异步优化看板查询接口,从29s优化至2.8s
1、背景
平台主页看板接口,需要查询一段时间的任务执行情况,然后绘制图表。默认时间是过去一周时间,并且设置缓存。但是如果在页面自定义选择时间段,没有设置缓存。
该接口的业务需要查询出所有的测试项目,然后根据测试项目,进行查询该时间段内的每个项目对应的所有执行任务,根据任务的执行情况,返回成功失败比例。
所以就需要遍历所有的测试项目,目前测试项目有 200+, 后续的查询就需要遍历查询 200 多次测试记录的数据库。
业务方面检查没办法进行优化,只能进行性能优化。初步打算:线程池+countDownLanch 控制进行异步查询优化。
2、技术选型
进行优化分析:
1、添加数据库索引优化性能,发现数据库原本已经添加了索引,并且每次查询耗时并不是很长,主要时间可能发生在了数据库 IO 上。
2、数据库优化已经无法进行,只能进行业务代码性能优化。
3、初步打算将测试项目分解为 10 条一组,由一个线程负责处理,将 200+条查询改为异步执行。
4、使用 countDownLanch 控制主线程流程,确保主线程在查询执行完成之后再恢复进行
2.1、线程池
线程池核心参数主要参考 ThreadPoolExecutor 这个类的 7 个参数的构造函数

- corePoolSize 核心线程数目
- maximumPoolSize 最大线程数目 = (核心线程+救急线程的最大数目)
- keepAliveTime 生存时间 - 救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
- unit 时间单位 - 救急线程的生存时间单位,如秒、毫秒等
- workQueue - 当没有空闲核心线程时,新来任务会加入到此队列排队,队列满会创建救急线程执行任务
- threadFactory 线程工厂 - 可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
- handler 拒绝策略 - 当所有线程都在繁忙,workQueue 也放满时,会触发拒绝策略
工作流程

@Configuration
public class ThreadPoolConfig {
/**
* 核心线程池大小
*/
private static final int CORE_POOL_SIZE = 10;
/**
* 最大可创建的线程数
*/
private static final int MAX_POOL_SIZE = 20;
/**
* 队列最大长度
*/
private static final int QUEUE_CAPACITY = 1000;
/**
* 线程池维护线程所允许的空闲时间
*/
private static final int KEEP_ALIVE_SECONDS = 500;
@Bean("taskExecutor")
public ExecutorService executorService(){
AtomicInteger c = new AtomicInteger(1);
LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>(QUEUE_CAPACITY);
return new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_SECONDS,
TimeUnit.MILLISECONDS,
queue,
r -> new Thread(r, "autotest-pool-" + c.getAndIncrement()),
new ThreadPoolExecutor.DiscardPolicy()
);
}
}
2.2、CountDownLanch
CountDownLatch(闭锁/倒计时锁)用来进行线程同步协作,等待所有线程完成倒计时
(一个或者多个线程,等待其他多个线程完成某件事情之后才能执行)
- 其中构造参数用来初始化等待计数值
- await () 用来等待计数归零
- countDown () 用来让计数减一
3、设计
1、计算项目(workflows)总条数。
2、根据总条数分割成 10 条的一页,分成 totalPageSize 页,并且 CountDownLatch 设置为 totalPageSize。
3、遍历 totalPageSize 页,将原本执行的任务分割成 10 条一个线程查询处理,添加任务到线程池中。
4、每次执行完一个任务 cdl.countDown () 减一,最后 cdl 到 0 的时候主线程恢复运行。
//总条数
int count = workflows.size();
//总页数
int totalPageSize = count % PAGE_SIZE == 0 ? count / PAGE_SIZE : count / PAGE_SIZE + 1;
//开始执行时间
long startTime = System.currentTimeMillis();
//一共有多少页,就创建多少个CountDownLatch的计数
CountDownLatch countDownLatch = new CountDownLatch(totalPageSize);
int fromIndex;
List<Workflow> taskWorkFlows = null;
for (int i = 0; i < totalPageSize; i++) {
//起始分页条数
fromIndex = i * PAGE_SIZE;
//分割任务
taskWorkFlows = workflows.subList(fromIndex, Math.min(fromIndex + PAGE_SIZE, count));
//创建线程,做批量操作
TaskThread taskThread = new TaskThread(taskWorkFlows, countDownLatch,tasks,startDate,endDate);
//执行线程
executorService.execute(taskThread);
}
//调用await()方法,用来等待计数归零
countDownLatch.await();
long endTime = System.currentTimeMillis();
log.info("共:{}条,共消耗时间:{}毫秒", count, (endTime - startTime));
class TaskThread implements Runnable {
List<Workflow> taskWorkFlows;
CountDownLatch cdl;
List<StatisticsVo.DagStateCountVo> tasks;
Date startDate;
Date endDate;
public TaskThread(List<Workflow> taskWorkFlows, CountDownLatch cdl,List<StatisticsVo.DagStateCountVo> tasks,Date startDate,Date endDate) {
this.taskWorkFlows = taskWorkFlows;
this.cdl = cdl;
this.tasks = tasks;
this.startDate = startDate;
this.endDate = endDate;
}
@SneakyThrows
@Override public void run() {
taskWorkFlows.forEach(workflow -> {
List<DagStateCountDTO> taskData = DataUtil.translateListMapToListBeanWithSnakeCase(DagStateCountDTO.class, dagRepo.countByDagState(workflow.getId(), startDate, endDate));
if (!ObjectUtils.isEmpty(taskData)) {
tasks.add(convertDtoToVo(workflow, taskData));
}
});
//让计数减一
cdl.countDown();
}
}
4、效果
优化前:
查询接口耗时:27s
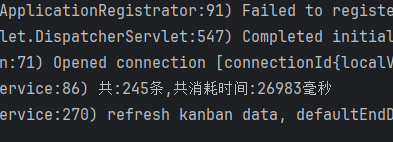
优化后
查询接口耗时:2.8 s
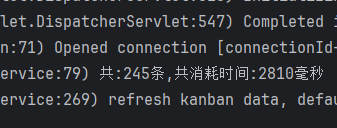
效果十分显著。