AI Infra 如何打造?云轴科技ZStack在中国CID大会上主题演讲
10月19日,2024年“中国云计算基础架构开发者大会(China Cloud Computing Infrastructure Developer Conference - 简称CID)”在北京举办。大会聚集业界最前沿的云计算基础架构技术成果,覆盖主论坛与四大技术主题分论坛,围绕云计算基础架构技术领域的技术交流,展示先进技术在行业中的典型实践,赋能行业客户业务变革。助力企业技术管理者、CTO、架构师做好技术选型,专注业务价值实现,加码可持续发展。云轴科技ZStack作为领先的基础软件提供商受邀参会,ZStack CTO王为以《云平台到AI原生平台的升级之路》为主题,围绕市场发展与用户态度,从场景需求、技术难度、用户体验等维度探讨ZStack如何基于原有的Cloud 平台发展 AIOS。

在AI时代,企业面临着前所未有的计算、存储和通信挑战。ZStack致力于成为智算时代全球领先的基础软件提供商,为用户提供数智化算力平台。自2015年成立以来一直致力于提供强大的云平台软件,以满足这些不断变化的需求。ZStack的云平台软件不断扩展产品功能和稳定性,支持虚拟化、容器、裸金属等多种形式。
AI 业务的特征与需求
那么随着 ChatGPT、StableDiffusion 这些 AI 应用的火热,我们开始思考,随着 AI 时代的到来,AI 业务的需求是怎么样的?
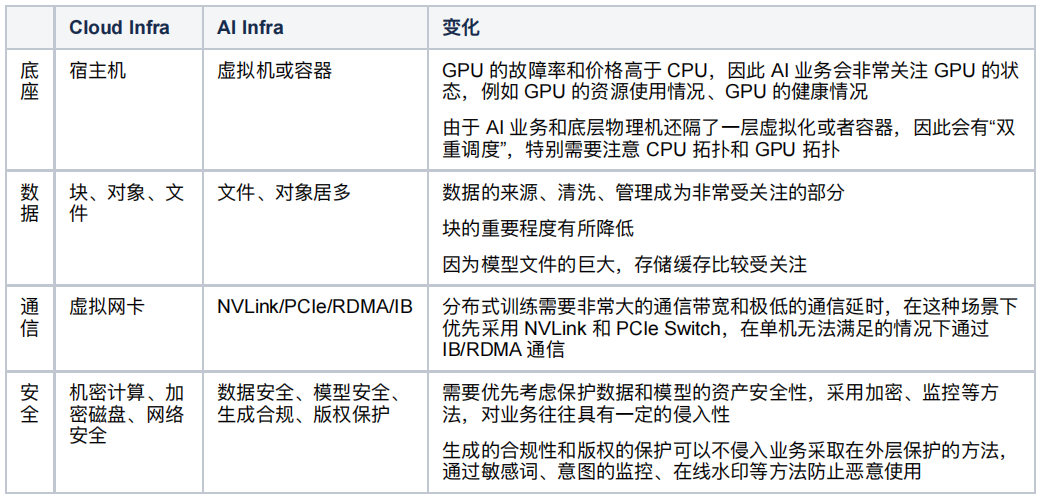
以上我们从资源角度分析了 AI 业务的特征,这些资源满足之后,我们可以做到将 AI 业务合规、正确地部署起来,但是这并不意味着能用好,我们把 AI 业务的上线流程做个梳理,发现可以把 AI 业务上线分为三个步骤:
-
筛选模型,目前 ModelScope 上有 15204 多个模型,Hugging Face 上有 105 万个模型,涉及多模态、计算机视觉、自然语言处理、音频生成等类别,寻找合适的底座、合适的参数是整个项目成功的关键因素;
-
