基于机器学习与深度学习的贷款批准预测
1.项目背景
该数据集源自Kaggle的“Playground Series - Season 4, Episode 10”竞赛,是通过在贷款批准预测数据集上训练的深度学习模型生成的数据,旨在使用借款人信息预测贷款批准结果,它通过模拟真实贷款审批场景,帮助金融机构评估借款人风险。
2.数据说明
| 字段名 | 说明 |
|---|---|
| id | 样本ID |
| person_age | 借款人年龄(岁) |
| person_income | 借款人年收入(美元) |
| person_home_ownership | 借款人房屋拥有情况,取值为:RENT(租房)、OWN(拥有)、MORTGAGE(按揭)、OTHER(其他) |
| person_emp_length | 借款人工作年限(年) |
| loan_intent | 贷款意图,取值包括:EDUCATION(教育)、MEDICAL(医疗)、PERSONAL(个人消费)、VENTURE(创业)、DEBTCONSOLIDATION(债务整合)、HOMEIMPROVEMENT(家庭改善) |
| loan_grade | 贷款信用等级,从A到G表示不同的信用等级,一般来说A是最好的,依次递减 |
| loan_amnt | 贷款金额(美元) |
| loan_int_rate | 贷款利率(百分比) |
| loan_percent_income | 贷款金额占收入的比例 |
| cb_person_default_on_file | 是否有违约记录(Y:有,N:无) |
| cb_person_cred_hist_length | 信用历史长度(年) |
| loan_status | 是否获得贷款批准(0:未获得,1:获得) |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import chi2_contingency,ks_2samp,spearmanr,f_oneway
from scipy import stats
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report,confusion_matrix,roc_curve, auc
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.optimizers import Adam
import shap
train_data = pd.read_csv('/home/mw/input/data9293/train.csv')
test_data = pd.read_csv('/home/mw/input/data9293/test.csv')
4.数据预览
print('训练集信息:')
print(train_data.info())
训练集信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 58645 entries, 0 to 58644
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 58645 non-null int64
1 person_age 58645 non-null int64
2 person_income 58645 non-null int64
3 person_home_ownership 58645 non-null object
4 person_emp_length 58645 non-null float64
5 loan_intent 58645 non-null object
6 loan_grade 58645 non-null object
7 loan_amnt 58645 non-null int64
8 loan_int_rate 58645 non-null float64
9 loan_percent_income 58645 non-null float64
10 cb_person_default_on_file 58645 non-null object
11 cb_person_cred_hist_length 58645 non-null int64
12 loan_status 58645 non-null int64
dtypes: float64(3), int64(6), object(4)
memory usage: 5.8+ MB
None
print('测试集信息:')
print(test_data.info())
测试集信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 39098 entries, 0 to 39097
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 39098 non-null int64
1 person_age 39098 non-null int64
2 person_income 39098 non-null int64
3 person_home_ownership 39098 non-null object
4 person_emp_length 39098 non-null float64
5 loan_intent 39098 non-null object
6 loan_grade 39098 non-null object
7 loan_amnt 39098 non-null int64
8 loan_int_rate 39098 non-null float64
9 loan_percent_income 39098 non-null float64
10 cb_person_default_on_file 39098 non-null object
11 cb_person_cred_hist_length 39098 non-null int64
dtypes: float64(3), int64(5), object(4)
memory usage: 3.6+ MB
None
# 查看重复值
print(f'训练集中存在的重复值:{train_data.duplicated().sum()}')
print(f'测试集中存在的重复值:{test_data.duplicated().sum()}')
训练集中存在的重复值:0
测试集中存在的重复值:0
# 查看分类特征的唯一值
characteristic = train_data.select_dtypes(include=['object']).columns
print('训练集中分类变量的唯一值情况:')
for i in characteristic:
print(f'{i}:')
print(f'共有:{len(train_data[i].unique())}条唯一值')
print(train_data[i].unique())
print('-'*50)
训练集中分类变量的唯一值情况:
person_home_ownership:
共有:4条唯一值
['RENT' 'OWN' 'MORTGAGE' 'OTHER']
--------------------------------------------------
loan_intent:
共有:6条唯一值
['EDUCATION' 'MEDICAL' 'PERSONAL' 'VENTURE' 'DEBTCONSOLIDATION'
'HOMEIMPROVEMENT']
--------------------------------------------------
loan_grade:
共有:7条唯一值
['B' 'C' 'A' 'D' 'E' 'F' 'G']
--------------------------------------------------
cb_person_default_on_file:
共有:2条唯一值
['N' 'Y']
--------------------------------------------------
#绘制箱线图来观察是否存在异常值
# 定义特征及其中文名称映射
feature_map = {
'person_age': '借款人年龄',
'person_income': '借款人年收入',
'person_emp_length': '借款人工作年限',
'loan_amnt': '贷款金额',
'loan_int_rate': '贷款利率(百分比)',
'loan_percent_income': '贷款金额占收入的比例',
'cb_person_cred_hist_length': '信用历史长度(年)'
}
plt.figure(figsize=(20, 15))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(2, 4, i)
sns.boxplot(y=train_data[col])
plt.title(f'训练集中{col_name}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
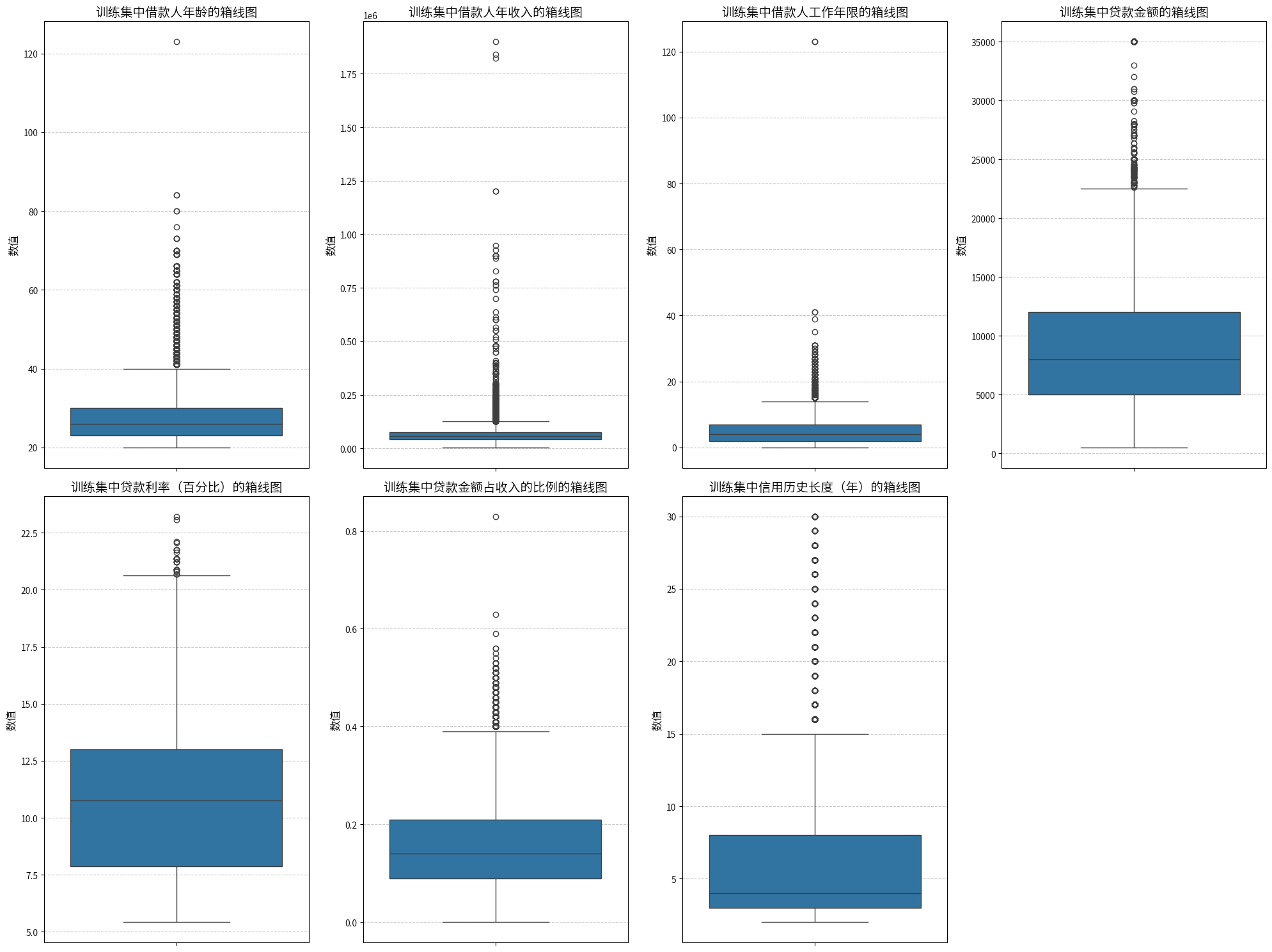
plt.figure(figsize=(20, 15))
for i, (col, col_name) in enumerate(feature_map.items(), 1):
plt.subplot(2, 4, i)
sns.boxplot(y=test_data[col])
plt.title(f'测试集中{col_name}的箱线图', fontsize=14)
plt.ylabel('数值', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
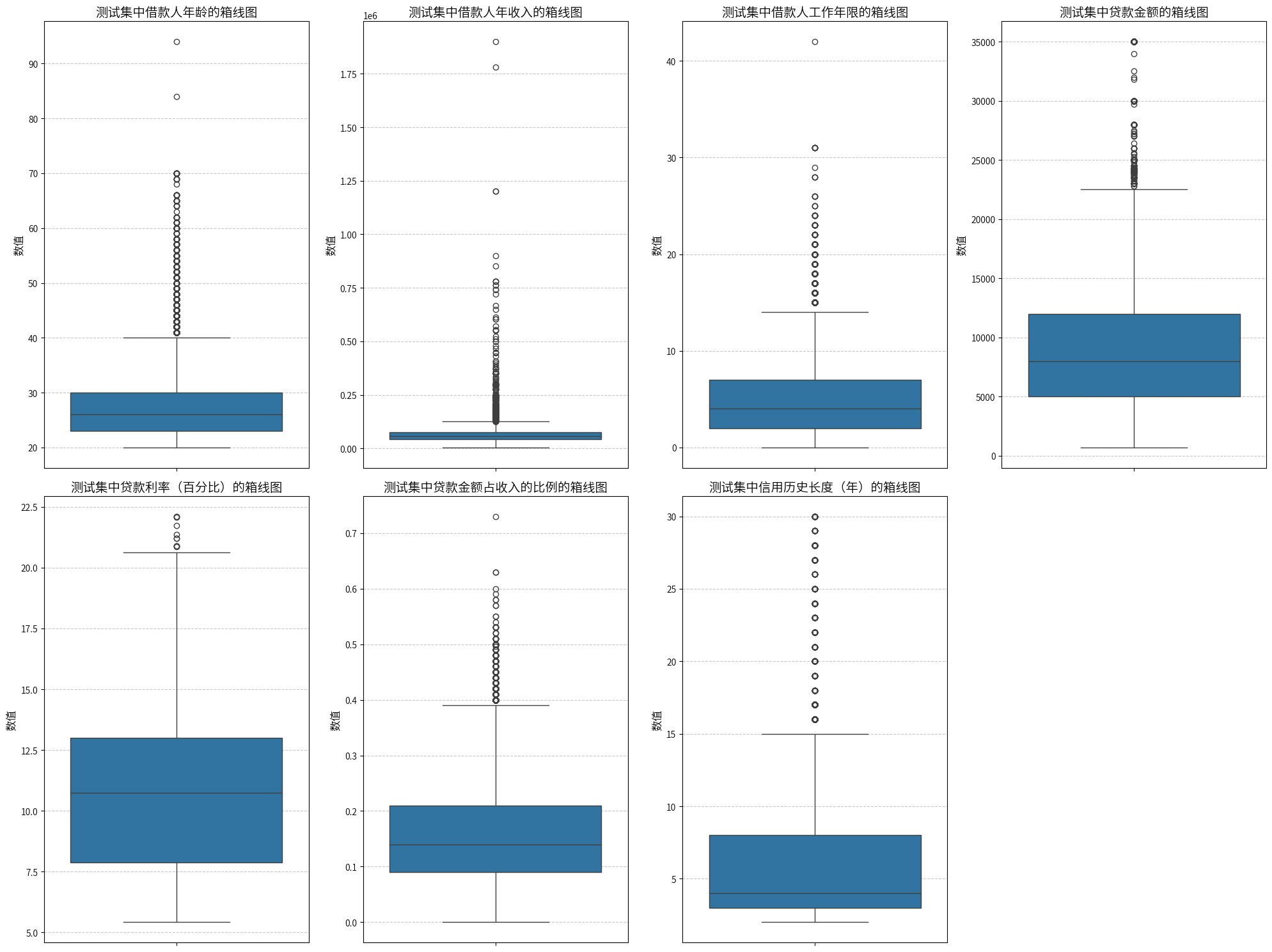
通过训练集和测试集的对比,不难发现在训练集中存在一些异常值,比如训练集中出现了120岁以上的年龄,而测试集最大年龄约为95岁,因此120岁以上的年龄在训练集中可能是异常值,并且在工作年限那里,有人的竟然工作了120年!肯定是不正确的,其他的看起来没啥问题,虽然存在一些比较高的特殊值,但是也是在生活中可能出现的,接下来,还要检查数据中逻辑是否有问题,即工作年限和年龄的关系,还有计算贷款金额和收入占比的比例是否正确等等。
# 使用"person_age"和"person_emp_length"筛选出年龄超过120岁或工作年限超过120年的异常数据
abnormal_data = train_data[(train_data['person_age'] > 120) | (train_data['person_emp_length'] > 120)]
abnormal_data
