强化学习——基本概念

- state
例如上图就是location,就是网格的位置为state

- action
就是可采取的行动,这里就是可以move的位置

- state transition
就是状态采取action后的state
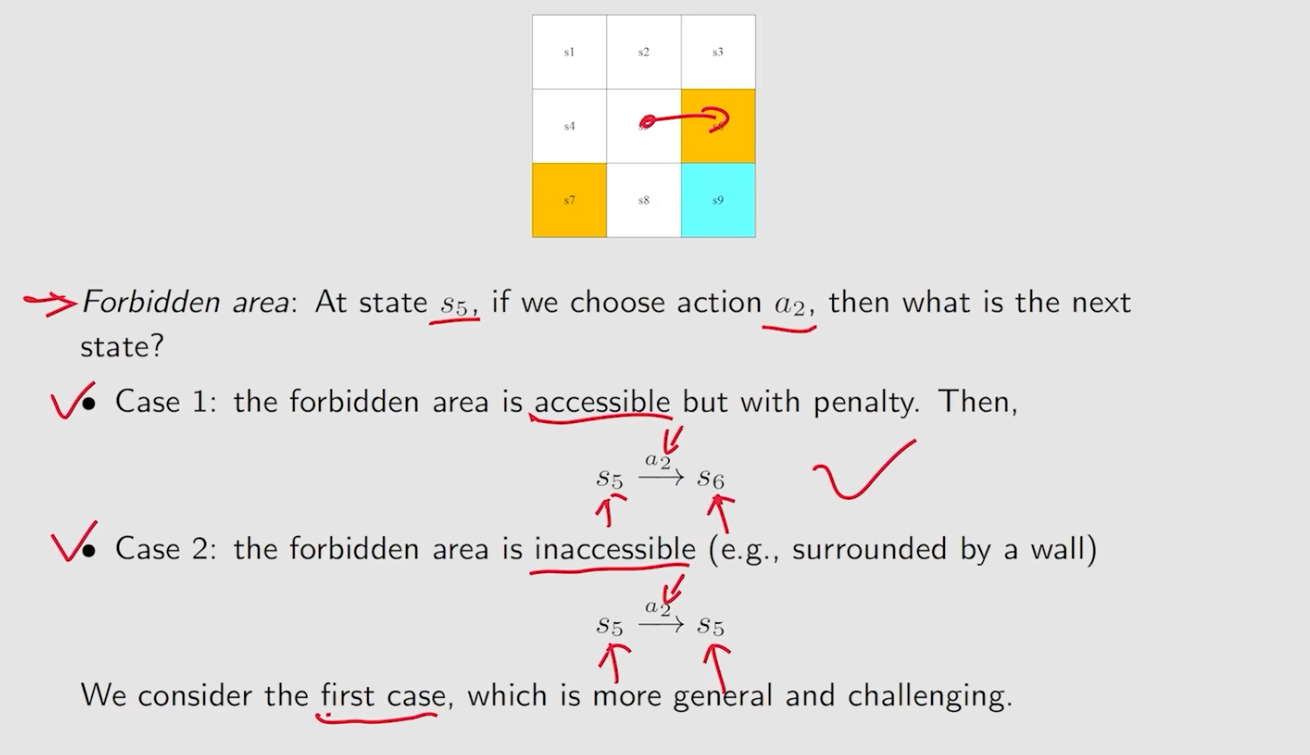
- forbidden area考虑两种,一种是可以进去,但是会有惩罚,第二种不可以。课程采用的第一种