规模训练、微调或构建数据库,筛选到合适的底座后需要进行规模训练和微调,例如做多模态内容检索,需要对大量素材生成向量并录入向量数据库,如果需要微调的话,以 72B 模型 8 卡微调 300M 语料需要 80h以上,如果需要训练的话根据模型参数、数据量可能需要大量的算力以及配套设施;
-
适配部署,部署时需要考虑所应对的请求数量,如果用户数量多、并发量大,可能需要很大的推理算力需求,特别是 Sora 类的文生图应用,需要高端显卡才能达到合理的生成速度,算力要求非常高。
按照这三个阶段,可以进一步总结他们的关注点:
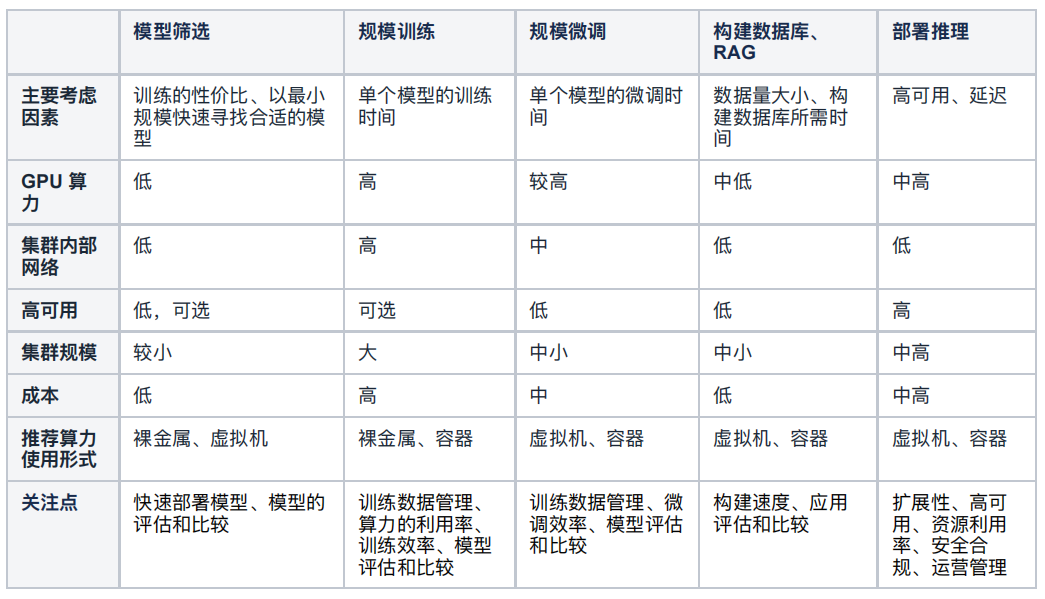
可以看到除了传统的资源相关的情况之外,模型部署便利程度、扩展性、模型评估等工作是传统 IaaS 云难以满足的,因此我们需要面向 AI 业务的 AI Infra。
计算能力
从计算范式上看,AI 业务最明显的特征就是计算中心从 CPU 转向了 GPU。不过虽然 Intel 的股价 表现不好,但是 2005 发布的 VT-x 绝对是 CPU 划时代的进展,它代表着虚拟化由纯软模拟转向了硬件辅助,随着 