PViT-AIR:一种用于乳腺组织图像配准的深度学习模型|顶刊精析·24-10-10
小罗碎碎念
今日顶刊:Med Image Anal
今天分享的这篇文章于2024-09-30在线发表,介绍了一种名为PViT-AIR的新方法,它是一个基于深度学习的图像配准流程,用于将乳腺组织的X射线(Faxitron)图像与相应的组织切片的组织病理学图像进行仿射配准。该方法结合了卷积神经网络和视觉变换器(Vision Transformers),能够同时捕获整个组织宏观切片及其片段的局部和全局信息。这种方法通过一种基于拼图的机制实现图像片段的同时配准和拼接。

一作&通讯
| 姓名 | 单位 |
|---|---|
| Negar Golestani | 斯坦福大学放射科 |
| Mirabela Rusu | 斯坦福大学放射科、泌尿科、生物医学数据科学系 |
一、引言
1-1:动机
乳腺癌是全球公共卫生的重大关注点,也是女性最常见的诊断癌症,导致了显著的患者病残和死亡(American Cancer Society, 2023)。研究表明,大约八分之一的女性在其一生中将会发展成侵袭性乳腺癌(Breast Cancer, 2023),预计2022年将有287,850例新发病例和43,250例女性死亡(Giaquinto et al., 2022)。
通常,乳腺癌的诊断采用核心针穿刺活检,一旦确诊,将根据肿瘤病理考虑不同的治疗方案(National Breast Cancer Foundation, 2022)。其中一种治疗方案是手术结合术前系统性治疗(新辅助治疗),这已被证明可以改善预后,特别是在HER2阳性、三阴性(ER/PR/HER2阴性)和/或淋巴结阳性疾病的情况下(Britt et al., 2020)。
手术后,切除的标本需进行病理检查,以确定肿瘤的大小、分级、分期和残余癌的边缘状态。这些信息用于指导后续的治疗决策,包括是否需要额外的手术或系统性治疗。在很多机构,包括作者所在机构,病理处理涉及通过柜式X光(faxitron)放射影像观察切除的手术组织(肿块切除术或乳房切除术)的大体切片。
对于较大的标本,只有一小部分组织被提交进行组织学处理和显微镜检查。识别用于组织学检查的相关切片是确定残余肿瘤的存在、大小和边缘状态以及肿瘤是否显示出治疗效应的关键。这些特征对于规划下一步治疗至关重要。
手动选择适当的切片是一个耗时且资源密集的任务,严重依赖病理学家的经验和判断,可能导致潜在的变异性。经过治疗的切除组织可能不再显示出肿块的可视证据,在这种情况下,残余肿瘤可能会被遗漏,最终导致诊断不准确和治疗计划不当(Yousif et al., 2022)。
此外,准确识别癌灶的范围和位置可能很困难,尤其是在新辅助化疗后,这可能会改变肿瘤微环境,给病理图像的视觉评估带来挑战,可能导致处理延迟并需要额外的后续切片(Sha et al., 2019; Lester, 2010)。这些局限性凸显了需要一种自动化的方法来识别和选择适当的切片进行组织学检查。
