Cloudera Hue深度解析:安装、配置到高级用法
Hue的介绍
HUE 是一个开源的 Apache Hadoop UI 系统,早期由 Cloudera 开发,它是基于 Python Web 框架 Django 实现,后来贡献给开源社区。它包括 3 个部分 hue ui,hue server, hue db。通过使用 Hue 我们可以通过浏览器方式操纵 Hadoop 集群,查看修改 hdfs 的 文件,管理 hive 的元数据,运行 Sqoop,编写 Oozie 工作流等大量工作。
Hue 的安装依赖 hive 和 oozie,首先需要安装 Hive 和 oozie。
1. 选择集群,添加服务:

2. 添加服务向导: 选择“hue”服务,点击“继续”:

选择依赖的 HDFS,点击“继续”:

角色按照默认配置即可,点击“继续”,完成 hue 的安装。


Hue的使用
以上将 hue 安装在 cm1 节点上,这里登陆 hue 时,地址为:http://cm1:8888,首次 登陆 hue 需要登陆 hue 的账号密码,这里输入 user:myhue,password:myhue。最 好这里使用 hdfs 用户。因为 hdfs 用户可以操作 hdfs 中的文件,如果使用其他用户只 能在当前用户的目录下创建文件。
1. hue创建用户
点击“管理用户”可以创建用户,并且可以指定权限,是否在 HDFS 中创建主目录。


2. hue操作HDFS文件
可以创建新的文件,也可以修改,最好 HDFS 中大文件不要在 hue 中操作。hue 中
的用户默认是进入当前用户的主目录进行操作。
3. hue操作hive中的数据
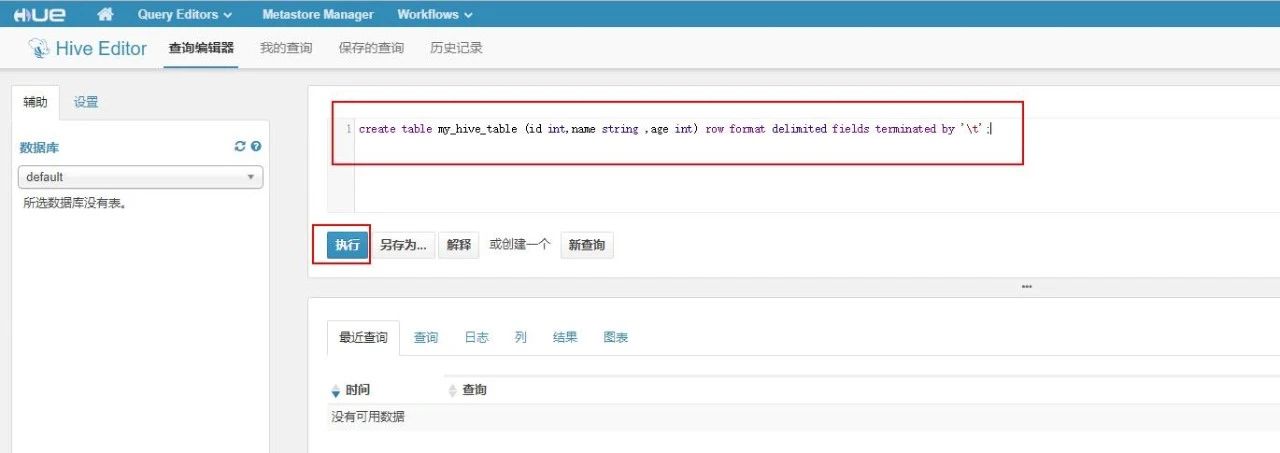
登录 hue 之后,点击“Query Editors”->“Hive”,编写 sql 创建 Hive 表:
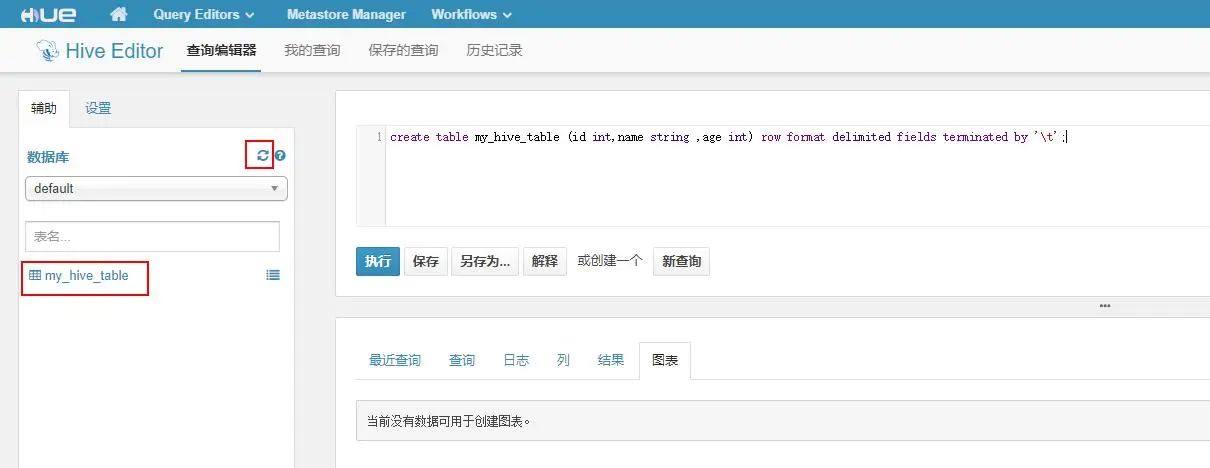
创建完成后,点击 hive 数据库刷新,可以看到刚才创建的 Hive 表:
创建表完成之后,可以点击“Metastore Manager”,点击刚才创建的表名,可 以导入数据,选择的数据可以是 HDFS 中也可以是本地中的文件数据:

上传完数据之后,选择上传的数据,导入到表中。
点击浏览表中的数据如下:
点击“Query Editors”,在查询编辑器中执行查询 sql 语句:


之后 sql 语句之后,hql 转换成 MR 作业,可以点击“Job Browser”查看任务:

点击点击“Query Editors”->“Hive”->“查看结果”,可以看到任务执行的结果:

4. hue添加rdbms数据库
登录 hue 之后,点击“Query Editors”->“DB 查询”,发现没有 rdbms 数据 库。

配置关系型数据库步骤如下:
进入 CDH,找到 Hue 选项,点击配置:

在配置中搜索“hue_safety_valve.ini”配置项,保存更改,配置如下内容:
1.[librdbms]
2.[[databases]]
3.[[[mysql]]]
4.nice_name="all mysql databases" 5. engine=mysql
5.host=192.168.179.14
6.port=3306
7.user=root
8.password=123456
9.options={ "init_command":"SET NAMES 'utf8'"}
以上参数中,nice_name 指定在 hue 中显示的连接名称。name 指定连接的 mysql 数据库名称,不指定这个参数,将默认显示全部的数据库。engine 指定 mysql 数据库类型。host 指定数据库地址。port 指定数据库端口号。user 指定连接用 户名。password 指定密码。options 中指定的“init_command”指定数据库 编码为 utf-8,防止有中文时乱码。
以上配置完成之后,重启 hue。在 hue webui 中点击“Query Editors”->“DB 查询”,可以看到出现配置的 mysql 数据库。

以上就是今天分享的全部内容。
想了解更多关于大数据技术的内存扩容、缩容策略,详尽解析了故障诊断与问题排查的方法论的问题,可以找我:15928721005
