Linux 搭建与使用yolov5训练和检验自建模型的步骤
Linux 搭建与使用yolov5训练和检验自建模型的步骤
硬件设备
环境搭建(无cuda)
下载anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
bash Anaconda3-2024.06-1-Linux-x86_64.sh
# 看完许可证后, yes, 后面选择安装路径, 可以按默认路径/home/[用户名]/anaconda3
当看到后面的内容, 可以选择是否自动初始化conda, 如果选择默认no, 则需要手动先source [path/to/anaconda]/bin/activate
WARNING:
You currently have a PYTHONPATH environment variable set. This may cause
unexpected behavior when running the Python interpreter in Anaconda3.
For best results, please verify that your PYTHONPATH only points to
directories of packages that are compatible with the Python interpreter
in Anaconda3: /home/smile/anaconda3
Do you wish to update your shell profile to automatically initialize conda?
This will activate conda on startup and change the command prompt when activated.
If you'd prefer that conda's base environment not be activated on startup,
run the following command when conda is activated:
conda config --set auto_activate_base false
You can undo this by running `conda init --reverse $SHELL`? [yes|no]
[no] >>>
激活anaconda
如果是一路敲回车
source ~/anaconda3/bin/activate
如果修改了默认路径, 则需要将上面的路径修改为新路径
当看到在用户名以及主机名前面出现(base)就说明安装完成了

创建虚拟环境
这里的代码只能复制 $ 后面的, 前面只是为了显示当前的环境
# 创建以python38为基础的虚拟环境
(base) smile@smile: ~/$ conda create -n yolo python=3.8
# 查询是否创建成功
(base) smile@smile:~/$ conda env list
# conda environments:
#
base /home/smile/anaconda3
yolo * /home/smile/anaconda3/envs/yolo
# 激活yolo虚拟环境
(base) smile@smile: ~/$ conda activate yolo
# 执行完以后, 终端应该以(yolo)开头
(yolo) smile@smile: ~/$
下载yolo源码
注: 以下操作均在虚拟环境(yolo)中进行, 尤其是下载依赖时, 一定要在虚拟环境, 否则会影响系统的python环境, 可能发生系统异常或程序异常
mkdir ~/MachineLearning
git clone https://github.com/ultralytics/yolov5.git #注这里的是yolov5
cd yolov5
which pip # 检查当前使用的pip是否是虚拟环境中的pip
