特征工程在营销组合建模中的应用:基于因果推断的机器学习方法优化渠道效应估计
在机器学习领域,特征工程是提升模型性能的关键步骤。它涉及选择、创建和转换输入变量,以构建最能代表底层问题结构的特征集。然而,在许多实际应用中,仅仅依靠统计相关性进行特征选择可能导致误导性的结果,特别是在我们需要理解因果关系的场景中。
因果推断方法为特征工程提供了一个更深层次的框架,使我们能够区分真正的因果关系和简单的统计相关性。这种方法在需要理解干预效果的领域尤为重要,如经济学、医学和市场营销。
营销组合建模(Marketing Mix Modeling, MMM)是应用因果推断进行特征工程的一个典型案例。MMM旨在回答一个核心的因果问题:"每个营销渠道的X美元投资将如何影响销售额?"这个问题的准确答案对优化营销预算分配至关重要,但它也凸显了因果推断在实际商业问题中的复杂性。

本文将以MMM为例,深入探讨如何将因果推断原理应用于特征工程,以提高机器学习模型的准确性和可解释性。我们将证明,在模型中包含或排除某些变量可能导致因果估计的偏差,进而影响基于数据的决策质量。
文章结构如下:
- 特征选择的因果视角:通过一个MMM模拟案例,我们将展示基于因果推断的特征选择如何显著影响模型结果。这部分将说明不同特征集如何导致营销渠道效应估计的巨大差异。
- 因果推断在特征工程中的应用:我们将深入分析潜在的偏差来源,结合Judea Pearl的因果推断理论[1]和Matheus Facure的研究[3]。这部分将详细讨论在构建机器学习模型时应如何处理混杂变量、中介变量和碰撞变量。
- 实证分析与模型评估:我们将把这些理论知识应用到MMM的模拟数据案例中,验证基于因果推断的特征工程方法的实际效果。我们将比较传统特征选择方法与因果推断方法在模型性能和因果效应估计准确性上的差异。
通过本文,我们可以展示因果推断如何改进机器学习中的特征工程过程,从而提高模型的解释性和决策支持能力。虽然我们以MMM为例,但这种方法可以推广到其他需要理解因果关系的机器学习应用场景,为数据科学家提供一个更全面的特征工程框架。
1、营销组合模型中变量选择的重要性
为了说明变量选择在MMM中的关键作用,我们将通过一个简化的案例进行演示。尽管将使用简单的线性回归,但请注意即使在更复杂的MMM中(如包含饱和度和延续效应的贝叶斯模型),变量选择问题同样重要。
假设你在一家在线体育用品零售商的营销部门工作。过去三年,部门主要通过电视、短视频和社交媒体进行广告投放。现在需要评估这些营销渠道对销售的贡献。首先我们收集了每周的营销渠道支出和公司销售数据,如下图所示:
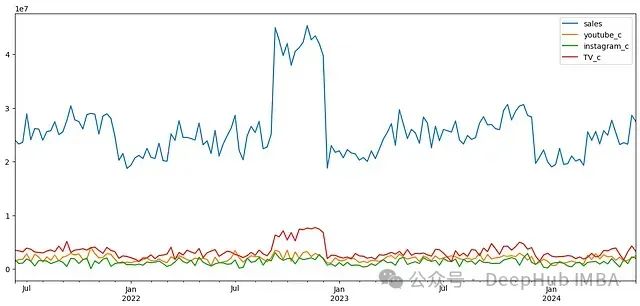
图1:销售额和营销支出的时间序列数据
最简单的MMM方法是对营销渠道进行线性回归来拟合销售数据:
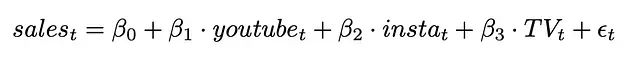
