端侧Agent系列 | 端侧AI Agent任务拆解大师如何助力AI手机?(详解版)
-
引言
-
简介
-
Octo-planner
-
规划和执行Agent框架
-
规划数据集
-
基准设计
-
-
实验设计
-
结果
-
全量微调与LoRA
-
多LoRA训练与合并
-
不同基础模型的全量微调
-
不同数据集大小的全量微调
-
-
总结
-
实战
-
英文
-
中文示例1:
-
中文示例2:
-
0. 引言
人生到处知何似,应似飞鸿踏雪泥。

小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖沙茶面的小男孩。延续之前端侧大模型系列:
端侧大模型系列 | 端侧Agent合纵连横AI江湖,破局端侧大模型之困!Octopus v4
端侧大模型系列 | 不到10亿参数的端侧Agent竟媲美GPT-4V,AI手机端倪初现?且看Octopus v3
端侧大模型系列 | 斯坦福手机端侧Agent大模型:Octopus v2
端侧大模型系列 | 陈天奇MLC-LLM重磅升级:基于机器学习编译的通用LLM部署引擎
端侧大模型系列 | 如何将千问大模型Qwen部署到手机上?环境安装及其配置(上篇)
端侧大模型系列 | 如何将千问大模型Qwen部署到手机上?实战演示(下篇)
端侧大模型系列 | PowerInfer-2助力AI手机端侧部署47B大模型
订阅点这里:端侧大模型系列。
今天这篇小作文主要介绍端侧Agent智能体中任务规划和拆解,从而实现复杂场景下多指令任务的执行。随着人工智能技术的快速发展,AI Agent(智能体)在各个领域的应用越来越广泛。然而,目前大多数AI Agent依赖于大型语言模型(LLM),这些模型通常需要通过联网的方式在云端消耗大量的计算资源,这限制了其在边缘设备上的应用。为了解决这一问题,研究人员提出了Octo-planner,这是一个专为边缘设备而设计的用于规划任务的AI Agent框架。更多大模型相关,如模型解读、模型微调、模型部署、推理加速等,可以留意本微信公众号《小窗幽记机器学习》
小窗幽记机器学习
记录机器学习过程中的点点滴滴和坑坑洼洼
公众号
1. 简介
AI智能体由于其能够自主决策并执行任务并解决诸多问题,从而在各领域变得越发重要。为了有效运作AI Agent,NexaAI的研发人员提出了一种设备端 规划-执行框架 ,将规划和执行分为两个部分:Octo-planner和Octopus执行智能体。Octo-planner将任务分解为子步骤,然后由Octopus模型(指之前提出的Octopus v1、v2、v3、v4模型)执行。为优化资源受限设备上的运行性能,官方使用模型微调而非上下文学习,从而降低计算成本和能耗,提高响应速度。至于数据,研究人员使用GPT-4生成多样化的规划查询和响应,然后对这些数据进行验证以确保质量。然后使用这个精心策划的数据集对Phi-3 Mini模型进行微调, 最终在领域内测试取得97%的成功率。为应对多领域规划,官方还开发了多LoRA训练方法,合并不同函数子集上的LoRA权重,以灵活处理复杂查询。

模型下载:https://huggingface.co/NexaAIDev/octopus-planning
论文地址:https://arxiv.org/abs/2406.18082
2. Octo-planner
这一章节介绍端侧设备上的规划-执行智能体框架:Octo-planner。首先,介绍集成规划和执行的Agent,以高效解决问题。接着,详细介绍规划Agent的数据集设计和训练过程,包括对广泛功能函数的支持和附加函数集的即插即用能力。最后,概述了用于评估Agent性能的基准数据集。
规划和执行Agent框架
Octo-planner将规划和执行过程分成两个组件,这与一般的Agent框架不同。这种分离提高了模块化,并允许对每个组件进行专门优化。Octo-planner框架的运作如下:
规划阶段:对于给定的用户查询 ,规划模型 将任务分解为一系列子步骤。形式化地表示为:
其中 是可用函数描述的集合(即待调用函数集合), 是第 个执行步骤。在指令微调过程中, 内化 。
执行阶段:对于执行序列中的每一步,使用执行模型 。在第 步,给定当前状态的观察 ,执行模型执行以下操作:
,()
其中 和 被传递到下一步以继续执行。这一迭代过程确保任务子步骤的连贯推进。