在切除组织的faxitron放射影像上自动定位残余肿瘤或肿瘤床,有望提高效率和准确性,从而缩短周转时间并获得更准确的诊断(Acs et al., 2020)。然而,当前的自动化方法无法在faxitron放射影像上区分残余肿瘤和反应性间质改变,这强调了在这方面需要进一步研究。
生成标记的训练数据集对于促进精确深度学习算法的开发和训练至关重要,这些算法用于在faxitron图像上自动检测癌症。这一过程需要将癌症范围的精确映射从组织病理学图像对应到体外组织的faxitron放射影像上,使用图像配准。然而,由于faxitron图像和组织病理学图像的内容和分辨率差异,对齐这两种图像是具有挑战性的。
Faxitron图像显示整个大体切片的X光,而组织病理学图像是5 μm厚的切片,贯穿甲醛固定石蜡包埋的组织块的不同深度。这种差异使得准确图像配准变得困难,导致配准错误和数据可能的误解释(Gurcan et al., 2009)。
进一步复杂化faxitron和组织病理学图像对齐的因素包括固定和处理过程中的组织变形、两种图像类型中的伪影、组织取向的变异性以及由于对faxitron图像上采样组织的估计不准确而导致图像之间的精确对应性(Madabhushi and Lee, 2016)。
1-2:相关工作
尽管存在多种多模态技术,faxitron与组织病理学图像的配准仍存在显著的研究空白,强调了开发这两种模态配准方法的必要性(Guo et al., 2006)。
传统的迭代方法与基于深度学习的方法是可用于实现这一空间多模态图像配准的潜在技术(Bharati et al., 2022; Andrade et al., 2018; Zou et al., 2022)。传统迭代方法利用优化技术迭代最小化成本函数以确定最佳变换。然而,这些方法需要大量的计算资源,可能耗时且易陷入局部最优(Klein et al., 2009; Shen and Davatzikos, 2002; Hill et al., 2001)。
另一方面,基于深度学习的方法利用神经网络一步对齐图像,实现实时且稳健的配准(Rocco et al., 2017; Balakrishnan et al., 2019; Georgiou et al., 2020)。
深度学习在医学图像配准方面取得了显著成功,但大多数研究聚焦于监督学习方法,这需要大量带注释的数据集和专业知识(Chen et al., 2021; Fu et al., 2020; Chen et al., 2022; Haskins et al., 2020)。因此,当缺乏带真实配准标签的标记图像时,这些方法可能不适用,正如本研究提出的问题。
无监督和弱监督方法作为减轻对精确真实标签需求的替代方案而出现,显示出前景(De Vos et al., 2017, 2019; Fan et al., 2019)。尽管这些方法有可能克服监督方法的局限性,但它们在多模态图像配准中的有效性尚未得到充分研究,需要进一步探究(Chen et al., 2021; Fu et al., 2020)。
