rdagent框架代码拆解:自动化因子挖掘
原创内容第674篇,专注量化投资、个人成长与财富自由。
1、网站绑定星球会员完善(已完成)。
2、盘后数据更新,策略集自动运行(已完成)。
3、用户可发布策略:公开,积分或私有化。
4、ETF维度筛选:热门ETF,LOF,分类:宽基、行业,smartbeta等
5、新增趋势指标。
前沿探索:crewai投研,rdagent+qlib(已开始)。
crewai与rdagent的框架,动机有类似之处。
都是通过LLM,自动化收集、分析资料。只不过rdagent更专有一些,直接面向r&d的过程去生成模型,面向数据驱动的场景直接建模。
从这个意义上讲,rdagent面向crewai之上构建的落地应用。
我来尝试看看二者有没有整合的可能。
以前我们做量化,需要到量化社区,前沿论文中去找线索。而且多数论文是没有代码复现的,我们还需要花大量的时间去复现。
有没有一种可能,借助大模型的能力,把这个过程直接自动化,那样的话,科研就非常轻松了。——这也是rdagent框架的初心。
大模型的能力,就是读文本,写文本。(当然还可以多模态)。
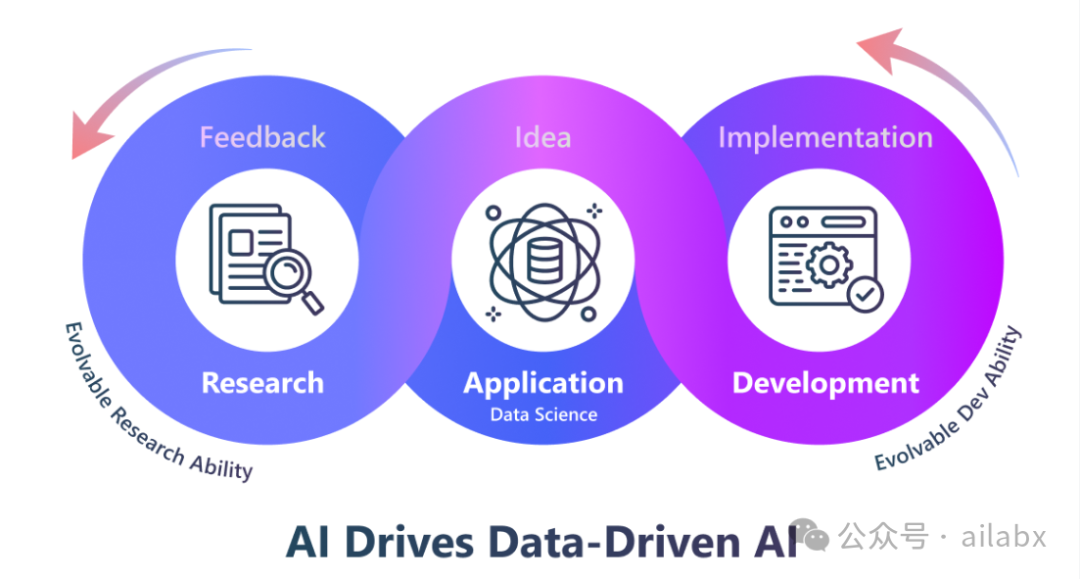
根据意图调用函数或者外部工具。
class APIBackend:
"""
This is a unified interface for different backends.
(xiao) thinks integerate all kinds of API in a single class is not a good design.
So we should split them into different classes in `oai/backends/` in the future.
