以胜任,也能避免商业版模型 QPS 限制的问题,所以投入产出比更好。比如 Embedding 服务,翻译服务,代码问答服务,智能知识库等。
基于函数计算快速部署 Qwen2 7B
目前市面上有多种大语言模型托管的平台,像海外的 HuggingFace,Ollama,国内的魔搭 ModelScope。这些模型托管平台均在函数计算应用中心中有应用模板,可以快速一键进行部署。
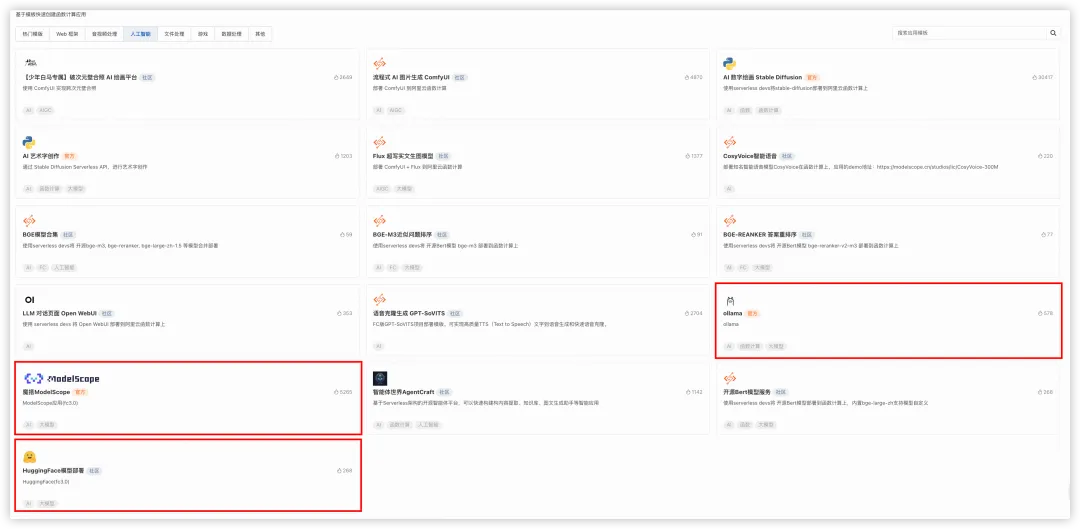
比如以 Ollama 为例,在应用中心中通过应用模板一键部署好 Ollama 服务,然后就可以通过 Ollama 的 API 下载 Qwen2 7B 模型,并运行在函数计算 GPU 资源上。
可以同样在函数计算应用中心一键部署 Ollama Open WebUI 应用,通过白屏化界面下载 Qwen2 7B。
基于 TensorRT-LLM 加速 Qwen2 7B 推理
我们测试对比了 TensorRT-LLM 和 vLLM 的推理效果:
- Qwen/QWen2-7B FP16:对比平均响应时间(RT)指标,TensorRT-LLM 对比 vLLM 改善了 21%。
- QWen/QWen2-7B FP8:对比平均响应时间(RT)指标,TensorRT-LLM 对比 vLLM 改善了 28%。
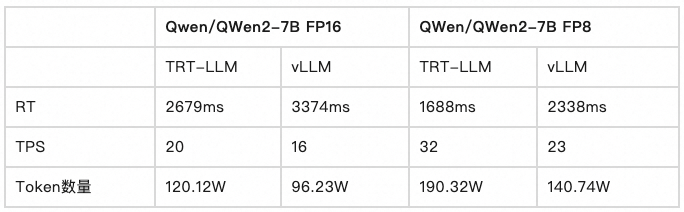
综上,使用 TensorRT-LLM 推理框架使 Qwen2 7B 的推理性能有近 30% 的提升,再加上函数计算 GPU 计算资源高效率、高利用率的特性,使用户在构建基于 LLM 的 AI 应用时在稳定性、性能、效率、成本各方面都会有大幅提升,如虎添翼。
总结
目前 NVIDIA TensorRT-LLM 已经支持了市面上所有主流的开源 LLM,同时函数计算应用中心使用 GPU 资源的应用都已支持 TensorRT-LLM 推理框架,此次云栖发布的云应用开发平台 CAP 也会全面支持 TensorRT-LLM 推理框架。
阿里云函数计算与 NVIDIA 技术团队的合作具有重要的战略意义,双方通过结合各自的技术优势,为 AI 技术的高效落地提供了强有力的支持。阿里云函数计算以其无服务器架构和弹性扩展能力,使开发者能够在无需管理底层基础设施的情况下灵活处理 AI 任务。而 NVIDIA 则通过其高性能的推理引擎,如 TensorRT,TensorRT-LLM,为深度学习模型提供了极高的计算效率和优化能力。两者的结合不仅能够加速复杂模型的推理速度,还能大幅降低 AI 应用的运行成本。
这种合作推动了 AI 技术的实际应用落地,特别是在计算密集型的任务如图像生成、自然语言处理等领域,能够通过无缝集成的高效计算平台,大规模部署 AI 模型。开发者可以借助这种平台,快速开发并迭代 AI 产品,从而缩短从概念到实际应用的时间。同时,这种合作还支持企业灵活应对动态的计算需求,特别是在面对高并发或大规模任务时,实现弹性扩展和高效资源管理,为 AI 在各个行业的广泛应用提供了坚实的技术基础。
函数计算按量付费、资源包 8 折优惠,以及面向中国站的中国内地地域夜间 5 折优惠活动正在进行中:https://www.aliyun.com/product/fc
相关链接:
[1] Stable Diffusion 应用模板
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Ffcnext.console.aliyun.com%2Fapplications%2Fcreate%3Ftemplate%3Dfc-stable-diffusion-v3&clearRedirectCookie=1&lang=zh
[2] GPU 阶梯定价
https://help.aliyun.com/zh/functioncompute/fc-3-0/product-overview/product-changes-changes-of-billable-items-resource-plans-and-trial-quota-of-function-compute