Intel、AMD 的数据中心 CPU 对虚拟化有了越来越好的支持(VT-x、VT-d、EPT、VMCS、ACPIv、AVIC),虚拟化的 CPU 效率和物理 CPU 相比已经不遑多让。

然而遗憾的是,在 GPU 上还没有看到这么易用、强大且几乎没有额外成本的替代技术,提到 GPU 的虚拟化,你会收获一大堆专用名词,其中一些和厂商强绑定(例如 MIG、MPS),一些是较为通用技术思路:
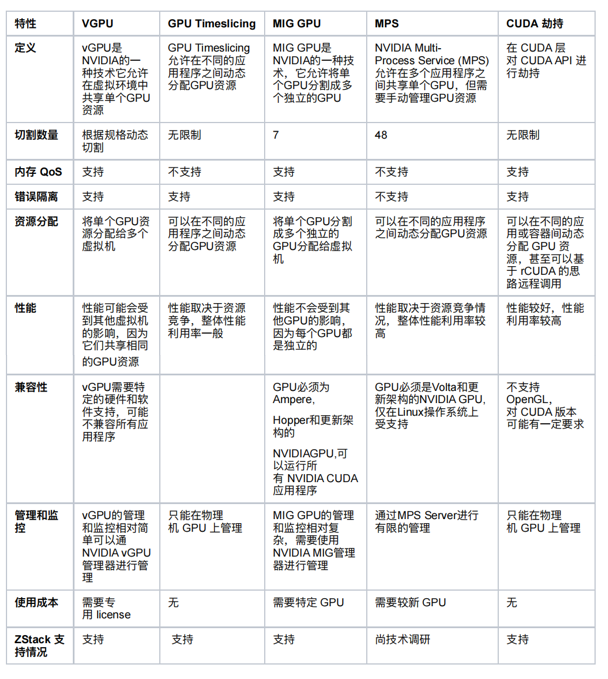
为什么会有这么多选择,其实究其根本我认为是 GPU 的物理特性和 GPU 的工作方法所决定的,首先看物理特性:
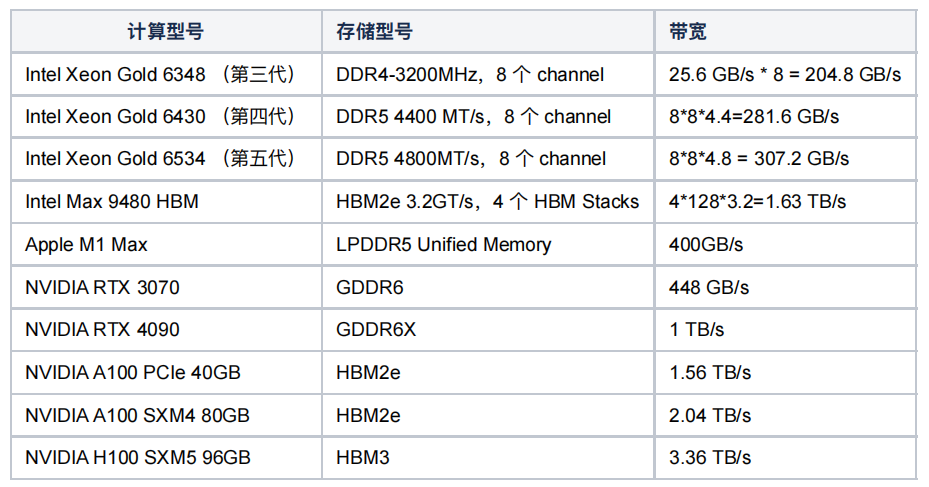
可以看到 Intel Max 9480 引入 HBM 内存因此 其带宽可以到 1.63TB 外,大部分情况下 CPU、内存的通信效率只有 200~300GB/s,而显存带宽可以轻易达到 1TB/s、2TB/s 这种速率上的不匹配产生了第一个影响——显存及其 L1、L2 Cache 速度极快,而 PCIe 和内存跟不上。