此外,由于组织病理学图像仅包含组织的采样部分,这一情况下的独特挑战进一步加剧了两种图像模态间数据可用性的不一致性,使得实现精确的多模态图像配准更为复杂。
许多现有研究在应用弹性或变形配准技术之前,将仿射变换作为初始步骤(De Vos et al., 2019; Shen et al., 2019)。这些研究大多主要关注改善变形配准,而将仿射配准视为一个简单的初步步骤,甚至完全忽略(Mok and Chung, 2022; Balakrishnan et al., 2019)。
然而,在医学成像研究中,仿射配准是一个关键步骤,其精度可以显著影响整体对齐质量。值得注意的是,作者数据中观察到的变形变化主要局限于脂肪组织,其范围相对有限。不准确的预对齐可能会损害配准精度并阻碍优化算法的收敛,导致次优解。
因此,仿射配准步骤的重要性需要彻底研究(Mok and Chung, 2022)。为解决这一问题,作者提出了一个新的基于深度学习的流程,用于配准乳腺的faxitron和组织病理学图像。
二、材料与方法
2-1:数据描述
本研究经斯坦福大学机构审查委员会批准,涉及对100名接受新辅助化疗后进行手术切除的女性的数据分析。
切除的乳腺标本经过墨水标记方向,并按照病理实验室的标准临床协议在均匀距离下进行切片。切片间的距离取决于切除组织的尺寸,从乳腺部分切除标本的3毫米到乳腺切除标本的大约1厘米不等。使用faxitron设备对大体切片进行成像,生成3440 × 3440像素的X射线放射图像,全面展现切除组织的体外结构。
根据标本大小,整个组织切除或特定兴趣区域被提交进行组织学检查。随后,获取4600 × 6000像素的数字苏木精-伊红(H&E)图像,用于组织片段,并由病理学家在相应faxitron图像上标注感兴趣的区域(Box-ROIs)。所有faxitron和组织病理学图像均为RGB格式。
此外,乳腺专科病理学家审查组织病理学H&E切片,并标注侵袭性乳腺癌(IBC)和导管原位癌(DCIS)的范围。需要注意的是,一些大体切片仅对部分区域进行了组织学分析,导致与faxitron图像相比,组织病理学图像数量有限。
2-2:预处理
作者开发了一个预处理流程(图1)和图形用户界面(GUI),用于处理和可视化faxitron和组织病理学图像(图S1),并为配准算法生成所需的输入图像。
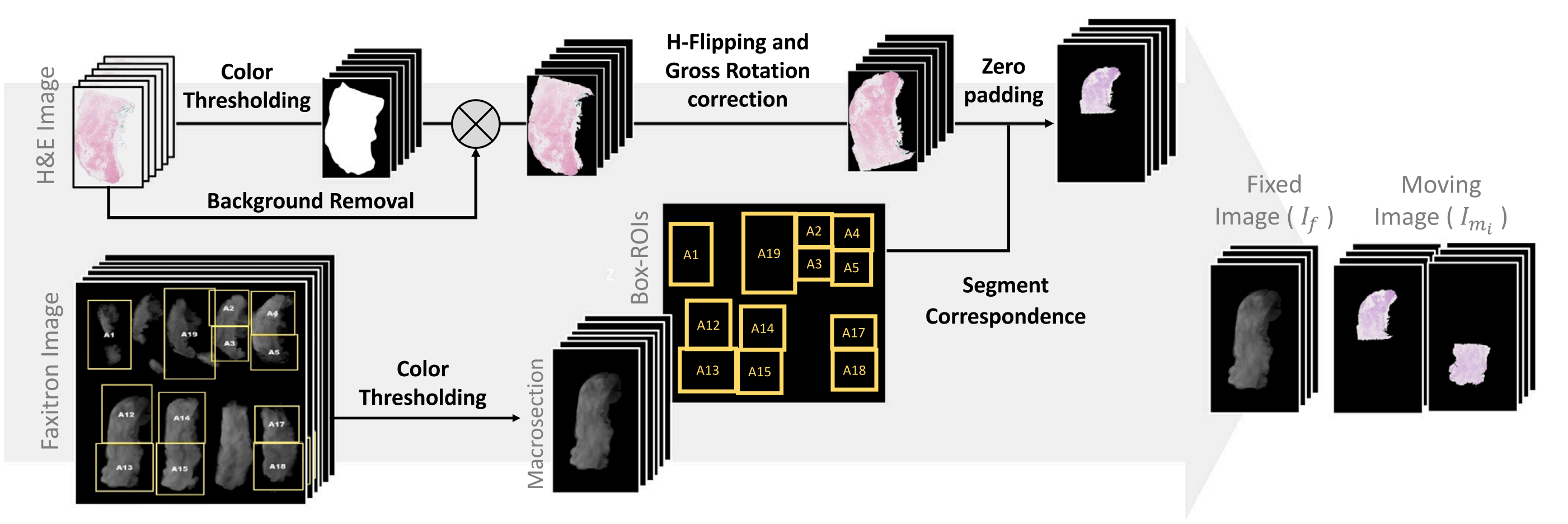
faxitron图像经历了一个自动化预处理步骤,旨在提取大体切片、Box-ROIs(黄色框)及其相关的病理学家标注标签(例如,图1中显示的A1、A2、A3标签)。此过程采用了颜色阈值分割和文本提取方法(Smith, 2007)。
组织病理学图像需要三个预处理步骤。
首先,采用自动颜色阈值分割进行组织分割和背景移除。其次,估计相对于相应faxitron图像的宏观旋转角度,并在适用时确定水平翻转。这一预处理步骤有助于纠正组织切片在玻璃片上装载时引起的变异,包括在温浴中的组织旋转或组织不同侧的装载。
