记一次Video-LLaMa部署过程

依旧是很久之前就star的一个项目,一直躺在GitHub的列表中,苦于显存不足的原因,今日终于借着别人的显卡运行起来,故记录一下。
先说配置GPU4090-2张,一张24G就够用,如果不够,可以走人了废话不多说,项目简介:
作者: Hang Zhang, Xin Li, Lidong Bing
论文地址: https://arxiv.org/abs/2306.02858
项目地址: https://github.com/DAMO-NLP-SG/Video-LLaMA
摘要
本文为视频LLaMA提供了一个多模式框架,使大型语言模型(LLMs)能够理解视频中的视觉和听觉内容。Video-LLaMA从冻结的预先训练的视觉和音频编码器以及冻结的LLMs中引导跨模态训练。与以前的作品补充LLMs仅处理视觉或音频信号不同,Video-LLaMA通过解决两个挑战来实现视频理解:(1)捕捉视觉场景中的时间变化,(2)整合视听信号。为了应对第一个挑战,提出了一种视频Q-former,将预先训练的图像编码器组装到的视频编码器中,并引入视频到文本生成任务来学习视频语言对应关系。对于第二个挑战,利用ImageBind(一种对齐多个模态的通用嵌入模型)作为预训练的音频编码器,并在ImageBind之上引入音频Q-former,以学习LLM模块的合理听觉查询嵌入。为了使视觉和音频编码器的输出与LLM’s的嵌入空间对齐,首先在大量视频/图像字幕对上训练Video-LLaMA,然后用适量但更高质量的视觉指令数据集调整我们的模型。发现,Video-LLaMA显示了感知和理解视频内容的能力,并基于视频中呈现的视觉和听觉信息产生有意义的反应。
开始
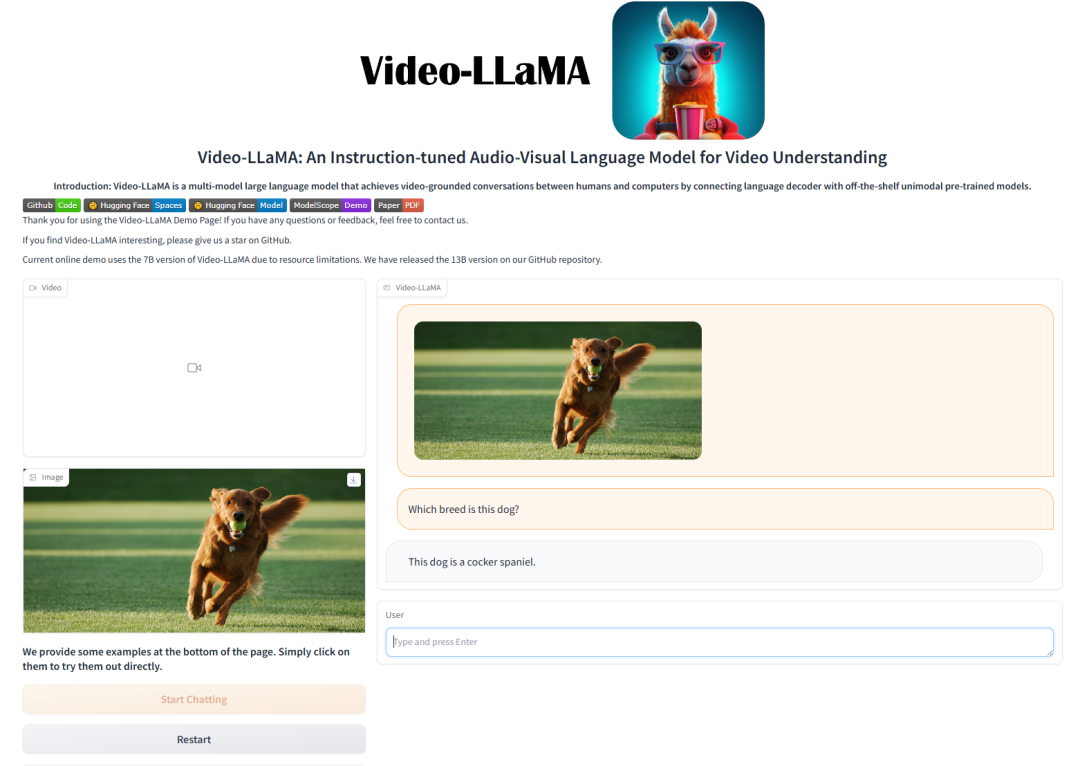
\1. 首先这里是官方提供的在线demo:https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA(我没有直接从huggingface克隆代码,我的环境不支持这样做 )
)
\2. 直接从github克隆代码下来
git clone https://github.com/DAMO-NLP-SG/Video-LLaMA.git
\3. 接着我从huggingface上的官方demo中copy三部分内容,将这三个文件下载下来放到项目目录中,这里是前期我为了保证可运行做的
\4. 直接cd到项目中,运行代码,查看确实什么包,一一安装,如果嫌麻烦,可直接requirement.txt 安装所有
cd path/Video-LLaMA
pip install -i requirement.txt
python app.py
\5. 如果包都安装完成后这里就会提示缺少模型文件了,很多个模型文件,下面是之前下载的配置文件中的部分(video_llama_eval.yaml)

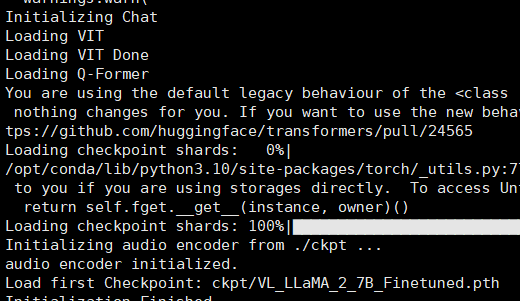
① blip2_pretrained_flant5xxl.pth从步骤3中ckpt中下载,里面另一个模型finetune-vicuna7b-v2.pth本来对应着此处的 ckpt: xxx,但是下载下来使用,回答都是各种乱码,显然是模型版本不对的问题。
② llama-2-7b-chat-hf 和 VL_LLaMA_2_7B_Finetuned.pth 从DAMO-NLP-SG/Video-LLaMA-2-7B-Finetuned · Hugging Face 下载(这里有四个版本可以下载)

③ VIT这个模型可以不用管,会在线下载的
\6. 到此别以为万事大吉了,还需要修改代码中的一些配置
vim video_llama/models/video_llama.py
搜索 bert-base-uncased,需要从HuggingFace上下载这部分模型,
并将路径替换成本地:/home/xxx/bert-base-uncased
搜索 imagebind_ckpt_path 将路径替换成本地ckpt的路径:imagebind_ckpt_path = './ckpt',
\7. 一些其它错误
- pip install --upgrade gradio==3.37.0
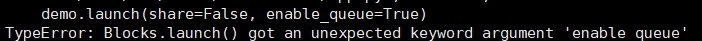
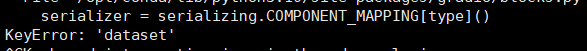
- 替换本地examples中的文件名即可
\8. 运行: python app.py,如果不出其它意外,且显存够的话应该出现以下日志,访问后显示,那么恭喜你成功99%,浏览器访问:127.0.0.1:3535 试着点击默认视频,看看运行是否正常,这样才100%成功,至于还有什么问题可以自行搜索和私信我

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。