| id | person_age | person_income | person_home_ownership | person_emp_length | loan_intent | loan_grade | loan_amnt | loan_int_rate | loan_percent_income | cb_person_default_on_file | cb_person_cred_hist_length | loan_status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 41079 | 41079 | 28 | 60350 | MORTGAGE | 123.0 | MEDICAL | D | 25000 | 15.95 | 0.35 | Y | 6 | 1 |
| 47336 | 47336 | 123 | 36000 | MORTGAGE | 7.0 | PERSONAL | B | 6700 | 10.75 | 0.18 | N | 4 | 0 |
| 49252 | 49252 | 21 | 192000 | MORTGAGE | 123.0 | VENTURE | B | 20000 | 11.49 | 0.10 | N | 2 | 0 |
- ID为41079和49252的年龄分别为28和21岁,但工作年限为123年,存在明显异常。
- ID为47336的年龄为123岁,但工作年限为7年,也属于异常数据。
# 删除年龄超过120或工作年限超过120的记录
train_data = train_data[(train_data['person_age'] <= 120) & (train_data['person_emp_length'] <= 120)]
train_age_emp = train_data.copy()
train_age_emp['age_minus_emp_length'] = train_age_emp['person_age'] - train_age_emp['person_emp_length']
train_age_emp['age_minus_emp_length'].describe()
count 58642.000000
mean 22.852392
std 6.755495
min 2.000000
25% 17.000000
50% 22.000000
75% 26.000000
max 82.000000
Name: age_minus_emp_length, dtype: float64
好家伙,年龄与工龄之差的最小值竟然是2,最大值是82,明显不符合实际情况,看看测试集是啥情况。
test_age_emp = test_data.copy()
test_age_emp['age_minus_emp_length'] = test_age_emp['person_age'] - test_age_emp['person_emp_length']
test_age_emp['age_minus_emp_length'].describe()
count 39098.000000
mean 22.879713
std 6.774023
min 2.000000
25% 17.000000
50% 22.000000
75% 26.000000
max 92.000000
Name: age_minus_emp_length, dtype: float64
好家伙,同样出现了年龄与工龄之差的最小值是2,而且最大值是92,同样不符合实际情况。
for i in range(8,19):
abnormal_age_emp_difference_train_under_count = train_age_emp[train_age_emp['age_minus_emp_length'] < i].shape[0]
abnormal_age_emp_difference_test_under_count = test_age_emp[test_age_emp['age_minus_emp_length'] < i].shape[0]
print(f"训练集中年龄与工龄之差在{i}以下的数据有{abnormal_age_emp_difference_train_under_count}条,占比{round(abnormal_age_emp_difference_train_under_count/len(train_age_emp)*100,2)}%")
print(f"测试集中年龄与工龄之差在{i}以下的数据有{abnormal_age_emp_difference_test_under_count}条,占比{round(abnormal_age_emp_difference_test_under_count/len(test_age_emp)*100,2)}%")
print('-'*50)
训练集中年龄与工龄之差在8以下的数据有5条,占比0.01%
测试集中年龄与工龄之差在8以下的数据有10条,占比0.03%
--------------------------------------------------
训练集中年龄与工龄之差在9以下的数据有7条,占比0.01%
测试集中年龄与工龄之差在9以下的数据有11条,占比0.03%
--------------------------------------------------
训练集中年龄与工龄之差在10以下的数据有10条,占比0.02%
测试集中年龄与工龄之差在10以下的数据有12条,占比0.03%
--------------------------------------------------
训练集中年龄与工龄之差在11以下的数据有11条,占比0.02%
测试集中年龄与工龄之差在11以下的数据有12条,占比0.03%
--------------------------------------------------
训练集中年龄与工龄之差在12以下的数据有14条,占比0.02%
测试集中年龄与工龄之差在12以下的数据有14条,占比0.04%
--------------------------------------------------
训练集中年龄与工龄之差在13以下的数据有21条,占比0.04%
测试集中年龄与工龄之差在13以下的数据有15条,占比0.04%
--------------------------------------------------
训练集中年龄与工龄之差在14以下的数据有26条,占比0.04%
测试集中年龄与工龄之差在14以下的数据有20条,占比0.05%
--------------------------------------------------
训练集中年龄与工龄之差在15以下的数据有48条,占比0.08%
测试集中年龄与工龄之差在15以下的数据有37条,占比0.09%
--------------------------------------------------
训练集中年龄与工龄之差在16以下的数据有980条,占比1.67%
测试集中年龄与工龄之差在16以下的数据有619条,占比1.58%
--------------------------------------------------
训练集中年龄与工龄之差在17以下的数据有13692条,占比23.35%
测试集中年龄与工龄之差在17以下的数据有9117条,占比23.32%
--------------------------------------------------
训练集中年龄与工龄之差在18以下的数据有15332条,占比26.15%
测试集中年龄与工龄之差在18以下的数据有10184条,占比26.05%
--------------------------------------------------
初步观察,发现差值在16以下占比比较少,可以认定满16岁就可以开始工作,也就是“年龄-工龄”不能小于16。
for i in range(30, 60, 10):
abnormal_age_emp_difference_train_above_count = train_age_emp[train_age_emp['age_minus_emp_length'] > i].shape[0]
abnormal_age_emp_difference_test_above_count = test_age_emp[test_age_emp['age_minus_emp_length'] > i].shape[0]
print(f"训练集中年龄与工龄之差在{i}以上的数据有{abnormal_age_emp_difference_train_above_count}条,占比{round(abnormal_age_emp_difference_train_above_count/len(train_age_emp)*100,2)}%")
print(f"测试集中年龄与工龄之差在{i}以上的数据有{abnormal_age_emp_difference_test_above_count}条,占比{round(abnormal_age_emp_difference_test_above_count/len(test_age_emp)*100,2)}%")
print('-'*50)
训练集中年龄与工龄之差在30以上的数据有6994条,占比11.93%
测试集中年龄与工龄之差在30以上的数据有4692条,占比12.0%
--------------------------------------------------
训练集中年龄与工龄之差在40以上的数据有1217条,占比2.08%
测试集中年龄与工龄之差在40以上的数据有820条,占比2.1%
--------------------------------------------------
训练集中年龄与工龄之差在50以上的数据有288条,占比0.49%
测试集中年龄与工龄之差在50以上的数据有196条,占比0.5%
--------------------------------------------------
初步观察,发现差值40岁以上占比比较少,可以认定“年龄-工龄”不能大于40,现在开始处理,针对差值小于16的,采用“调整后的年龄 = 现有年龄 + (16 - 差值)”,针对差值大于40的,采用“调整后的工龄 = 现有工龄 + (差值 - 40)”。
# 定义一个函数来调整年龄和工龄
def adjust_age_and_emp_length(df):
# 计算年龄减工龄的差值
df['age_minus_emp_length'] = df['person_age'] - df['person_emp_length']
# 差值小于16:增加年龄
df.loc[df['age_minus_emp_length'] < 16, 'person_age'] += 16 - df['age_minus_emp_length']