然而我们知道还有其他变量可能影响销售,需要考虑是否将它们纳入模型。这些变量包括:
- 季节性变量:销售通常呈现自然的季节性模式
- 重大事件指标:如足球世界杯期间的销售增长
- 价格:假设销售与价格有强相关性
- 网站访问量:网站流量增加通常伴随销售增长
考虑到这些额外的变量,我们构建了5个不同的线性回归模型,每个模型包含不同的变量集:

这些模型得出的渠道效应估计如下:
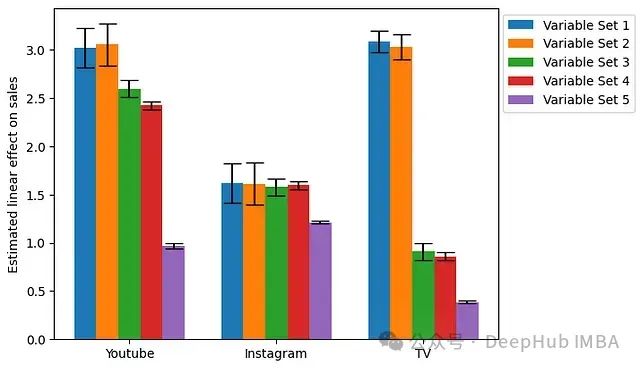
图2:不同模型的渠道效应估计比较
从上图可以看出,不同变量集导致的渠道估计差异显著。这意味着基于不同模型的营销决策可能大相径庭。例如:
关于电视广告投资:
根据模型1,每1美元的电视投资带来约3美元的销售额,建议增加投资。而根据模型5,每1美元投资产生的销售额不足0.5美元,建议削减电视广告支出。
关于最有效的营销渠道:
模型1显示电视最有效;模型2、3、4显示YouTube最有效;模型5则认为Instagram最有效
这个案例清楚地表明,如果不谨慎选择MMM中的变量,得出的营销决策可能与随机决策无异。所以就需要因果推断理论为我们提供了确定应包含和排除哪些变量的方法论基础。在接下来的章节中,我们将详细探讨这个问题,最终使您能够判断哪组变量(如果有的话)能够产生准确的因果估计。
需要特别注意的是,"选择能够最准确预测销售的变量"并不是一个可靠的方法。我们的目标不是预测销售,而是确定营销渠道对销售的因果效应。这两个目标有本质区别。正如我们将在后面看到的,一些对销售预测非常有效的变量,可能会导致营销渠道对销售的因果效应估计产生偏差。
2、估计偏差的来源
在构建营销组合模型(MMM)时,准确识别和处理可能导致估计偏差的变量至关重要。本节将详细讨论三种主要的偏差来源:混杂变量的遗漏、中介变量的包含以及碰撞变量的包含。
a、混杂变量的遗漏
混杂变量的正确处理是获得无偏估计的关键。我们将解释什么是混杂变量,为什么它们如此重要,以及如何在MMM中识别它们。
混杂变量的定义
混杂变量是同时对公司销售和一个或多个营销渠道具有因果效应的变量。以我们的在线体育用品零售案例为例,"足球世界杯"就是一个典型的混杂变量。它会导致公司增加电视广告投资,同时也直接促进足球相关产品的销售。这种关系可以用以下因果图表示:

图3:混杂变量的因果关系图
混杂变量的重要性
如果我们在模型中忽略了混杂变量,就可能导致对营销渠道效果的错误估计。以"世界杯"为例:
世界杯期间,电视广告支出和销售额都会增加;如果模型不包含"世界杯"变量,它可能会错误地将所有销售增长归因于电视广告,而实际上部分增长是由世界杯直接引起的。
这种情况可以通过下图直观理解:
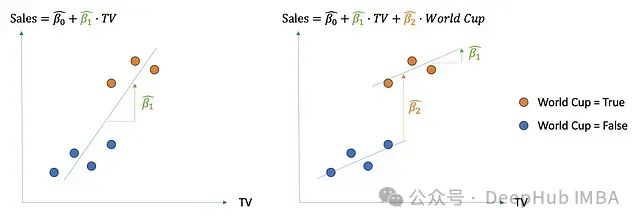
图4:包含和不包含混杂变量的回归比较
左图显示了不考虑世界杯影响的情况,此时电视广告对销售的估计效果(β1)被高估。右图显示了包含世界杯变量后的情况,电视广告的估计效果(β1)明显减小,而世界杯的直接效果(β2)被正确捕获。