# 如果返回的内容类似: /home/smile/anaconda3/envs/yolo/bin/pip 看到anaconda3就可以放心执行下面的命令
pip install -r requirements.txt # 注: 这里一定要是虚拟环境!!!!
# 下载依赖的过程会比较慢(墙), 建议手动指定使用阿里源进行下载
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
修改yolo源码(非必需, 出错再来看)
getsize找不到
默认下载的pillow版本比较新, 新版本的pillow弃用了 getsize(label) 方法, 应该使用getbbox(label)
如果报错类似
with torch.cuda.amp.autocast(amp):
Exception in thread Thread-6:
Traceback (most recent call last):
File "/home/zc/MachineLearning/anaconda3/envs/yolo/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/home/zc/MachineLearning/anaconda3/envs/yolo/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/home/zc/MachineLearning/yolov5/utils/plots.py", line 305, in plot_images
annotator.box_label(box, label, color=color)
File "/home/zc/MachineLearning/yolov5/utils/plots.py", line 91, in box_label
w, h = self.font.getsize(label) # text width, height
AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
按照下面的步骤修改代码即可(不影响训练, 只是无法绘制标定框上面的文字, 在训练完成后没有输出图片, 可能会影响识别, 毕竟写不了字, 可能导致程序异常退出)
路径: /path/to/yolov5/utils/plots.py
修改项:
# 修改前
w, h = self.font.getsize(label) # 第91行(或差不多的位置, 可以直接查询font.getsize)
# 修改后
w, h = self.font.getbbox(label)[2:4] # text width, height
w, h = self.font.getsize(text) # 第170行(或差不多的位置, 可以直接查询font.getsize)
# 修改后
w, h = self.font.getbbox(text)[2:4] # text width, height
潜在风险
0%| | 0/97 00:00train.py:307: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.`
有一个方法被弃用了, 只是暂时还支持该方法, 后面可能会出问题, 因此先找找, 可以先不改, 但是得知道
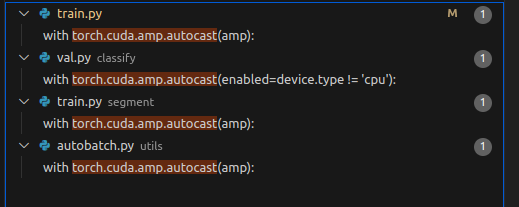
一共4处, 可以修改为(暂未验证, 只是查了一下)
with torch.amp.autocast(device_type='cuda', enabled=amp):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
使用默认的模型对图片或视频流进行检测
开始检测
- –weights: 指定模型权重文件路径(.pt)
- 示例:
--weights yolov5s.pt
