DSPy101
DSPy 介绍
DSPy(Declarative Self-improved Language Programs in Python) 是一个用于系统化和增强在流水线内使用语言模型的框架,它通过数据驱动和意图驱动的系统来优化大型语言模型(LLM)的使用。
DSPy 的核心是模块化架构,它提供了一套内置模块,这些模块可以组合成更大的程序,以构建复杂的 AI 系统 。
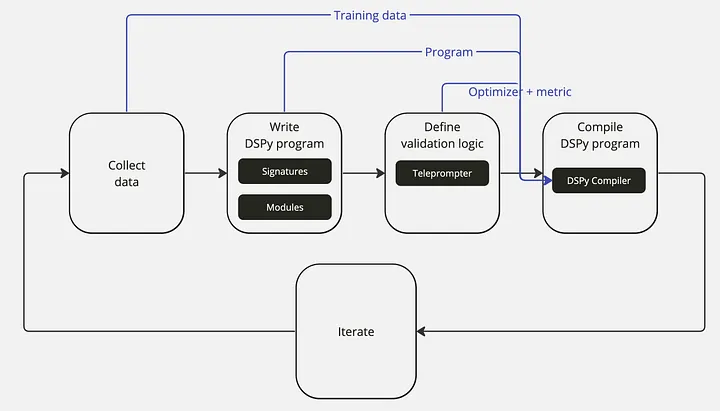
入门 DSPy,你可以遵循以下步骤:
- 安装 DSPy:首先需要安装 DSPy 库,可以通过 Python 的包管理工具 pip 进行安装。
- 配置语言模型和检索模型:在 DSPy 中配置所需的语言模型(LM)和检索模型(RM)。
- 加载数据集:加载用于训练和验证的数据集。
- 编写 DSPy 程序:使用 DSPy 的 Signature 和 Modules 定义程序逻辑和组件之间的信息流。
- 定义验证逻辑:设置验证逻辑和优化器以优化程序。
- 编译 DSPy 程序:DSPy 编译器将考虑训练数据、程序、优化器和验证度量,以优化程序。
DSPy 还引入了优化器的概念,这些优化器可以自动调整 LM 调用的提示和权重,以最大化所需指标,从而提高输出的可靠性和可预测性 。
DSPy 是一个高级的框架,它允许开发者通过编程的方式而不是传统的提示工程技术来使用大型语言模型(LLM)。下面是一个简单的示例,展示了如何使用 DSPy 构建一个问答系统。这个系统将使用一个检索增强的生成模型(RAG),它首先从文档中检索相关信息,然后生成答案。
DSPy 是一个为大型语言模型(LLMs)设计的框架,旨在通过编程方式而非传统的提示工程技术来使用这些模型。以下是 DSPy 的使用方法、目录说明和架构设计分析:
使用方法
-
安装:
- 使用 Python 的包管理工具 pip 安装 DSPy。
-
配置环境:
- 根据需要配置语言模型(LM)和检索模型(RM)。
-
编写程序:
- 使用 DSPy 的模块和签名(Signature)来定义程序逻辑。
-
编译程序:
- DSPy 编译器将根据训练数据和优化器来优化程序。
-
执行程序:
- 使用编译后的程序进行预测或其他任务。
目录说明
DSPy 的目录结构可能包括以下部分:
dspy/:主目录,包含所有 DSPy 的核心模块和类。core.py:包含 DSPy 的核心类和函数。modules/:包含各种模块,用于实现特定的功能,如检索和生成答案。teleprompt/:包含提词器(Teleprompters),用于优化程序。datasets/:包含用于训练和评估的数据集。compiler/:包含编译器相关的代码,用于优化程序。
架构设计特点
DSPy 的架构设计具有以下特点:
-
模块化:
- DSPy 采用模块化设计,每个模块负责一个具体的功能,如检索、生成答案等。
-
签名(Signature):
- 签名定义了模块的输入和输出,使得模块的接口清晰明确。
-
优化器(Teleprompters):
- 优化器用于自动调整模块的参数,以优化性能。
-
编译器:
- 编译器是 DSPy 的核心组件,它将程序、数据和优化器结合起来,生成优化后的程序。
-
数据驱动:
- DSPy 的设计允许从数据中学习,以自动调整程序的行为。
-
意图驱动:
- 通过清晰的签名和模块化设计,DSPy 允许开发者以意图驱动的方式构建程序。
-
可扩展性:
- 新的模块和优化器可以很容易地集成到现有的架构中。
-
灵活性:
- 开发者可以根据需要选择使用 DSPy 的不同组件。
-
自动化:
- 自动化优化减少了手动调整提示和模型参数的工作量。
-
可靠性:
- 通过系统化的方法,DSPy 提高了 AI 应用的可靠性和预测性。
DSPy 的架构设计使其成为一个强大且灵活的工具,适用于构建和优化基于大型语言模型的 AI 应用。通过模块化和自动化的优化,DSPy 简化了开发过程,并提高了最终应用的性能和可靠性。
如何结合 LangChain 技术使用 DSPy 框架优化语言模型?