# 差值大于40:增加工龄
df.loc[df['age_minus_emp_length'] > 40, 'person_emp_length'] += df['age_minus_emp_length'] - 40
# 重新计算“年龄减工龄”的差值,以验证调整效果
df['age_minus_emp_length'] = df['person_age'] - df['person_emp_length']
return df
train_age_emp = adjust_age_and_emp_length(train_age_emp)
print(f"处理后的训练集中年龄与工龄之差小于16的数据有{train_age_emp[train_age_emp['age_minus_emp_length'] < 16].shape[0]}条,大于40的数据有{train_age_emp[train_age_emp['age_minus_emp_length'] > 40].shape[0]}条")
train_data['person_age'] = train_age_emp['person_age']
train_data['person_emp_length'] = train_age_emp['person_emp_length']
处理后的训练集中年龄与工龄之差小于16的数据有0条,大于40的数据有0条
test_age_emp = adjust_age_and_emp_length(test_age_emp)
print(f"处理后的测试集中年龄与工龄之差小于16的数据有{test_age_emp[test_age_emp['age_minus_emp_length'] < 16].shape[0]}条,大于40的数据有{test_age_emp[test_age_emp['age_minus_emp_length'] > 40].shape[0]}条")
test_data['person_age'] = test_age_emp['person_age']
test_data['person_emp_length'] = test_age_emp['person_emp_length']
处理后的测试集中年龄与工龄之差小于16的数据有0条,大于40的数据有0条
train_age_emp['age_minus_hist_length'] = train_age_emp['person_age'] - train_age_emp['cb_person_cred_hist_length']
test_age_emp['age_minus_hist_length'] = test_age_emp['person_age'] - test_age_emp['cb_person_cred_hist_length']
train_age_emp['age_minus_hist_length'].describe()
count 58642.000000
mean 21.755022
std 3.158081
min -1.000000
25% 20.000000
50% 21.000000
75% 23.000000
max 62.000000
Name: age_minus_hist_length, dtype: float64
又出现异常值了,经过处理后的年龄和信用历史长度的差值,竟然出现了负数,明显不符合常理,看一下测试集有没有异常。
test_age_emp['age_minus_hist_length'].describe()
count 39098.000000
mean 21.755716
std 3.154762
min 7.000000
25% 20.000000
50% 21.000000
75% 23.000000
max 67.000000
Name: age_minus_hist_length, dtype: float64
还好,测试集这里相对正常,那么针对训练集中差值小于7的视为异常值,查看训练集中差值小于7的数据。
print(f"查看训练集中差值小于7的数据有{train_age_emp[train_age_emp['age_minus_hist_length'] < 7].shape[0]}条")
查看训练集中差值小于7的数据有1条
还好,只有一条数据是小于7的,就是那一条负数了,这里直接删除这条数据。
train_age_emp[train_age_emp['age_minus_hist_length'] < 7]
| id | person_age | person_income | person_home_ownership | person_emp_length | loan_intent | loan_grade | loan_amnt | loan_int_rate | loan_percent_income | cb_person_default_on_file | cb_person_cred_hist_length | loan_status | age_minus_emp_length | age_minus_hist_length | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21827 | 21827 | 28 | 186480 | MORTGAGE | 2.0 | PERSONAL | A | 10000 | 5.42 | 0.05 | N | 29 | 0 | 26.0 | -1 |
直接在原始数据中删除Id21827这条数据。
train_data = train_data[train_data['id'] != 21827]
至于贷款金额和收入占比的比例,这里也不验证了,肯定有错误的,毕竟从之前分析年龄>120的数据,算了一下就发现有问题,这里直接重新计算并且替换吧。
train_data['loan_percent_income'] = round(train_data['loan_amnt'] / train_data['person_income'],2)
test_data['loan_percent_income'] = round(test_data['loan_amnt'] / test_data['person_income'],2)
5.一致性检验
5.1可视化分析
# 添加一个列来区分训练集和测试集
train_data['dataset'] = 'train'
test_data['dataset'] = 'test'
# 合并数据
combined_df = pd.concat([train_data, test_data], ignore_index=True)
plt.figure(figsize=(20,15))
plt.subplot(3,4,1)
sns.kdeplot(data=combined_df, x='person_age', hue='dataset', common_norm=False)
plt.title(f'借款人年龄在训练集和测试集核密度分布图')
plt.xlabel('借款人年龄')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,2)
sns.kdeplot(data=combined_df, x='person_income', hue='dataset', common_norm=False)
plt.title(f'借款人年收入在训练集和测试集核密度分布图')
plt.xlabel('借款人年收入(美元)')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,3)
person_home_ownership_counts = combined_df.groupby(['dataset', 'person_home_ownership']).size().unstack()
person_home_ownership_proportions = person_home_ownership_counts.div(person_home_ownership_counts.sum(axis=1), axis=0)
person_home_ownership_proportions.plot(kind='bar', stacked=True, ax=plt.gca())
plt.title(f'借款人房屋拥有情况在训练集和测试集中占比分布')
plt.xlabel('数据集')
plt.xticks(rotation=0)
plt.legend(loc='upper right')
plt.ylabel('占比')
plt.subplot(3,4,4)
sns.kdeplot(data=combined_df, x='person_emp_length', hue='dataset', common_norm=False)
plt.title(f'借款人工作年限在训练集和测试集核密度分布图')
plt.xlabel('借款人工作年限')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,5)
loan_intent_counts = combined_df.groupby(['dataset', 'loan_intent']).size().unstack()
loan_intent_proportions = loan_intent_counts.div(loan_intent_counts.sum(axis=1), axis=0)
loan_intent_proportions.plot(kind='bar', stacked=True, ax=plt.gca())
plt.title(f'贷款意图在训练集和测试集中占比分布')
plt.xlabel('数据集')
plt.xticks(rotation=0)
plt.legend(loc='upper right')
plt.ylabel('占比')
plt.subplot(3,4,6)
loan_grade_counts = combined_df.groupby(['dataset', 'loan_grade']).size().unstack()
loan_grade_proportions = loan_grade_counts.div(loan_grade_counts.sum(axis=1), axis=0)
loan_grade_proportions.plot(kind='bar', stacked=True, ax=plt.gca())
plt.title(f'贷款信用等级在训练集和测试集中占比分布')
plt.xlabel('数据集')
plt.xticks(rotation=0)
plt.legend(loc='upper right')
plt.ylabel('占比')
plt.subplot(3,4,7)
sns.kdeplot(data=combined_df, x='loan_amnt', hue='dataset', common_norm=False)
