vue综合指南(一)

🌈个人主页:前端青山
🔥系列专栏:Vue篇
🔖人终将被年少不可得之物困其一生
依旧青山,本期给大家带来Vuet篇专栏内容:Vue-综合指南
目录
1、你知道Vue响应式数据原理吗?Proxy 与 Object.defineProperty 优劣对比
2、Vue2.x组件通信有哪些方式
3、Vue 中的 computed 和 watch 的区别在哪里
4、组件中的data为什么是一个函数
5、nextTick的实现原理是什么
6、说说你对keep-alive组件的了解
7、你都做过哪些Vue的性能优化
8、vue3.0介绍
9、Composition API 的出现带来哪些新的开发体验,为啥需要这个?
10、什么情况下使用 Vuex
11、可以直接修改state的值吗?
12、为什么Vuex的mutation不能做异步操作
13、v-model和vuex有冲突吗?
14、路由懒加载是什么意思?如何实现路由懒加载?
15 Vue-router导航守卫有哪些?
16、vue路由hash模式和histroy模式实现原理分别是什么 区别是什么?
17、说一下Vue的双向绑定数据的原理
18、解释单向数据流和双向数据绑定
19、Vue 如何去除url中的 #
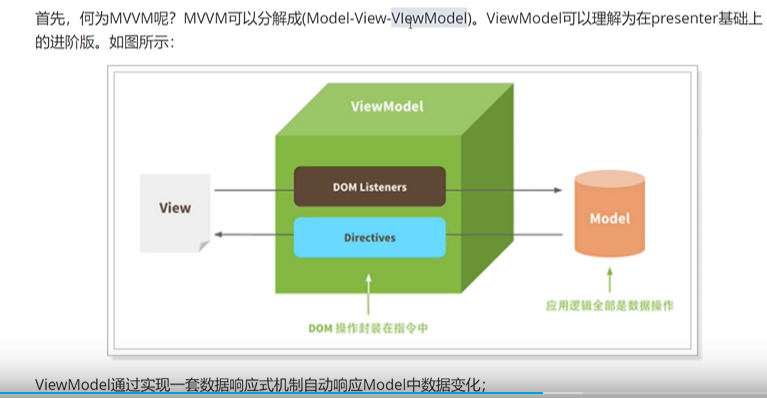
20、对 MVC、MVVM的理解
1、你知道Vue响应式数据原理吗?Proxy 与 Object.defineProperty 优劣对比
一、Proxy的优势如下:
1.Proxy可以直接监听对象⽽⾮属性 。
2.Proxy可以直接监听数组的变化 。
3.Proxy有多达13种拦截⽅法,不限于apply、ownKeys、deleteProperty、has等等是 Object.defineProperty 不具备的 。
4.Proxy返回的是⼀个新对象,我们可以只操作新的对象达到⽬的,⽽ Object.defineProperty 只能遍历对象属性直接修改。
5.Proxy作为新标准将受到浏览器⼚商重点持续的性能优化,也就是传说中的新标准的性能红利 。
二、Object.defineProperty的优势如下:
1.兼容性好,⽀持IE9。
2、Vue2.x组件通信有哪些方式
常见使用场景可以分为三类:
-
父子通信: 父向子传递数据是通过 props,子向父是通过 events(
$emit);通过父链 / 子链也可以通信($parent/$children);ref 也可以访问组件实例;provide / inject API;$attrs/$listeners -
兄弟通信: Bus;Vuex
-
跨级通信: Bus;Vuex;provide / inject API、
$attrs/$listeners
3、Vue 中的 computed 和 watch 的区别在哪里
计算属性computed :
\1. 支持缓存,只有依赖数据发生改变,才会重新进行计算
\2. 不支持异步,当computed内有异步操作时无效,无法监听数据的变化
3.computed 属性值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data中声明过或者父组件传递的props中的数据通过计算得到的值
\4. 如果一个属性是由其他属性计算而来的,这个属性依赖其他属性,是一个多对一或者一对一,一般用computed
5.如果computed属性属性值是函数,那么默认会走get方法;函数的返回值就是属性的属性值;在computed中的,属性都有一个get和一个set方法,当数据变化时,调用set方法。
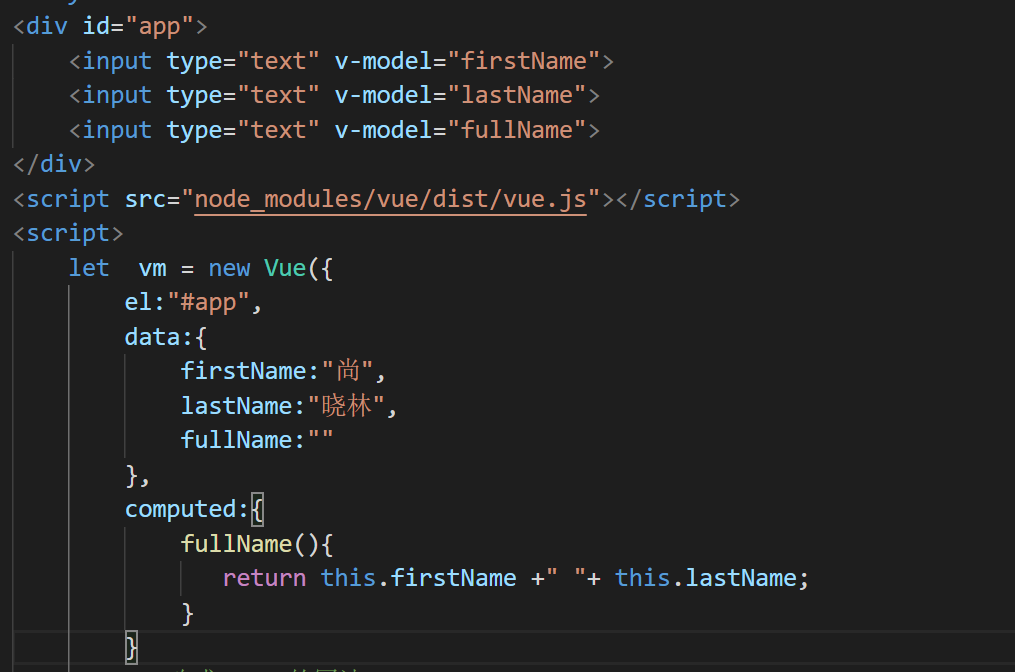