结合 LangChain 技术使用 DSPy 框架优化语言模型,可以按照以下步骤进行:
-
理解 DSPy 框架:首先,需要了解 DSPy(Declarative Language Model Programming)是一个由斯坦福大学研究人员开发的开源项目,旨在通过声明式编程来优化大型语言模型(LLM)。它将传统提示词工程转变为以编程为中心的方法,用于基于语言模型的应用程序。
-
自动化 Prompt 生成和管理:DSPy 作为一个高效的自动化 Prompt 框架,简化了复杂的 Prompt 生成和管理过程。可以通过快速上手教程在短时间内实现自动化 Prompt 的创建和优化。
-
编程优先:DSPy 优先考虑编程而非手动调整提示词,以创建更复杂的 LMP 应用。这意味着在使用 DSPy 时,应避免一次性训练或提示模型解决整个问题,而是通过逐步优化和编程来解决问题。
-
结合 LangChain 技术:LangChain 技术可以与 DSPy 框架结合,利用 LangChain 提供的工具和库来增强 DSPy 的功能。例如,LangChain 可能提供额外的数据处理、模型集成或后处理功能,这些都可以与 DSPy 的声明式编程和自动化 Prompt 生成相结合,以进一步优化语言模型的性能。
-
优化流程:DSPy 引入了一种独特的编译过程,为特定任务优化整个流程。这包括使用 LangChain 技术来优化数据流、模型训练和推理过程,确保语言模型在不同任务中的高效运行。
-
综合应用:结合 LangChain 技术和 DSPy 框架,可以实现从数据预处理到模型微调、检索增强生成(RAG)和 Fine-tuning 等多方面的优化。这种综合应用可以提高语言模型的准确性、知识更新速度和答案透明度。
-
代码示例:
pip install dspy
import dspy
llm = dspy.OpenAI(model='gpt-3.5-turbo',api_key=openai_key)
dspy.settings.configure(lm=llm)
# 实现一个未优化的谎言检测器
text = "Barack Obama was not President of the USA"
lie_detector = dspy.Predict("text -> veracity")
response = lie_detector(text=text)
print(response.veracity)
# 假设你想控制输出,使其始终为布尔值(True 或 False)
# 之前的简单实现无法保证这一点
# 一种保证方法是使用更精确的签名
# 精确签名
class LieSignature(dspy.Signature):
"""Identify if a statement is True or False"""
text = dspy.InputField()
veracity = dspy.OutputField(desc="a boolean 1 or 0")
lie_detector = dspy.Predict(LieSignature)
response = lie_detector(text=text)
print(response.veracity)
# 生成合成数据
from typing import List
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
model = ChatOpenAI(temperature=1, api_key=openai_key)