plt.title(f'贷款金额在训练集和测试集核密度分布图')
plt.xlabel('贷款金额(美元)')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,8)
sns.kdeplot(data=combined_df, x='loan_int_rate', hue='dataset', common_norm=False)
plt.title(f'贷款利率在训练集和测试集核密度分布图')
plt.xlabel('贷款利率(百分比)')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,9)
sns.kdeplot(data=combined_df, x='loan_percent_income', hue='dataset', common_norm=False)
plt.title(f'贷款金额占收入的比例在训练集和测试集核密度分布图')
plt.xlabel('贷款金额占收入的比例')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.subplot(3,4,10)
cb_person_default_on_file_counts = combined_df.groupby(['dataset', 'cb_person_default_on_file']).size().unstack()
cb_person_default_on_file_proportions = cb_person_default_on_file_counts.div(cb_person_default_on_file_counts.sum(axis=1), axis=0)
cb_person_default_on_file_proportions.plot(kind='bar', stacked=True, ax=plt.gca())
plt.title(f'违约记录情况在训练集和测试集中占比分布')
plt.xlabel('数据集')
plt.xticks(rotation=0)
plt.legend(loc='upper right')
plt.ylabel('占比')
plt.subplot(3,4,11)
sns.kdeplot(data=combined_df, x='cb_person_cred_hist_length', hue='dataset', common_norm=False)
plt.title(f'信用历史长度在训练集和测试集核密度分布图')
plt.xlabel('信用历史长度(年)')
plt.ylabel('密度')
plt.legend(title='数据集', labels=['train', 'test'])
plt.tight_layout()
plt.show()
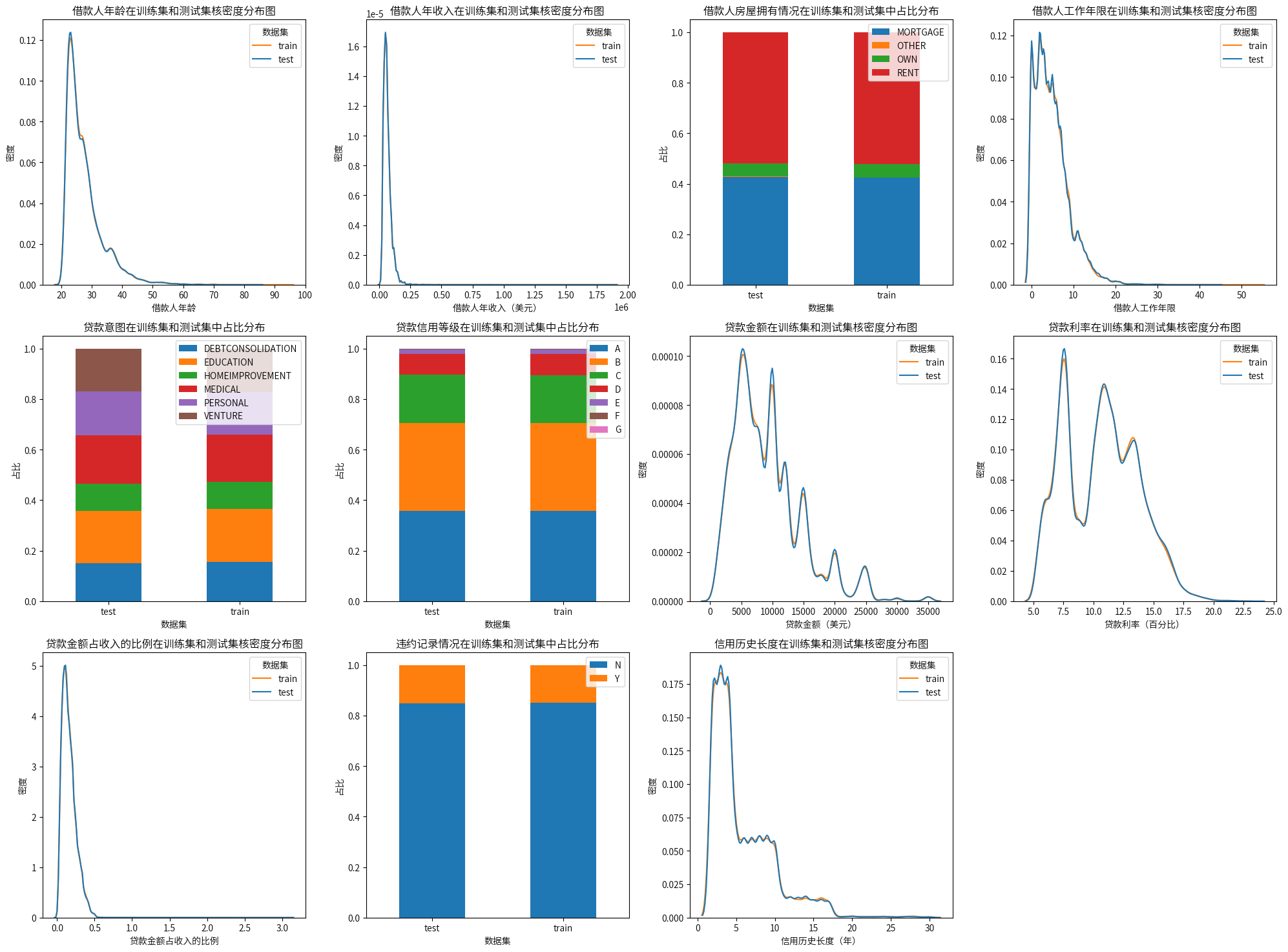
# 删除训练集和测试集中的 dataset 列
train_data.drop(columns=['dataset'], inplace=True)
test_data.drop(columns=['dataset'], inplace=True)
5.2KS检验
numerical_features = test_data.select_dtypes(include=['int64','float64']).columns[1:]
results = []
for feature in numerical_features:
statistic, p_value = ks_2samp(train_data[feature], test_data[feature])
results.append({'Feature': feature,'Statistic': statistic, 'p-value': p_value})
results_df = pd.DataFrame(results)
results_df
| Feature | Statistic | p-value | |
|---|---|---|---|
| 0 | person_age | 0.004581 | 0.706661 |
| 1 | person_income | 0.004998 | 0.599303 |
| 2 | person_emp_length | 0.002911 | 0.988323 |
| 3 | loan_amnt | 0.004335 | 0.768399 |
| 4 | loan_int_rate | 0.004306 | 0.775348 |
| 5 | loan_percent_income | 0.006015 | 0.362652 |
| 6 | cb_person_cred_hist_length | 0.003013 | 0.983011 |
5.3卡方检验
results = []
categorical_features = train_data.select_dtypes(include=['object']).columns
for feature in categorical_features:
table = pd.crosstab(train_data[feature], test_data[feature])
chi2, p, dof, expected = chi2_contingency(table)
results.append({'Feature': feature, 'Statistic': chi2, 'p-value': p})
results_df = pd.DataFrame(results)
results_df
| Feature | Statistic | p-value | |
|---|---|---|---|
| 0 | person_home_ownership | 12.949284 | 0.164915 |
| 1 | loan_intent | 22.602336 | 0.600772 |
| 2 | loan_grade | 15.462160 | 0.998897 |
| 3 | cb_person_default_on_file | 0.145298 | 0.703070 |
综上所述,可以认为训练集和测试集在特征分布上是一致的,因此可以只对训练集进行进一步的分析和模型训练,将简化分析过程,并确保模型在测试集上的评估具有代表性。
6.描述性分析
train_data.describe(include='all')
| id | person_age | person_income | person_home_ownership | person_emp_length | loan_intent | loan_grade | loan_amnt | loan_int_rate | loan_percent_income | cb_person_default_on_file | cb_person_cred_hist_length | loan_status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 58641.000000 | 58641.000000 | 5.864100e+04 | 58641 | 58641.000000 | 58641 | 58641 | 58641.000000 | 58641.000000 | 58641.000000 | 58641 | 58641.000000 | 58641.000000 |
| unique | NaN | NaN | NaN | 4 | NaN | 6 | 7 | NaN | NaN | NaN | 2 | NaN | NaN |
| top | NaN | NaN | NaN | RENT | NaN | EDUCATION | A | NaN | NaN | NaN | N | NaN | NaN |
| freq | NaN | NaN | NaN | 30594 | NaN | 12271 | 20983 | NaN | NaN | NaN | 49940 | NaN | NaN |
| mean | 29321.280265 | 27.568664 | 6.404244e+04 | NaN | 4.842499 | NaN | NaN | 9217.133098 | 10.677859 | 0.159707 | NaN | 5.813254 | 0.142375 |
| std | 16929.613591 | 6.016827 | 3.792517e+04 | NaN | 4.040348 | NaN | NaN | 5563.426567 | 3.034643 | 0.094312 | NaN | 4.028158 | 0.349437 |
| min | 0.000000 | 20.000000 | 4.200000e+03 | NaN | 0.000000 | NaN | NaN | 500.000000 | 5.420000 | 0.000000 | NaN | 2.000000 | 0.000000 |
| 25% | 14660.000000 | 23.000000 | 4.200000e+04 | NaN | 2.000000 | NaN | NaN | 5000.000000 | 7.880000 | 0.090000 | NaN | 3.000000 | 0.000000 |
| 50% | 29321.000000 | 26.000000 | 5.800000e+04 | NaN | 4.000000 | NaN | NaN | 8000.000000 | 10.750000 | 0.140000 | NaN | 4.000000 | 0.000000 |
| 75% | 43982.000000 | 30.000000 | 7.560000e+04 | NaN | 7.000000 | NaN | NaN | 12000.000000 | 12.990000 | 0.210000 | NaN | 8.000000 | 0.000000 |
| max | 58644.000000 | 84.000000 | 1.900000e+06 | NaN | 44.000000 | NaN | NaN | 35000.000000 | 23.220000 | 3.120000 | NaN | 30.000000 | 1.000000 |
- 借款人群体较年轻,主要是租房者,可能反映了年轻人对贷款的需求较高。
- 教育是最常见的贷款目的,这可能与年轻的借款人群体特征相关。
- 大多数借款人拥有较好的信用评级(A级最多),且大部分没有违约记录。
- 贷款批准率是14%。
7.贷款获批的影响因素分析
7.1可视化分析
plt.figure(figsize=(20,12))
plt.subplot(2,3,1)