侦听属性watch:
\1. 不支持缓存,数据变,直接会触发相应的操作;
2.watch支持异步;
3.监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值;
\4. 当一个属性发生变化时,需要执行对应的操作;一对多;
\5. 监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数,
immediate:组件加载立即触发回调函数执行,
deep: 深度监听,为了发现对象内部值的变化,复杂类型的数据时使用,例如数组中的对象内容的改变,注意监听数组的变动不需要这么做。注意:deep无法监听到数组的变动和对象的新增,参考vue数组变异,只有以响应式的方式触发才会被监听到。
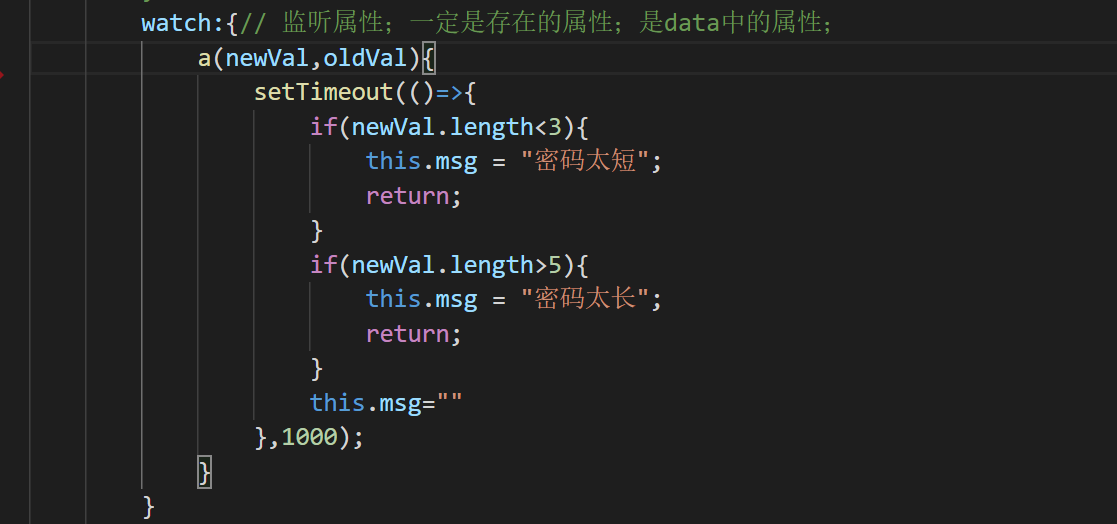
监听的对象也可以写成字符串的形式
4、组件中的data为什么是一个函数
如果两个实例引用同一个对象,当其中一个实例的属性发生改变时,另一个实例属性也随之改变,只有当两个实例拥有自己的作用域时,才不会相互干扰。
这是因为JavaScript的特性所导致,在component中,data必须以函数的形式存在,不可以是对象。
组建中的data写成一个函数,数据以函数返回值的形式定义,这样每次复用组件的时候,都会返回一份新的data,相当于每个组件实例都有自己私有的数据空间,它们只负责各自维护的数据,不会造成混乱。而单纯的写成对象形式,就是所有的组件实例共用了一个data,这样改一个全都改了。
5、nextTick的实现原理是什么
官方文档对 nextTick 的功能如是说明:
在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
// 修改数据
vm.msg = 'Hello'
// DOM 还没有更新
Vue.nextTick(function () {
// DOM 更新了
})
// 作为一个 Promise 使用 (2.1.0 起新增,详见接下来的提示)
Vue.nextTick()
.then(function () {
// DOM 更新了
})2.1.0 起新增:如果没有提供回调且在支持 Promise 的环境中,则返回一个 Promise。请注意 Vue 不自带 Promise 的 polyfill,所以如果你的目标浏览器不原生支持 Promise (IE:你们都看我干嘛),你得自己提供 polyfill。
从上面的官方介绍中可以看到,nextTick 的主要功能就是更新数据后让回调函数作用于更新后的DOM 。看到这句话,你可能第一反应是:呸!说了等于没说,还是不理解。那么请看下面这个例子:
<template>
<div id="example">{{message}}</div>
</template>
<script>
var vm = new Vue({
el: '#example',
data: {
message: '123'
}
})
vm.message = 'new message' // 更改数据
console.log(vm.$el.innerHTML) // '123'
Vue.nextTick(function () {
console.log(vm.$el.innerHTML) // 'new message'
})
</script>在上面例子中,当我们更新了message的数据后,立即获取vm.$el.innerHTML,发现此时获取到的还是更新之前的数据:123。但是当我们使用nextTick来获取vm.$el.innerHTML时,此时就可以获取到更新后的数据了。这是为什么呢?
