安全、稳定、SLA高达99.9%:Azure OpenAI数据分离与隔离优势
近期有不少客户,由于其开发的系统软件是面向海外以及政企的,又想通过微软Azure OpenAI服务将大模型接入其业务作为优势,因此非常重视服务的安全性和稳定性。
下面将重点介绍微软Azure OpenAI 服务的数据、隐私和安全内容。
稳定:SLA高达99.9%

参考链接:
微软 Azure OpenAI 试用申请

来源微软官网:
https://www.microsoft.com/licensing/docs/view/Service-Level-Agreements-SLA-for-Online-Services?lang=5
“Azure OpenAI 资源”是指在 Microsoft Azure 订阅的 Azure 区域中创建的 Azure OpenAI 类型的 Azure 资源。
“部署”是指部署在 Azure OpenAI 资源中的模型终结点。
“请求”是指对部署的 API 调用。
“最大可用分钟数”是指在一个适用期间内,客户在 Azure OpenAI 资源中部署指定“部署”的总分钟数。
“停机时间”是指在最大可用分钟数内,部署不可用的总分钟数。如果在某一分钟内,向部署发出的请求中有 0.01% 以上返回错误代码,则认为在这一分钟内此部署不可用。如果在某一分钟内未向部署发送请求,则认为在这一分钟内此部署 100% 可用。
“正常服务时间百分比”计算公式如下所示:
![]()
服务额度:

首先,微软强调用户的数据永远是用户的,不会利用这些数据进行训练或者提供给OpenAI。

来源微软官网:
Data, privacy, and security for Azure OpenAI Service - Azure AI services | Microsoft Learn
里面提到:
您的提示(输入)和完成(输出)、您的嵌入和您的训练数据:
不提供给其他客户。
OpenAI 无法使用。
不用于改进 OpenAI 模型。
不用于改进任何 Microsoft 或第三方产品或服务。
不会用于自动改进 Azure OpenAI 模型以供您在资源中使用(模型是无状态的,除非您使用训练数据明确微调模型)。
经过微调的 Azure OpenAI 模型仅供您使用。
Azure OpenAI 服务完全由 Microsoft 控制;Microsoft 在 Microsoft 的 Azure 环境中托管 OpenAI 模型,并且该服务不会与 OpenAI 运营的任何服务(例如 ChatGPT 或 OpenAI API)交互。
Azure OpenAI 服务处理哪些数据?
Azure OpenAI 处理以下类型的数据:
提示和生成的内容。提示由用户提交,内容由服务通过完成、聊天完成、图像和嵌入操作生成。
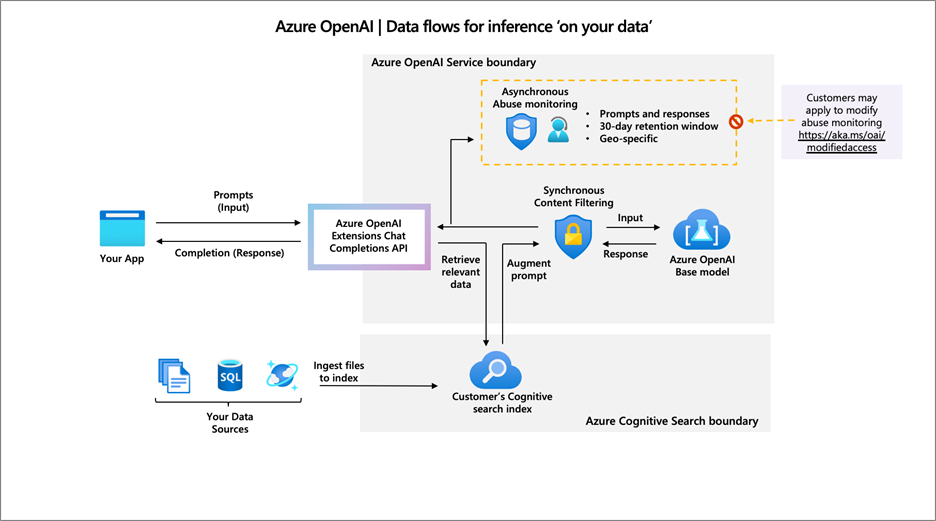
提示中包含增强数据。使用“基于您的数据”功能时,服务会从配置的数据存储中检索相关数据,并增强提示以生成以您的数据为基础的生成。
训练和验证数据。您可以提供由提示完成对组成的自己的训练数据,以便对OpenAI 模型进行微调。
Azure OpenAI 服务如何处理数据?
下图说明了您的数据是如何处理的。该图涵盖了三种不同类型的处理:
1.Azure OpenAI 服务如何处理您的提示以生成内容(包括何时使用 Azure OpenAI 将来自连接的数据源的其他数据添加到您的数据的提示中)。
2.Azure OpenAI 服务如何使用您的训练数据创建微调(自定义)模型。
3.Azure OpenAI 服务和 Microsoft 人员如何分析提示、完成和图像中是否存在有害内容以及暗示以违反行为准则或其他适用产品条款的方式使用该服务的模式。
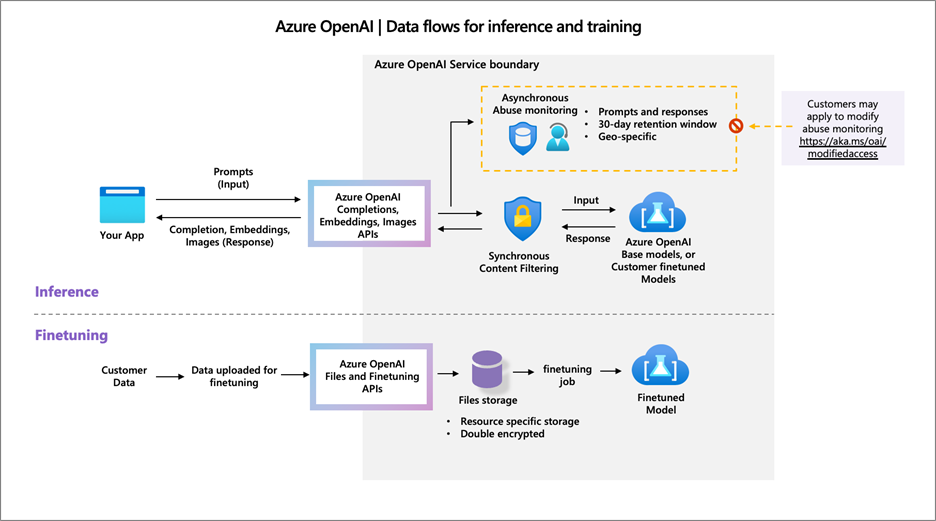
生成完成、图像或嵌入
部署在您的资源中的模型(基础或微调)处理您的输入提示并生成带有文本、图像或嵌入的响应。
提示和响应在客户指定的地理位置内处理,但可能会出于运营目的(包括性能和容量管理)在地理位置内的区域之间进行处理。该服务配置为实时同步评估提示和完成数据以检查有害内容类型并停止生成超过配置阈值的内容。在Azure OpenAI 服务内容过滤中了解更多信息。
这些模型是无状态的:模型中不存储任何提示或代数。此外,提示和代数不用于训练、重新训练或改进基础模型。
使用从数据源检索的数据增强提示,以“巩固”生成的结果
Azure OpenAI 的“基于您的数据”功能可让您连接数据源,以便将生成的结果与您的数据结合起来。数据仍存储在您指定的数据源和位置中。
没有数据被复制到 Azure OpenAI 服务中。收到用户提示时,服务会从连接的数据源检索相关数据并增强提示。模型处理此增强提示,并按上述方式返回生成的内容。
如上图所示,管理客户可以申请修改滥用监控。
使用您的数据创建定制(微调)模型:
客户可以将其训练数据上传到服务以微调模型。上传的训练数据存储在客户 Azure 租户中的 Azure OpenAI 资源中。训练数据和微调模型:
-仅供客户使用。
-与 Azure OpenAI 资源存储在同一区域内。
-可以在静态时进行双重加密(默认使用 Microsoft 的 AES-256 加密,也可以选择使用客户管理的密钥)。
-客户可以随时删除。
为微调而上传的训练数据不会用于训练、重新训练或改进任何 Microsoft 或第三方基础模型。
防止滥用和有害内容的产生
为了降低 Azure OpenAI 服务被恶意使用的风险,Azure OpenAI 服务同时包含内容过滤和滥用监控功能。要了解有关内容过滤的更多信息,请参阅 Azure OpenAI 服务内容过滤。要了解有关滥用监控的更多信息,请参阅滥用监控。
内容过滤与服务处理提示以生成内容同步进行,如上所述和此处所述。内容分类器模型中不会存储任何提示或生成的结果,也不会使用提示和结果来训练、重新训练或改进分类器模型。
Azure OpenAI 滥用监控可检测并缓解重复出现的内容和/或行为,这些内容和/或行为暗示以可能违反行为准则或其他适用产品条款的方式使用该服务。
为了检测和缓解滥用,Azure OpenAI 会将所有提示和生成的内容安全地存储长达三十 (30) 天。(如果客户获得批准并选择关闭滥用监控,则不会存储任何提示或完成内容,如下所述。)
存储提示和完成的数据存储在逻辑上按客户资源分隔(每个请求都包含客户的 Azure OpenAI 资源的资源 ID)。
每个提供 Azure OpenAI 服务的区域都有一个单独的数据存储,客户的提示和生成的内容存储在客户部署 Azure OpenAI 服务资源的 Azure 区域中,在 Azure OpenAI 服务边界内。
评估潜在滥用的人工审核人员只有在滥用监控系统标记该数据时才能访问提示和完成数据。人工审核人员是经过授权的 Microsoft 员工,他们使用请求 ID、安全访问工作站 (SAW) 和团队经理授予的即时 (JIT) 请求批准通过逐点查询访问数据。
对于部署在欧洲经济区的 Azure OpenAI 服务,经过授权的 Microsoft 员工位于欧洲经济区。