- Policy 告诉agent在每个state应该采取什么action
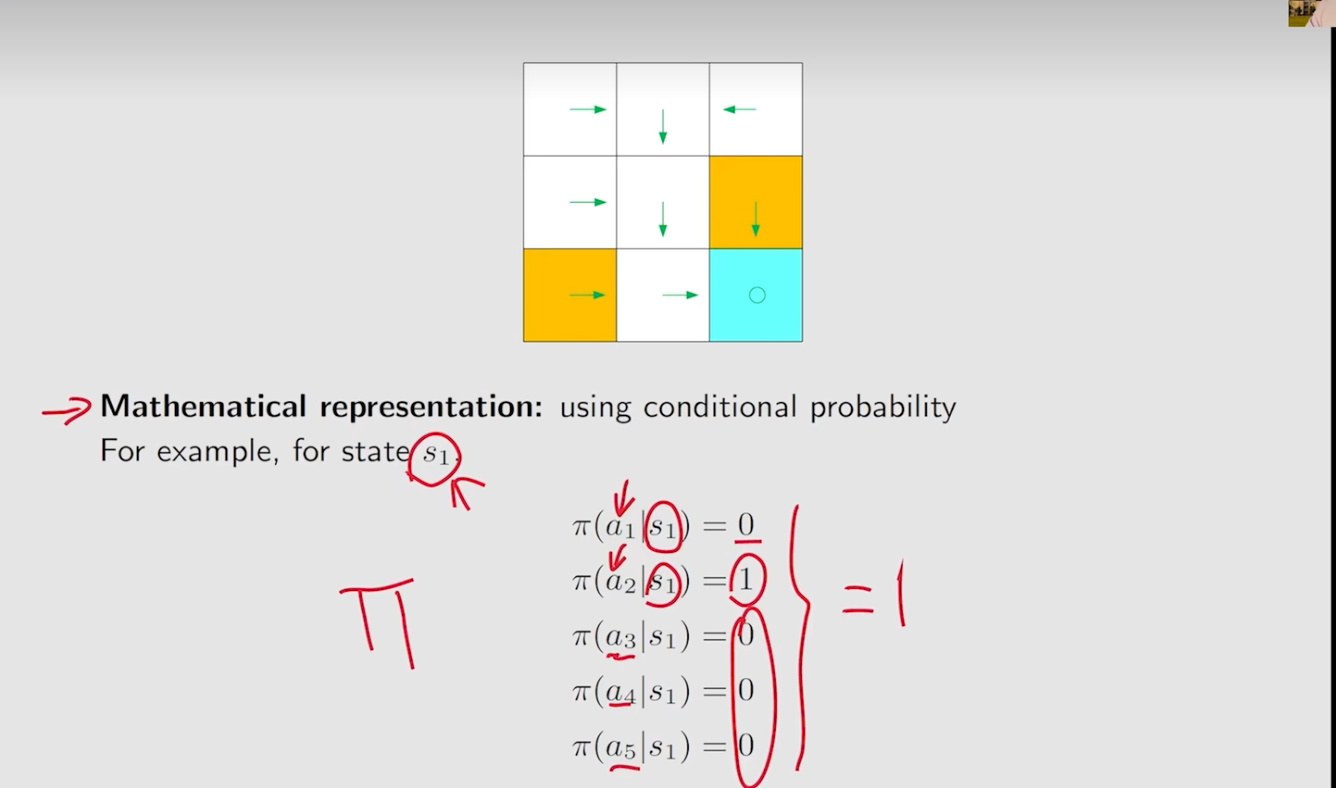
- 比如用Π表示策略,在状态S1下采取不同的action的概率。其概率之和为1

- reward
当这个数是正数,代表这个行为是鼓励的,如果是负数,代表为惩罚,这个行为不鼓励。(这个正负数是相对的,就是数学概念,比如也可以用正数代表惩罚)
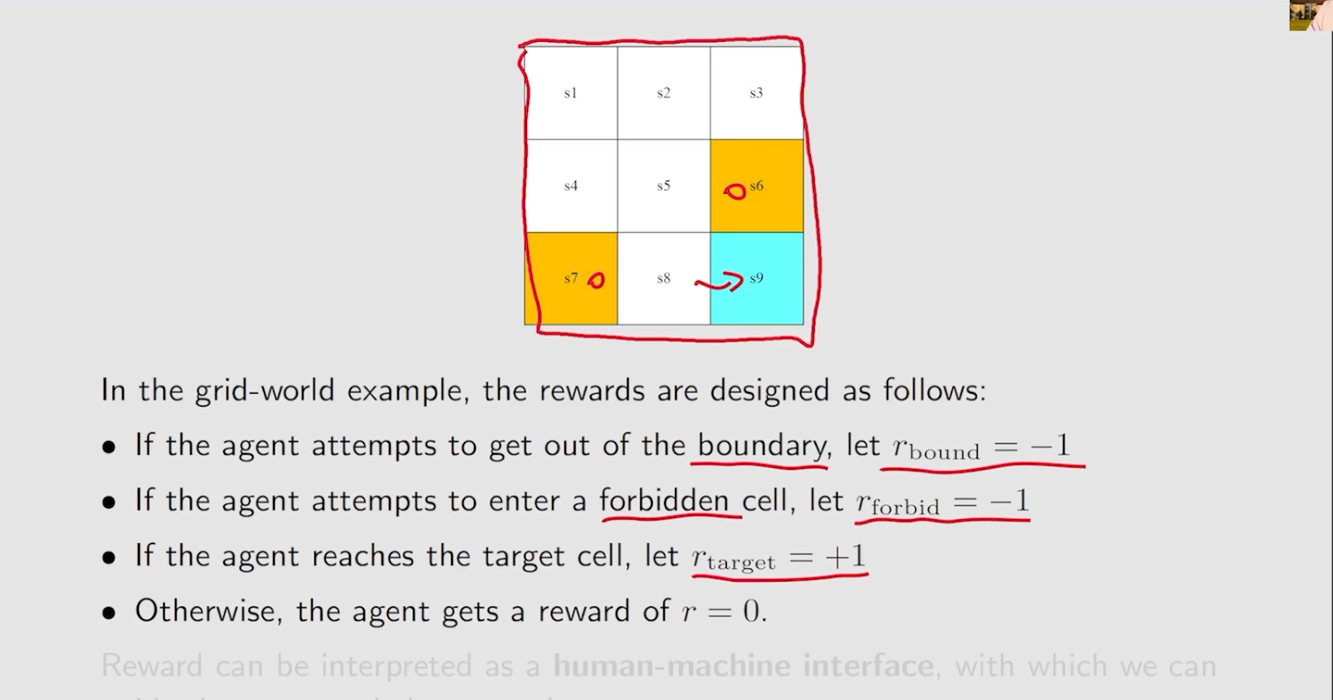