这里就涉及到Vue中对DOM的更新策略了,Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个事件队列,并缓冲在同一事件循环中发生的所有数据变更。如果同一个 watcher 被多次触发,只会被推入到事件队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。然后,在下一个的事件循环“tick”中,Vue 刷新事件队列并执行实际 (已去重的) 工作。
在上面这个例子中,当我们通过 vm.message = ‘new message‘更新数据时,此时该组件不会立即重新渲染。当刷新事件队列时,组件会在下一个事件循环“tick”中重新渲染。所以当我们更新完数据后,此时又想基于更新后的 DOM 状态来做点什么,此时我们就需要使用Vue.nextTick(callback),把基于更新后的DOM 状态所需要的操作放入回调函数callback中,这样回调函数将在 DOM 更新完成后被调用。
OK,现在大家应该对nextTick是什么、为什么要有nextTick以及怎么使用nextTick有个大概的了解了。那么问题又来了,Vue为什么要这么设计?为什么要异步更新DOM?这就涉及到另外一个知识:JS的运行机制。
-
前置知识:JS的运行机制
我们知道 JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
-
所有同步任务都在主线程上执行,形成一个执行栈(
execution context stack)。 -
主线程之外,还存在一个"任务队列"(
task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。 -
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
-
主线程不断重复上面的第三步。
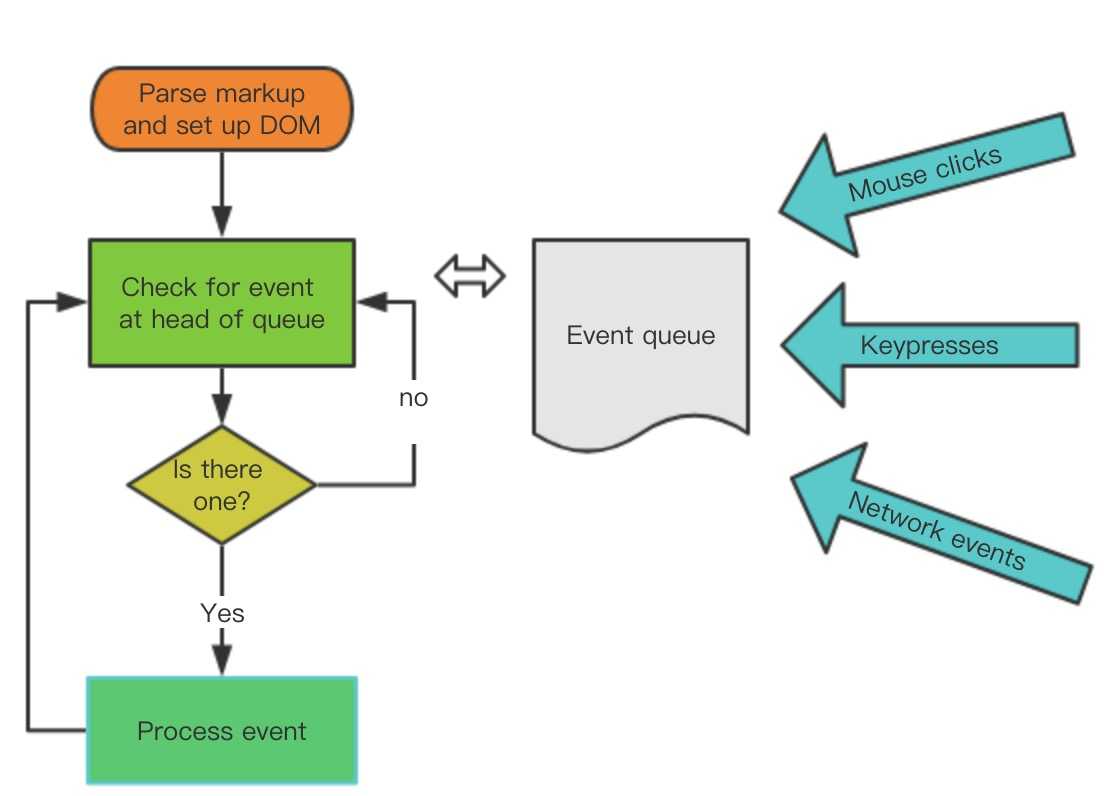
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是宏任务(macro task) 和微任务(micro task),并且每执行完一个个宏任务(macro task)后,都要去清空该宏任务所对应的微任务队列中所有的微任务(micro task),他们的执行顺序如下所示:
for (macroTask of macroTaskQueue) {
// 1. 处理当前的宏任务
handleMacroTask();
// 2. 处理对应的所有微任务
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}在浏览器环境中,常见的
-
宏任务(
macro task) 有setTimeout、MessageChannel、postMessage、setImmediate; -
微任务(
micro task)有MutationObsever和Promise.then。
OK,有了这个概念之后,接下来我们就进入本篇文章的正菜:从Vue源码角度来分析nextTick的实现原理。
-
nextTick源码分析
nextTick 的源码位于src/core/util/next-tick.js,总计118行。
nextTick源码主要分为两块:
-
能力检测
-
根据能力检测以不同方式执行回调队列
4.1 能力检测
Vue 在内部对异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
宏任务耗费的时间是大于微任务的,所以在浏览器支持的情况下,优先使用微任务。如果浏览器不支持微任务,使用宏任务;但是,各种宏任务之间也有效率的不同,需要根据浏览器的支持情况,使用不同的宏任务。
这一部分的源码如下:
let microTimerFunc
let macroTimerFunc
let useMacroTask = false
/* 对于宏任务(macro task) */
// 检测是否支持原生 setImmediate(高版本 IE 和 Edge 支持)
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
}
// 检测是否支持原生的 MessageChannel
else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
}
// 都不支持的情况下,使用setTimeout
else {
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
/* 对于微任务(micro task) */
// 检测浏览器是否原生支持 Promise
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
}
}
// 不支持的话直接指向 macro task 的实现。
else {
// fallback to macro
microTimerFunc = macroTimerFunc
}首先声明了两个变量: microTimerFunc 和 macroTimerFunc ,它们分别对应的是 micro task 的函数和 macro task 的函数。对于 macro task 的实现,优先检测是否支持原生 setImmediate,这是一个高版本 IE 和Edge 才支持的特性,不支持的话再去检测是否支持原生的 MessageChannel,如果也不支持的话就会降级为 setTimeout 0;而对于 micro task 的实现,则检测浏览器是否原生支持 Promise,不支持的话直接指向 macro task 的实现。
4.2 执行回调队列
接下来就进入了核心函数nextTick中,如下:
const callbacks = [] // 回调队列
let pending = false // 异步锁
// 执行队列中的每一个回调
function flushCallbacks () {
pending = false // 重置异步锁
// 防止出现nextTick中包含nextTick时出现问题,在执行回调函数队列前,提前复制备份并清空回调函数队列
const copies = callbacks.slice(0)
callbacks.length = 0
// 执行回调函数队列
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
// 将回调函数推入回调队列
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick')
}
} else if (_resolve) {
_resolve(ctx)
}
})
// 如果异步锁未锁上,锁上异步锁,调用异步函数,准备等同步函数执行完后,就开始执行回调函数队列
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// 如果没有提供回调,并且支持Promise,返回一个Promise
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}首先,先来看 nextTick函数,该函数的主要逻辑是:先把传入的回调函数 cb 推入 回调队列callbacks 数组,同时在接收第一个回调函数时,执行能力检测中对应的异步方法(异步方法中调用了回调函数队列)。最后一次性地根据 useMacroTask 条件执行 macroTimerFunc 或者是 microTimerFunc,而它们都会在下一个 tick 执行 flushCallbacks,flushCallbacks 的逻辑非常简单,对 callbacks 遍历,然后执行相应的回调函数。
nextTick 函数最后还有一段逻辑:
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}这是当 nextTick 不传 cb 参数的时候,提供一个 Promise 化的调用,比如:
nextTick().then(() => {})当 _resolve 函数执行,就会跳到 then 的逻辑中。
这里有两个问题需要注意:
-
如何保证只在接收第一个回调函数时执行异步方法?
