【NLP】基于“检测器-纠错器”中文文本纠错框架
前言
许多方法将中文拼写纠正(检测和纠正给定中文句子中的错误字符)视为序列标注任务,并在句子对上进行微调。一些方法使用错误检测器作为初步任务,然后将检测结果用于辅助后续的错误纠正过程。然而,现有方法在使用检测器时存在一些问题,如检测器性能不足或检测信息未能有效应用于纠正过程。
难点:中文拼写纠正的难点在于中文是由象形文字组成的,字符的形状和发音与其意义密切相关。此外,中文句子通常由连续的字符组成,没有分隔符,这使得CSC方法必须基于上下文信息来辨别错误,而不是直接从独立的词语中查找拼写错误。
本文介绍的文章提出了一种基于检测器-纠错器框架的方法,用于解决中文拼写纠正问题
方法
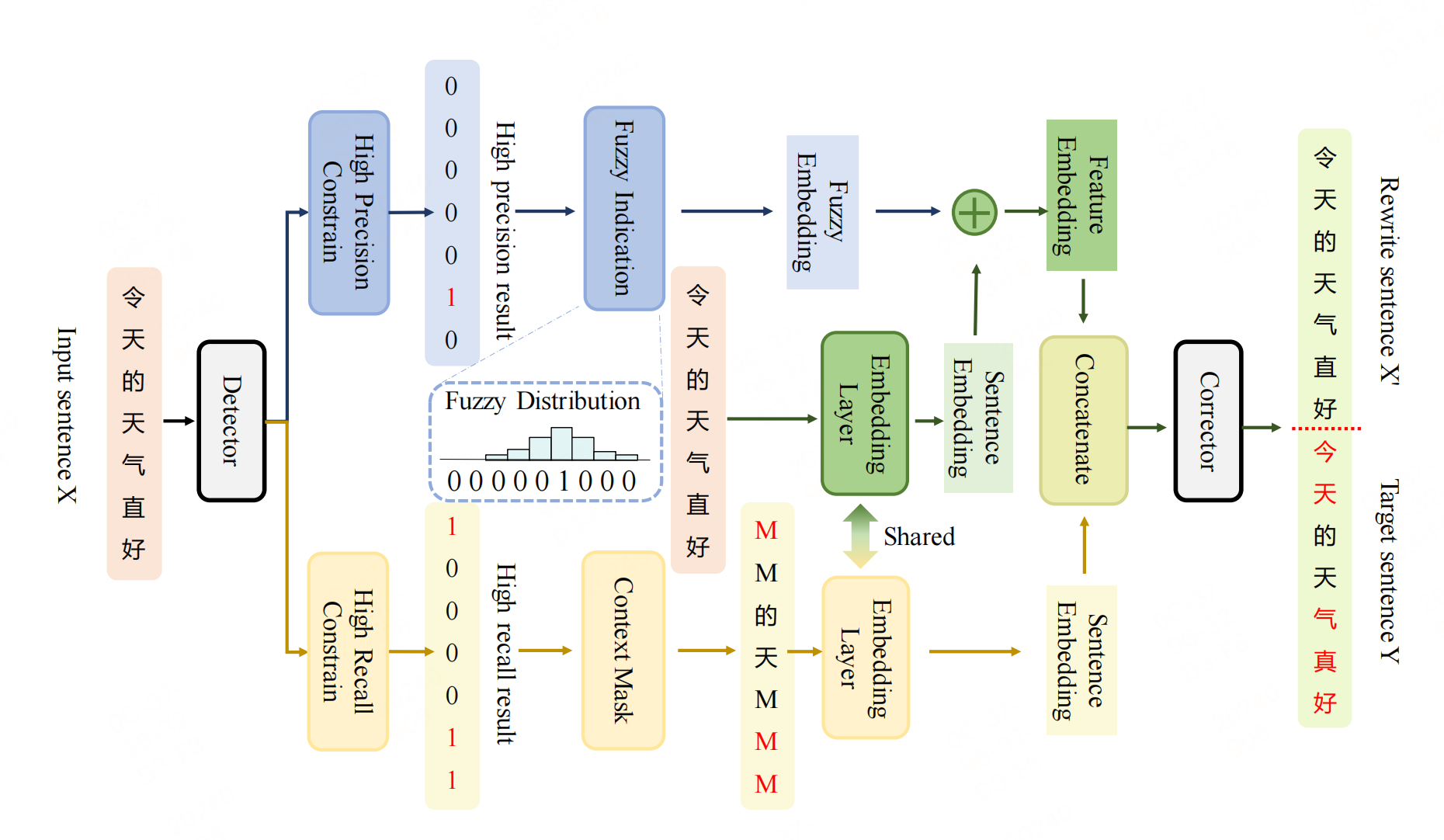