- agent到达不同的位置的奖励分数,或者在不同的状态下采取对应的行动获得的得分

- trajectory
包含了状态,action, reward。每个trajectory需要有return

- 数学上定义一个policy比较好的方式,就是return的值比较好

- discounted return
如上图,每次进入到target都会得一分,然后分数就会无穷大了

- 使用discounted rate
每一个reward都设置一个,此时这个无穷值就变成了一个数,并且,如果
接近0,证明后面的reward的影响衰减快,主要依赖于前面的reward,等于1,则衰减的较慢。
减少会更加近视,注重前面的reward,增加会更加远视

- Episode
通常是有限步,就是有限步后停止了
MDP

- 集合化
-
- 状态集合S
- 行为集合A(s)
- 回报集合R(s,a)
- 概率分布
-
- 状态过度概率:在当前的状态s采取行动a,到达s'的概率
- 回报过度概率:在当前的状态s采取行动a,获得分数r的概率
- policy
- 与历史无关
得到状态St+1只与t的状态和行为有关
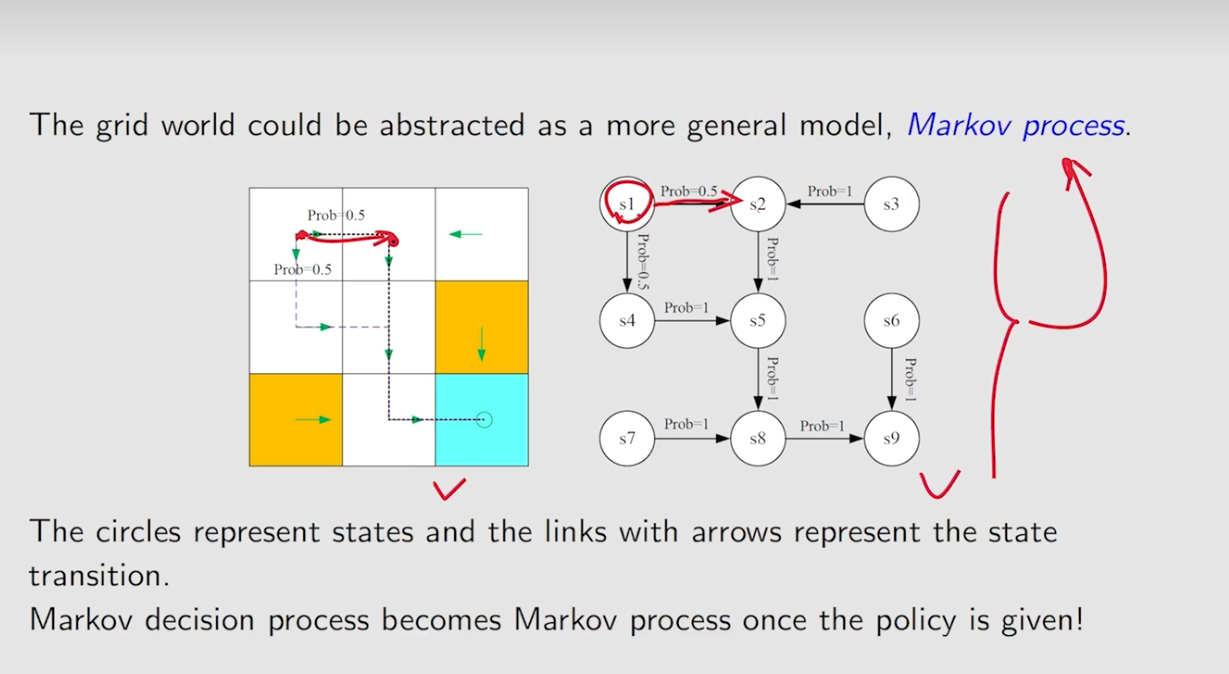
decision process给出policy后变为markov process