nextTick源码中使用了一个异步锁的概念,即接收第一个回调函数时,先关上锁,执行异步方法。此时,浏览器处于等待执行完同步代码就执行异步代码的情况。 -
执行
flushCallbacks函数时为什么需要备份回调函数队列?执行的也是备份的回调函数队列?因为,会出现这么一种情况:
nextTick的回调函数中还使用nextTick。如果flushCallbacks不做特殊处理,直接循环执行回调函数,会导致里面nextTick中的回调函数会进入回调队列。 -
总结
以上就是对 nextTick 的源码分析,我们了解到数据的变化到 DOM 的重新渲染是一个异步过程,发生在下一个 tick。当我们在实际开发中,比如从服务端接口去获取数据的时候,数据做了修改,如果我们的某些方法去依赖了数据修改后的 DOM 变化,我们就必须在 nextTick 后执行。如下:
getData(res).then(()=>{
this.xxx = res.data
this.$nextTick(() => {
// 这里我们可以获取变化后的 DOM
})
})6、说说你对keep-alive组件的了解
一、Keep-alive 是什么
keep-alive是vue中的内置组件,能在组件切换过程中将状态保留在内存中,防止重复渲染DOM
keep-alive 包裹动态组件时,会缓存不活动的组件实例,而不是销毁它们
keep-alive可以设置以下props属性:
-
include - 字符串或正则表达式。只有名称匹配的组件会被缓存
-
exclude - 字符串或正则表达式。任何名称匹配的组件都不会被缓存
-
max - 数字。最多可以缓存多少组件实例
关于keep-alive的基本用法:
<keep-alive>
<component :is="view"></component>
</keep-alive>
123使用includes和exclude:
<keep-alive include="a,b">
<component :is="view"></component>
</keep-alive>
<!-- 正则表达式 (使用 `v-bind`) -->
<keep-alive :include="/a|b/">
<component :is="view"></component>
</keep-alive>
<!-- 数组 (使用 `v-bind`) -->
<keep-alive :include="['a', 'b']">
<component :is="view"></component>
</keep-alive>
12345678910111213匹配首先检查组件自身的 name 选项,如果 name 选项不可用,则匹配它的局部注册名称 (父组件 components 选项的键值),匿名组件不能被匹配
设置了 keep-alive 缓存的组件,会多出两个生命周期钩子(activated与deactivated):
-
首次进入组件时:beforeRouteEnter > beforeCreate > created> mounted > activated > … … > beforeRouteLeave > deactivated
-
再次进入组件时:beforeRouteEnter >activated > … … > beforeRouteLeave > deactivated
二、使用场景
使用原则:当我们在某些场景下不需要让页面重新加载时我们可以使用keepalive
举个栗子:
当我们从首页–>列表页–>商详页–>再返回,这时候列表页应该是需要keep-alive
从首页–>列表页–>商详页–>返回到列表页(需要缓存)–>返回到首页(需要缓存)–>再次进入列表页(不需要缓存),这时候可以按需来控制页面的keep-alive
在路由中设置keepAlive属性判断是否需要缓存
{
path: 'list',
name: 'itemList', // 列表页
component (resolve) {
require(['@/pages/item/list'], resolve)
},
meta: {
keepAlive: true,
title: '列表页'
}
}
1234567891011使用<keep-alive>
<div id="app" class='wrapper'>
<keep-alive>
<!-- 需要缓存的视图组件 -->
<router-view v-if="$route.meta.keepAlive"></router-view>
</keep-alive>
<!-- 不需要缓存的视图组件 -->
<router-view v-if="!$route.meta.keepAlive"></router-view>
</div>
12345678三、原理分析
keep-alive是vue中内置的一个组件
源码位置:src/core/components/keep-alive.js
export default {
name: 'keep-alive',
abstract: true,
props: {
include: [String, RegExp, Array],
exclude: [String, RegExp, Array],
max: [String, Number]
},
created () {
this.cache = Object.create(null)
this.keys = []
},
destroyed () {
for (const key in this.cache) {
pruneCacheEntry(this.cache, key, this.keys)
}
},
mounted () {
this.$watch('include', val => {
pruneCache(this, name => matches(val, name))
})
this.$watch('exclude', val => {
pruneCache(this, name => !matches(val, name))
})
},
render() {
/* 获取默认插槽中的第一个组件节点 */
const slot = this.$slots.default
const vnode = getFirstComponentChild(slot)
/* 获取该组件节点的componentOptions */
const componentOptions = vnode && vnode.componentOptions
if (componentOptions) {
/* 获取该组件节点的名称,优先获取组件的name字段,如果name不存在则获取组件的tag */
const name = getComponentName(componentOptions)
const { include, exclude } = this
/* 如果name不在inlcude中或者存在于exlude中则表示不缓存,直接返回vnode */
if (
(include && (!name || !matches(include, name))) ||
// excluded
(exclude && name && matches(exclude, name))
) {
return vnode
}
const { cache, keys } = this
/* 获取组件的key值 */
const key = vnode.key == null
// same constructor may get registered as different local components
// so cid alone is not enough (#3269)
? componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '')
: vnode.key
/* 拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存 */
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance
// make current key freshest
remove(keys, key)
keys.push(key)
}
/* 如果没有命中缓存,则将其设置进缓存 */
else {
cache[key] = vnode
keys.push(key)
// prune oldest entry
/* 如果配置了max并且缓存的长度超过了this.max,则从缓存中删除第一个 */
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode)
}
}
vnode.data.keepAlive = true
}
return vnode || (slot && slot[0])
}
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081可以看到该组件没有template,而是用了render,在组件渲染的时候会自动执行render函数
this.cache是一个对象,用来存储需要缓存的组件,它将以如下形式存储:
this.cache = {
'key1':'组件1',
'key2':'组件2',
// ...