"""
# FIXME: (xiao) We should avoid using self.xxxx.
# Instead, we can use self.cfg directly. If it's difficult to support different backend settings, we can split them into multiple BaseSettings.
def __init__( # noqa: C901, PLR0912, PLR0915
self,
*,
chat_api_key: str | None = None,
chat_model: str | None = None,
chat_api_base: str | None = None,
chat_api_version: str | None = None,
embedding_api_key: str | None = None,
embedding_model: str | None = None,
embedding_api_base: str | None = None,
embedding_api_version: str | None = None,
use_chat_cache: bool | None = None,
dump_chat_cache: bool | None = None,
use_embedding_cache: bool | None = None,
dump_embedding_cache: bool | None = None,
) -> None:
self.cfg = RD_AGENT_SETTINGS
if self.cfg.use_llama2:
self.generator = Llama.build(
ckpt_dir=self.cfg.llama2_ckpt_dir,
tokenizer_path=self.cfg.llama2_tokenizer_path,
max_seq_len=self.cfg.max_tokens,
max_batch_size=self.cfg.llams2_max_batch_size,
)
self.encoder = None
elif self.cfg.use_gcr_endpoint:
gcr_endpoint_type = self.cfg.gcr_endpoint_type
if gcr_endpoint_type == "llama2_70b":
self.gcr_endpoint_key = self.cfg.llama2_70b_endpoint_key
self.gcr_endpoint_deployment = self.cfg.llama2_70b_endpoint_deployment
self.gcr_endpoint = self.cfg.llama2_70b_endpoint
elif gcr_endpoint_type == "llama3_70b":
self.gcr_endpoint_key = self.cfg.llama3_70b_endpoint_key
self.gcr_endpoint_deployment = self.cfg.llama3_70b_endpoint_deployment
self.gcr_endpoint = self.cfg.llama3_70b_endpoint
elif gcr_endpoint_type == "phi2":
self.gcr_endpoint_key = self.cfg.phi2_endpoint_key
self.gcr_endpoint_deployment = self.cfg.phi2_endpoint_deployment
self.gcr_endpoint = self.cfg.phi2_endpoint
elif gcr_endpoint_type == "phi3_4k":
self.gcr_endpoint_key = self.cfg.phi3_4k_endpoint_key
self.gcr_endpoint_deployment = self.cfg.phi3_4k_endpoint_deployment
self.gcr_endpoint = self.cfg.phi3_4k_endpoint
elif gcr_endpoint_type == "phi3_128k":
self.gcr_endpoint_key = self.cfg.phi3_128k_endpoint_key
self.gcr_endpoint_deployment = self.cfg.phi3_128k_endpoint_deployment
self.gcr_endpoint = self.cfg.phi3_128k_endpoint
else:
error_message = f"Invalid gcr_endpoint_type: {gcr_endpoint_type}"
raise ValueError(error_message)
self.headers = {
"Content-Type": "application/json",
"Authorization": ("Bearer " + self.gcr_endpoint_key),
"azureml-model-deployment": self.gcr_endpoint_deployment,
}
self.gcr_endpoint_temperature = self.cfg.gcr_endpoint_temperature
self.gcr_endpoint_top_p = self.cfg.gcr_endpoint_top_p
self.gcr_endpoint_do_sample = self.cfg.gcr_endpoint_do_sample
self.gcr_endpoint_max_token = self.cfg.gcr_endpoint_max_token
if not os.environ.get("PYTHONHTTPSVERIFY", "") and hasattr(ssl, "_create_unverified_context"):
ssl._create_default_https_context = ssl._create_unverified_context # noqa: SLF001
self.encoder = None
else:
self.use_azure = self.cfg.use_azure
self.use_azure_token_provider = self.cfg.use_azure_token_provider
self.managed_identity_client_id = self.cfg.managed_identity_client_id
# Priority: chat_api_key/embedding_api_key > openai_api_key > os.environ.get("OPENAI_API_KEY")
# TODO: Simplify the key design. Consider Pandatic's field alias & priority.
self.chat_api_key = (
chat_api_key
or self.cfg.chat_openai_api_key
or self.cfg.openai_api_key
or os.environ.get("OPENAI_API_KEY")
)
self.embedding_api_key = (
embedding_api_key
or self.cfg.embedding_openai_api_key
or self.cfg.openai_api_key
or os.environ.get("OPENAI_API_KEY")
)
self.chat_model = self.cfg.chat_model if chat_model is None else chat_model
self.encoder = None # tiktoken.encoding_for_model(self.chat_model)
self.chat_api_base = self.cfg.chat_azure_api_base if chat_api_base is None else chat_api_base
self.chat_api_version = self.cfg.chat_azure_api_version if chat_api_version is None else chat_api_version
self.chat_stream = self.cfg.chat_stream
self.chat_seed = self.cfg.chat_seed
self.embedding_model = self.cfg.embedding_model if embedding_model is None else embedding_model
self.embedding_api_base = (
self.cfg.embedding_azure_api_base if embedding_api_base is None else embedding_api_base
)
self.embedding_api_version = (
self.cfg.embedding_azure_api_version if embedding_api_version is None else embedding_api_version
)
if self.use_azure:
if self.use_azure_token_provider:
dac_kwargs = {}
if self.managed_identity_client_id is not None:
dac_kwargs["managed_identity_client_id"] = self.managed_identity_client_id
credential = DefaultAzureCredential(**dac_kwargs)
token_provider = get_bearer_token_provider(
credential,
"https://cognitiveservices.azure.com/.default",
)
self.chat_client = openai.AzureOpenAI(
azure_ad_token_provider=token_provider,
api_version=self.chat_api_version,
azure_endpoint=self.chat_api_base,
)
self.embedding_client = openai.AzureOpenAI(
azure_ad_token_provider=token_provider,
api_version=self.embedding_api_version,
azure_endpoint=self.embedding_api_base,
)
else:
self.chat_client = openai.AzureOpenAI(
api_key=self.chat_api_key,
api_version=self.chat_api_version,
azure_endpoint=self.chat_api_base,
)
self.embedding_client = openai.AzureOpenAI(
api_key=self.embedding_api_key,
api_version=self.embedding_api_version,
azure_endpoint=self.embedding_api_base,
)
else:
self.chat_client = openai.OpenAI(api_key=self.chat_api_key)
self.embedding_client = openai.OpenAI(api_key=self.embedding_api_key)
self.dump_chat_cache = self.cfg.dump_chat_cache if dump_chat_cache is None else dump_chat_cache
self.use_chat_cache = self.cfg.use_chat_cache if use_chat_cache is None else use_chat_cache
self.dump_embedding_cache = (
self.cfg.dump_embedding_cache if dump_embedding_cache is None else dump_embedding_cache
)
self.use_embedding_cache = self.cfg.use_embedding_cache if use_embedding_cache is None else use_embedding_cache
if self.dump_chat_cache or self.use_chat_cache or self.dump_embedding_cache or self.use_embedding_cache:
self.cache_file_location = self.cfg.prompt_cache_path
self.cache = SQliteLazyCache(cache_location=self.cache_file_location)
# transfer the config to the class if the config is not supposed to change during the runtime
self.use_llama2 = self.cfg.use_llama2
self.use_gcr_endpoint = self.cfg.use_gcr_endpoint
self.retry_wait_seconds = self.cfg.retry_wait_seconds
吾日三省吾身
读《居里夫人》,有一点感悟。
好奇心非常重要。
她做放射性研究,纯粹出于好奇,就想搞清楚,这个放射性背后是什么。并没有出于通过一个答辩或者获得一个学位的考量。
从这个角度出发,无论条件多艰难,都会乐此不疲地持续下去。
当然,理论功底与科学素养还是需要的。
你得接触得到前沿的进展,也就是能够触及到领域的边界。
然后在边界上往前走一步,就扩展了人类整体的认知边缘。
AI量化实验室 星球,已经运行三年多,1200+会员。
quantlab代码交付至5.X版本,含几十个策略源代码,因子表达式引擎、遗传算法(Deap)因子挖掘引擎等,每周五迭代一次。
(国庆优惠券)
作者:AI量化实验室(专注量化投资、个人成长与财富自由)
扩展 • 历史文章
• 年化从19.1%提升到22.5%,全球大类资产轮动,加上RSRS择时,RSRS性能优化70倍。(附策略源码)
• 年化53%的策略随quantlab5.13发布,可以直接运行在服务器上了(附python代码)
• AI量化实验室——2024量化投资的星辰大海