作者的研究包括这些程序的手动校正和自动化实现,并提供了两种方法的结果。最后一步是使用标签自动将组织病理学图像与faxitron图像上提取的黄色Box-ROIs关联。这种对应关系有助于确定组织病理学图像在其大体切片faxitron图像中的相对位置,从而澄清组织片段之间的关系。这些信息对于确保每个组织病理学图像与faxitron图像具有统一的物理尺寸并进行配准模型输入准备至关重要。
需要注意的是,作者之前的研究表明,边界框的位置仅提供了组织片段在组织病理学图像中相对于faxitron图像的大致位置,即使使用配准算法也无法准确地将组织病理学图像与faxitron对齐(Golestani et al., 2024)。
2-3:训练数据集
由于缺乏组织病理学图像与其相应faxitron图像之间的空间对应关系的真实数据,配准网络在合成单模态数据集上进行训练。在本研究中,作者将训练限制在具有一对移动图像的样本上。
因此,训练数据集由固定图像和两个移动图像(𝑁 = 2)组成的样本构成,这些样本通过多步骤过程创建。作者在训练阶段使用带有两个移动图像的合成样本以最小化计算成本,并且所得模型在推理阶段能够注册具有更多移动图像的样本。
为了合成这些图像,作者首先使用由B样条函数定义的连续平滑曲线边界将参考图像𝐼𝑟(faxitron或组织病理学图像)分割成两个部分。分割的选择,无论是水平还是垂直,都是随机确定的。接下来,作者从曲线生成两个掩模,以掩模原始图像并创建两个包含图像独特部分的独立图像。
为了确保分割图像包含初始组织片段的实质性部分,每个分割图像至少需要保留15%的组织。在第二步中,对每个图像分区应用模拟变换,以生成代表合成训练样本的两个移动图像的变换图像。通过这种方法生成的合成样本的插图在补充材料部分呈现(图S4)。
为了确保模拟变换的合理性,变量是从预定义的间隔中随机抽取的。旋转角度选自-20至20度,缩放系数从0.9至1.1,平移系数在图像尺寸的10%内,剪切系数在图像尺寸的5%内。作者使用了5127张faxitron和组织病理学图像的组织片段来生成合成单模态训练数据集。
三、讨论
本研究介绍了一种名为PViT-AIR的模型,该模型结合了卷积神经网络和视觉变换器,用于将X射线(faxitron)成像的大体组织切片与多个组织病理学片段以拼图范式进行配准。
PViT-AIR模型在评估指标上表现出统计学上的显著优势,包括高Dice系数(0.91)、低地标误差(1.51毫米)、拼接距离(1.15毫米)和Hausdorff距离(3.85毫米),相较于其他基于深度学习或迭代方法的配准途径。
此外,作者提出的全自动版本PViT-AIR+也表现出了相媲美的性能,其Dice系数为0.91,地标误差为1.63毫米,拼接距离为1.24毫米,Hausdorff距离为3.75毫米。实现的配准误差远小于组织厚度(约3毫米–1厘米)或平均癌症大小(9.8毫米),后者大小在1–20毫米范围内。