}
12345在组件销毁的时候执行pruneCacheEntry函数
function pruneCacheEntry (
cache: VNodeCache,
key: string,
keys: Array<string>,
current?: VNode
) {
const cached = cache[key]
/* 判断当前没有处于被渲染状态的组件,将其销毁*/
if (cached && (!current || cached.tag !== current.tag)) {
cached.componentInstance.$destroy()
}
cache[key] = null
remove(keys, key)
}
1234567891011121314在mounted钩子函数中观测 include 和 exclude 的变化,如下:
mounted () {
this.$watch('include', val => {
pruneCache(this, name => matches(val, name))
})
this.$watch('exclude', val => {
pruneCache(this, name => !matches(val, name))
})
}
12345678如果include 或exclude 发生了变化,即表示定义需要缓存的组件的规则或者不需要缓存的组件的规则发生了变化,那么就执行pruneCache函数,函数如下:
function pruneCache (keepAliveInstance, filter) {
const { cache, keys, _vnode } = keepAliveInstance
for (const key in cache) {
const cachedNode = cache[key]
if (cachedNode) {
const name = getComponentName(cachedNode.componentOptions)
if (name && !filter(name)) {
pruneCacheEntry(cache, key, keys, _vnode)
}
}
}
}
123456789101112在该函数内对this.cache对象进行遍历,取出每一项的name值,用其与新的缓存规则进行匹配,如果匹配不上,则表示在新的缓存规则下该组件已经不需要被缓存,则调用pruneCacheEntry函数将其从this.cache对象剔除即可
关于keep-alive的最强大缓存功能是在render函数中实现
首先获取组件的key值:
const key = vnode.key == null?
componentOptions.Ctor.cid + (componentOptions.tag ? `::${componentOptions.tag}` : '')
: vnode.key
123拿到key值后去this.cache对象中去寻找是否有该值,如果有则表示该组件有缓存,即命中缓存,如下:
/* 如果命中缓存,则直接从缓存中拿 vnode 的组件实例 */
if (cache[key]) {
vnode.componentInstance = cache[key].componentInstance
/* 调整该组件key的顺序,将其从原来的地方删掉并重新放在最后一个 */
remove(keys, key)
keys.push(key)
}
1234567
直接从缓存中拿 vnode 的组件实例,此时重新调整该组件key的顺序,将其从原来的地方删掉并重新放在this.keys中最后一个
this.cache对象中没有该key值的情况,如下:
123
/* 如果没有命中缓存,则将其设置进缓存 */
else {
cache[key] = vnode
keys.push(key)
/* 如果配置了max并且缓存的长度超过了this.max,则从缓存中删除第一个 */
if (this.max && keys.length > parseInt(this.max)) {
pruneCacheEntry(cache, keys[0], keys, this._vnode)
}
}
123456789表明该组件还没有被缓存过,则以该组件的key为键,组件vnode为值,将其存入this.cache中,并且把key存入this.keys中
此时再判断this.keys中缓存组件的数量是否超过了设置的最大缓存数量值this.max,如果超过了,则把第一个缓存组件删掉
四、思考题:缓存后如何获取数据
解决方案可以有以下两种:
-
beforeRouteEnter
-
actived
beforeRouteEnter 每次组件渲染的时候,都会执行beforeRouteEnter
beforeRouteEnter(to, from, next){
next(vm=>{
console.log(vm)
// 每次进入路由执行
vm.getData() // 获取数据
})
}
1234567actived 在keep-alive缓存的组件被激活的时候,都会执行actived钩子
activated(){
this.getData() // 获取数据
},7、你都做过哪些Vue的性能优化
-
尽量减少
data中的数据,data中的数据都会增加getter和setter,会收集对应的watcher -
v-if和v-for不能连用 -
如果需要使用
v-for给每项元素绑定事件时使用事件代理 -
SPA页面采用keep-alive缓存组件 -
在更多的情况下,使用
v-if替代v-show -
key保证唯一 -
使用路由懒加载、异步组件
-
防抖、节流
-
第三方模块按需导入
-
长列表滚动到可视区域动态加载
-
图片懒加载
SEO优化
-
预渲染
-
服务端渲染
SSR
打包优化
-
压缩代码
-
Tree Shaking/Scope Hoisting -
使用
cdn加载第三方模块 -
多线程打包
happypack -
splitChunks抽离公共文件 -
sourceMap优化
用户体验
-
骨架屏
-
PWA
8、vue3.0介绍
2020年9月19日凌晨,尤雨溪大大正式发布了 Vue.js 3.0 版本,代号:One Piece。此框架新的主要版本提供了更好的性能、更小的捆绑包体积、更好的 TypeScript 集成、用于处理大规模用例的新 API,并为框架未来的长期迭代奠定了坚实的基础。
3.0 版本的开发周期长达两年多,期间产生了 30+ RFCs、2600+ commits、628 pull requests,以及核心仓库之外的大量开发和文档工作。
Vue 3.0 的发布标志着此框架整体上已处于可用状态。尽管框架的某些子项目可能仍需要进一步的开发才能达到稳定状态(特别是 devtools 中的路由和 Vuex 集成),不过现在仍然是开始使用 Vue 3 启动新项目的合适时机。官方还鼓励库作者现在可以开始升级项目以支持 Vue 3。
9、Composition API 的出现带来哪些新的开发体验,为啥需要这个?
Composition API是Vue的下一个主要版本中最常用的讨论和特色语法。这是一种全新的逻辑重用和代码组织方法
当前,我们使用所谓的Options API构建组件。为了向Vue组件添加逻辑,我们填充(选项)属性,例如数据,方法,计算的等。这种方法的最大缺点是,这本身并不是有效的JavaScript代码。您需要确切了解模板中可以访问哪些属性,以及此关键字的行为。在后台,Vue编译器需要将此属性转换为工作代码。因此,我们无法从自动建议或类型检查中受益。
Composition API的目的是通过将当前可用组件属性作为JavaScript函数暴露出来的机制来解决这个问题。Vue核心团队将Composition API描述为“一组基于功能的附加API,可以灵活地组合组件逻辑”。使用 Composition API 编写的代码更易读,而且没有任何幕后的魔力,更容易阅读和学习。
10、什么情况下使用 Vuex
Vuex 可以帮助我们管理共享状态,并附带了更多的概念和框架。这需要对短期和长期效益进行权衡。
如果您不打算开发大型单页应用,使用 Vuex 可能是繁琐冗余的。确实是如此——如果您的应用够简单,您最好不要使用 Vuex。一个简单的 store 模式就足够您所需了。但是,如果您需要构建一个中大型单页应用,您很可能会考虑如何更好地在组件外部管理状态,Vuex 将会成为自然而然的选择。
11、可以直接修改state的值吗?