class Data(BaseModel):
fact: str = Field(description="A general fact about life or a scientific fact or a historic fact")
answer: str = Field(description="The veracity of a fact is a boolean 1 or 0")
parser = JsonOutputParser(pydantic_object=Data)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
chain.invoke({"query": "Generate data"})
# 创建10对事实-答案的列表
list_of_facts = [chain.invoke({"query": "Generate data"}) for i in range(10)]
few_shot_examples = [dspy.Example(fact) for fact in list_of_facts]
print(list_of_facts)
# 先前方法存在的问题,数据多样性不足
# 访问模式
data_schema = Data.schema()
# 访问模式中的属性描述
fact_description = data_schema['properties']['fact']['description']
answer_description = data_schema['properties']['answer']['description']
list_of_facts = []
for i in range(10):
prompt = f"Generate data. Should be different than {list_of_facts}. Answers should be diverse and representative of {answer_description}"
example = chain.invoke({"query": prompt })
list_of_facts.append(example)
few_shot_examples = [dspy.Example(fact) for fact in list_of_facts]
print(list_of_facts)
# 合成提示优化
from dspy.teleprompt import BootstrapFewShot
from dspy.evaluate import answer_exact_match
text = "Barack Obama was not President of the USA"
# 将事实定义为谎言检测器的输入
trainset = [x.with_inputs('fact') for x in few_shot_examples]
# 定义谎言检测器模块使用的签名
# 为了评估,你需要定义一个答案字段
class Veracity(dspy.Signature):
"Evaluate the veracity of a statement"
fact = dspy.InputField(desc="a statement")
answer = dspy.OutputField(desc="an assessment of the veracity of the statement")