sns.boxplot(x=train_data['loan_status'],y=train_data['person_age'])
plt.title('年龄与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('借款人年龄')
plt.subplot(2,3,2)
sns.boxplot(x=train_data['loan_status'],y=train_data['person_income'])
plt.title('年收入与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('借款人年收入(美元)')
plt.subplot(2,3,3)
sns.boxplot(x=train_data['loan_status'],y=train_data['person_emp_length'])
plt.title('工作年限与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('借款人工作年限')
ownership_and_loan = pd.crosstab(train_data['person_home_ownership'], train_data['loan_status'])
ownership_and_loan_percent = ownership_and_loan.div(ownership_and_loan.sum(axis=1), axis=0) * 100
ax4 = plt.subplot(2,3,(4,6))
ownership_and_loan_percent[1].plot(kind='bar',ax=ax4)
plt.title('房屋拥有情况与贷款批准情况的关系')
plt.xlabel('借款人房屋拥有情况')
plt.ylabel('贷款批准率')
plt.xticks(rotation=0)
for p in ax4.patches:
ax4.annotate(f"{p.get_height():.1f}%", (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.tight_layout()
plt.show()
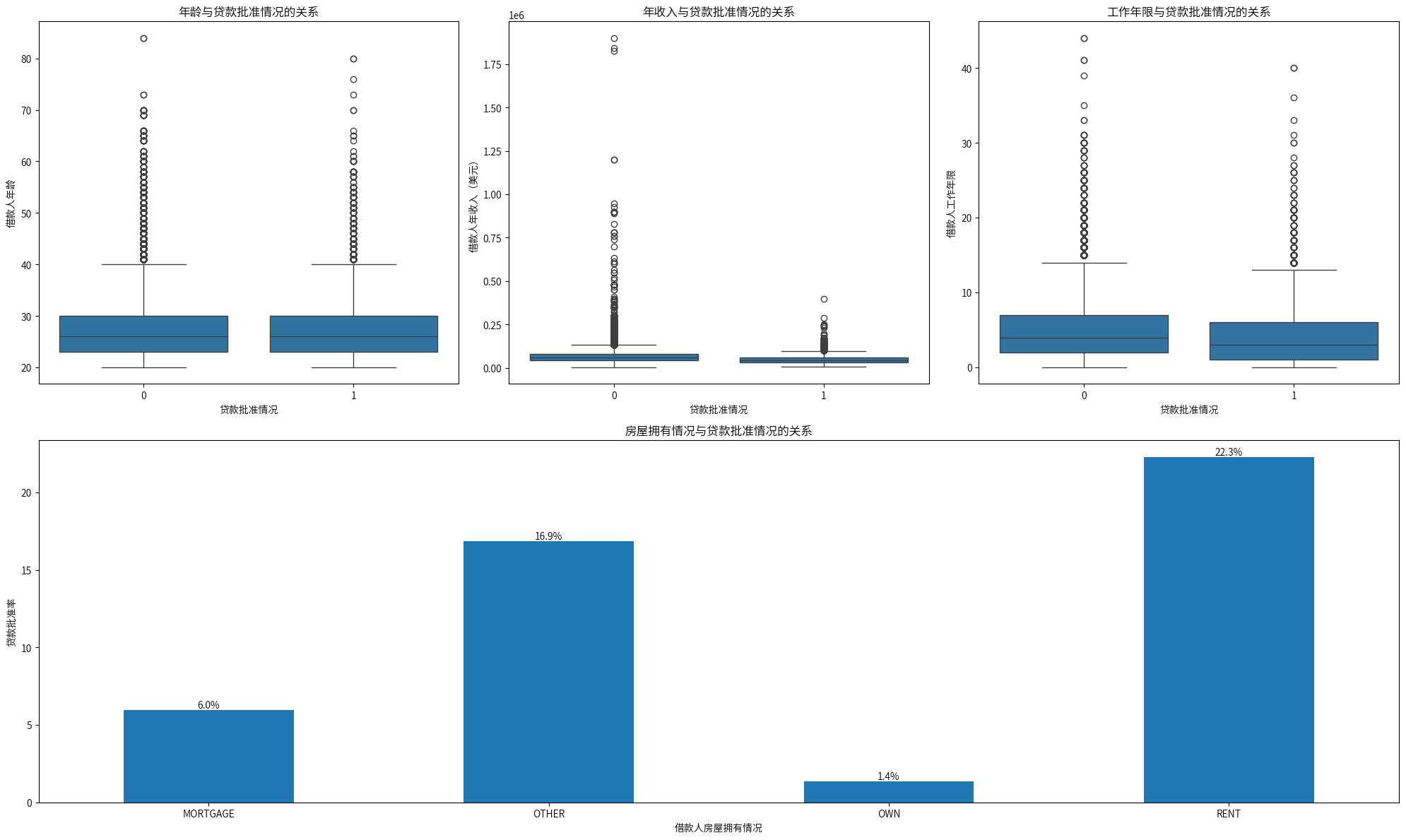
由于数据是模拟生成的,在这个数据中,可以看到,年龄、年收入和贷款批准情况是没显著关系的,通过批准的工作年限中位数反而比未通过的工作年限中位数低,并且租房和其他的通过率比按揭房屋和拥有房屋的通过率高,这并不符合常识。
plt.figure(figsize=(20,20))
plt.subplot(4,3,1)
sns.boxplot(x=train_data['loan_status'],y=train_data['loan_amnt'])
plt.title('贷款金额与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('贷款金额(美元)')
plt.subplot(4,3,2)
sns.boxplot(x=train_data['loan_status'],y=train_data['person_income'])
plt.title('贷款利率与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('贷款利率(百分比)')
plt.subplot(4,3,3)
sns.boxplot(x=train_data['loan_status'],y=train_data['loan_percent_income'])
plt.title('贷款金额占收入的比例与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('贷款金额占收入的比例')
plt.subplot(4,3,4)
sns.boxplot(x=train_data['loan_status'],y=train_data['cb_person_cred_hist_length'])
plt.title('信用历史长度与贷款批准情况的关系')
plt.xlabel('贷款批准情况')
plt.ylabel('信用历史长度')
default_and_loan = pd.crosstab(train_data['cb_person_default_on_file'], train_data['loan_status'])
default_and_loan_percent = default_and_loan.div(default_and_loan.sum(axis=1), axis=0) * 100
ax5 = plt.subplot(4,3,(5,6))
default_and_loan_percent[1].plot(kind='bar',ax=ax5)
plt.title('违约记录情况与贷款批准情况的关系')
plt.xlabel('违约记录情况')
plt.ylabel('贷款批准率')
plt.xticks(rotation=0)
for p in ax5.patches:
ax5.annotate(f"{p.get_height():.1f}%", (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
intent_and_loan = pd.crosstab(train_data['loan_intent'], train_data['loan_status'])
intent_and_loan_percent = intent_and_loan.div(intent_and_loan.sum(axis=1), axis=0) * 100
ax7 = plt.subplot(4,3,(7,9))
intent_and_loan_percent[1].plot(kind='bar',ax=ax7)
plt.title('贷款意图与贷款批准情况的关系')
plt.xlabel('贷款意图')
plt.ylabel('贷款批准率')
plt.xticks(rotation=0)
for p in ax7.patches:
ax7.annotate(f"{p.get_height():.1f}%", (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
grade_and_loan = pd.crosstab(train_data['loan_grade'], train_data['loan_status'])
grade_and_loan_percent = grade_and_loan.div(grade_and_loan.sum(axis=1), axis=0) * 100
ax10 = plt.subplot(4,3,(10,12))
grade_and_loan_percent[1].plot(kind='bar',ax=ax10)
plt.title('贷款信用等级与贷款批准情况的关系')
plt.xlabel('贷款信用等级')
plt.ylabel('贷款批准率')
plt.xticks(rotation=0)
for p in ax10.patches:
ax10.annotate(f"{p.get_height():.1f}%", (p.get_x() + p.get_width() / 2., p.get_height()),
ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.tight_layout()
plt.show()
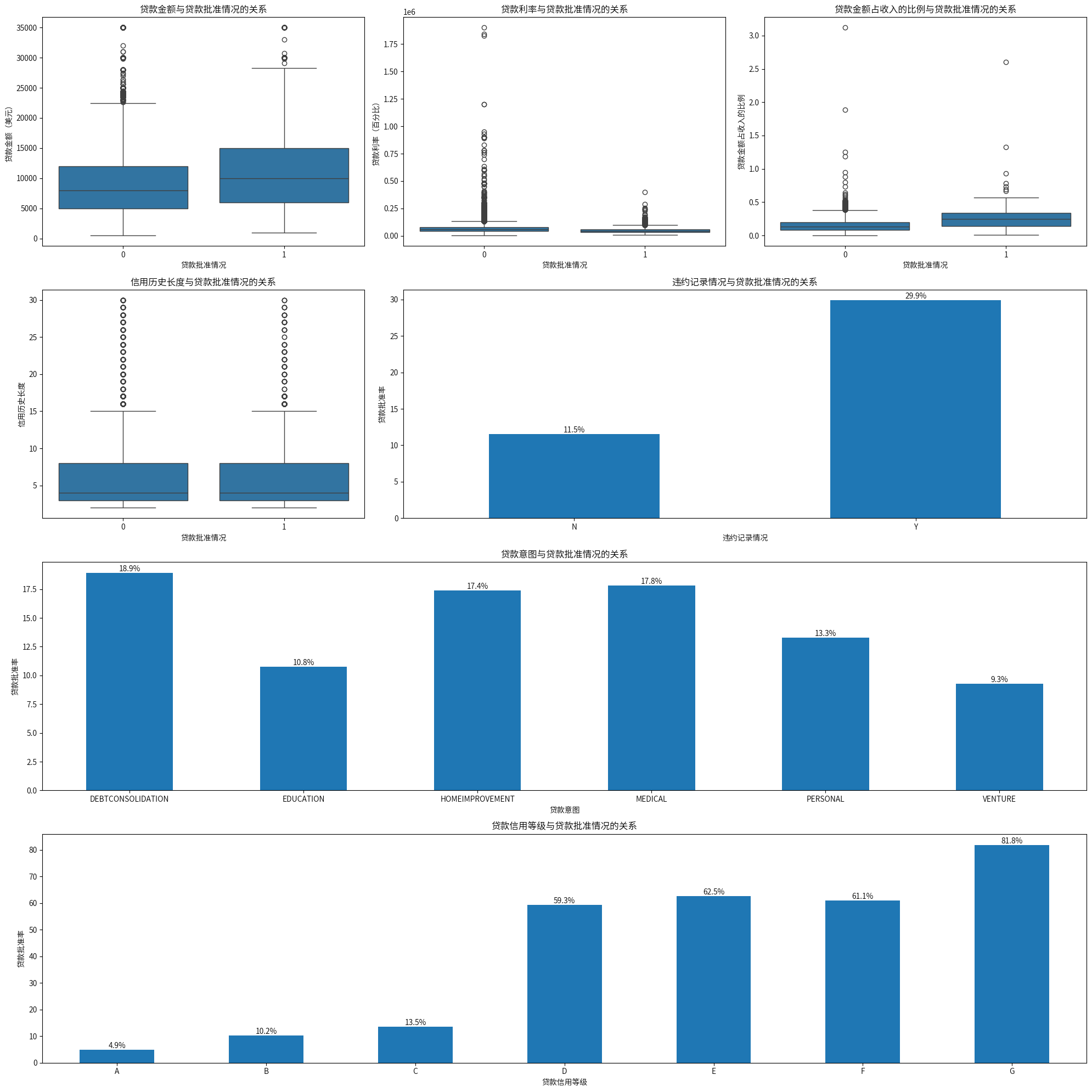
在通过批准的数据中,贷款金额和贷款金额与收入比例的中位数比未通过的贷款金额中位数高,贷款利率的中位数比未通过的贷款利率中位数低,信用历史长度与贷款审批的关系看着不显著,而有违约的通过率更高,信用评分在G级的通过率也是最高的,考虑有些可能是样本太小导致的,比如某个类别只有3个样本,可是有一例通过批准了,这样就会导致他的通过率特别的高,所以还要使用置信区间分析,通过计算通过率的置信区间。这可以了解结果的可靠性。
def calculate_confidence_interval(successes, total, confidence=0.95):
"""
计算二项分布的置信区间
:param successes: 成功次数(这里是获得贷款批准的次数)
:param total: 总样本数
:param confidence: 置信水平,默认95%
:return: (下限, 上限, 点估计)
"""
if total == 0:
return 0, 0, 0
point_estimate = successes / total
z = stats.norm.ppf((1 + confidence) / 2)
margin_of_error = z * np.sqrt((point_estimate * (1 - point_estimate)) / total)
lower_bound = max(0, point_estimate - margin_of_error)
upper_bound = min(1, point_estimate + margin_of_error)
return lower_bound, upper_bound, point_estimate
def analyze_feature(df, feature_name):
"""
分析特定特征的贷款批准率及其置信区间
:param df: 数据框
:param feature_name: 特征名称
"""
grouped = df.groupby(feature_name)
results = []
for group, data in grouped:
total = len(data)
approved = data['loan_status'].sum()
lower, upper, point = calculate_confidence_interval(approved, total)
results.append({
'Group': group,
'Total Samples': total,
'Approval Rate': point,
'CI Lower': lower,
'CI Upper': upper
})
return pd.DataFrame(results)
print("房屋拥有情况的置信区间分析:")
analyze_feature(train_data, 'person_home_ownership')
房屋拥有情况的置信区间分析:
| Group | Total Samples | Approval Rate | CI Lower | CI Upper | |
|---|---|---|---|---|---|