检测器
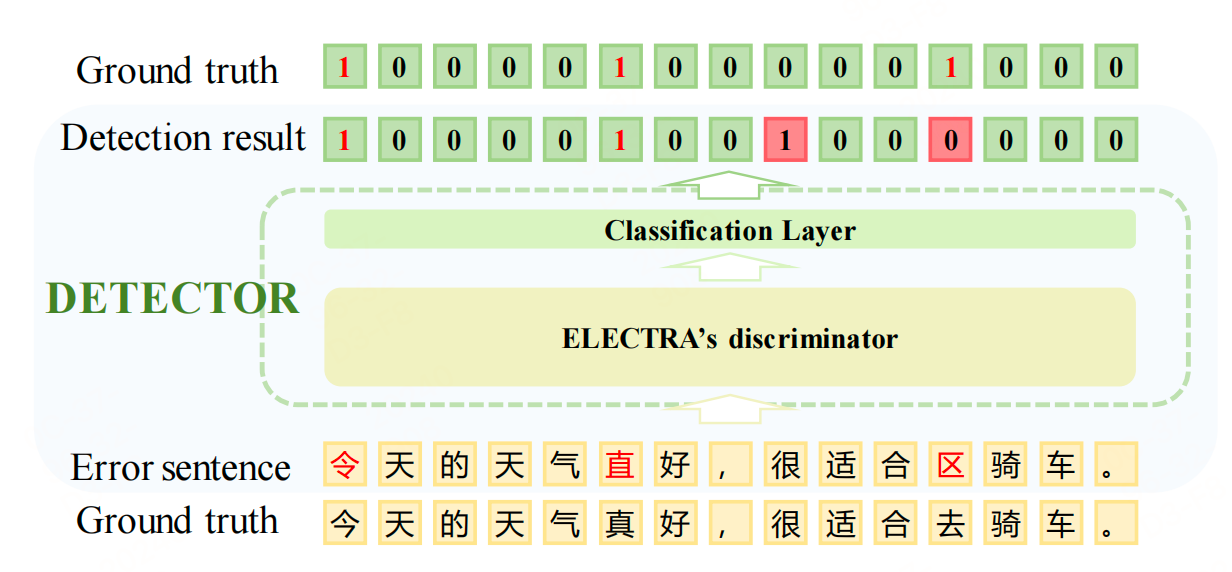
设计一个检测器生成高精度的检测结果和高召回率的检测结果。检测器基于ELECTRA模型,通过字符级别的二分类任务来识别错误字符。检测器的输出是一个概率值,表示每个字符是否为错误字符。
检测器通过设置两个阈值来获得高置信度的检测结果。高阈值用于保留高置信度的预测(高精确度),低阈值用于保留有一定置信度的预测(高召回率)。这么做有以下两个目的:
- 高精度检测结果用于特征融合,通过将检测结果直接加到源句子嵌入中,使错误字符的嵌入与其他字符区分开来。
- 高召回率检测结果用于选择性掩码策略,通过在原始句子中选择性掩码错误检测位置及其上下文,引导模型在纠正过程中考虑这些位置。
纠错器