提出的流程能够自动识别faxitron大体切片与组织病理学图像之间的对应关系,通过提取Box-ROIs和标签匹配实现。随后,配准模型能够同时将所有片段与其对应的大体切片faxitron图像对齐。作者的模型通过有效解决片段配准期间的不完全数据问题,改善了图像拼接结果。通过拼接注册的组织病理学图像获得的复合图像在组织之间展现出最小或无重叠区域或间隙。
PViT-AIR成功的主要原因在于它结合了全局和局部处理,这与缺乏全局处理能力的CNN基线方法(如BreastRegNet)形成了区别。
此外,提出的方法通过在变换计算中纳入所有组织片段的信息,解决了片段对片段配准方法的局限性。与独立注册然后拼接与大体切片相关的组织片段的基线方法不同,PViT-AIR考虑了所有部分与大体切片之间的相互关系。它首次在考虑拼接过程的情况下识别最佳配准,应对病理数据获取的现实情况,即组织被切割成多个样本,需要一起考虑以获得彼此之间及与其他图像(例如faxitron放射照片)的有意义的空间对齐。
这种全面集成使得模型能够利用来自整个组织片段集合的信息,克服了依赖单个片段数据的限制,并减轻了分割组织图像中的数据不匹配的影响。
作者还使用了求和来合并变换后的组织病理学图像,允许模型在训练期间惩罚重叠的片段,这是由于使用了均方误差(MSE)作为损失函数。这种方法显著提高了模型在片段对齐和拼接方面的性能,与替代方法相比,在推理期间实现了最小或可忽略的重叠。
获得的结果表明,乳腺组织在faxitron和组织病理学切片之间的边界被精确对齐,展示了作者提出的模型在实现组织准确全局对齐方面的有效性。在评估多图像配准时,不仅要考虑模型在组织边界对齐方面的准确性,而且要确保注册的移动图像之间没有重叠或间隙,特别是当它们形成一个完整切片时。
因此,考虑所有指标以全面评估准确性是至关重要的。Hausdorff距离测量图像中组织边界的距离,关注它们的外部边界,而Dice系数量化了Faxitron和复合图像的二值掩模之间的相似性。然而,这些指标单独并不能提供对拼接过程的完整评估,包括组织片段之间的潜在重叠或间隙。
因此,本研究提出的拼接距离度量是对现有评估指标的补充。例如,作者的发现表明,尽管BreastRegNet实现了较低的Hausdorff距离,但它表现出较高的拼接距离,表明该模型在尝试覆盖整个组织时未能正确拼接组织片段(图3)。
图3展示了使用不同策略将乳腺组织切片的上下两半部分的组织病理学图像与整个部分的Faxitron图像进行配准的定性比较。
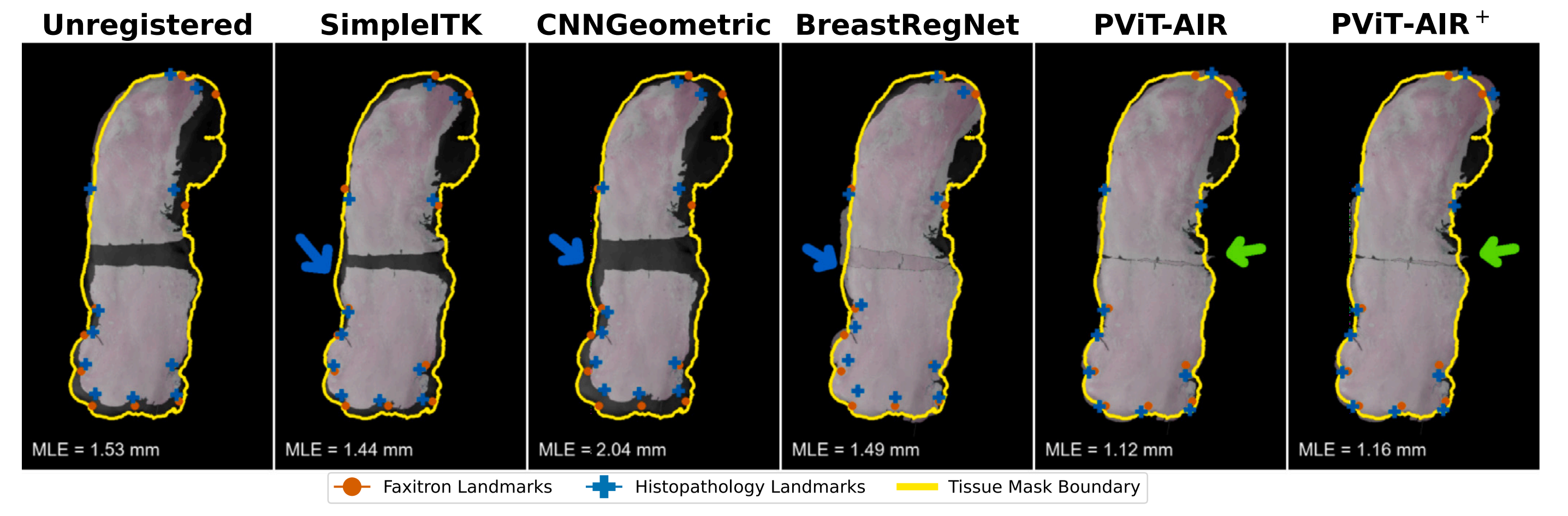
以下是对图3的分析:
-
PViT-AIR方法:
- PViT-AIR方法成功实现了组织病理学图像与Faxitron图像的精确边界对齐。
- 该方法无缝拼接了组织病理学图像,没有出现重叠或间隙(绿色箭头所示)。
- 这表明PViT-AIR在配准过程中能够有效地处理图像边缘,实现平滑的过渡。
-
SimpleITK迭代方法:
- SimpleITK迭代方法未能成功关闭组织病理学图像之间的间隙。