| 0 | MORTGAGE | 24820 | 0.059710 | 0.056762 | 0.062658 |
| 1 | OTHER | 89 | 0.168539 | 0.090767 | 0.246312 |
| 2 | OWN | 3138 | 0.013703 | 0.009635 | 0.017771 |
| 3 | RENT | 30594 | 0.222560 | 0.217899 | 0.227221 |
- “按揭”样本量大,置信区间较窄,说明这个估计比较精确,按揭房主的贷款批准率相对较低。
- “其他”样本量最小,导致置信区间非常宽,这个类别的结果不太可靠,难以得出确切结论。
- “拥有房产”样本量比较小,置信区间相对较窄,自有房产者的贷款批准率出人意料地低。
- “租房”最大的样本量,置信区间很窄,估计非常精确,租房者的贷款批准率明显高于其他类别。
print("违约记录的置信区间分析:")
analyze_feature(train_data, 'cb_person_default_on_file')
违约记录的置信区间分析:
| Group | Total Samples | Approval Rate | CI Lower | CI Upper | |
|---|---|---|---|---|---|
| 0 | N | 49940 | 0.115118 | 0.112319 | 0.117917 |
| 1 | Y | 8701 | 0.298816 | 0.289198 | 0.308434 |
有违约记录的申请者获得贷款批准的概率明显高于无违约记录的申请者。
print("贷款意图的置信区间分析:")
analyze_feature(train_data, 'loan_intent')
贷款意图的置信区间分析:
| Group | Total Samples | Approval Rate | CI Lower | CI Upper | |
|---|---|---|---|---|---|
| 0 | DEBTCONSOLIDATION | 9133 | 0.189313 | 0.181279 | 0.197348 |
| 1 | EDUCATION | 12271 | 0.107734 | 0.102248 | 0.113219 |
| 2 | HOMEIMPROVEMENT | 6280 | 0.173726 | 0.164356 | 0.183097 |
| 3 | MEDICAL | 10933 | 0.178176 | 0.171003 | 0.185349 |
| 4 | PERSONAL | 10014 | 0.132814 | 0.126167 | 0.139461 |
| 5 | VENTURE | 10010 | 0.092807 | 0.087123 | 0.098491 |
样本分布都比较均匀,这使得所有估计都相对可靠,债务整合、家庭改善和医疗贷款批准率高,教育、个人消费的批准率相对较低,创业的批准率是最低的。
print("贷款信用等级的置信区间分析:")
analyze_feature(train_data, 'loan_grade')
贷款信用等级的置信区间分析:
| Group | Total Samples | Approval Rate | CI Lower | CI Upper | |
|---|---|---|---|---|---|
| 0 | A | 20983 | 0.049183 | 0.046257 | 0.052109 |
| 1 | B | 20398 | 0.102314 | 0.098155 | 0.106473 |
| 2 | C | 11036 | 0.135375 | 0.128992 | 0.141758 |
| 3 | D | 5033 | 0.593483 | 0.579913 | 0.607053 |
| 4 | E | 1009 | 0.625372 | 0.595506 | 0.655237 |
| 5 | F | 149 | 0.610738 | 0.532449 | 0.689028 |
| 6 | G | 33 | 0.818182 | 0.686588 | 0.949775 |
A到D级的结果较为可靠,因为样本量大,置信区间窄,批准率与信用等级呈现反比关系,这与传统信贷逻辑相悖。
7.2斯皮尔曼相关性分析
# 定义映射关系
grade_order = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6, 'G': 7}
defaul_mapping = {'N': 0, 'Y':1}
# 将有序变量转换为数值
train_data['loan_grade'] = train_data['loan_grade'].map(grade_order)
test_data['loan_grade'] = test_data['loan_grade'].map(grade_order)
train_data['cb_person_default_on_file'] = train_data['cb_person_default_on_file'].map(defaul_mapping)
test_data['cb_person_default_on_file'] = test_data['cb_person_default_on_file'].map(defaul_mapping)
def plot_spearmanr(data,features,title,wide,height):
# 计算斯皮尔曼相关性矩阵和p值矩阵
spearman_corr_matrix = data[features].corr(method='spearman')
pvals = data[features].corr(method=lambda x, y: spearmanr(x, y)[1]) - np.eye(len(data[features].columns))
# 转换 p 值为星号
def convert_pvalue_to_asterisks(pvalue):
if pvalue <= 0.001:
return "***"
elif pvalue <= 0.01:
return "**"
elif pvalue <= 0.05:
return "*"
return ""
# 应用转换函数
pval_star = pvals.applymap(lambda x: convert_pvalue_to_asterisks(x))
# 转换成 numpy 类型
corr_star_annot = pval_star.to_numpy()
# 定制 labels
corr_labels = spearman_corr_matrix.to_numpy()
p_labels = corr_star_annot
shape = corr_labels.shape
# 合并 labels
labels = (np.asarray(["{0:.2f}\n{1}".format(data, p) for data, p in zip(corr_labels.flatten(), p_labels.flatten())])).reshape(shape)
# 绘制热力图
fig, ax = plt.subplots(figsize=(height, wide), dpi=100, facecolor="w")
sns.heatmap(spearman_corr_matrix, annot=labels, fmt='', cmap='coolwarm',
vmin=-1, vmax=1, annot_kws={"size":10, "fontweight":"bold"},
linecolor="k", linewidths=.2, cbar_kws={"aspect":13}, ax=ax)
ax.tick_params(bottom=False, labelbottom=True, labeltop=False,
left=False, pad=1, labelsize=12)
ax.yaxis.set_tick_params(labelrotation=0)
# 自定义 colorbar 标签格式
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(direction="in", width=.5, labelsize=10)
cbar.set_ticks([-1, -0.5, 0, 0.5, 1])
cbar.set_ticklabels(["-1.00", "-0.50", "0.00", "0.50", "1.00"])
cbar.outline.set_visible(True)
cbar.outline.set_linewidth(.5)
plt.title(title)
plt.show()
features = train_data.drop(['id','person_home_ownership','loan_intent'],axis=1).columns.tolist()
plot_spearmanr(train_data,features,'各变量之间的斯皮尔曼相关系数热力图',12,15)
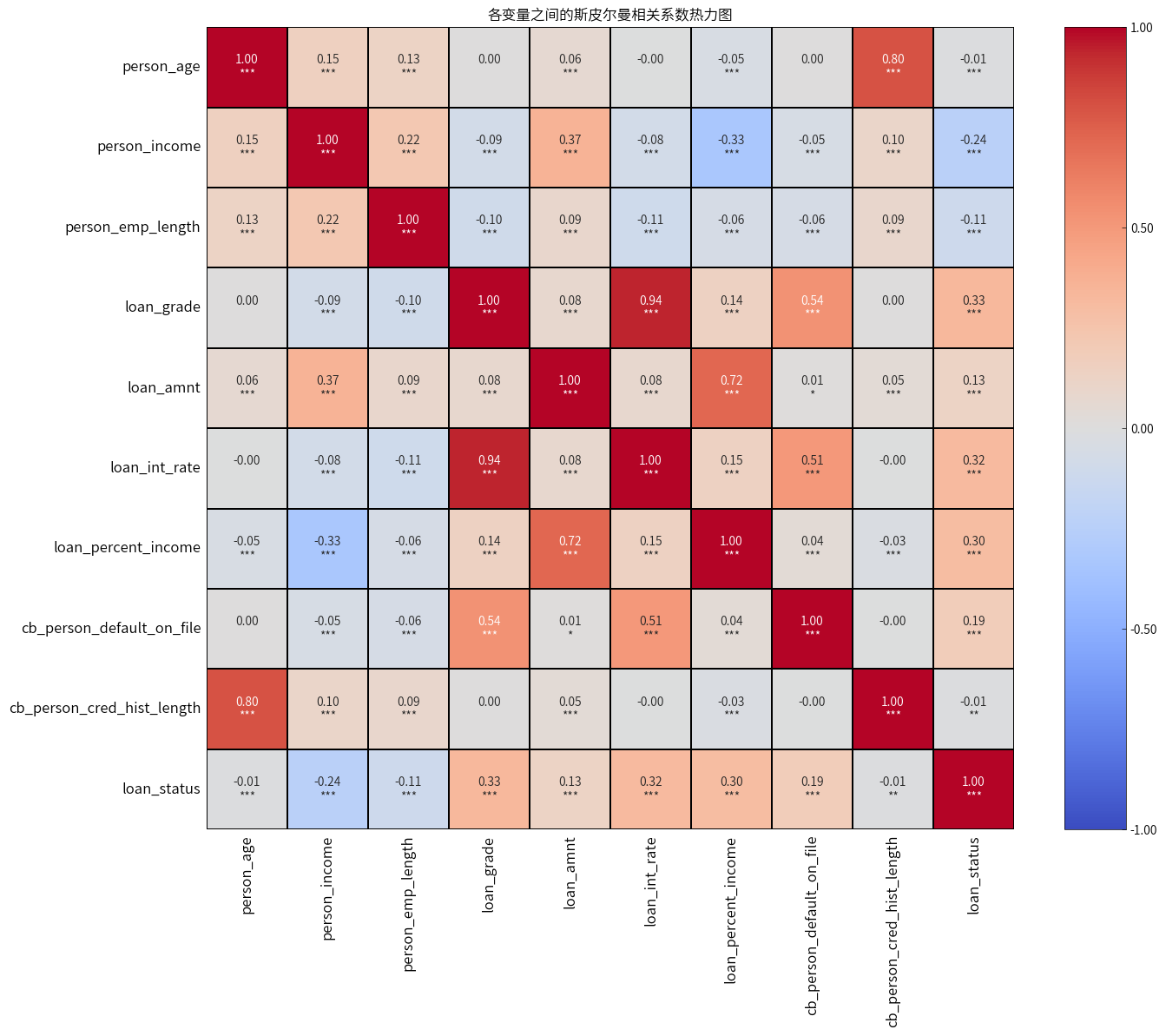
目标变量(是否获得贷款批准)与 借款人年龄、信用历史长度不相关,与借款人年收入、借款人工作年限呈弱负相关,与贷款信用等级、贷款利率、 贷款金额占收入的比例呈中等正相关(注意:贷款信用等级越大表示信用越差),与贷款金额、违约记录呈弱正相关。
7.3卡方检验
def chi_square_test(var1, var2):
contingency_table = pd.crosstab(train_data[var1], train_data[var2])
chi2, p, dof, expected = stats.chi2_contingency(contingency_table)
return chi2, p
loan_status_chi_square_results = {}
cat_features = ['person_home_ownership', 'loan_intent']
loan_status_chi_square_results = {feature: chi_square_test(feature, 'loan_status') for feature in cat_features}
loan_status_chi_square_df = pd.DataFrame.from_dict(loan_status_chi_square_results,orient='index',columns=['Chi-Square','P-Value'])
loan_status_chi_square_df
| Chi-Square | P-Value | |