纠正器**基于BERT模型(如:ELECTRA)**构建,使用预训练的中文BERT模型来初始化纠正器的权重。纠正器利用检测器产生的高精确度和高召回率的检测结果,分别采用错误位置信息融合策略(EP)和选择性掩蔽策略(SM)。
-
错误位置信息融合策略(EP):对于高精确度的检测结果,通过将错误检测结果直接添加到源句子嵌入中,只改变被识别为错误的标记的嵌入。为了更好地处理上下文中的错误,引入了模糊指示(Fuzzy Indication, FI)策略,将狄拉克δ分布映射到高斯分布,以适应离散情况。这种方法有助于模型在处理不精确的错误位置指示时,仍然能够正确地纠正错误。
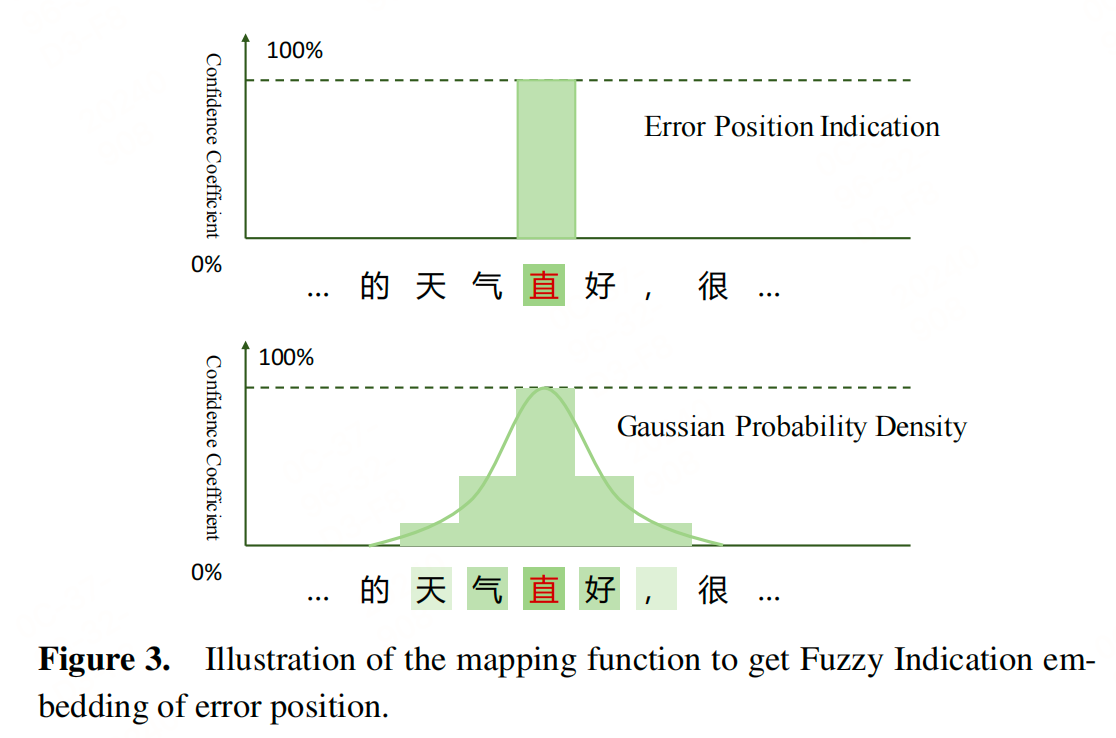
计算方法:
- 对于每个字符,根据其在句子中的位置和预设的高斯分布参数(μ, δ, s),计算其高斯分布值。