关于其工作方法,可以总结到下面这张图,由于 GPU 的核心工作是大量的并行计算,而大模型的大量参数需要确保首先装载到模型,再加上 GPU Context 的切换成本,导致大尺寸模型下“GPU 虚拟化”的价值较为微弱,对于小尺寸模型且最好是低算力需求的场景还可以发挥作用,在较大尺寸模型场景下效用不是那么突出。
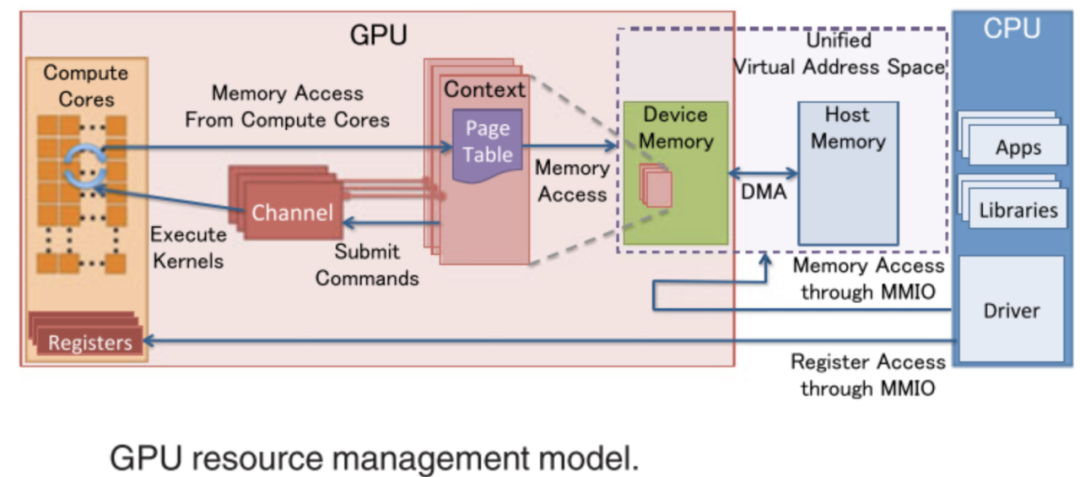
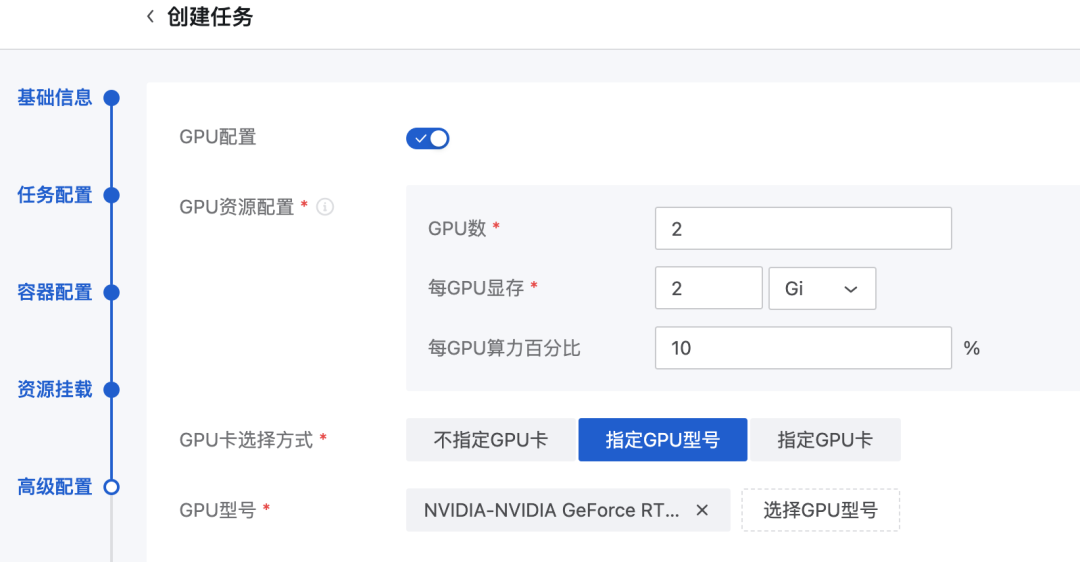
但是,考虑到客户提升资源利用率的需求,ZStack AIOS 提供了各种 GPU 切割的方式和支持,特别是在客户 GPU 数量较小,主要目的是教学、测试、研发等场景,尽可能提升 GPU 的使用效率,包括 vGPU、CUDA 共享等,确保用户可以灵活的使用资源:
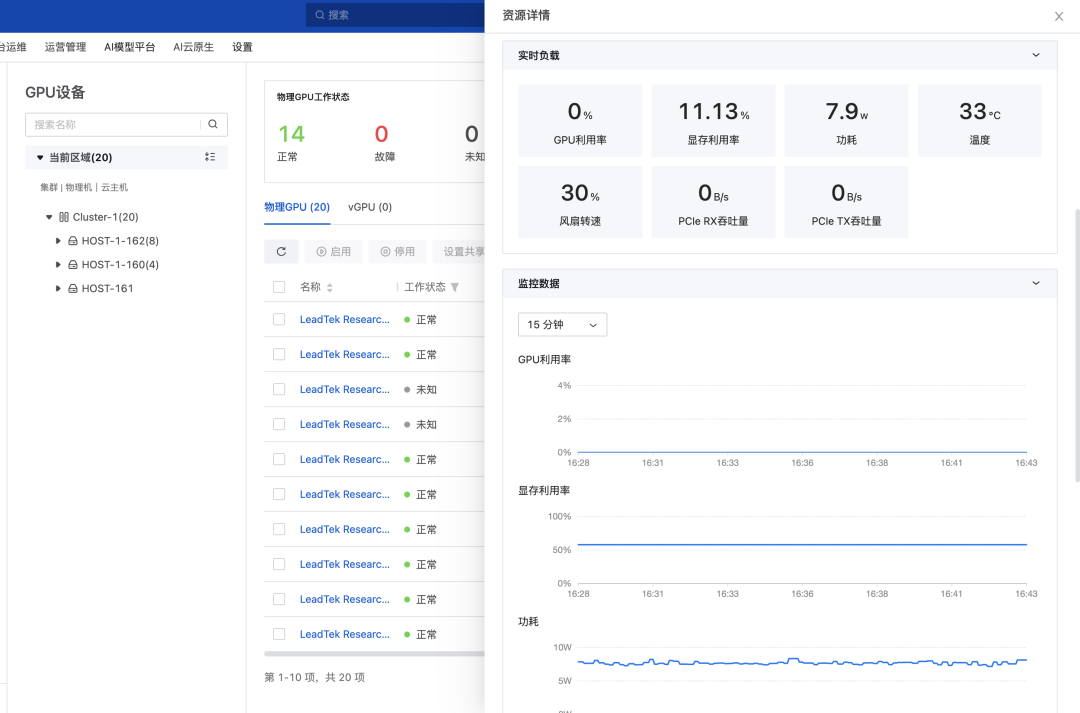