识别MMM中的混杂变量
识别混杂变量需要深入理解业务流程和市场动态。以下是一些常见的混杂变量示例:
- 季节性:在多数行业中,销售和营销预算都受季节影响(如圣诞节期间)。
- 促销活动:如果公司的折扣活动同时影响营销预算和销售,它就是一个混杂变量。
- 竞争对手的营销活动:竞争对手的行为可能同时影响你的销售和营销策略。
- 新产品发布:新产品通常会带来额外的营销投入和销售增长。
识别混杂变量的关键在于全面了解影响营销决策的因素。这通常需要与公司内部相关人员进行深入沟通,了解预算分配的决策过程。
处理不可测量的混杂变量
在某些情况下,重要的混杂变量可能无法测量或缺乏数据。如果这些变量的影响很大,可能需要重新考虑是否继续进行MMM项目。在这种情况下,没有估计可能比依赖有偏估计更好。
b、中介变量的包含
在构建MMM时,另一个常见的错误是包含中介变量,这可能导致对营销渠道效果的低估。
中介变量的定义
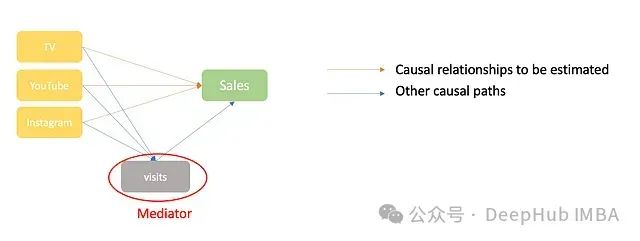
中介变量是营销渠道通过它间接影响销售的变量。例如,在评估电视广告对销售的影响时,网站访问量可能是一个中介变量:

图5:中介变量的因果路径图
中介变量导致的偏差
包含中介变量会导致对营销渠道总效果的低估:
不包含中介变量时,模型估计的是营销渠道的总效果(直接效应 + 间接效应)。包含中介变量时,模型只估计直接效应,忽略了通过中介变量的间接效应。
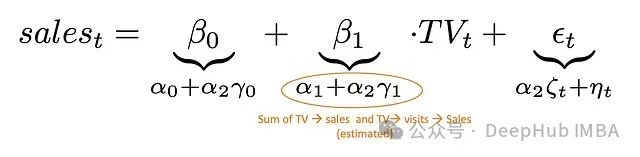
这可以通过以下数学表达式来说明:
销售的真实生成过程:
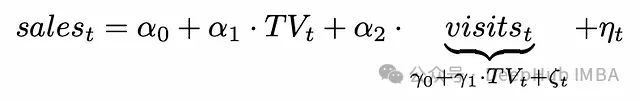
包含中介变量的模型估计:
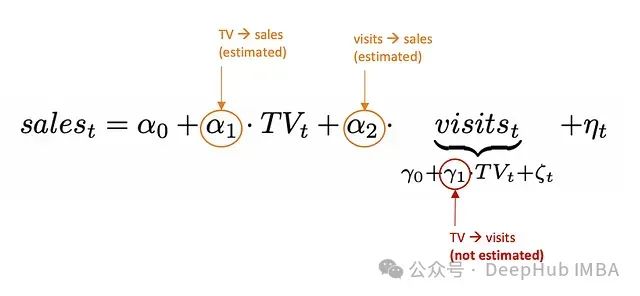
不包含中介变量的模型估计:
MMM中处理中介变量的挑战
在大多数情况下,识别和排除中介变量相对简单。但是当一个营销渠道同时是另一个渠道的中介时,情况会变得复杂。例如电视广告可能会增加搜索量,从而影响付费搜索的支出:

图6:营销渠道作为中介变量的情况
在这种情况下,我们面临两个选择:
排除付费搜索变量,获得电视广告的无偏估计,但失去对付费搜索效果的估计。包含付费搜索变量,获得付费搜索的无偏估计,但电视广告的估计将有偏差。
选择哪种方法取决于具体的业务目标和优先级。
c、碰撞变量的包含
最后一种需要避免的偏差来源是包含碰撞变量。
碰撞变量的定义
碰撞变量是同时受到我们感兴趣的原因变量(如营销渠道)和结果变量(如销售)影响的变量。在MMM中,这种情况相对少见,但仍然值得注意。
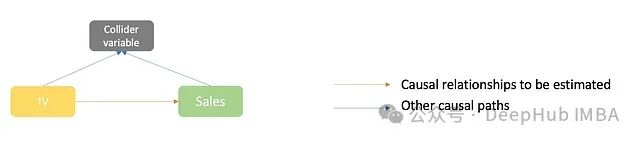
图7:碰撞变量的因果路径图
MMM中的碰撞变量示例