- 如果一个字符被检测为错误,其高斯分布值将显著高于其他字符,从而在嵌入中突出显示这个位置。
-
选择性遮蔽策略(SM):对于高召回率的检测结果,通过掩蔽句子中相应位置的字符(将这些字符替换为特殊的掩蔽标记(如BERT中的[MASK]标记)),并在原始句子后拼接这个部分遮蔽的句子(这样,原始句子提供了完整的上下文信息,而掩蔽的句子部分则提供了需要纠正的明确位置。)。这种方法类似于在原始句子的末尾重写句子,但为不太确定的位置留下空白。这种策略不仅提示模型在预测时考虑错误的上下文,而且在检测结果偏离时,通过扩展掩蔽长度,增强了对检测不精确性的容忍度。
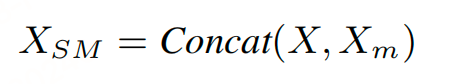
实验
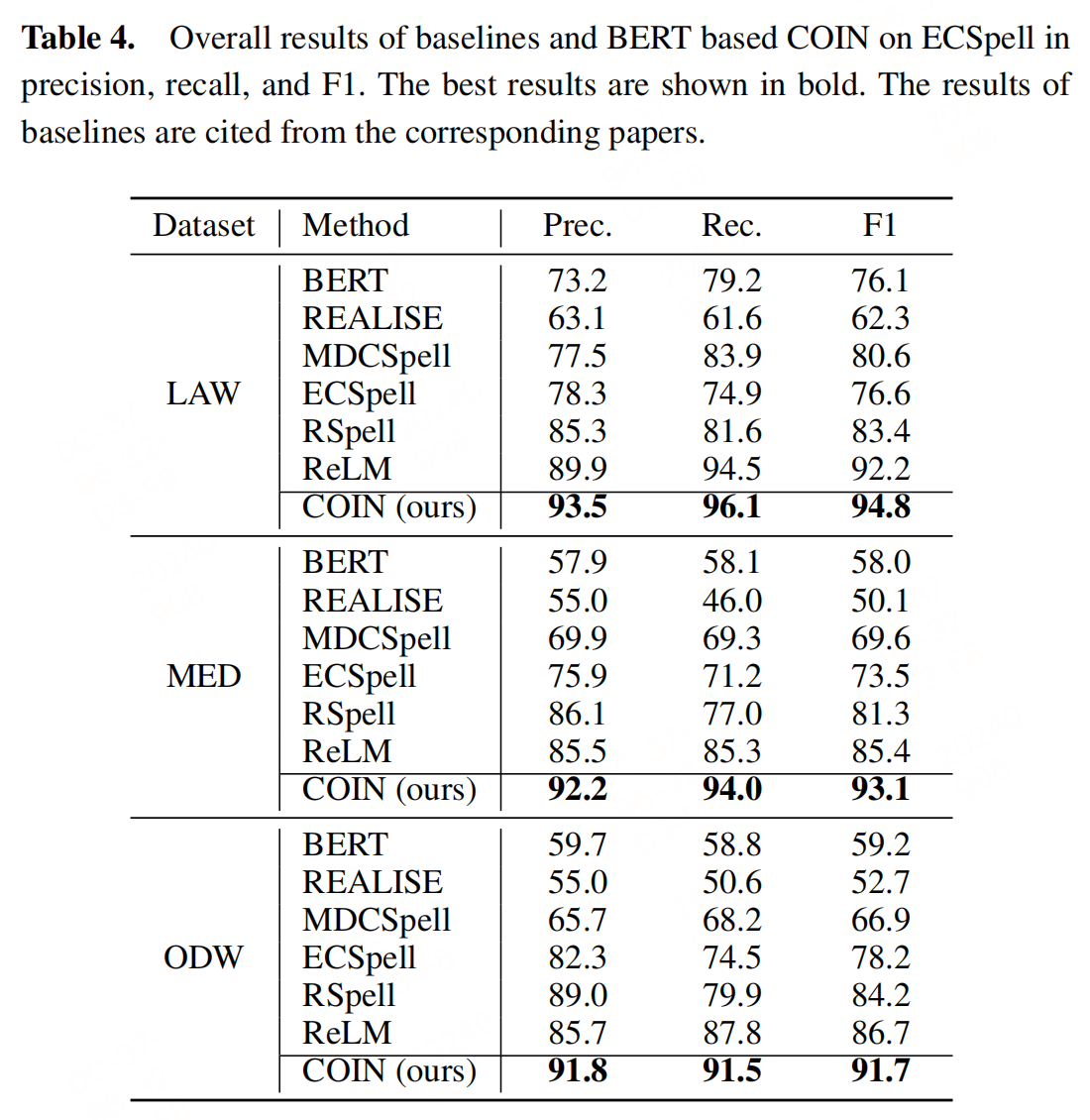