|---|---|---|
| person_home_ownership | 3426.017802 | 0.000000e+00 |
| loan_intent | 659.623116 | 2.632671e-140 |
通过卡方检验,发现借款人房屋拥有情况和贷款意图的P值很小,因此认为与是否获得贷款批准是显著相关的。
8.预测贷款批准通过情况
8.1数据预处理
考虑后续会使用逻辑回归、神经网络模型,还是对数据采取标准化和独热编码,同时剔除斯皮尔曼相关性分析中不显著的两个变量,然后划分数据,注意,这里不打算平衡样本了,因为我在后续的分析中,发现逻辑回归平衡样本后对类别1的预测反而下降了,可能是过度采样带来的噪声,当然这种只是特例,假如读者在分析其他数据时,发现不平衡会导致少数类的预测准确率几乎接近0的话,还是要平衡样本,或者调整决策阈值。
new_train_data = train_data.drop(columns=['id','person_age','cb_person_cred_hist_length'])
new_test_data = test_data.drop(columns=['id','person_age','cb_person_cred_hist_length'])
# 独热编码和标签编码的列
one_hot_features = ['person_home_ownership', 'loan_intent']
# 独热编码类别特征,并删除第一个类别避免虚拟变量陷阱
new_train_data = pd.get_dummies(new_train_data, columns=one_hot_features, drop_first=True)
new_test_data = pd.get_dummies(new_test_data, columns=one_hot_features, drop_first=True)
# 将布尔值转换为数值型(0 和 1)
new_train_data = new_train_data.astype(int)
new_test_data = new_test_data.astype(int)
numerical_features = ['person_income', 'person_emp_length','loan_amnt','loan_int_rate','loan_percent_income']
# 对数值型特征进行标准化
scaler = StandardScaler()
new_train_data[numerical_features] = scaler.fit_transform(new_train_data[numerical_features])
new_test_data[numerical_features] = scaler.transform(new_test_data[numerical_features])
x = new_train_data.drop(['loan_status'],axis=1)
y = new_train_data['loan_status']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=15) #28分
8.2逻辑回归
# 初始化逻辑回归模型
log_reg = LogisticRegression(random_state=15)
# 训练模型
log_reg.fit(x_train, y_train)
y_pred_log = log_reg.predict(x_test)
class_report_log = classification_report(y_test, y_pred_log)
print('逻辑回归模型评估如下:')
print(class_report_log)
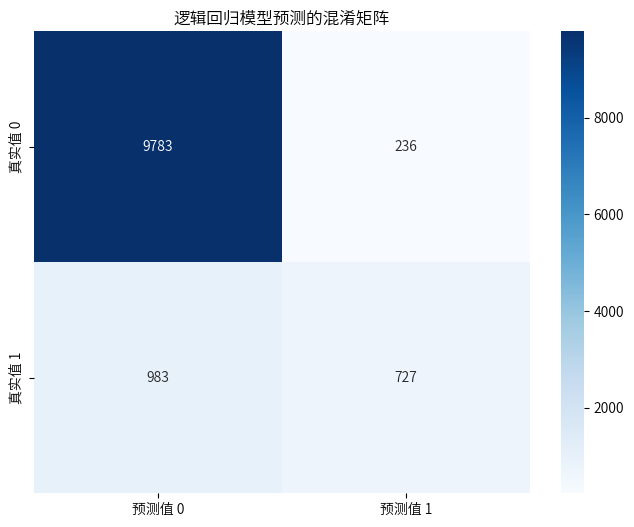
逻辑回归模型评估如下:
precision recall f1-score support
0 0.91 0.98 0.94 10019
1 0.75 0.43 0.54 1710
accuracy 0.90 11729
macro avg 0.83 0.70 0.74 11729
weighted avg 0.89 0.90 0.88 11729
cm = confusion_matrix(y_test,y_pred_log)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues',
xticklabels=['预测值 0', '预测值 1'],
yticklabels=['真实值 0', '真实值 1'])
plt.title('逻辑回归模型预测的混淆矩阵')
plt.show()
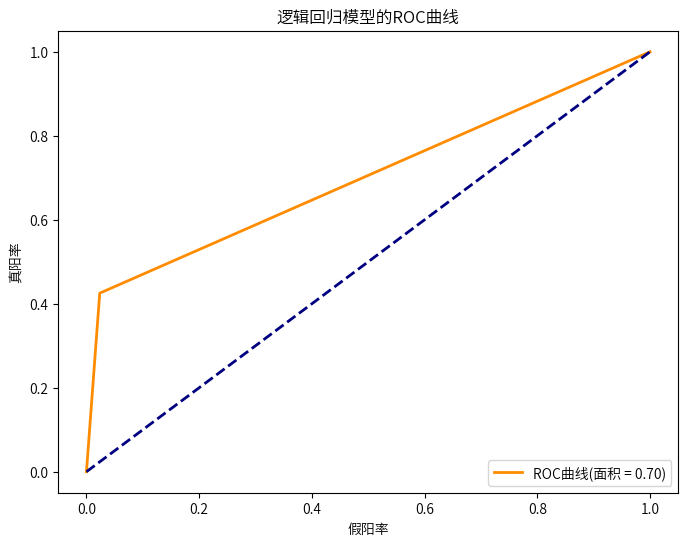
#绘制ROC曲线
fpr, tpr, _ = roc_curve(y_test, y_pred_log)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线(面积 = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳率')
plt.ylabel('真阳率')
plt.title('逻辑回归模型的ROC曲线')
plt.legend(loc="lower right")
plt.show()
8.3随机森林
rf_clf = RandomForestClassifier(random_state=15)
rf_clf.fit(x_train, y_train)
y_pred_rf = rf_clf.predict(x_test)
class_report_rf = classification_report(y_test, y_pred_rf)
print('随机森林模型评估如下:')
print(class_report_rf)
随机森林模型评估如下:
precision recall f1-score support
0 0.95 0.99 0.97 10019
1 0.89 0.68 0.77 1710
accuracy 0.94 11729
macro avg 0.92 0.83 0.87 11729
weighted avg 0.94 0.94 0.94 11729
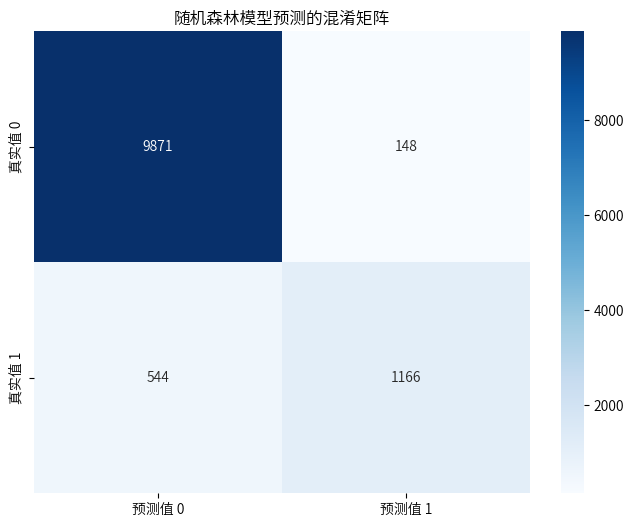
cm = confusion_matrix(y_test,y_pred_rf)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues',
xticklabels=['预测值 0', '预测值 1'],
yticklabels=['真实值 0', '真实值 1'])
plt.title('随机森林模型预测的混淆矩阵')
plt.show()
#绘制ROC曲线
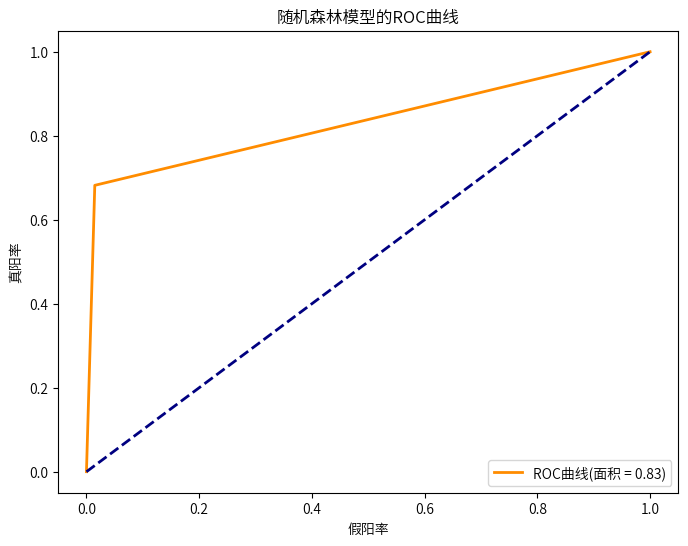
fpr, tpr, _ = roc_curve(y_test, y_pred_rf)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线(面积 = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳率')
plt.ylabel('真阳率')
plt.title('随机森林模型的ROC曲线')
plt.legend(loc="lower right")
plt.show()
8.4多层感知机
# 建立神经网络模型
mlp_model = Sequential([
Input(shape=(x_train.shape[1],)), # 指定输入形状
Dense(64, activation='relu'), # 隐藏层
Dense(32, activation='relu'), # 隐藏层
Dense(1, activation='sigmoid') # 输出层
])
# 编译模型
mlp_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
mlp_model.fit(x_train, y_train, epochs=50, batch_size=32, validation_data=(x_test, y_test), verbose=0)
y_pred_mlp = (mlp_model.predict(x_test) >= 0.6).astype(int) # 这里把概率大于0.6的才看作1,这是调整分类阈值来提高准确率的
class_report_mlp = classification_report(y_test, y_pred_mlp)
print('多层感知机评估如下:')
print(class_report_mlp)
多层感知机评估如下:
precision recall f1-score support
0 0.95 0.99 0.97 10019
1 0.92 0.67 0.78 1710
accuracy 0.94 11729
macro avg 0.93 0.83 0.87 11729
weighted avg 0.94 0.94 0.94 11729
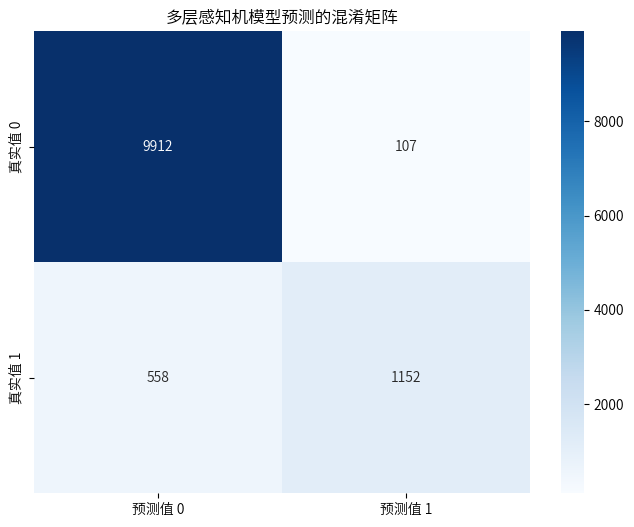
cm = confusion_matrix(y_test,y_pred_mlp)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues',
xticklabels=['预测值 0', '预测值 1'],
yticklabels=['真实值 0', '真实值 1'])
plt.title('多层感知机模型预测的混淆矩阵')
plt.show()
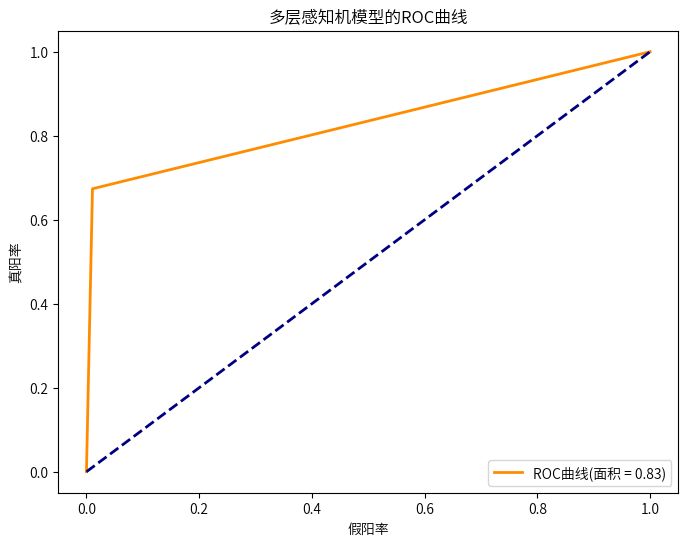
#绘制ROC曲线
fpr, tpr, _ = roc_curve(y_test, y_pred_mlp)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线(面积 = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳率')
plt.ylabel('真阳率')
plt.title('多层感知机模型的ROC曲线')
plt.legend(loc="lower right")
plt.show()
8.5深度神经网络
# 构建深度神经网络模型
deep_model = Sequential([
Input(shape=(x_train.shape[1],)),
Dense(128, activation='relu'), # 第一层隐藏层,128节点
Dropout(0.3), # Dropout层,丢弃30%的节点
Dense(64, activation='relu'), # 第二层隐藏层,64节点