一个潜在的碰撞变量例子是公司利润。营销渠道支出会减少利润,而销售会增加利润。然而,在实际的MMM中,很少会考虑将利润作为一个变量。
由于碰撞变量在MMM中相对罕见,我们不会深入讨论它们导致偏差的具体机制。感兴趣的读者可以参考Mattheus Facure的相关研究[3]。
在下一节中,我们将把这些理论知识应用到我们的模拟数据案例中,展示如何在实践中识别和处理这些不同类型的变量。
3、模拟研究
为了验证我们前面讨论的理论,我们将通过一个模拟研究来展示变量选择对营销组合模型(MMM)结果的影响。这个模拟研究将帮助我们理解如何在实践中识别和处理不同类型的变量。
因为文字比较多,所以完整代码链接放在最后了
数据生成过程
首先详细说明模拟数据的生成过程。
营销预算生成
营销预算的生成过程如下:
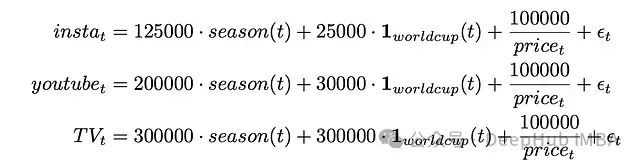
在这个模型中,三个营销渠道(YouTube、Instagram和电视)的预算都受到季节性、世界杯事件和价格的影响。剩余的变化被模拟为随机噪声。
销售额和网站访问量生成
销售额和网站访问量的生成过程如下:
销售额方程:
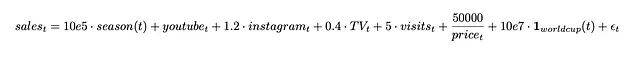
网站访问量方程:
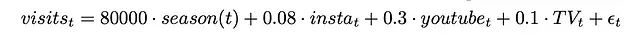
这些方程表明,销售额受到季节性、营销渠道预算、价格、世界杯事件和网站访问量的影响。同时网站访问量本身也受到营销预算和季节性的影响。
变量分类
基于上述数据生成过程,我们可以对变量进行分类:
混杂变量
季节性、世界杯和价格都是混杂变量,因为它们同时影响营销渠道预算和销售额。
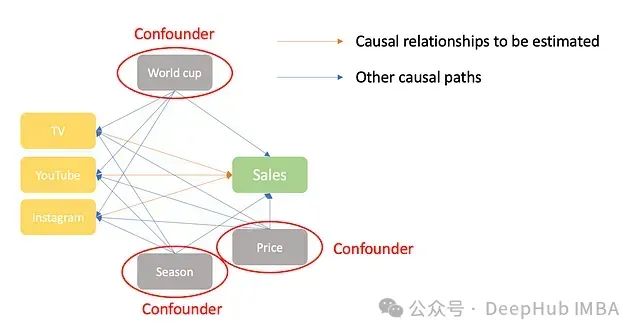
中介变量
网站访问量是一个中介变量,因为它被营销渠道影响,并进而影响销售额。
真实因果效应计算
根据数据生成过程,我们可以计算出营销渠道的真实因果效应。每个渠道的总效应由直接效应和通过增加网站访问量的间接效应组成。
对于每个渠道,总因果效应计算如下:
- YouTube: 1 + 0.3 * 5 = 2.5
- Instagram: 1.2 + 0.08 * 5 = 1.6
- 电视: 0.4 + 0.1 * 5 = 0.9
这里直接效应来自销售方程中的系数,间接效应是访问量方程中的系数与销售方程中访问量系数的乘积。
模型估计结果
我们使用不同的变量集估计了多个线性回归模型。下图展示了这些模型的估计结果:
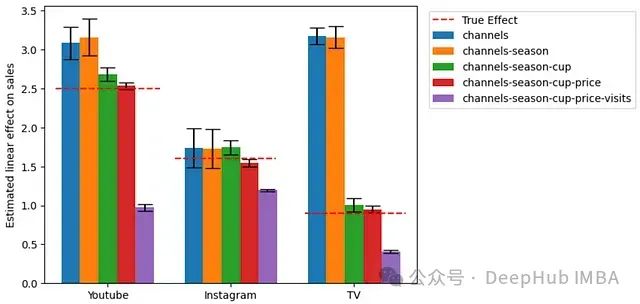
图8:不同变量集下的营销渠道效应估计
从这些结果中,我们可以观察到:
- 模型5(包含所有混杂变量,不包含中介变量)最接近真实的因果效应。
- 忽略混杂变量(如模型1-4)会导致显著的估计偏差。例如,在模型1中,电视广告的效果被高估了约3倍。
- 包含中介变量(模型5vs模型4)也会导致偏差。例如,在包含网站访问量后,YouTube的估计效果降低了一半以上。