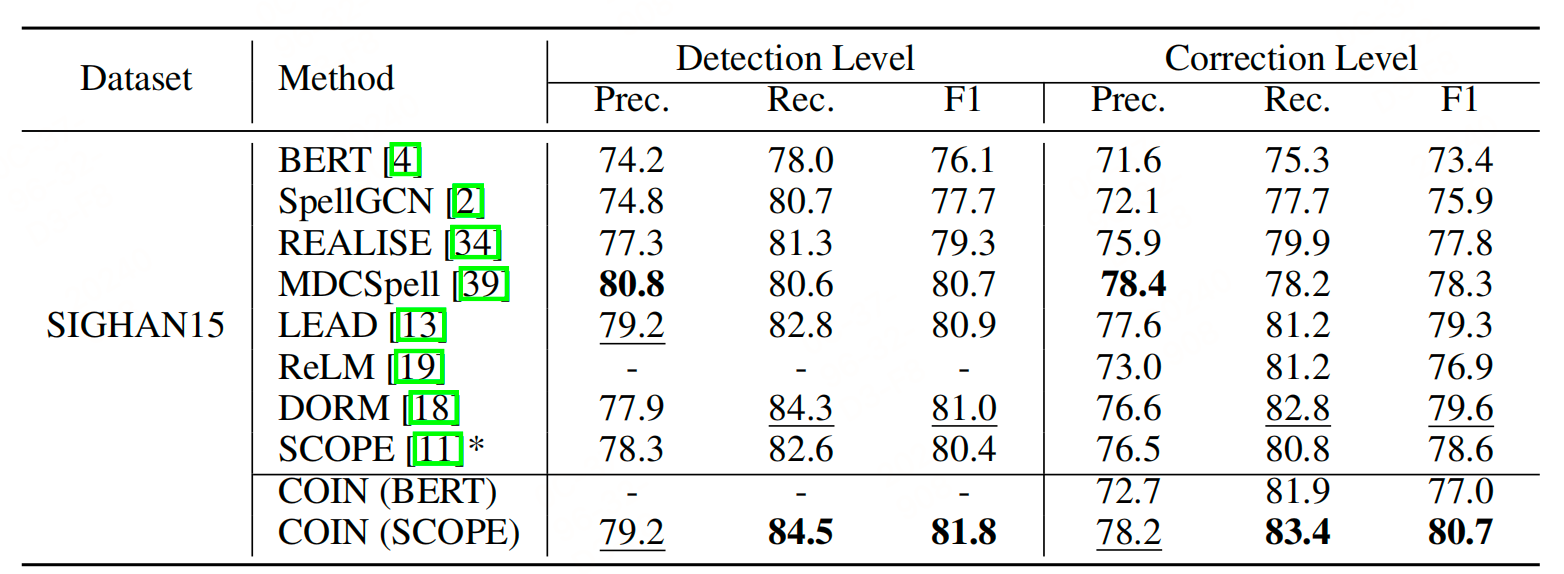
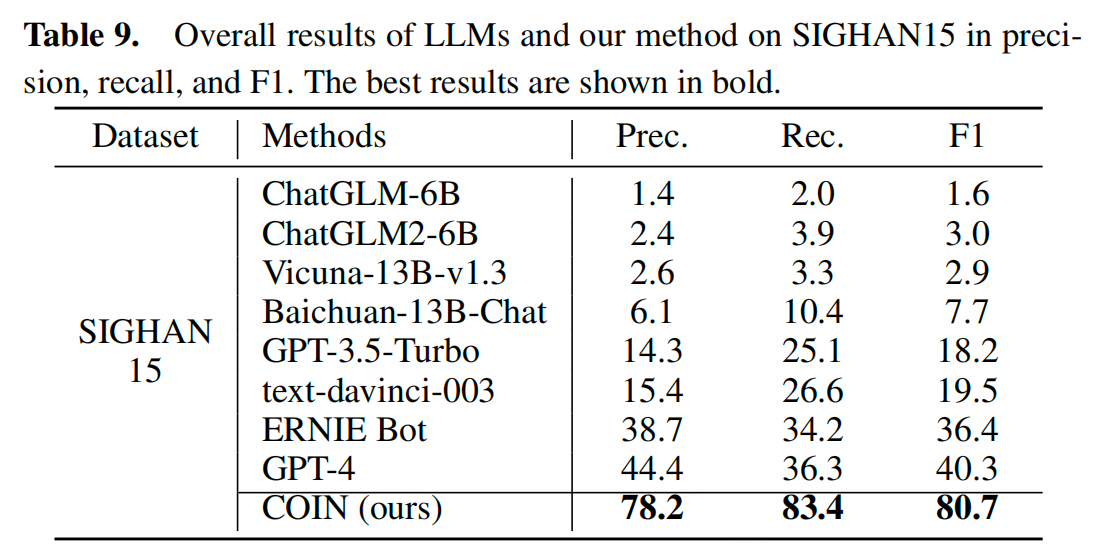


消融实验表明高斯分布在模糊指示中表现最佳,遮蔽长度为5时效果最好。
结论
这篇文章提出了一种基于检测器-纠正器框架的中文拼写纠正方法,通过设计高精度的检测器和高召回率的检测器,并结合特征融合策略和选择性遮蔽策略,提高了错误纠正的效果。本文提出的纠错方法还是属于传统NLP领域的方法,供参考。
参考文献
- A Coin Has Two Sides: A Novel Detector-Corrector Framework for Chinese Spelling Correction,https://arxiv.org/abs/2409.04150v1