对于执行模型,使用 Octopus 系列模型(包括 v1、v2、v3、v4),其专为端侧设备上的函数调用而设计。图 2 展示了Octo-planner规划-执行框架与单模型方法在大型语言模型(LLM)智能体中的区别。
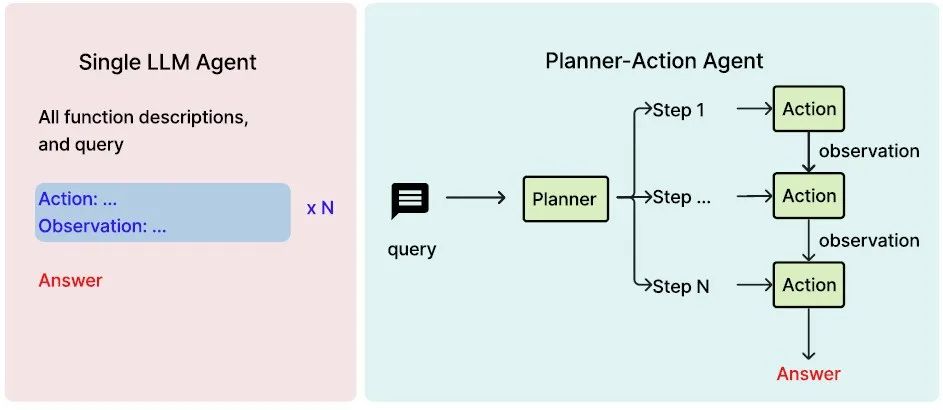
Figure 2:单 LLM Agent和规划-执行Agent框架的比较。(左)单 LLM Agent:一个统一模型同时执行任务规划和执行。(右)规划-执行Agent:一个专门的规划模型将任务分解为子任务,而一个独立的执行模型顺序执行每个子任务。
Octo-planner框架的模块化设计有如下优点:
-
专业化:规划和执行的分离,使得可以对每个模型进行专门优化,以提高复杂任务中的性能。
-
可扩展性:规划和执行能力的独立扩展可有效适应不同复杂程度的任务。
-
可解释性:不同阶段的明确分离,提高了决策过程的透明度。
-
适应性:更容易将领域特定知识或约束集成到任一阶段,而无需对整个系统进行更改。
规划数据集
Octo-planner框架使用Octopus模型作为执行模型,只需训练规划器Agent。使用以下数据集格式对规划器Agent进行微调:
<|user|>{user’s query}<|end|>
<|assistant|>{query1}<nexa_split>{query2}<nexa_split>...<nexa_split>{queryn}.<|end|>
像<|user|>和<|assistant|>这种特殊token仅用于聊天模型(即chat版模型)的预训练,其他情况则是非必需的。n的取值设置为1~5,这是因为研究人员发现,大多数移动应用任务由<=5个步骤组成。数据集生成和整理过程包括:
-
数据集收集:给定可用函数,使用大语言模型(这里指GPT-4)生成可由这些函数回答的多样化查询。这个过程增加模型的温度设置以确保查询的多样性。然后以指定的数据集格式生成响应。需要说明的是,虽然在生成过程中使用了函数描述,但它们不包含在最终数据集中。相反,规划器模型在训练过程中内化这些函数信息。
-
数据验证:使用相同的语言模型作为验证工具来评估查询-响应对的正确性。尽管初始生成过程中存在一些错误,但研究人员发现该模型能区分生成的内容是否有效,使得最终能够过滤掉不正确的输出并维持数据集质量。
不同子步骤数量的示例数据如下所示:
One-step example:
query: Tell me today’s stock market.
response: Search for today’s stock market news and latest updates<|end|>
Two-step example:
query: Find and email me Jensen Huang’s news in English.
response: Find articles about Jensen Huang in English<nexa_split> Email the first article
found to myself<|end|>
Three-step example:
query: Find and increase the screen brightness by 20% to better view the quarterly report
document before connecting to the office printer via Bluetooth.
response: Find the quarterly report document in the system<nexa_split> Increase screen
brightness by 20% to improve visibility<nexa_split> Connect to the office printer via
Bluetooth to print the quarterly report<|end|>
Four-step example:
query: Find and email the project proposal document to project.manager@company.com,
then look up the submission deadline and schedule it in my calendar with a reminder.