- 示例:
- –source: 输入源,可以是视频文件、图片文件、文件夹、或者摄像头(例如
0)- 示例:
--source 0(摄像头, 这里一般是笔记本自带的)、--source ./images(文件夹)
- 示例:
- –img-size: 输入图像的大小,默认是 640
- 示例:
--img-size 640
- 示例:
- –conf-thres: 置信度阈值,默认为 0.25,低于此值的检测将被过滤
- 示例:
--conf-thres 0.25
- 示例:
- –classes: 选择要检测的类别(用逗号分隔的类别索引)
- 示例:
--classes 0,2(只检测类别 0 和 2)
- 示例:
- –name: 指定保存结果的子目录名称
- 示例:
--name runs/detect/exp
- 示例:
常见的使用场景
注: yolov5s.pt 可以检测的类别可以参考/path/to/yolo/data/coco128.yaml, 总计80种不同类别
注: 以下操作均在虚拟环境(yolo)中进行
# 检测视频流(摄像头)
python detect.py --weights yolov5s.pt --source 0
# 仅检测特定类别(例如人和车)这里的类别的标签来自上述的coco128.yaml
python detect.py --weights yolov5s.pt --source ./images --classes 0,2
# 检测图片
python detect.py --weights yolov5s.pt --source ./images/image.jpg
训练自己的模型
准备数据集
公开数据集
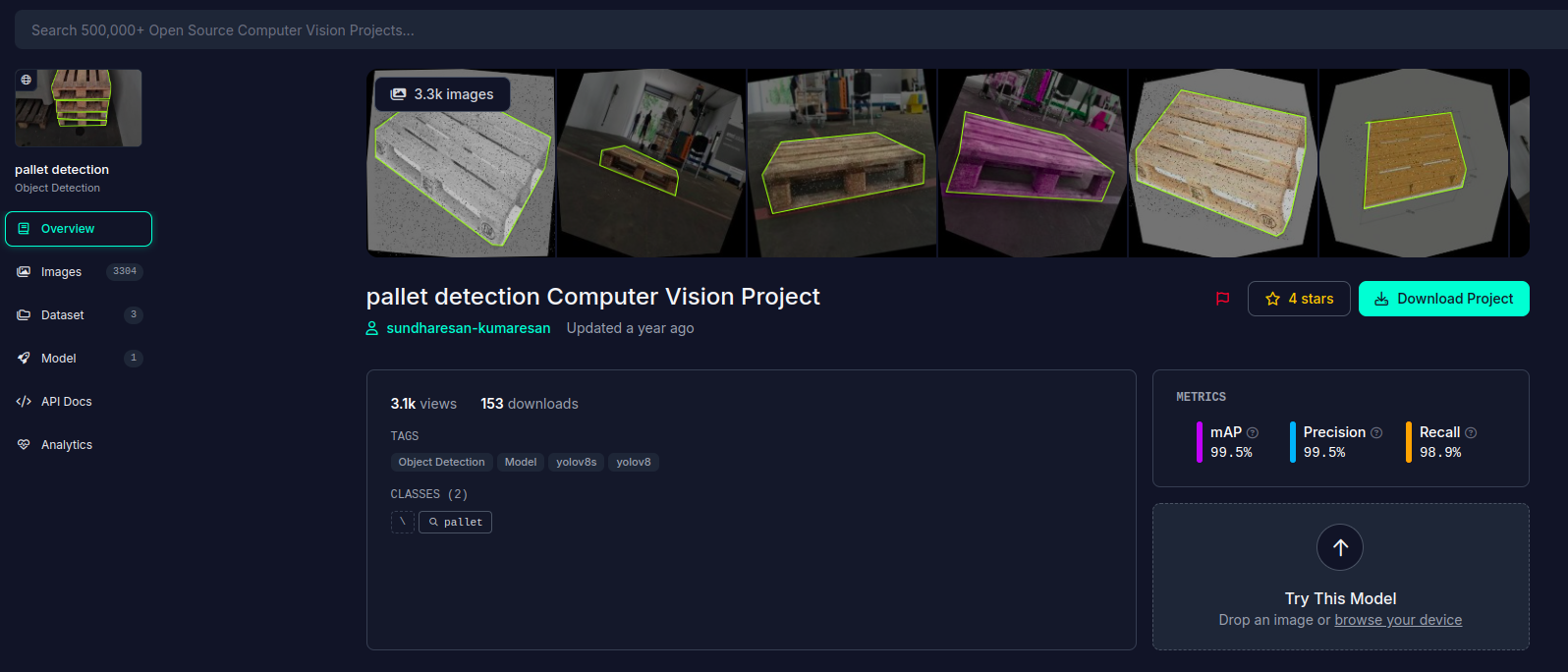
可以先去Roboflow查找是否存在成品数据集, 例如托盘类(pallet)
在这里可以上传自己的图像, 进行模型的实验, 不过这里都是通过API进行访问的, 似乎无法直接使用该模型