Dropout(0.3),
Dense(32, activation='relu'), # 第三层隐藏层,32节点
Dropout(0.3),
Dense(16, activation='relu'), # 第四层隐藏层,16节点
Dense(1, activation='sigmoid') # 输出层,Sigmoid激活
])
# 编译模型
deep_model.compile(optimizer=Adam(learning_rate=0.001), loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
deep_model.fit(x_train, y_train, epochs=100, batch_size=32, validation_data=(x_test, y_test), verbose=0)
y_pred_deep = (deep_model.predict(x_test) >= 0.6).astype(int)
class_report_deep = classification_report(y_test, y_pred_deep)
print('深度神经网络模型评估如下:')
print(class_report_deep)
深度神经网络模型评估如下:
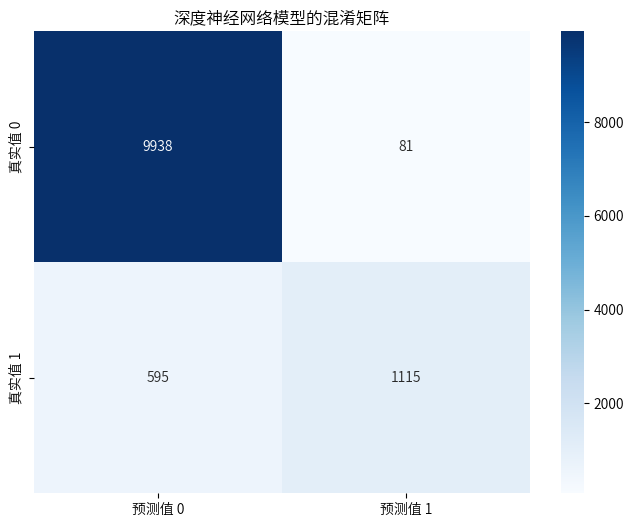
precision recall f1-score support
0 0.94 0.99 0.97 10019
1 0.93 0.65 0.77 1710
accuracy 0.94 11729
macro avg 0.94 0.82 0.87 11729
weighted avg 0.94 0.94 0.94 11729
cm = confusion_matrix(y_test,y_pred_deep)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues',
xticklabels=['预测值 0', '预测值 1'],
yticklabels=['真实值 0', '真实值 1'])
plt.title('深度神经网络模型的混淆矩阵')
plt.show()
#绘制ROC曲线
fpr, tpr, _ = roc_curve(y_test, y_pred_deep)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC曲线(面积 = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳率')
plt.ylabel('真阳率')
plt.title('深度神经网络模型的ROC曲线')
plt.legend(loc="lower right")
plt.show()
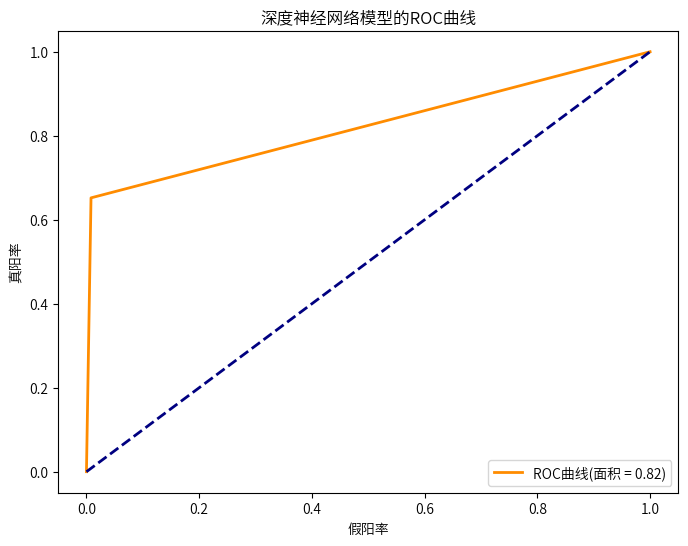
综合看下来,各个模型的预测效果都不错,虽然可以进一步优化参数,但是考虑优化参数耗时特别久,耗费的时间或许不值得(当然,如果是一个真实数据,有大型服务器的企业,能提高一些精度也是十分有必要的)。
8.6SHAP分析
# 创建SHAP解释器
explainer = shap.DeepExplainer(deep_model, x_test.values[:1000]) # 使用前1000个样本作为背景
# 计算SHAP值
shap_values = explainer.shap_values(x_test.values)
print(f"shap_values最后一个维度是{shap_values.shape[-1]}")
shap_values最后一个维度是1
shap_values最后一个维度是1,需要去除,因为对于大多数机器学习模型,SHAP值通常是二维数组:(样本数, 特征数),但在某些深度学习框架或SHAP实现中,可能会输出三维数组:(样本数, 特征数, 1),而且当最后一个维度是1时,它不包含额外信息,只是一个冗余的维度。
shap_values = shap_values.squeeze(-1)
# 绘制 SHAP 汇总图
plt.figure(figsize=(12, 8))
shap.summary_plot(shap_values, x_test, plot_type="bar", show=False)
plt.title("深度神经网络的 SHAP 特征重要性")
plt.tight_layout()
plt.show()
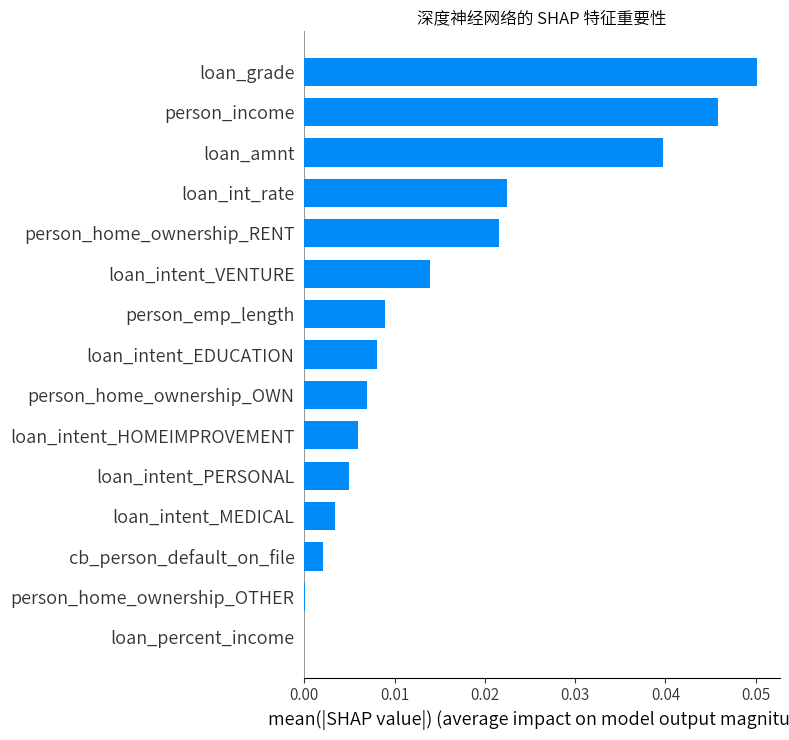
# 计算并打印特征重要性
feature_importance = np.abs(shap_values).mean(0)
importance_df = pd.DataFrame(list(zip(x_test.columns, feature_importance)),
columns=['特征', '重要性'])
importance_df = importance_df.sort_values('重要性', ascending=False)
importance_df
| 特征 | 重要性 | |
|---|---|---|
| 2 | loan_grade | 0.050171 |
| 0 | person_income | 0.045789 |
| 3 | loan_amnt | 0.039707 |
| 4 | loan_int_rate | 0.022440 |
| 9 | person_home_ownership_RENT | 0.021598 |
| 14 | loan_intent_VENTURE | 0.013976 |
| 1 | person_emp_length | 0.008896 |
| 10 | loan_intent_EDUCATION | 0.008064 |
| 8 | person_home_ownership_OWN | 0.006981 |
| 11 | loan_intent_HOMEIMPROVEMENT | 0.005900 |
| 13 | loan_intent_PERSONAL | 0.004905 |
| 12 | loan_intent_MEDICAL | 0.003385 |
| 6 | cb_person_default_on_file | 0.002048 |
| 7 | person_home_ownership_OTHER | 0.000121 |
| 5 | loan_percent_income | 0.000000 |
# 绘制 SHAP 值的分布图
plt.figure(figsize=(12, 8))
shap.summary_plot(shap_values, x_test, show=False)
plt.title("SHAP 值分布")
plt.tight_layout()
plt.show()
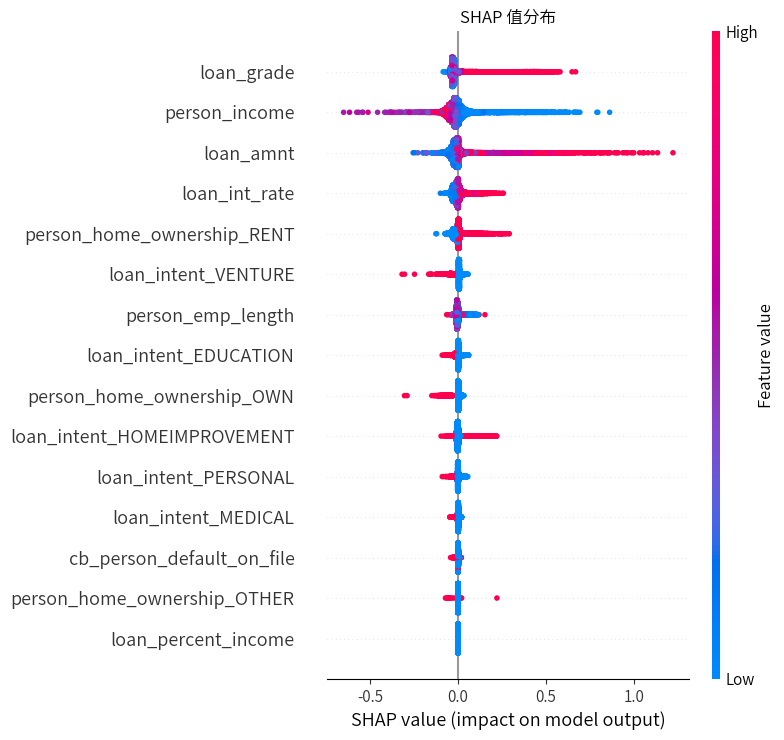
通过SHAP值分析,发现深度神经网络中,重要的特征因素是贷款信用等级、借款人年收入、贷款的利率。
9.多模型预测测试集
new_y_pred_log = log_reg.predict(new_test_data)
new_y_pred_rf = rf_clf.predict(new_test_data)
new_y_pred_mlp = (mlp_model.predict(new_test_data) >= 0.6).astype(int).ravel()
new_y_pred_deep = (deep_model.predict(new_test_data) >= 0.6).astype(int).ravel()
test_data['log_pred'] = new_y_pred_log
test_data['rf_pred'] = new_y_pred_rf
test_data['mlp_pred'] = new_y_pred_mlp
test_data['nn_pred'] = new_y_pred_deep
test_data.head()
| id | person_age | person_income | person_home_ownership | person_emp_length | loan_intent | loan_grade | loan_amnt | loan_int_rate | loan_percent_income | cb_person_default_on_file | cb_person_cred_hist_length | log_pred | rf_pred | mlp_pred | nn_pred | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 58645 | 23 | 69000 | RENT | 3.0 | HOMEIMPROVEMENT | 6 | 25000 | 15.76 | 0.36 | 0 | 2 | 1 | 1 | 1 | 1 |
| 1 | 58646 | 26 | 96000 | MORTGAGE | 6.0 | PERSONAL | 3 | 10000 | 12.68 | 0.10 | 1 | 4 | 0 | 0 | 0 | 0 |
| 2 | 58647 | 26 | 30000 | RENT | 5.0 | VENTURE | 5 | 4000 | 17.19 | 0.13 | 1 | 2 | 1 | 1 | 1 | 0 |
| 3 | 58648 | 33 | 50000 | RENT | 4.0 | DEBTCONSOLIDATION | 1 | 7000 | 8.90 | 0.14 | 0 | 7 | 0 | 0 | 0 | 0 |
| 4 | 58649 | 26 | 102000 | MORTGAGE | 8.0 | HOMEIMPROVEMENT | 4 | 15000 | 16.32 | 0.15 | 1 | 4 | 0 | 0 | 0 | 0 |
10.总结
本项目从影响因素分析和建立模型两个主要角度,深入探讨了贷款批准通过的影响因素,并基于 SHAP(SHapley Additive exPlanations)对深度神经网络模型行了分析。得出以下结论:
- 贷款批准通过的影响因素主要有:借款人年收入、借款人工作年限、贷款信用等级、贷款利率、 贷款金额占收入的比例、贷款金额、违约记录、借款人房屋拥有情况和贷款意图。
- 四类模型预测效果均比较理想。
- 通过SHAP值分析,发现深度神经网络中,重要的特征因素是贷款信用等级、借款人年收入、贷款的利率。
- 由于数据是模拟生成的,许多地方出现了与常识不符合的地方,本项目仅供学习参考,是来自Kaggle上的一个比赛,截止目前完成该项目的时候,第一名的准确率得分是0.97378,而我的得分只有0.93379,推测可能是没有进行参数优化,或者进一步特征工程导致的。