此外再说一下 GPU 的运维报警,由于 GPU 的故障率远高于 CPU,而且对于使用人员和运维人员来说越早发现故障、定位故障可以越早的减少损失、恢复业务(训练或推理),因此 GPU 的故障判断也是 AI Infra 一项非常重要的工作,我们主要通过 lspci、nvidia-smi(或其他厂家的 rocm-smi、efsmi 等)、日志等来检查故障,随时监控算力健康:
存储能力
在 AI 训练业务中会非常关注并行文件系统,这是因为:
-
多个节点需要并发读取训练数据和模型文件,产生巨大的 IO
-
模型训练时,需要定时保存 checkpoint,而 checkpoint 保存期间,GPU 不继续工作,因此不仅产生巨大的 IO,还伴随着巨大的浪费

关于模型训练如何减少 Checkpoint 时间、通过异步等方式减少 Checkpoint 等待以及如何优化并行文件系统已经有很多文章,这里主要分析一下大语言模型推理和微调为主的业务所对应的存储场景:
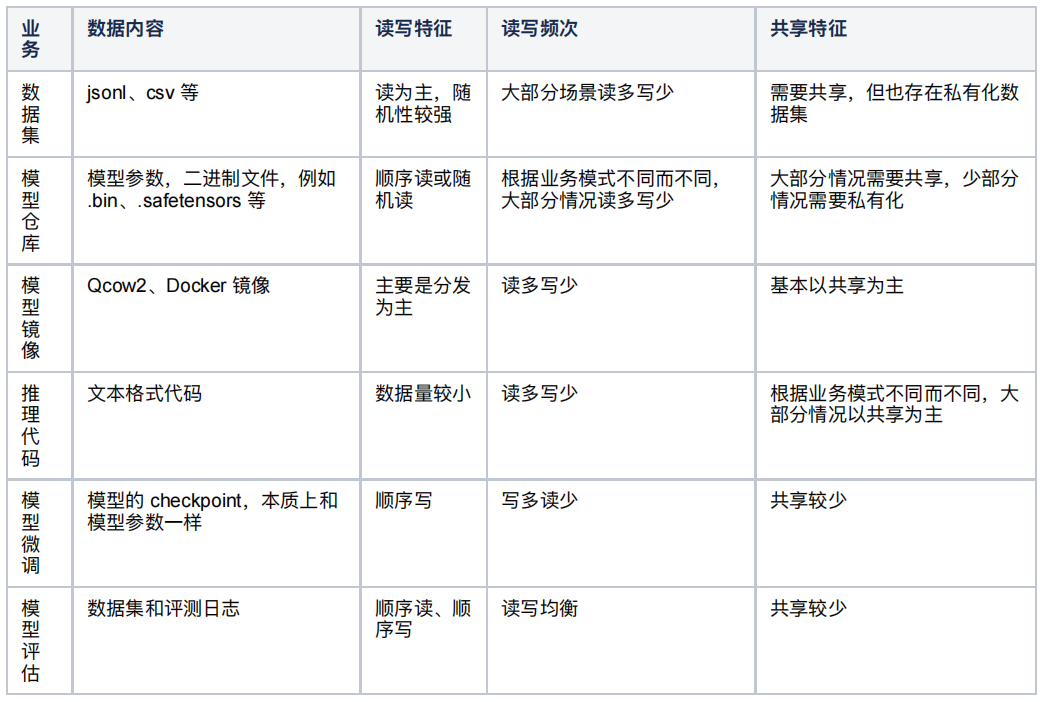