但是它的数据集是可以直接下载的, 因此可以作为很好的数据集来源
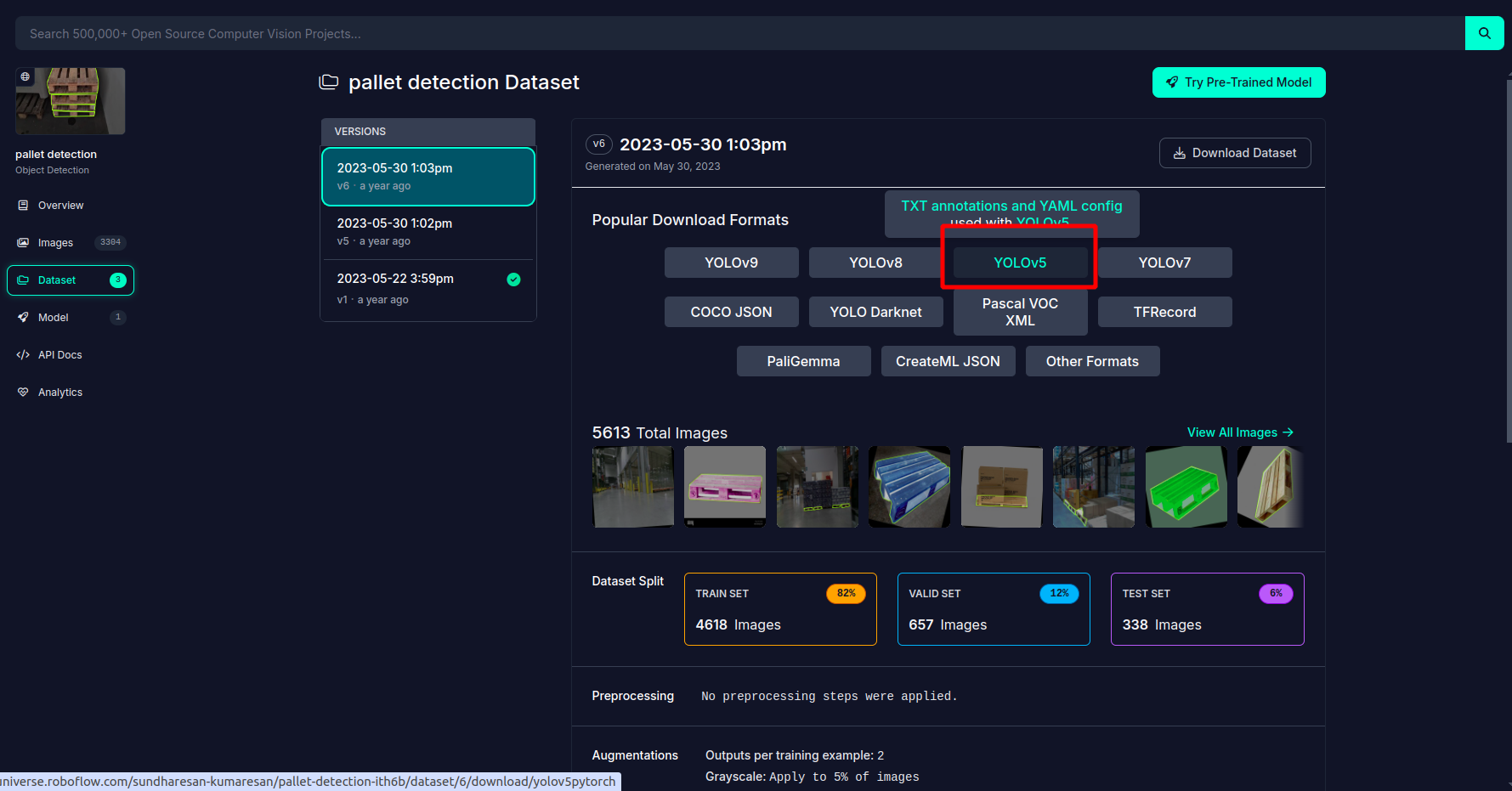
在下载数据集时, 注意选择标签的格式, 因为是yolov5, 因此需要选择yolov5支持的数据格式
自建数据集
如果对公开数据集不满意, 可以自己建立数据集进行针对性训练
下载一个标注器, 或找一个在线标注的网站(这个数据可能会被网站运营方保存并商用, 如果无所谓, 就可以选择这种方法)
以在线标注为例, 选择目标检测
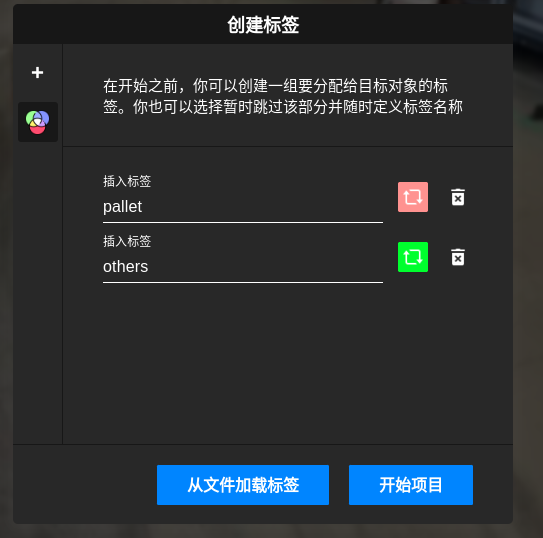
上传图片后, 需要创建标签, 例如pallet
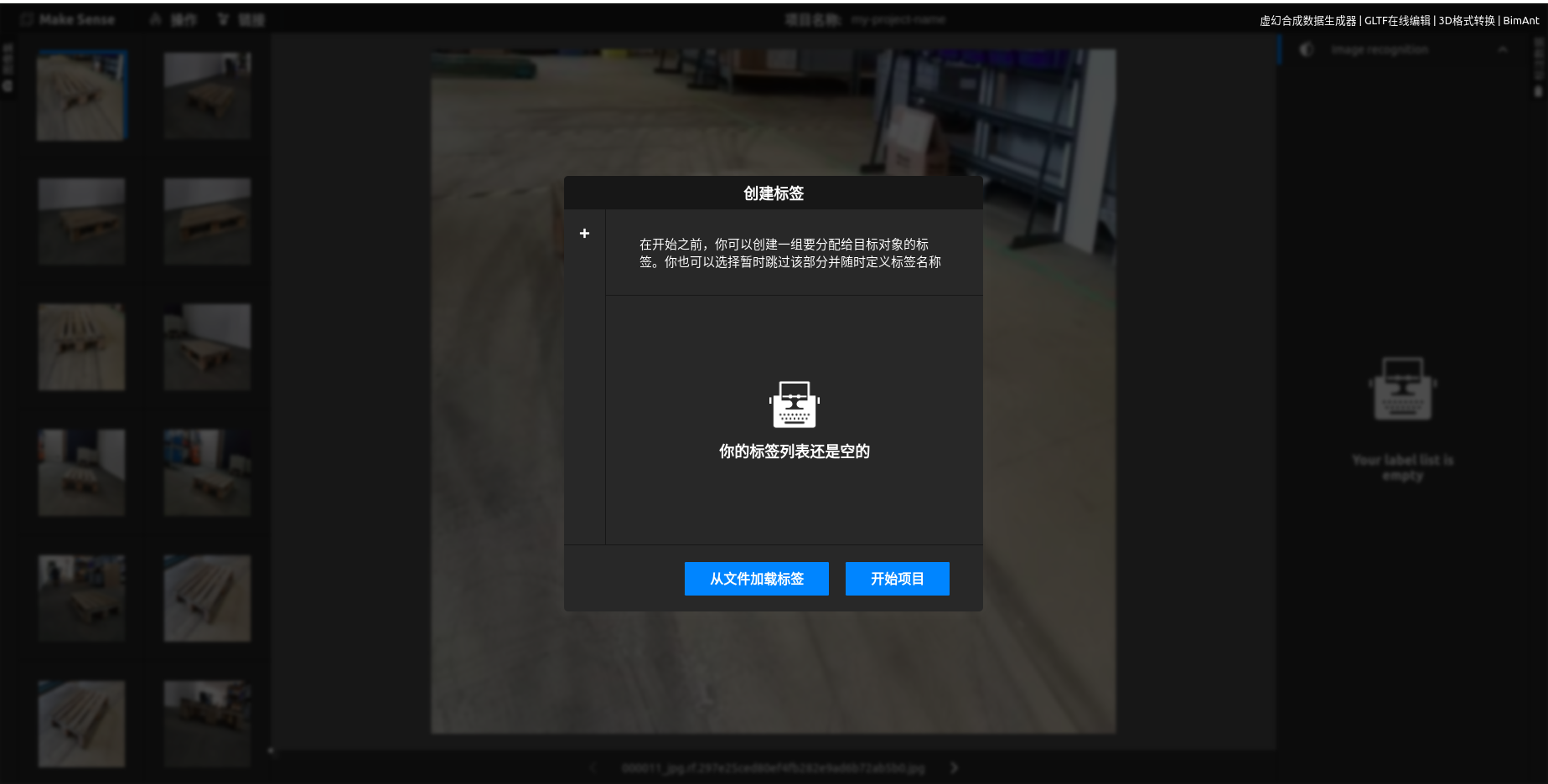
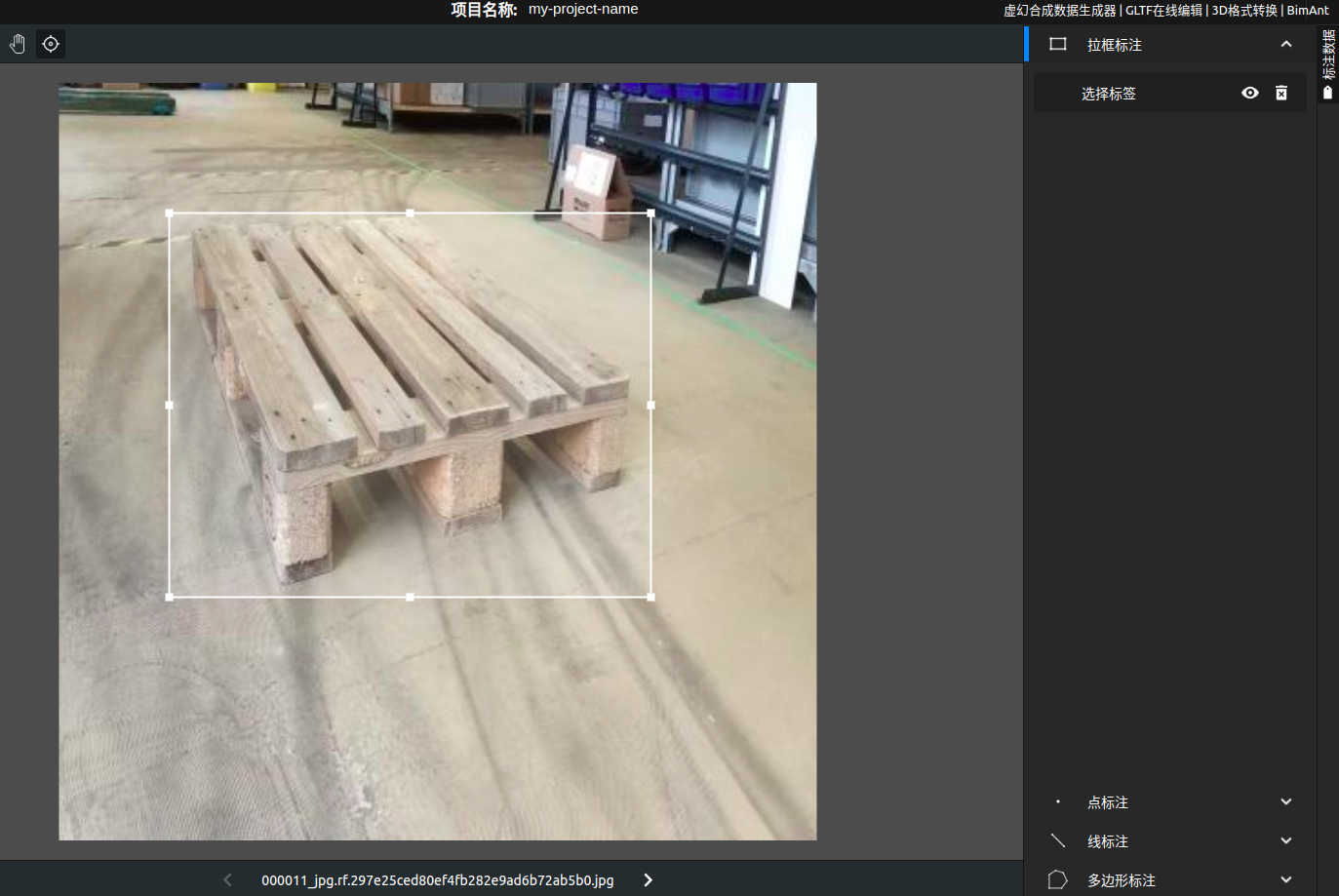
选择拉框标注(当然, 也能选其他的), 圈定范围, 选择标签, 例如pallet
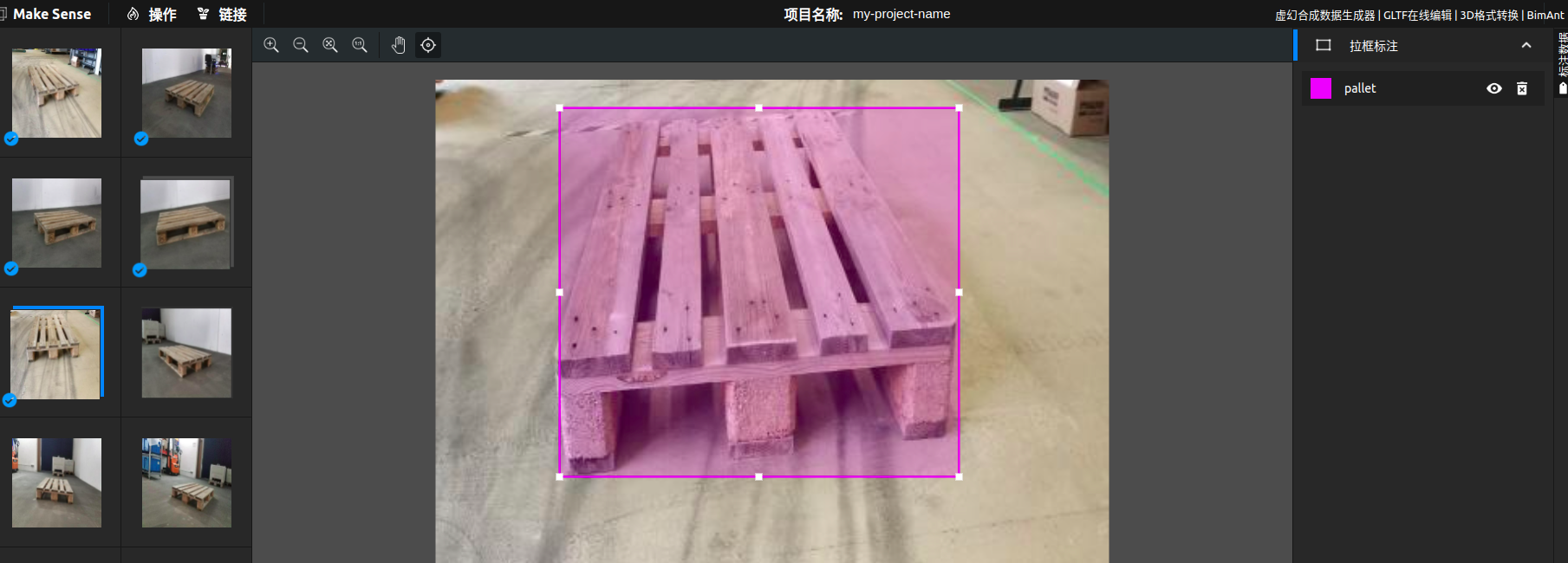
完成后, 导出, 选择yolo格式的zip压缩包
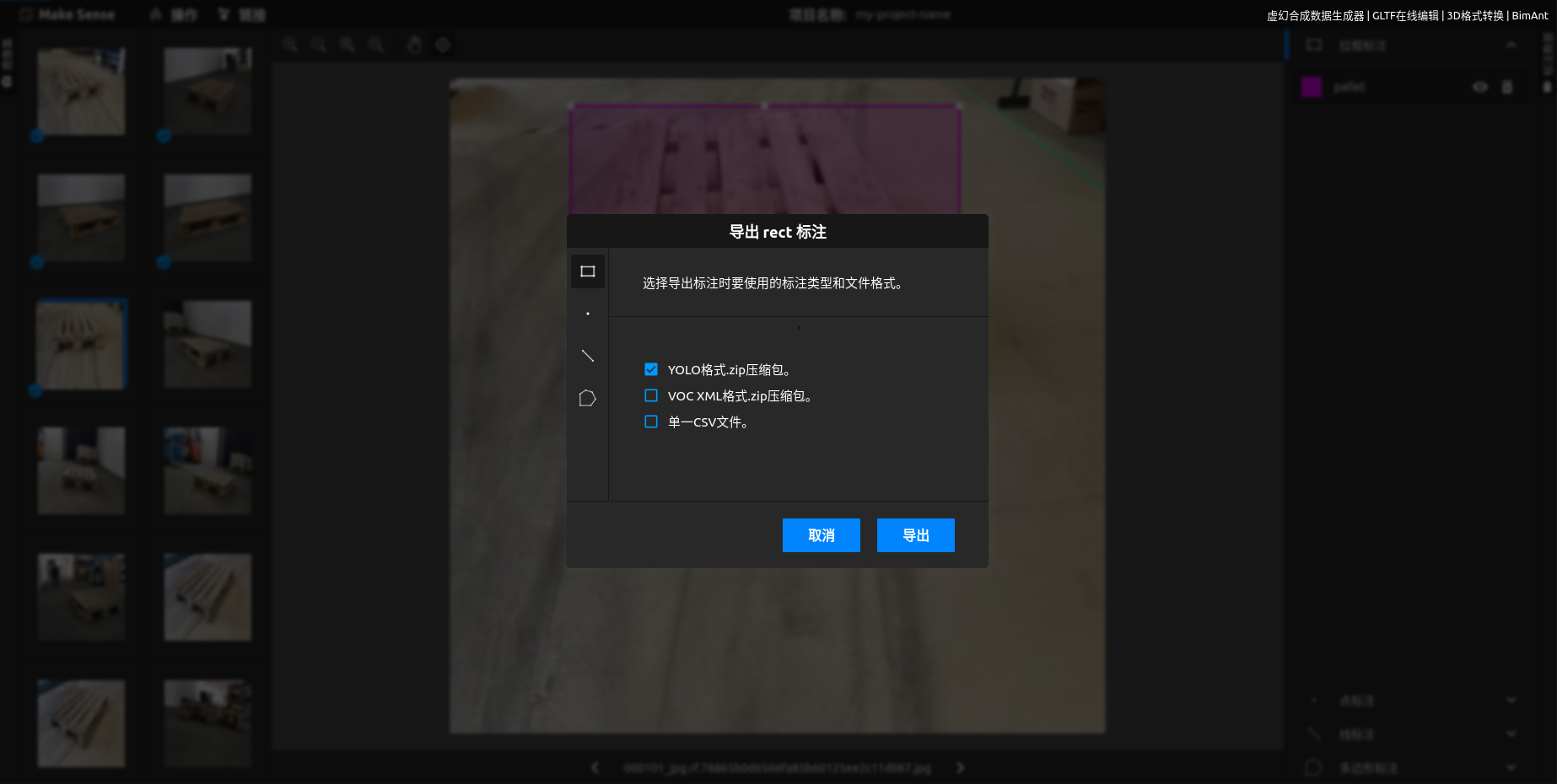
解压该压缩包就可以看到一组txt文件, 例如
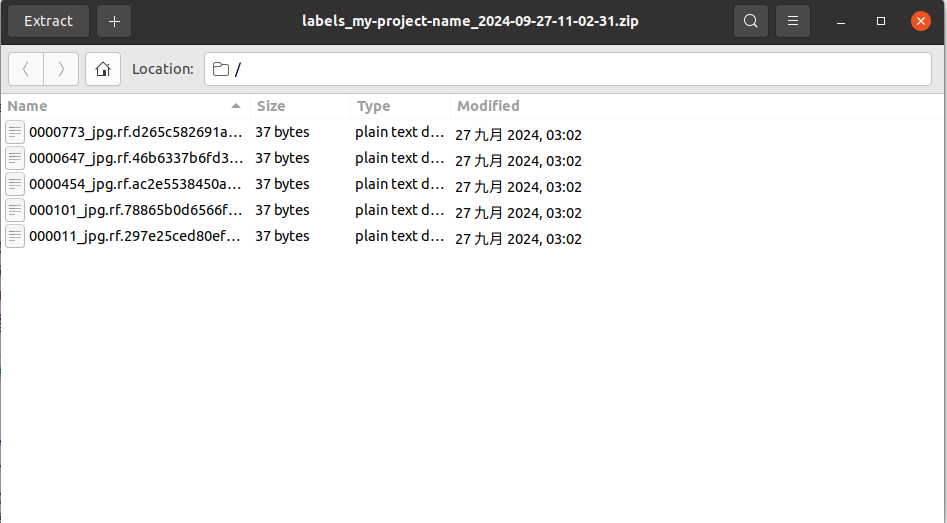
这里的文件名称与图像名称是一一对应的, 不要修改文件名, 只需要把这里的文件解压即可
里面的内容是
0 0.554698 0.515444 0.794080 0.472329
第一个指的是类型编码, 即在标注时第一个类别, 例如上述标注时的0就是pallet, 1就是others
后面4个代表的是坐标, 用的是比例制
数据集构成
dataset : 该目录为数据集总目录, 一般包含train, val两个文件夹, 里面存放训练数据以及验证数据, 因此在做数据集时, 可以将图片与标签分成两组, 例如95%的图片用作训练, 剩下的5%用于验证, 注: 需要包含标签!!!>