- 这可能导致配准后的图像在拼接处出现不连续,影响图像的整体一致性。
-
CNNGeometric方法:
- 同样,CNNGeometric方法也未能关闭组织病理学图像之间的间隙。
- 这表明该方法在处理图像拼接时可能存在局限性。
-
BreastRegNet方法:
- BreastRegNet方法导致了组织重叠(蓝色箭头所示)。
- 这可能意味着在配准过程中,该方法未能准确估计组织病理学图像之间的相对位置,导致重叠。
-
PViT-AIR+(全自动版本):
- PViT-AIR+表示PViT-AIR的全自动版本,意味着整个配准过程无需手动干预。
- 文章中没有直接展示PViT-AIR+的结果,但可以推断,由于它是PViT-AIR的全自动版本,其结果应该与PViT-AIR相似,能够实现精确的图像配准和无缝拼接。
总体而言,图3强调了PViT-AIR方法在处理组织病理学图像与Faxitron图像配准方面的优势,特别是在实现精确边界对齐和无缝拼接方面的表现优于其他方法。
训练一个多模态网络以注册faxitron和组织病理学图像在本研究中构成了一个重大挑战。
这一挑战源于缺乏有效的无监督学习损失函数或包含准确空间对应关系的faxitron-组织病理学图像对的数据库以进行监督学习。
作者采用了一种替代方法来克服这个问题,即训练作者的模型以生成自组织病理学和faxitron图像的合成单模态样本。需要注意的是,尽管模型学习的是同一模态的移动和固定图像之间的配准,但它从生成自组织病理学或faxitron图像的样本中学习。同一个模型看到了这两种模态。
作者的发现表明,PViT-AIR能够处理多模态数据并提高对齐精度,即使它是在单模态输入上训练的,如地标误差的减少所证明。这种成功可以归因于模型能够整合来自faxitron和组织病理学图像的高层特征。
在训练期间使用多样化的参数集进行合成变换确保了观察到的同时涵盖faxitron和组织病理学图像的仿射变换的全面覆盖。此外,使用单模态数据集使得能够使用MSE作为损失函数以提取图像配准的相关特征。先前的研究已经证明了这种方法的有效性,并展示了即使在单模态学习的情况下也能实现准确的多模态推论(Shao et al., 2021)。作者使用互信息作为直接评分函数对此多模态配准进行的实验未能实现竞争性结果,进一步强调了提出方法的优势。
PViT-AIR的另一个独特特点是,它能够在推理过程中处理任意数量的移动图像,尽管它是在只有两个移动图像片段的合成图像上训练的。报告的结果展示了模型在注册所有样本时的性能,无论输入移动图像的数量如何变化。
基于学习的方法,如PViT-AIR,相较于迭代配准方法具有显著优势,速度快约200倍。然而,PViT-AIR仍然是唯一一个在保持最小拼接伪影的同时也精确的学习型配准方法。
作者方法的增强速度使得能够实时交互执行组织病理学-faxitron配准,这一能力超越了传统方法的限制。通过显著加快配准过程,作者的方法有望为创建包含通过注册组织病理学图像投影的地面真实癌症标签的faxitron图像标签数据集做出宝贵贡献。
