快速实现AI搜索!Fivetran 支持 Milvus 作为数据迁移目标


Fivetran 现已支持 Milvus 向量数据库作为数据迁移的目标,能够有效简化 RAG 应用和 AI 搜索中数据源接入的流程。
数据是 AI 应用的支柱,无缝连接数据是充分释放数据潜力的关键。非结构化数据对于企业搜索和检索增强生成(RAG)聊天机器人等 AI 应用有着巨大价值。随着数据量的增长,像 Milvus 这样的可扩展向量数据库对于高效搜索组织信息至关重要。
用于搜索的数据通常存储在各种地方,如云存储、商业应用和关系型数据库中。常见的方法是将这些不同来源的数据合并到同一个存储库中,将非结构化数据(如文本)转换为 Embedding 向量,同时将元数据也一同存储在向量数据库中。这样一来,AI 应用能够访问多种数据集并适应数据源的变化。
Fivetran 现已支持 Milvus 向量数据库作为数据迁移的目标,有效简化了上述流程,用户无需构建、维护和监控复杂的数据管道(Data Pipeline)。数据工程师只需轻击几下鼠标,便可以创建快速、高效且可扩展的 AI 搜索解决方案,更专注于创造业务价值,而不是管理复杂的基础设施。
01.
Milvus 和 Fivetran 如何为 AI 构建基础
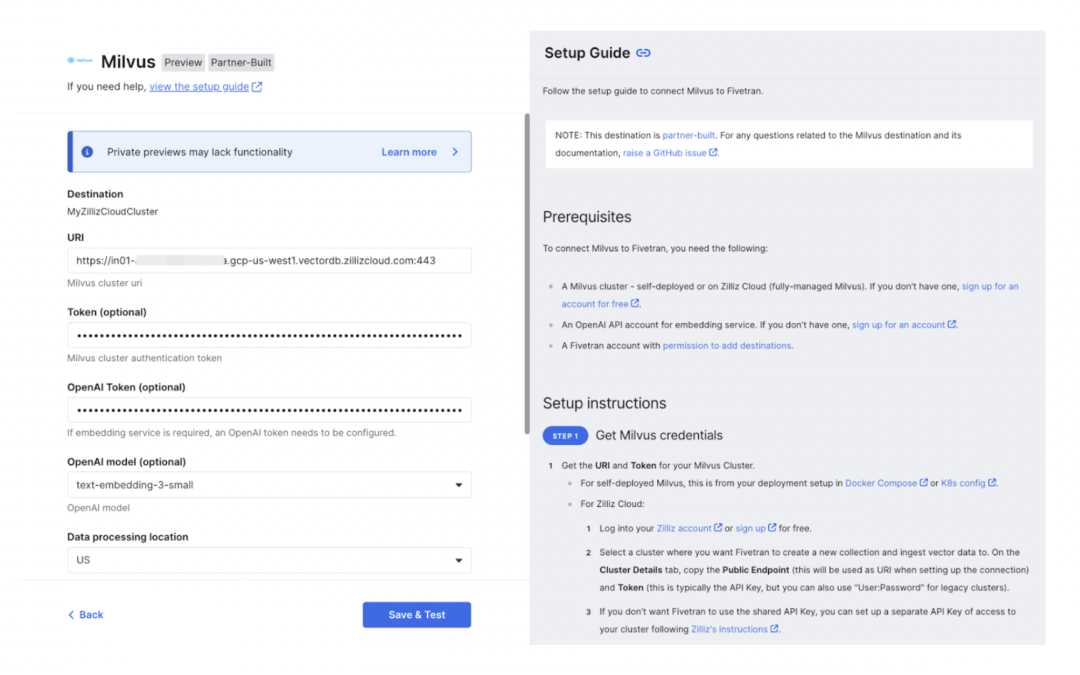
Milvus 是一款高性能、高度可扩展的开源向量数据库。在 Kubernetes 上部署的单个 Milvus 集群可以处理数十亿向量数据。Zilliz Cloud 是全托管的 Milvus 服务,增加了企业级特性(如 RBAC 和 SOC2 安全合规认证),并且自带专有的 Cardinal 向量搜索引擎,性能更出色。Milvus 和 Zilliz Cloud 被广泛应用于语义搜索、RAG 和多模态搜索等应用中。构建 AI 搜索解决方案的一个挑战是如何将来自各种来源的数据 Ingest 到 Milvus 中,以实现实时搜索。Fivetran 支持 Milvus 向量数据库作为数据迁移的目标,简化了将任何来源的数据 Ingest 到 Milvus 的流程,帮助企业免去管理传输的麻烦,更高效地分析数据。通过利用 Milvus 的高级向量搜索功能和简化的数据传输流程,开发者可以快速构建AI 应用,充分利用其组织来自多样数据源的数据 。
使用 Fivetran 的 Milvus 目标,您可以:
通过 Fivetran 连接器(Connector)将超过 500 个数据来源的数据 Ingest 到 Milvus/Zilliz Cloud 中。
使用 OpenAI Embedding 模型简化非结构化数据的提取、加载和向量化流程。
通过结构化数据列,实现在向量搜索过程中进行元数据过滤。
构建近实时的搜索功能,支持增量数据同步。
02.