dataset/train: 该目录下存放的是用于训练的图片及其标签, 分别位于train/images 以及train/labels目录下, 这里的图片名称需要和标签名称一致, 只是后缀一个是.jpg一个是.txt
dataset/val: 与train类似
dataset/data.yaml: 这是一个yaml文件, 用于指定上述数据集的路径, 在yolo的train.py中需要传入该文件, 后面会提到该参数
train: /home/smile/MLPallet/dataset/train/images
val: /home/smile/MLPallet/dataset/valid/images
# 这里需要对分类的信息给出描述, 例如一共有几种类型, 需要按顺序填写, 例如0是pallet, 1是others, 按实际情况进行修改
nc: 1
names: ['pallet']
# 添加 'path' 字段,指向数据集的根目录
path: /home/smile/MLPallet/dataset
开始训练
–data: 指定数据集的 YAML 文件,定义训练和验证集路径及类别, 这里的yaml文件就是上面自己定义的dataset/data.yaml
- 示例:
--data data/coco128.yaml
–weights: 预训练模型的路径,可以是自定义权重文件
- 示例:
--weights yolov5s.pt
–epochs: 训练的总轮数
多多益善? 最终收敛的时候不一定会完全跑完所有轮次, 建议拉大一点
- 示例:
--epochs 50
–batch-size: 每次训练的样本数,默认为 16
这个参数的含义就是, 在训练时会把n张图片拼接到一张图片上进行训练, 加快训练过程, 但是这也会导致内存需求激增, 在3060上跑64会中断
- 示例:
--batch-size 32