不可以
12、为什么Vuex的mutation不能做异步操作
Vuex中所有的状态更新的唯一途径都是mutation,异步操作通过 Action 来提交 mutation实现,这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用。
每个mutation执行完成后都会对应到一个新的状态变更,这样devtools就可以打个快照存下来,然后就可以实现 time-travel 了。如果mutation支持异步操作,就没有办法知道状态是何时更新的,无法很好的进行状态的追踪,给调试带来困难。
13、v-model和vuex有冲突吗?
第一种(暴力流)
<div>
<input type="text" v-model="$store.state.Root.value" />
<p>{{ $store.state.Root.value }}</p>
// 这里为什么是state.Root.value 是我这里用到了vuex里的modules
// 关于modules我会用新一篇文章来介绍,这里大家看看就行
</div>-
我们都知道v-model是一种语法糖:
<input type="text" v-model="val" /> 复制代码
等价于
<input type="text" :value="value" @input="value = $event.tagret.value" /> 复制代码
-
其实第一种方法就是利用了v-model的语法糖,至于为什么不需要mutations我猜是因为对象的引用关系
-
第二种(优雅型,通过computed)
-
这种方式一直是我在团队里比较建议使用的,因为它遵从了Vuex的核心理念:使用mutations来改变state
-
<input v-model="getVal" />
computed: { getVal: { get() { // 这里也是用了Vuex里的 modules 大家可以当成普通的变量来看 return this.$store.state.Root.value }, set(newVal) { this.$store.commit('handleVal', newVal) } } } -
computed其实可以接受两个参数:
-
get:当获取值时会触发
-
set:当修改值时会触发并有新值作为参数返回
-
-
所以我在get里获取Vuex
-
在set里调用 mutations
-
// store.js mutations: { handleVal(state, payload) { state.value = payload } }
14、路由懒加载是什么意思?如何实现路由懒加载?
像vue这种单页面应用,如果没有应用懒加载,运用webpack打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,时间过长,会出啊先长时间的白屏,即使做了loading也是不利于用户体验,而运用懒加载则可以将页面进行划分,需要的时候加载页面,可以有效的分担首页所承担的加载压力,减少首页加载用时
15 Vue-router导航守卫有哪些?
1、全局守卫: router.beforeEach
2、全局解析守卫: router.beforeResolve
3、全局后置钩子: router.afterEach
4、路由独享的守卫: beforeEnter
5、组件内的守卫: beforeRouteEnter、beforeRouteUpdate (2.2 新增)、beforeRouteLeave
导航表示路由正在发生改变,vue-router 提供的导航守卫主要用来:通过跳转或取消的方式守卫导航。有多种机会植入路由导航过程中:全局的, 单个路由独享的, 或者组件级的。
注意:参数或查询的改变并不会触发进入/离开的导航守卫。 你可以通过 观察 $route 对象 来应对这些变化,或使用 beforeRouteUpdate的组件内守卫。
1、全局守卫:
使用 router.beforeEach 注册一个全局前置守卫:
const router = new VueRouter({ ... })
router.beforeEach((to, from, next) => {
// ...
})
当一个导航触发时,全局前置守卫按照创建顺序调用。守卫是异步解析执行,此时导航在所有守卫 resolve 完之前一直处于等待中。
每个守卫方法接收三个参数:
to: Route: 即将要进入的目标 路由对象
from: Route: 当前导航正要离开的路由
next: Function: 一定要调用该方法来resolve这个钩子。执行效果依赖 next 方法的调用参数。
-
next(): 进行管道中的下一个钩子。如果全部钩子执行完了,则导航的状态就是confirmed(确认的)。 -
next(false): 中断当前的导航。如果浏览器的 URL 改变了 (可能是用户手动或者浏览器后退按钮),那么 URL 地址会重置到 from 路由对应的地址。 -
next('/') 或者 next({ path: '/' }): 跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。你可以向next 传递任意位置对象,且允许设置诸如replace: true、name: 'home' 之类的选项以及任何用在router-link的to prop或router.push中的选项。 -
next(error): (2.4.0+) 如果传入 next 的参数是一个 Error 实例,则导航会被终止且该错误会被传递给router.onError()注册过的回调。
确保要调用 next方法,否则钩子就不会被 resolved。
2、全局解析守卫:
2.5.0 新增
在 2.5.0+ 你可以用 router.beforeResolve 注册一个全局守卫。这和 router.beforeEach 类似,区别是:在导航被确认之前,同时在所有组件内守卫和异步路由组件被解析之后,解析守卫就被调用。
3、全局后置钩子
你也可以注册全局后置钩子,然而和守卫不同的是,这些钩子不会接受 next 函数也不会改变导航本身:
router.afterEach((to, from) => {
// ...
})4、路由独享的守卫
你可以在路由配置上直接定义 beforeEnter 守卫:
const router = new VueRouter({
routes: [
{
path: '/foo',
component: Foo,
beforeEnter: (to, from, next) => {
// ...