class lie_detector(dspy.Module):
def __init__(self):
super().__init__()
self.lie_identification = dspy.ChainOfThought(Veracity)
def forward(self, fact):
return self.lie_identification(fact=fact)
teleprompter = BootstrapFewShot(metric=answer_exact_match)
compiled_lie_detector = teleprompter.compile(lie_detector(), trainset=trainset)
response = compiled_lie_detector(fact=text)
print(f"veracity {response.answer}")
DSPy Visualizer
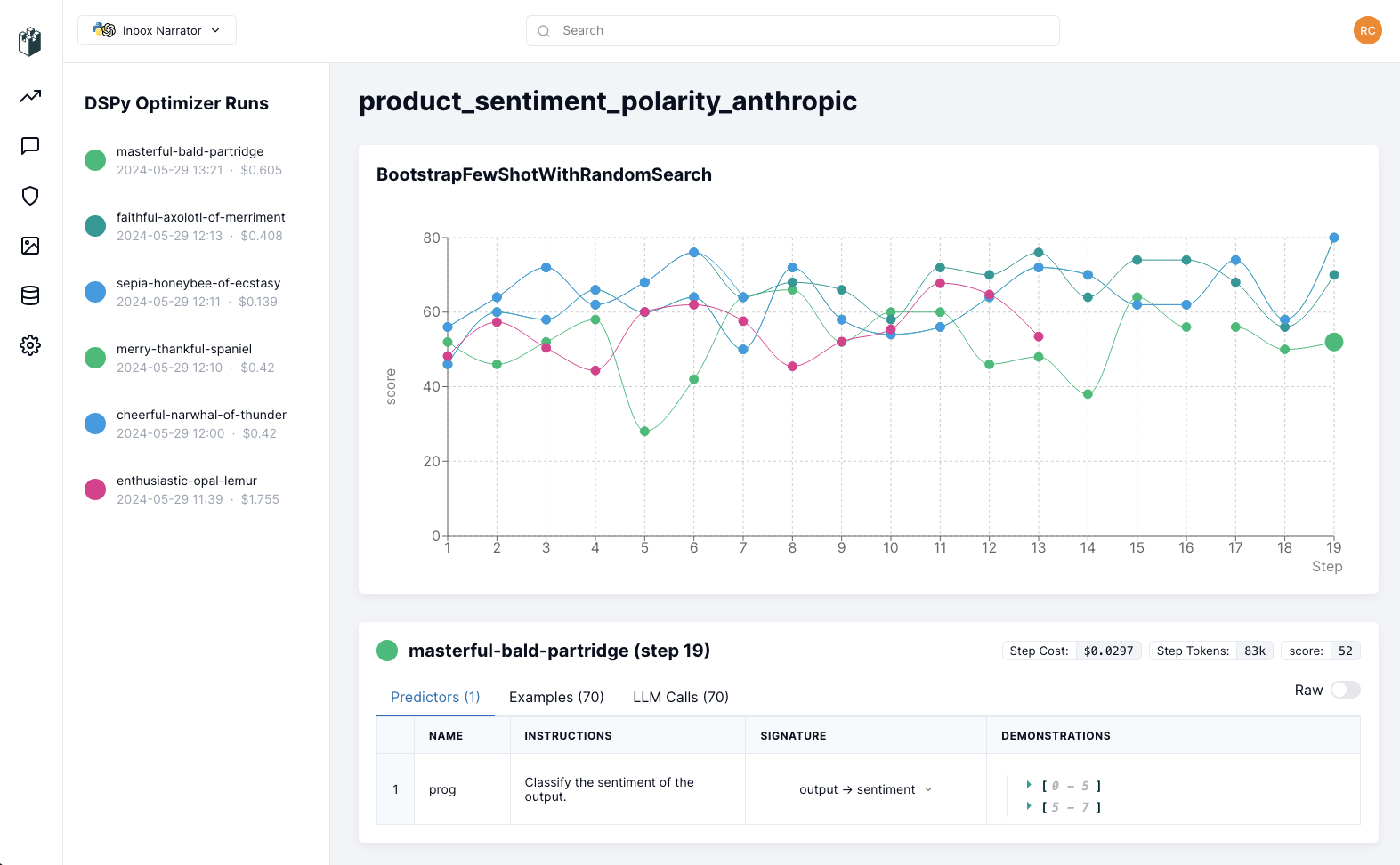
使用场景
以下是 DSPy 适合使用的一些场景以及相应的例子:
-
自动化任务优化:
- 场景:自动化地优化 AI 任务,如问答系统、摘要生成等,以提高性能。
- 例子:使用 DSPy 构建一个问答系统,该系统能够自动调整提示和模型权重,以提高答案的准确性。
-
复杂 AI 系统的构建:
- 场景:构建需要多个步骤和组件协同工作的复杂 AI 系统。
- 例子:开发一个多模态 AI 助手,它结合了图像识别、自然语言处理和知识检索来回答问题。
-
提高系统的可靠性和可预测性:
- 场景:在需要高度可靠性的应用中,如医疗咨询或法律分析。
- 例子:创建一个医疗咨询系统,它使用 DSPy 来确保所有医疗建议都是基于最新和最准确的数据。
-
减少对人工干预的依赖:
- 场景:减少在 AI 系统开发和维护过程中对人工干预的需求。
- 例子:自动化地生成和调整代码文档,减少手动编写和更新的需求。
-
教育和研究:
- 场景:在教育和研究中使用 DSPy 来教授和探索 AI 系统的设计和优化。
- 例子:在大学课程中使用 DSPy 来展示如何构建和优化一个机器翻译系统。
-
跨领域应用:
- 场景:在不同领域中应用 AI 技术,如金融、法律、医疗等。
- 例子:在金融领域,使用 DSPy 构建一个系统,该系统能够分析市场趋势并提供投资建议。
-
快速原型开发:
- 场景:快速开发 AI 原型,以验证新想法或解决方案的可行性。
- 例子:开发一个原型系统,用于自动生成新闻摘要,以评估自动化内容创作的潜力。
-
集成和扩展现有系统:
- 场景:将 AI 能力集成到现有的软件系统中,或扩展现有系统的功能。
- 例子:将 DSPy 集成到客户服务系统中,以自动回答常见问题并提高响应速度。
-
优化特定领域的约束:
- 场景:在特定领域中优化 AI 系统,以遵守该领域的特定规则和约束。
- 例子:在法律领域,使用 DSPy 构建一个合同审查工具,确保所有合同草案都符合法律要求。
-
探索新的 AI 应用:
- 场景:探索和实验新的 AI 应用,以发现新的使用场景和解决方案。
- 例子:使用 DSPy 构建一个创意写作助手,它能够根据用户提供的关键词和主题生成故事。
DSPy 通过其模块化架构和优化器,为上述场景提供了一种系统化和自动化的方法来构建和优化 AI 系统。
大厂案例:腾讯 TiDB 使用 DSPy
https://juejin.cn/post/7394284803748839424
实战,上代码!