response: Locate the project proposal document<nexa_split> Send the project proposal via
email to the project manager at project.manager@company.com<nexa_split> Find the project
proposal submission deadline<nexa_split> Schedule a calendar event for the project proposal
submission deadline with a reminder<|end|>
Five-step example:
query: I have a meeting tomorrow morning, please find my presentation then connect to the
conference room projector via Bluetooth. After that, increase the screen brightness then take
a screenshot of the final summary slide and email it to all participants.
response: Find the presentation for the meeting tomorrow<nexa_split> Connect to
the conference room projector via Bluetooth<nexa_split> Increase screen brightness by
20%<nexa_split> Take a screenshot of the final summary slide<nexa_split> Email the screenshot
to all meeting participants<|end|>
有关数据集收集的可视化,请参见Figure 3。示例函数描述在附录7.1中。
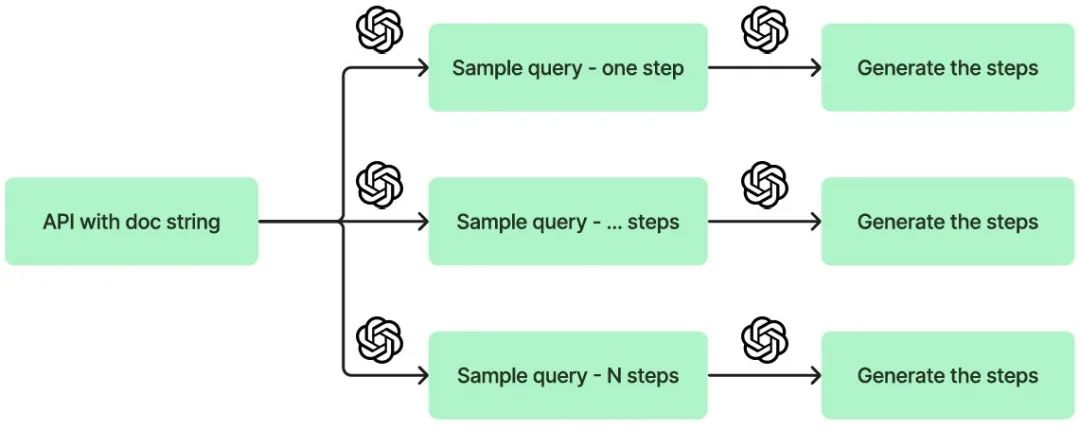
Figure 3:规划器模型训练数据的收集过程。首先,确定所需的步骤数,在当前情况下将N设置为1到5。接下来,为每个查询生成相应的查询和步骤。
基准设计
Octo-planner使用的评估依赖于精心构建的测试数据集。该数据集旨在代表真实世界规划的复杂性,因此采用多阶段方法,整合了自动生成、专家验证和实证测试。
该过程先使用GPT-4自动生成包含1,000个数据点的初始数据集。这些数据点随后经过严格的质量检查过程,以确保其完整性和相关性。质量评估标准如下:
-
每个步骤必须对应一个现有函数;
-
步骤的顺序必须正确。
为确保评估的可靠性,加入了额外的手动验证阶段。这个阶段涉及选择一部分示例进行端到端模型执行,从而验证结果的准确性。
对于Octo-planner规划模型的评估,具体是使用GPT-4作为判断生成计划正确性的标准。这个选择基于经验观察:GPT-4在特定用例中具有高度熟练度。
3. 实验设计
如何设计实验评估Octo-planner在设备端AI Agent 规划中的性能?为了在资源受限的设备上部署高效、准确的规划模型的最佳配置,同时保持对新领域和函数的适应性。设计的评估实验重点关注四个方面:
-
全量微调与LoRA之间的性能和效率权衡。
-
多LoRA在同时处理不同函数集时的准确性。
-
不同基础模型及其尺寸的性能比较。
-
数据集大小对准确性的影响,范围从100到1000个训练样本。
在自定义数据集(是否会公开发布子集?)上进行监督微调,使用Phi-3 Mini和其他几个模型作为基础模型。训练包括全量微调和LoRA技术。对于所有实验,将数据集大小设置为函数数量的800倍,并在NVIDIA A100 GPU上进行微调。在两种技术中使用的超参数:学习率为5 × 10^-6,批量大小为4,预热比为0.2,进行2个epoch。对于LoRA,将target_modules设置为所有线性模块。
4. 结果
全量微调与LoRA
表1详细比较了Octo-planner规划模型使用全量微调和LoRA方法的配置及其结果。实验显示这些方法的性能存在显著差异。全量微调实现了最高98.1%的准确率,表现出卓越的性能。相比之下,LoRA的性能取决于rank大小。当rank为64且alpha为256时,LoRA对应的准确率为85.1%,而减少到rank 16和alpha 32时准确率下降到72.9%。这些结果突显了使用LoRA时模型性能与计算效率之间的权衡。尽管全量微调提供了更好的准确性,LoRA则提供了一种更具资源效率的替代方案,其性能因rank配置而异。

多LoRA训练与合并
虽然基于LoRA的训练对特定函数集有效,但现实应用通常需要处理新的或扩展的函数集。为应对这一挑战,Octo-planner官方提出合并多个LoRA权重,每个权重在不同的功能子集上训练,使用相同的基础模型。此方法创建了一个复合模型,将来自各种函数集的知识结合在一起,为资源受限环境中的复杂多领域查询提供了一种可扩展的解决方案。
为了评估这一方法,构建基准数据集。构建方法:随机选择每个LoRA领域的函数,以相同概率将它们组合成工作流来;使用GPT-4生成的查询和计划。例如,在测试两个合并的LoRA时,查询可能涉及Android函数、电子商务领域的函数或两者兼有,概率相等。