}
}
]
})这些守卫与全局前置守卫的方法参数是一样的。
5、组件内的守卫
最后,你可以在路由组件内直接定义以下路由导航守卫:
beforeRouteEnter
beforeRouteUpdate(2.2 新增)
beforeRouteLeave
const Foo = {
template: `...`,
beforeRouteEnter (to, from, next) {
// 在渲染该组件的对应路由被 confirm 前调用
// 不!能!获取组件实例 `this`
// 因为当守卫执行前,组件实例还没被创建
},
//不过,你可以通过传一个回调给 next来访问组件实例。
//在导航被确认的时候执行回调,并且把组件实例作为回调方法的参数。
beforeRouteEnter (to, from, next) {
next(vm => {
// 通过 `vm` 访问组件实例
})
},
beforeRouteUpdate (to, from, next) {
// 在当前路由改变,但是该组件被复用时调用
// 举例来说,对于一个带有动态参数的路径 /foo/:id,在 /foo/1 和 /foo/2 之间跳转的时候,
// 由于会渲染同样的 Foo 组件,因此组件实例会被复用。而这个钩子就会在这个情况下被调用。
// 可以访问组件实例 `this`
},
beforeRouteLeave (to, from, next) {
// 导航离开该组件的对应路由时调用
// 可以访问组件实例 `this`
}
}注意:beforeRouteEnter 是支持给next 传递回调的唯一守卫。对于beforeRouteUpdate 和 beforeRouteLeave 来说,this 已经可用了,所以不支持传递回调,因为没有必要了:
beforeRouteUpdate (to, from, next) {
// just use `this`
this.name = to.params.name
next()
}离开守卫beforeRouteLeave:通常用来禁止用户在还未保存修改前突然离开。该导航可以通过 next(false) 来取消:
beforeRouteLeave (to, from , next) {
const answer = window.confirm('Do you really want to leave? you have unsaved changes!')
if (answer) {
next()
} else {
next(false)
}
}16、vue路由hash模式和histroy模式实现原理分别是什么 区别是什么?
hash 模式:
#后面 hash 值的变化,不会导致浏览器向服务器发出请求,浏览器不发出请求,就不会刷新页面
通过监听 hashchange 事件可以知道 hash 发生了哪些变化,然后根据 hash 变化来实现更新页面部分内容的操作。
history 模式:
history 模式的实现,主要是 HTML5 标准发布的两个 API,pushState 和 replaceState,这两个 API 可以在改变 url,但是不会发送请求。这样就可以监听 url 变化来实现更新页面部分内容的操作
区别
url 展示上,hash 模式有“#”,history 模式没有
刷新页面时,hash 模式可以正常加载到 hash 值对应的页面,而 history 没有处理的话,会返回 404,一般需要后端将所有页面都配置重定向到首页路由
兼容性,hash 可以支持低版本浏览器和 IE。
17、说一下Vue的双向绑定数据的原理
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。我们先来看Object.defineProperty()这个方法:
![]()
var obj = {};
Object.defineProperty(obj, 'name', {
get: function() {
console.log('我被获取了')
return val;
},
set: function (newVal) {
console.log('我被设置了')
}
})
obj.name = 'fei';//在给obj设置name属性的时候,触发了set这个方法
var val = obj.name;//在得到obj的name属性,会触发get方法![]()
已经了解到vue是通过数据劫持的方式来做数据绑定的,其中最核心的方法便是通过Object.defineProperty()来实现对属性的劫持,那么在设置或者获取的时候我们就可以在get或者set方法里假如其他的触发函数,达到监听数据变动的目的,无疑这个方法是本文中最重要、最基础的内容之一。
2.实现最简单的双向绑定
我们知道通过Object.defineProperty()可以实现数据劫持,是的属性在赋值的时候触发set方法,
![]()
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<div id="demo"></div>
<input type="text" id="inp">
<script>
var obj = {};
var demo = document.querySelector('#demo')
var inp = document.querySelector('#inp')
Object.defineProperty(obj, 'name', {
get: function() {
return val;
},
set: function (newVal) {//当该属性被赋值的时候触发
inp.value = newVal;
demo.innerHTML = newVal;
}
})
inp.addEventListener('input', function(e) {
// 给obj的name属性赋值,进而触发该属性的set方法
obj.name = e.target.value;
});
obj.name = 'fei';//在给obj设置name属性的时候,触发了set这个方法
</script>
</body>
</html>![]()
当然要是这么粗暴,肯定不行,性能会出很多的问题。
3.讲解vue如何实现
先看原理图
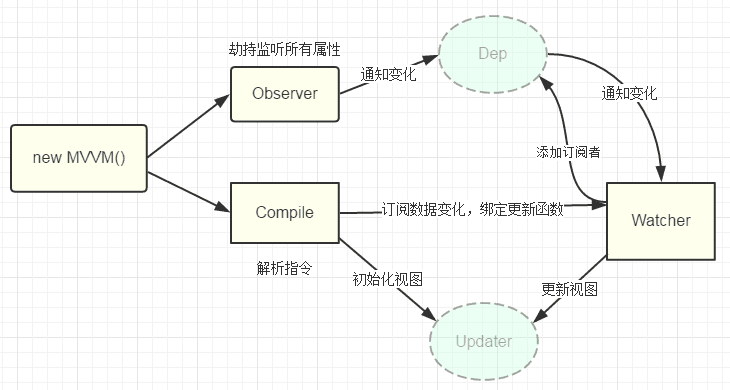
3.1 observer用来实现对每个vue中的data中定义的属性循环用Object.defineProperty()实现数据劫持,以便利用其中的setter和getter,然后通知订阅者,订阅者会触发它的update方法,对视图进行更新。
3.2 我们介绍为什么要订阅者,在vue中v-model,v-name,{{}}等都可以对数据进行显示,也就是说假如一个属性都通过这三个指令了,那么每当这个属性改变的时候,相应的这个三个指令的html视图也必须改变,于是vue中就是每当有这样的可能用到双向绑定的指令,就在一个Dep中增加一个订阅者,其订阅者只是更新自己的指令对应的数据,也就是v-model='name'和{{name}}有两个对应的订阅者,各自管理自己的地方。每当属性的set方法触发,就循环更新Dep中的订阅者。
4.vue代码实现
4.1 observer实现,主要是给每个vue的属性用Object.defineProperty(),代码如下:
![]()
function defineReactive (obj, key, val) {
var dep = new Dep();
Object.defineProperty(obj, key, {
get: function() {
//添加订阅者watcher到主题对象Dep
if(Dep.target) {
// JS的浏览器单线程特性,保证这个全局变量在同一时间内,只会有同一个监听器使用
dep.addSub(Dep.target);
}
return val;
},
set: function (newVal) {