Fivetran 的 Partner SDK:构建自定义连接器和目标
Fivetran 的 Partner SDK 使技术供应商能够为其服务创建源或目标连接器,并与 Fivetran 的自动化数据移动平台无缝集成。Partner SDK 的关键优势包括:
灵活的开发语言:基于 gRPC 的 SDK 允许使用任何支持的编程语言编写源和目标连接器,为开发者提供灵活性,以便在他们选择的语言中重用或编写新代码。
降低复杂性:通过模板和本地测试环境,第三方供应商可以轻松测试和部署连接器。
数据平台的新机遇:SDK 为产品开辟了新渠道,允许数据仓库、数据湖和存储平台轻松访问 Fivetran 的 500 多个连接器。
Zilliz 是 Milvus 背后的原厂,通过将其向量数据库操作紧密映射到 Fivetran 的关系型更新模型,构建了与 Fivetran 的集成。他们还简化了第三方解决方案的使用流程,例如通过 OpenAI Embedding 服务,在 Ingestion 过程中生成向量。
03.
AI 搜索演示
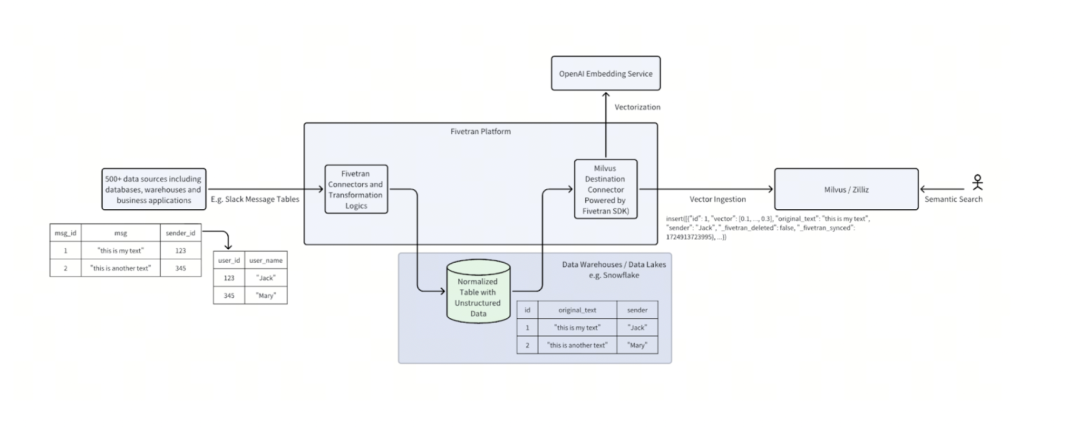
非结构化数据虽然通常最有价值,但也是最具挑战性的数据类型。借助 Fivetran 和 Milvus,企业可以快速且轻松地构建 AI 驱动的搜索工具,从丰富的数据集中获取洞察。
Fivetran 的全托管连接器可以自动、可靠且安全从主要的商业应用中传输数据,且支持 Schema 迁移。例如,一家公司想要为其 Slack 消息构建一个内部搜索工具。使用 Fivetran 的 Slack 连接器,数据首先被复制并以规范化格式存储在数仓或 data lakehouse(如 Snowflake)中。然后,可以反范式化、连接、分块和转换这些数据,之后可以通过 Fivetran 的 Snowflake 源连接器连接到 Milvus。只需将文本块存储在名为 original_text 的列中,Milvus 目标就会自动调用 OpenAI Embedding 服务为文本生成向量。向量与所有其他标签一起作为标量字段存储在 Milvus 中,随后通过向量相似性搜索和元数据过滤实现高效的语义搜索。
04.
总结
新推出的 Fivetran 的 Milvus 目标连接器进一步扩展了 AI 领域中的数据范围,实现了对多种数据源数据进行语义搜索。通过将来自多种数据库/数仓和商业应用的源数据 Ingest 到 Milvus 向量数据库,这种集成使得 AI 工作流变得更加轻松高效。欢迎根据设置说明使用 Fivetran 的 Milvus 目标连接器。
作者介绍

陈将
Zilliz 生态和 AI 平台负责人
推荐阅读