这些观察结果与我们之前的理论分析一致,验证了正确识别和处理混杂变量和中介变量的重要性。
4、结论与实践建议
本文通过理论分析和模拟实验,深入探讨了变量选择对营销组合模型(MMM)结果的影响。我们的主要发现和建议如下:
- 混杂变量的重要性:正确识别和包含混杂变量对于获得无偏的因果效应估计至关重要。在模拟中,忽略季节性、重大事件(如世界杯)和价格等混杂变量导致了显著的估计偏差。
- 中介变量的处理:包含中介变量(如网站访问量)会导致对营销渠道总效果的低估。在实践中应该仔细考虑是否将可能的中介变量纳入模型。
- 变量选择的复杂性:当一个营销渠道同时是另一个渠道的中介时(如付费搜索对电视广告的影响),需要根据具体的业务目标和优先级做出权衡。
- 因果推断的重要性:传统的基于预测性能选择变量的方法可能导致因果效应估计的偏差。在构建MMM时,应该基于对业务过程和市场动态的深入理解来选择变量。
- 数据质量和可用性:在某些情况下,重要的混杂变量可能无法测量或缺乏数据。这种情况下,可能需要重新评估进行MMM的可行性。
- 持续验证和更新:随着市场环境和业务策略的变化,应定期重新评估模型中的变量选择。
- 跨职能协作:构建有效的MMM需要营销、数据科学和业务团队的紧密合作,以确保对所有潜在的因果路径有全面的理解。
通过将因果推断原理应用于特征工程,数据科学家和机器学习工程师可以构建更准确、更可靠的预测模型,不仅能提高模型性能,还能增强模型的可解释性和决策支持能力。营销组合建模(MMM)作为一个典型案例,展示了这种方法在实际商业环境中的潜力,为营销资源的有效分配提供了更科学的指导。
但是我们还要识到,即使是经过因果推断优化的机器学习模型,也仍然是现实的简化表示。在MMM等复杂的商业应用中,模型结果应与其他数据分析方法、业务洞察和领域专家的判断相结合,以做出最佳决策。这种多角度的方法可以弥补单一模型的局限性,提供更全面的决策支持。
参考文献
[1] Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press.
[2] Pearl, J., Glymour, M., & Jewell, N. P. (2016). Causal Inference in Statistics: A Primer. Wiley.
[3] Facure, M. Causal Inference for the Brave and True. https://matheusfacure.github.io/python-causality-handbook/
代码与数据
本研究使用的完整代码和数据集可在以下GitHub仓库中获取:
https://avoid.overfit.cn/post/31ab4dd8c81d446f9b34cd04c6733608
作者:Felix Germaine