根据上面的这些业务需求,可以看到模型镜像(保存基础镜像、Python 依赖、CUDA 驱动、GPU 驱动等)本身和传统的镜像没有太大区别,可以沿用云的镜像存储,例如 ZStack ImageStore,保证较好的分发性能、读写性能,其他业务其实都需要一个共享的、最好是 POSIX 兼容、具备缓存能力的文件存储。因此 ZStack 开发了 ZStack Distributed File System 简称 ZDFS,确保在大、小文件、顺序和随机的读写场景均能有较好的性能表现。ZDFS 本身架构较为简单,由后端存储、ZDFS 元数据节点和 ZDFS Client 组成,其核心是通过元数据管理保障存储数据访问的隔离性和安全性,通过客户端缓存确保热数据读取和大文件写入的性能。
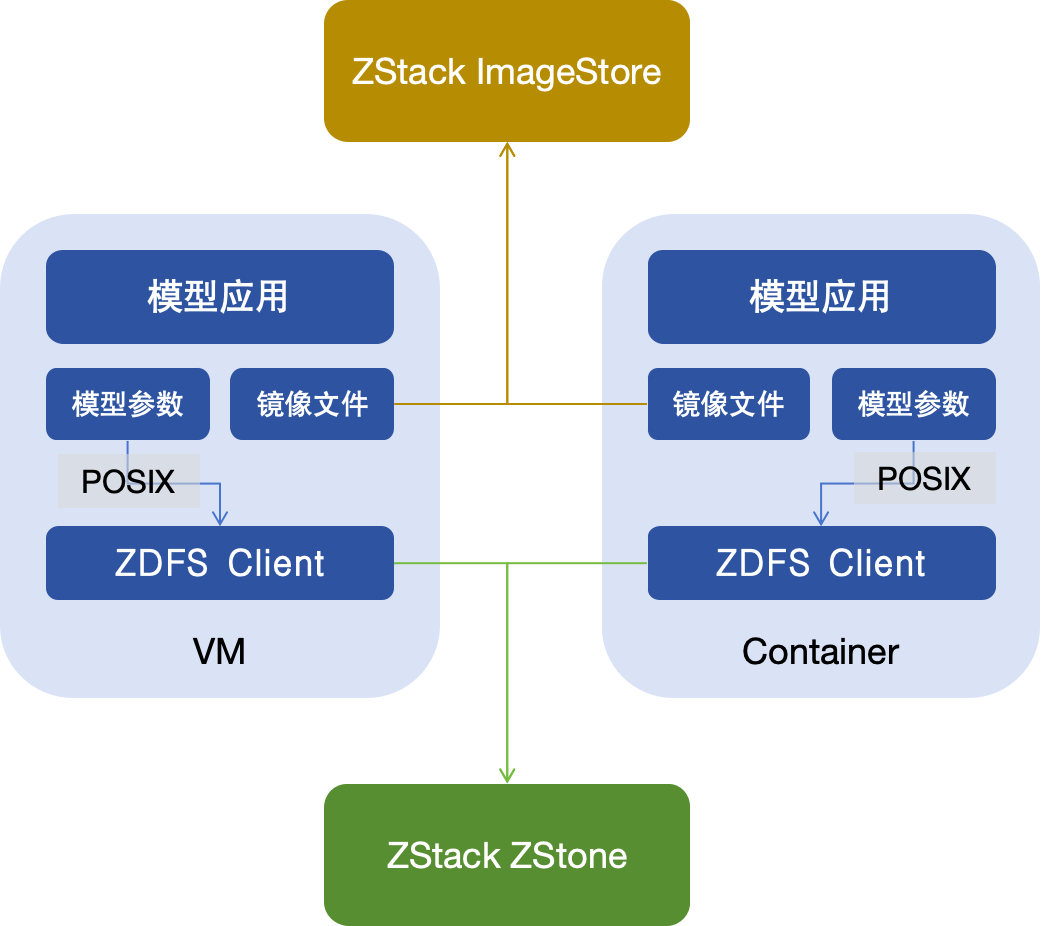
通信能力
在传统云计算里,通信主要是指网络,而且大部分情况是以太网络,但在 AI 场景,我们把通信会分的更为细致:
机器内通信
-
共享内存
-
PCIe
-
NVLink
机器间通信
-