下面的代码块显示了基准数据集中的示例查询以及来自多LoRA合并模型的相应推断结果:
Android functions only:
query: Find the quarterly report for Q3 and print it for the upcoming board meeting.
response: Locate the quarterly report document for Q3<|nexa_split|>Print the located
quarterly report document<|end|>
E-commerce functions only:
query: Find ergonomic office chairs and then buy the selected one using my default shipping
address and credit card
response: Search for ergonomic office chairs<nexa_split>Purchase the selected ergonomic
office chair using the default shipping address and credit card<|end|>
Android and E-commerce functions:
query: Find ergonomic office chair list doc and print it for my shopping
response: Search for ergonomic office chair list doc<nexa_split>Print the ergonomic office
chair list doc <|end|>
表2展示了多LoRA合并技术的性能结果。每个单独的LoRA都使用一致的超参数进行训练:rank 64,lora_alpha 256,target_modules设置为"all-linear"。在单领域的Android函数集上,LoRA取得了85.1%的准确率。当合并来自两个领域(Android和电子商务)的LoRA时,准确率略微下降到82.2%。进一步合并则导致更低的准确率:三个领域(添加视频流)为78.9%,四个领域(添加旅行)为69.7%。这些结果揭示了随着整合更多函数集,准确率逐步下降的趋势,特别是在添加第三个领域后,下降幅度更大。

不同基础模型的全量微调
表3展示了不同基础模型在全量微调后在基准评测集上的准确率。Google Gemma 2b的准确率为85.6%,而更大的Gemma 7b表现十分优异,达到了99.7%。微软的Phi-3也表现强劲,达到了98.1%。这些结果表明,Octo-planner框架能够很好地适应各种设备端的大型语言模型(LLM),并且较大的模型通常能获得更高的准确率。

不同数据集大小的全量微调
默认训练数据集包含1000个数据点,均匀分布在1至5步的序列中(每种200个),以代表不同复杂程度的任务。官方还研究了数据集大小对模型性能的影响,以优化函数集的集成效率,从而应对合成数据生成成本。表4显示了在不同训练数据集大小下,基准评测集的准确率:
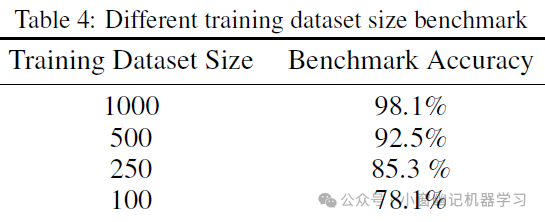
结果显示数据集大小与准确率之间存在明显的相关性。完整的1000个数据集达到了98.1%的准确率,而减少到500个数据点时准确率下降到92.5%。进一步减少到250和100个数据点时,准确率分别为85.3%和78.1%。这些发现表明,为了获得最佳性能,建议训练数据集应超过1000。
5. 总结
本文介绍了Octo-planner,这是一种设计用于与Octopus V2等执行类Agent协同工作的设备端规划类Agent。通过将规划和执行分开,提高了专业化和适应性。使用Octo-planner方法对Phi-3 Mini(一个38亿参数的LLM)进行了微调,使其能够作为规划类Agent在边缘设备上本地运行,并在领域内测试取得97%的成功率。通过Octo-planner方式,降低了计算需求,改善了延迟和电池寿命,并实施了多LoRA技术,以在不进行完全重新训练的情况下扩展模型能力。
Octo-planner有助于解决AI部署中的数据隐私、延迟和离线功能等问题。这代表着向个人设备提供实用且复杂的AI智能体(Agent)的进步。另外,官方开源了模型权重,以推动设备端AI的创新,促进开发高效、尊重隐私的应用程序,这些应用程序在不影响性能或安全的情况下改善日常生活。
6. 实战
英文
question = "Find my presentation for tomorrow's meeting, connect to the conference room projector via Bluetooth, increase the screen brightness, take a screenshot of the final summary slide, and email it to all participants"
输出结果
You are not running the flash-attention implementation, expect numerical differences.