–img-size: 输入图像的大小,支持多种尺寸
- 示例:
--img-size 640
注: 以下操作均在虚拟环境(yolo)中进行
可以有两种方式, 一种是在之前预训练模型的基础上进行微调, 另一种是直接从零开始训练一个新的模型,
一般而言第二种更精确, 但是需要更大的数据量以及更多的训练轮次
# 根据yolov5s.pt进行微调
python train.py --data /home/smile/MachineLearning/dataset/data.yaml --img-size 640 --batch-size 32 --epochs 500 --weights yolov5s.pt
# 从零开始训练
python train.py --data /home/smile/MachineLearning/dataset/data.yaml --img-size 640 --batch-size 32 --epochs 500 --weights ''
后面就是等待训练完成即可, 也可以在每完成一轮后, 检查验证结果, 看是否正在收敛
这就是训练完成后的结果, 可以通过mAP50来看目前准确度

使用自己的模型进行推理
在完成训练后, 可以在/path/to/yolov5/runs/train/expX目录下找到本次训练时的一些数据, 包含损失函数等图片, 以及在训练及验证时的剪影(jpg)
下图就是batch size为16时的剪影, 可以看到是16张图片被拼接到一起进行检测的

模型保存在/path/to/yolov5/runs/train/expX/weights/
这里会有一个best.pt以及一个last.pt这两个都是训练的结果, best.pt是针对last.pt优化后的权重, last.pt是最终训练好的权重, 一般情况下会采用best.pt
检测:
python detect.py --weights /path/to/best.pt --source ./images/image.jpg