TCP/IP
-
RDMA via RoCE
-
RDMA via InfinBand
训练场景里,机器间的通信网络是非常非常关键的因素,但现在训练门槛越来越高,大部分企业所需要的主要是推理和微调,因此更多要考虑的反而是机器内通信,借助 PCIe Switch,可以将通信延迟缩短到 1us 乃至 0.1us,但是需要注意 PCIe 通道的使用率,使用率高的时候会明显增加延迟,因此需要合理的规划 PCIe 链路的使用。
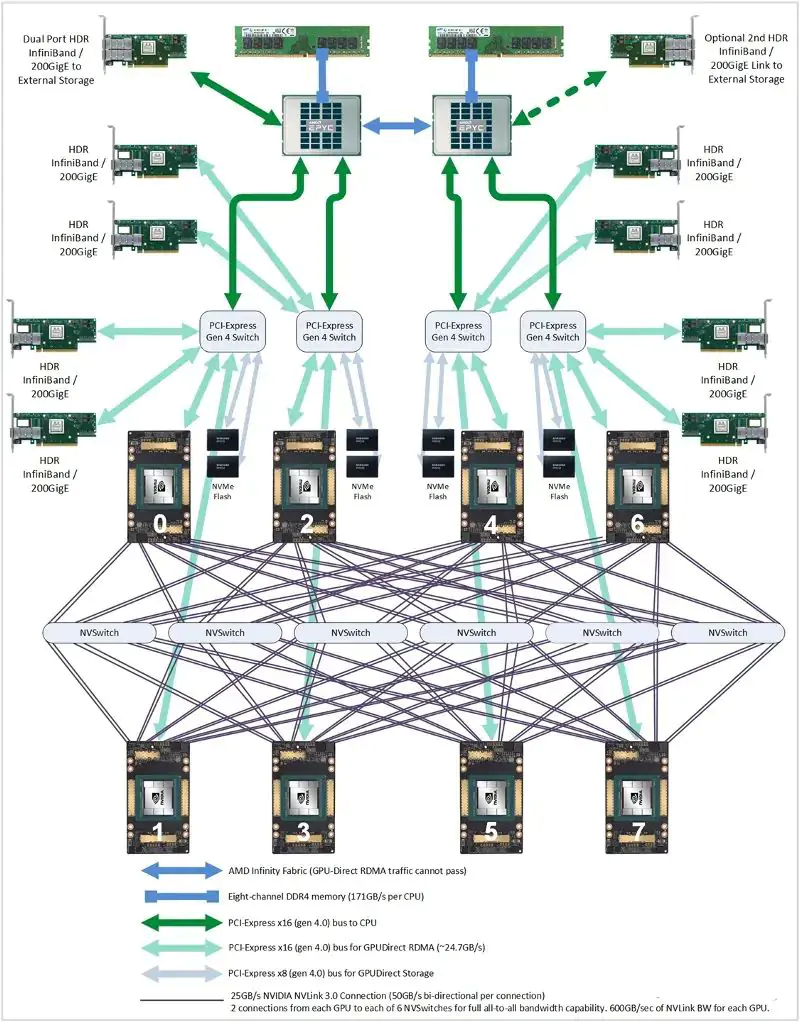
在模型部署时,可以配置多个 GPU 加速模型推理或满足大模型的显存需求。
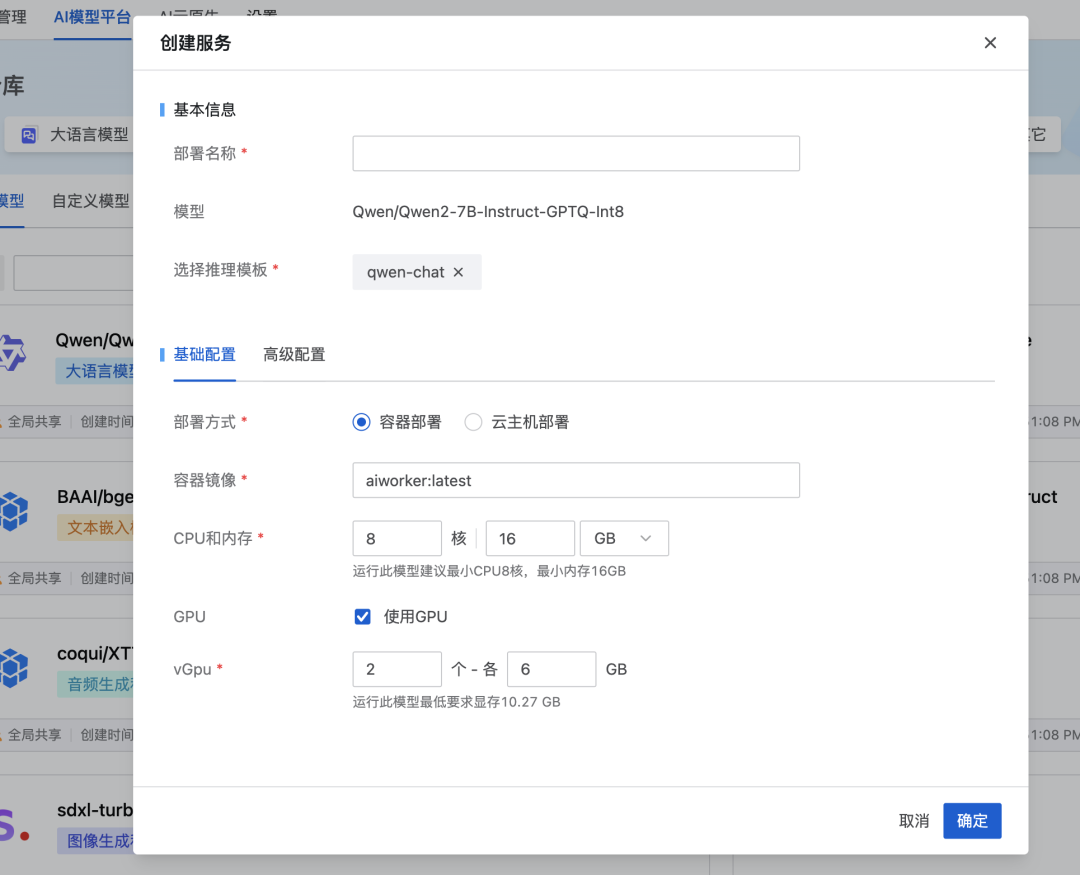
总结
-
根据业务阶段的不同,分别规划 AI Infra 的业务需求,分析需求
-
根据业务需要评估 GPU 共享的作用和效果
-
带缓存、支持共享的文件接口是目前 AI Infra 最青睐的存储方式
-
除了传统的机器间通信,充分利用机器内通信对 AI 业务非常重要