=== inference result ===
<s><|user|> Find my presentation for tomorrow's meeting, connect to the conference room projector via Bluetooth, increase the screen brightness, take a screenshot of the final summary slide, and email it to all participants<|end|><|assistant|> Locate the presentation file for the upcoming meeting<nexa_split>Connect to the conference room projector via Bluetooth<nexa_split>Increase the screen brightness for better visibility<nexa_split>Take a screenshot of the final summary slide of the presentation<nexa_split>Email the screenshot to all meeting participants with a brief note about the presentation content<|end|>
中文示例1:
question = "请找到我明天会议的演示文稿,通过蓝牙连接会议室的投影仪,增加屏幕亮度,截取最后总结幻灯片的截图,并将其发送给所有参会者。"
输出结果
=== inference result ===
<s><|user|> 请找到我明天会议的演示文稿,通过蓝牙连接会议室的投影仪,增加屏幕亮度,截取最后总结幻灯片的截图,并将其发送给所有参会者。<|end|><|assistant|> 找到会议的演示文稿<nexa_split>连接会议室的投影仪<nexa_split>增加投影仪的屏幕亮度<nexa_split>截取演示文稿的最后总结幻灯片的截图<nexa_split>发送截图给所有参会者<|end|>
中文示例2:
question = """
帮我下午5点预定一个5个人的会议,并添加到日历,主题是"如何实现使用LLM辅助编程",然后在飞书AI吃瓜划水群在群里通知大家会议时间,并发一下会议链接。另外,再帮我定下明天上午10点的会议,并设置提前30分钟提醒。最后设置明天早上8点半的闹钟,确保我能准时起床准备。
"""
输出结果:
=== inference result ===
<s><|user|> 帮我下午5点预定一个5个人的会议,并添加到日历,主题是"如何实现使用LLM辅助编程",然后在飞书AI吃瓜划水群在群里通知大家会议时间,并发一下会议链接。另外,再帮我定下明天上午10点的会议,并设置提前30分钟提醒。最后设置明天早上8点半的闹钟,确保我能准时起床准备。
<|end|><|assistant|> 1. 打开会议管理应用程序。
2. 在应用界面中找到会议的功能并创建一个新会议。
3. 设置会议时间为下午5点,并设置会议持续时间为1小时。
4. 在会议名称或标题中输入"如何实现使用LLM辅助编程"。
5. 在会议内容或描述中添加必要的信息。
6. 在会议的设置中选择添加到日历的选项,并确保会议在日历上显示。
7. 在会议的设置中输入会议链接或发送链接。
8. 在会议的设置中输入邮箱或电话号码,以便在会议结束后通知大家。
9. 在应用程序的其他功能中找到提醒功能,并设置一个提前30分钟的提醒,以便明天上午10点的会议。
10. 在提醒功能中设置一个早晨的闹钟,设置时间为8点半,以确保会议的准时起床。<|end|>
#AI手机 #AIOS #端侧大模型 #手机端侧部署大模型 #任务规划 #智能体 #Agent