if(newVal === val) return;
val = newVal;
console.log(val);
// 作为发布者发出通知
dep.notify();//通知后dep会循环调用各自的update方法更新视图
}
})
}
function observe(obj, vm) {
Object.keys(obj).forEach(function(key) {
defineReactive(vm, key, obj[key]);
})
}4.2实现compile:
compile的目的就是解析各种指令称真正的html。
![]()
function Compile(node, vm) {
if(node) {
this.$frag = this.nodeToFragment(node, vm);
return this.$frag;
}
}
Compile.prototype = {
nodeToFragment: function(node, vm) {
var self = this;
var frag = document.createDocumentFragment();
var child;
while(child = node.firstChild) {
console.log([child])
self.compileElement(child, vm);
frag.append(child); // 将所有子节点添加到fragment中
}
return frag;
},
compileElement: function(node, vm) {
var reg = /\{\{(.*)\}\}/;
//节点类型为元素(input元素这里)
if(node.nodeType === 1) {
var attr = node.attributes;
// 解析属性
for(var i = 0; i < attr.length; i++ ) {
if(attr[i].nodeName == 'v-model') {//遍历属性节点找到v-model的属性
var name = attr[i].nodeValue; // 获取v-model绑定的属性名
node.addEventListener('input', function(e) {
// 给相应的data属性赋值,进而触发该属性的set方法
vm[name]= e.target.value;
});
new Watcher(vm, node, name, 'value');//创建新的watcher,会触发函数向对应属性的dep数组中添加订阅者,
}
};
}
//节点类型为text
if(node.nodeType === 3) {
if(reg.test(node.nodeValue)) {
var name = RegExp.$1; // 获取匹配到的字符串
name = name.trim();
new Watcher(vm, node, name, 'nodeValue');
}
}
}
}![]()
4.3 watcher实现
![]()
function Watcher(vm, node, name, type) {
Dep.target = this;
this.name = name;
this.node = node;
this.vm = vm;
this.type = type;
this.update();
Dep.target = null;
}
Watcher.prototype = {
update: function() {
this.get();
this.node[this.type] = this.value; // 订阅者执行相应操作
},
// 获取data的属性值
get: function() {
console.log(1)
this.value = this.vm[this.name]; //触发相应属性的get
}
}![]()
4.4 实现Dep来为每个属性添加订阅者
![]()
function Dep() {
this.subs = [];
}
Dep.prototype = {
addSub: function(sub) {
this.subs.push(sub);
},
notify: function() {
this.subs.forEach(function(sub) {
sub.update();
})
}
}![]()
这样一来整个数据的双向绑定就完成了。
5.梳理
首先我们为每个vue属性用Object.defineProperty()实现数据劫持,为每个属性分配一个订阅者集合的管理数组dep;然后在编译的时候在该属性的数组dep中添加订阅者,v-model会添加一个订阅者,{{}}也会,v-bind也会,只要用到该属性的指令理论上都会,接着为input会添加监听事件,修改值就会为该属性赋值,触发该属性的set方法,在set方法内通知订阅者数组dep,订阅者数组循环调用各订阅者的update方法更新视图。
18、解释单向数据流和双向数据绑定
一:单向数据流
单向数据流的意思是指数据的改变只能从一个方向修改。
举个栗子:如一个父组件有两个子组件,分别为1和2。父组件向子组件传递数据,两个组件都接收到了父组件传递过来的数据,在组件1中修改父组件传递过来的数据,子组件2和父组件的值不会发生变化。这就是单向的数据流,子组件不能直接改变父组件的状态。但是如果父组件改变相应的数据,两个子组件的数据也会发生相应的改变。
二:双向数据绑定
由MVVM框架实现,MVVM的组成:View,ViewModel,Model。其中View 和 Model不能直接通信,要通过ViewModel来进行通信。
举个栗子:例如,当Model部分数据发生改变时,由于vue中Data Binding将底层数据和Dom层进行了绑定,ViewModel通知View层更新视图;当在视图 View数据发生变化也会同步到Model中。View和Model之间的同步完全是自动的,不需要人手动的操作DOM。
19、Vue 如何去除url中的 #
vue-router` 默认使用 `hash` 模式,所以在路由加载的时候,项目中的 `url` 会自带 `#`。如果不想使用 `#`, 可以使用 `vue-router` 的另一种模式 `history
new Router({
mode: 'history',
base: process.env.BASE_URL,
routes
})需要注意的是,当我们启用 history 模式的时候,由于我们的项目是一个单页面应用,所以在路由跳转的时候,就会出现访问不到静态资源而出现 404 的情况,这时候就需要服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面。
20、对 MVC、MVVM的理解
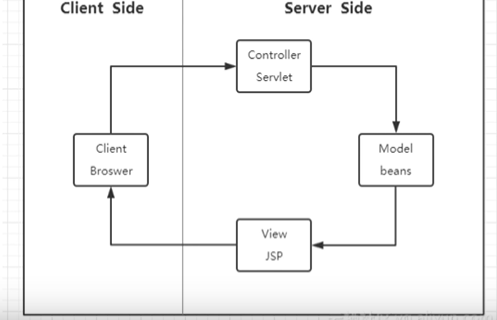
一、早期的mvc
早期的页面通常由多个PHP,jsp文件构成,这种代码难以维护,于是延伸了mvc开发模式和框架,前端展示以模板的形式出现,典型的框架如spring等,这种分成结构职责清晰,代码易于维护,但这里的mvc仅仅限于后端,前后端形成了一定的分离,前端只完成了开发成中的view层
缺点
1前端页面开发效率不高
2前后端职责不清晰
二、前端mvc
随着ajax的发展,前端得到进一步发展,前端的类库也开始发展最著名的就是jq,因此前端mvc随之而来
与后端类似,具有view,controller,model,mvc模式是单项绑定,即model绑定到view,当我们用js代码更新model时,view就会自动更新
model负责数据保存,与后端数据进行同步
controller负责业务逻辑,根据用户行为对model数据进行修改
view负责视图展示,将model中的数据可视化出来
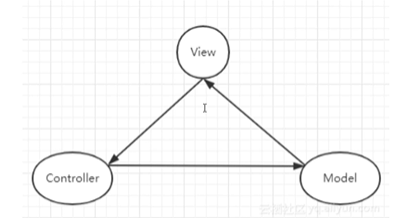
缺点:强行分层,一个小小的功能都必须经过这么一个流程,并不灵活
mvvm的出现