这样的数据集对于在faxitron图像上训练基于机器学习的乳腺癌检测方法至关重要。此外,经过训练后,PViT-AIR网络消除了精细化配准参数的必要性,从而简化了传统配准设置的相关复杂性。因此,作者的方法与常规方法相比,为非专家用户提供了更大的可访问性。
值得注意的是,本研究中呈现的配准技术是在乳腺背景下测试的,在这种情况下,作者有多个(1–6)组织病理学图像和一个放射学(faxitron)图像。作者预计作者的方法可以应用于其他放射学模态,以及其他组织类型的多片段对一配准场景中,例如在前列腺进行象限处理,或在脑部或肾脏中。
此外,作者提出的全自动方法不仅速度快200倍,而且在配准准确性方面也显著优于其他方法或手动配准。与手动配准相比的全面评估表明,这个过程对于人类读者来说不仅繁琐,而且极具挑战性,因为人类读者似乎只优化了一个或最多两个指标(例如,读者1 - MLE,读者2 - SDM和Dice,读者3 - Dice系数),而在其他方面则失败了。此外,这种对齐需要专门的软件和方法,这已经通过作者开发的GUI工具得到了简化。
尽管PViT-AIR在配准质量和执行时间方面优于其他配准方法,但作者的研究受限于单一机构的数据。作者计划通过在额外队列上测试作者的模型并纳入多读者地标来扩大模型的评估,这将使作者能够独立于特定输入队列评估模型的鲁棒性和泛化能力。尽管存在这一限制,提出的方法简化了组织病理学图像的多片段对faxitron图像的配准,与现有方法相比,包括迭代或深度学习方法,性能有所改进。
四、结论
精确的配准在将组织病理学图像与相应的faxitron放射照片对齐中扮演着关键角色,这有助于映射乳腺癌的范围和亚型。此种对齐对于提升乳腺faxitron图像的解释能力以及为开发和使用机器学习技术验证乳腺癌症检测模型提供标记数据具有显著潜力。
本研究介绍了PViT-AIR,这是首个利用深度学习技术进行乳腺癌患者手术获取的乳腺组织faxitron与组织病理学图像的2D配准的方法。作者提出的模型作为一种拼图求解器,能够高效地在单个推理步骤中将多个组织病理学图像片段与其对应的大体切片faxitron图像进行配准。通过整合卷积神经网络和视觉变换器,作者的模型能够从整个组织大体切片及其片段中提取局部和全局信息,从而实现图像片段的同时配准和拼接。
作者采用了一种弱监督的训练方法,使用合成的单模态训练数据集,使得模型能够在不依赖多模态真实数据的情况下执行faxitron与乳腺组织病理学图像的配准。实验结果表明,作者的模型在多模态测试数据上表现出了令人鼓舞的性能,与现有的最先进的配准技术,如深度学习和迭代方法相比,展现了更高的准确性和速度。
所提出的方法简化了多片段配准流程,实现了实时交互配准。本研究实现的精确配准使得能够从组织病理学图像到其对应的faxitron图像准确映射真实信息,如残留乳腺癌的大小和局灶性。这一进展提升了性能并改善了标记数据的可获取性,从而促进了在faxitron图像上定位残留肿瘤的机器学习方法的开发和验证,进而简化了病理工作流程。