请注意,这个示例需要你已经安装了 DSPy 和必要的依赖项。
此外,示例中的代码可能需要根据你的具体环境和 DSPy 的版本进行调整。
示例 1: 文本分类
DSPy 是一个框架,它专注于通过编程方式来使用大型语言模型(LLMs),而不是传统上使用提示工程技术。
虽然 DSPy 的核心优势在于构建复杂的、多步骤的 AI 系统,但它也可以用于更传统的自然语言处理(NLP)任务,比如文本分类或情感分析。以下是使用 DSPy 进行这类任务的一般步骤:
- 安装和配置 DSPy
首先,确保你已经安装了 DSPy 和所需的依赖项。
pip install dspy
-
选择或配置语言模型
选择一个适合文本分类或情感分析任务的语言模型。DSPy 支持多种语言模型,你可以选择一个预训练的模型,或者使用自己的模型。 -
准备数据集
准备你的训练和测试数据集。数据集应该包含文本样本及其对应的标签。 -
定义任务签名
使用 DSPy 的Signature来定义任务的输入和输出。例如,对于文本分类任务,输入是文本,输出是类别标签。
from dspy import Signature
TextClassification = Signature('text -> label')
- 创建模块
创建一个或多个模块来处理文本。这可能包括数据预处理、特征提取、模型预测等步骤。
from dspy import Module
class TextClassifier(Module):
def __init__(self, language_model):
super().__init__()
self.language_model = language_model
def forward(self, text):
# 这里可以添加预处理步骤
preprocessed_text = self.preprocess(text)
# 使用语言模型进行预测
prediction = self.language_model(preprocessed_text)
return prediction
-
编写优化逻辑
使用 DSPy 的优化器来调整模型参数,以提高任务性能。这可能涉及到调整提示、模型权重等。 -
编译程序
使用 DSPy 编译器来编译你的程序,这将包括优化步骤。
from dspy import compile
compiled_classifier = compile(TextClassifier, optimizer)
-
训练和评估模型
使用训练数据集来训练模型,并在测试数据集上评估其性能。 -
进行预测
使用编译后的模型对新的文本样本进行分类或情感分析。
new_text = "这里是需要分类或分析情感的文本。"
prediction = compiled_classifier(new_text)
print(f"预测结果: {prediction}")
注意事项
- DSPy 的设计初衷是为了处理更复杂的多步骤任务,因此对于简单的文本分类或情感分析任务,可能存在更简单、更直接的工具和库,如 scikit-learn、Hugging Face 的 Transformers 等。
- DSPy 的优势在于能够将复杂的多步骤 NLP 任务自动化和优化,例如结合检索和生成的问答系统。
使用 DSPy 进行自然语言处理任务时,你可能需要根据任务的具体需求来调整上述步骤,包括数据预处理、模型选择、优化策略等。
示例 2:问答系统
它包括了检索相关信息和生成答案的过程,并通过编译器进行了优化。
这只是一个基础示例,实际应用中可能需要更复杂的数据处理、模型配置和优化策略。
# 导入DSPy库和相关组件
import dspy
from dspy import Signature, Module, Predict, ChainOfThought, Retrieve
# 配置语言模型和检索模型
# 假设我们使用的是OpenAI的模型和一些示例检索模型
turbo = dspy.OpenAI(model='gpt-3.5-turbo')
dspy.settings.configure(lm=turbo, rm='some-retriever-model')
# 加载数据集,这里使用一个假设的数据集加载函数
# 实际使用时需要根据你的数据集进行调整
from dspy.datasets import load_dataset
dataset = load_dataset('your-dataset-name')
# 定义一个Signature,描述输入和输出
GenerateAnswer = Signature('context, question -> answer')
# 创建一个Retrieve模块,用于从文档中检索相关信息
class RAGRetrieve(Module):
def __init__(self, k=3):
super().__init__()
self.retrieve = Retrieve(k=k)
def forward(self, question):
return self.retrieve(question)
# 创建一个ChainOfThought模块,用于生成答案
class RAGGenerateAnswer(Module):
def __init__(self):
super().__init__()
self.generate_answer = ChainOfThought(GenerateAnswer)
def forward(self, context, question):
return self.generate_answer(context=context, question=question)
# 创建一个RAG模型,组合检索和生成答案的模块
class RAG(Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = RAGRetrieve(k=num_passages)
self.generate_answer = RAGGenerateAnswer()
def forward(self, question):
context = self.retrieve(question)['passages']
prediction = self.generate_answer(context=context, question=question)
return prediction
# 实例化RAG模型
rag = RAG()
# 定义优化器,这里使用一个简单的优化器作为示例
# 实际使用时可能需要更复杂的优化策略
from dspy.teleprompt import LabeledFewShot
optimizer = LabeledFewShot(metric=dspy.evaluate.answer_exact_match)
# 编译模型,这里简化了编译过程
compiled_rag = dspy.compile(rag, optimizer=optimizer)
# 使用模型进行预测
question = "What is the capital of France?"
prediction = compiled_rag(question)
# 打印预测结果
print(f"Question: {question}")
print(f"Answer: {prediction.answer}")