线性回归(一)
线性回归
1.基本术语
①特征:预测所依据的自变量称为特征或协变量
②标签:试图预测的目标称为标签或目标

2.举个栗子
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:

绘制图像如下图所示:
可知平面无法拟合所有的数据点,所以需求变成让尽可能多的点落在平面上,这个需要权重和偏置项来调整平面位置和倾斜度。
③权重决定了每个特征对我们预测值的影响
④偏置是指当所有特征都取值为0时,预测值应该为多少,对图像进行平移功能。

常见的为点积形式:

整合2.1.2式子可得

(2.1.3)
⑤误差(损失函数)
量化实际值与预测值之间存在的差距(用ε表示该误差)
对于每个样本存在该式:
 (2.1.4)
(2.1.4)
(真实值=预测值+误差项),误差值越小表示损失越小。
误差ε是独立并且具有相同的分布,并且服从均值为0方差为θ^2的高斯分布。独立表示一个变量的值不会影响另一个变量的值,同分布表示具有相同的统计特性,高斯分布:绝大多数情况下浮动不会太大,极小情况下浮动会比较大,符合正常情况
由于误差服从高斯分布:
(2.1.5)
将2.1.4代入2.1.5可得:
(2.1.6)
可以找到一个关于θ似然函数:
(2.1.7)
由于我们仅仅关注极值点的位置,并不关注极值的大小,所以可以给两边取对数,就可以将累乘变成累加,得到:
(2.1.8)
由logAB=logA+logB可得:
(2.1.9)
2.1.9公式可以看作是一个常数减去一个平方数的形式,所以要找2.1.9式的极大值,就可以看作找后面平方数的极小值,可得:
当样本i的预测值为y^i,其相应的真实标签为ytrue^i时, 平方误差可以定义为以下公式:
(2.1.10)
将2.1.4式代入2.1.11中可得
(2.1.11)
3.梯度下降算法
梯度下降算法的核心思想是:从一个初始点开始,沿着目标函数的梯度(最陡上升方向)的反方向迭代地更新参数,直到达到最小值。
首先由上面的推导,我们可以得出线性回归的目标函数为:

(3.1.1)
我们的目标是找后面平方数的极小值,所以对4.1.1式进行求导可得:
其中m为样本的数量,我们对J求关于θ的偏导得到梯度方程式

(3.1.2)
梯度下降算法原理就是每次迭代过程对参数向梯度反方向前进梯度个步数生成新的参数、直到找到最拟合目标函数的参数为止。
批量梯度下降:每次前进总样本的平均梯度,容易得到最优解,但是速度很慢,在数据量大的时候一般不使用,参数迭代方程式如下:
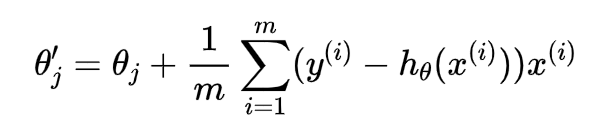
(3.1.3)
随机梯度下降:每次找一个样本的梯度进行迭代,速度快,但是随机性强,每次迭代不一定向着收敛的方向,参数迭代方程式如下:
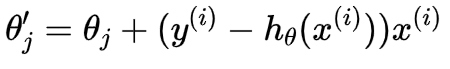
(3.1.4)
小批量梯度下降:每次使用一小部分的平均梯度进行迭代,速度快,迭代方向也比较好,经常被使用,参数迭代方程式(12)如下:
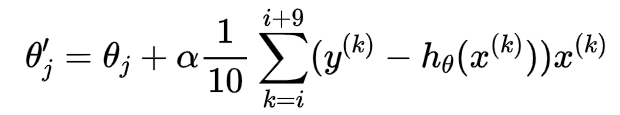
(3.1.5)
其中α为学习率
4.代码实现
import numpy as np
def normalize(features):
"""
特征归一化
:param features: 传入特征
:return: 归一化后的特征,特征均值,特征标准差
"""
features_normalized = np.copy(features).astype(float)
# 计算均值
features_mean = np.mean(features, 0)
# 计算标准差
features_deviation = np.std(features, 0)
# 标准化操作
if features.shape[0] > 1:
features_normalized -= features_mean
# 防止除以0
features_deviation[features_deviation == 0] = 1
features_normalized /= features_deviation
return features_normalized, features_mean, features_deviationimport numpy as np
import normalize
def generate_polynomials(dataset, polynomials_degree, normalize_data=False):
"""
变换方法:x1, x2, x1^2, x2^2, x1 * x2, x1 * x2^2, etc.
:param dataset:原始数据
:param polynomials_degree:多项式的维度
:param normalize_data:是否归一化
:return:生成的多项式参数
"""
features_split = np.array_split(dataset, 2, axis=1)
dataset_1 = features_split[0]
dataset_2 = features_split[1]
(num_examples_1, num_features_1) = dataset_1.shape
(num_examples_2, num_features_2) = dataset_2.shape
if num_examples_1 != num_examples_2:
raise ValueError("can not generate polynomials for two sets with different number")
if num_features_1 == 0 and num_features_2 == 0:
raise ValueError("can not generate polynomials for two sets with no colums")
if num_features_1 == 0:
dataset_1 = dataset_2
elif num_features_2 == 0:
dataset_2 = dataset_1
num_features = num_features_1 if num_features_1 < num_examples_2 else num_features_2
dataset_1 = dataset_1[:, :num_features]
dataset_2 = dataset_2[:, :num_features]
polynomials = np.empty((num_examples_1, 0))
for i in range(1, polynomials_degree + 1):
for j in range(i + 1):
polynomial_feature = (dataset_1 ** (i - j)) * (dataset_2 ** j)
polynomials = np.concatenate((polynomials, polynomial_feature), axis=1)
if normalize_data:
polynomials = normalize.normalize(polynomials)[0]
return polynomialsimport numpy as np
def generate_sinusoids(dataset, sinusoid_degree):
"""
变换方式 sin(x)
:param dataset: 原始数据
:param sinusoid_degree:变换维度
:return: 变换后的参数
"""
num_examples = dataset.shape[0]
sinusoids = np.empty((num_examples, 0))
for degree in range(1, sinusoid_degree + 1):
sinusoid_fatures = np.sin(degree * dataset)
sinusoids = np.concatenate((sinusoids, sinusoid_fatures), axis=1)
return sinusoids
import numpy as np
import normalize
import generate_polynomials
import generate_sinusoids
def prepare_for_train(data, polynomial_degree=0, sinusoid_degree=0, normalize_data=True):
"""
对数据进行预处理
:param data: 原始数据
:param polynomial_degree: 多项式维度
:param sinusoid_degree: 正弦维度
:param normalize_data: 是否进行归一化
:return: 处理后的数据,特征均值,特征方差
"""
# 获取样本总数
num_examples = data.shape[0]
data_processed = np.copy(data)
# 预处理
features_mean = 0
features_deviation = 0
data_normalized = data_processed
if normalize_data:
data_normalized, features_mean, features_deviation = normalize.normalize(data_processed)
data_processed = data_normalized
# 特征变量正弦变换
if sinusoid_degree > 0:
sinusoids = generate_sinusoids.generate_sinusoids(data_normalized, sinusoid_degree)
data_processed = np.concatenate((data_processed, sinusoids), axis=1)
# 特征变量多项式变换
if polynomial_degree > 0:
polynomials = generate_polynomials.generate_polynomials(data_processed, polynomial_degree, normalize_data)
data_processed = np.concatenate((data_processed, polynomials), axis=1)
# 加一列1
data_processed = np.hstack((np.ones((num_examples, 1)), data_processed))
return data_processed, features_mean, features_deviationimport numpy as np
import prepare_train
class LinearRegression:
def __init__(self, data, labels, polynomial_degree=0, sinusoid_degree=0, normalize_data=True):
"""
1、对数据进行预处理操作
2、得到特征个数
3、初始化参数矩阵
:param data:原始数据
:param labels:数据的标签
:param polynomial_degree:多项式维度
:param sinusoid_degree:正弦维度
:param normalize_data:是否进行归一化
"""
(data_processed, features_mean, features_deviation) = prepare_train.prepare_for_train(data, polynomial_degree,
sinusoid_degree,
normalize_data)
self.data = data_processed
self.labels = labels
self.features_mean = features_mean
self.features_deviation = features_deviation
self.polynomial_degree = polynomial_degree
self.sinusoid_degree = sinusoid_degree
self.normalize_data = normalize_data
num_features = self.data.shape[1]
self.theta = np.zeros((num_features, 1))
def train(self, alpha, num_epoch=500):
"""
开始训练
:param alpha: 学习速率
:param num_epoch: 迭代次数
:return: 训练好的参数,损失值记录
"""
cost_history = self.gradient_descent(alpha, num_epoch)
return self.theta, cost_history
def gradient_descent(self, alpha, num_epoch):
"""
小批量梯度下降算法
:param alpha: 学习速率
:param num_epoch: 迭代次数
:return: 损失值的记录
"""
cost_history = []
for i in range(num_epoch):
self.gradient_step(alpha)
cost_history.append(self.cost_function(self.data, self.labels))
return cost_history
def gradient_step(self, alpha):
"""
梯度下降参数更新方法
:param alpha: 学习率
:return: 无
"""
num_examples = self.data.shape[0]
prediction = LinearRegression.hypothesis(self.data, self.theta)
delta = prediction - self.labels
theta = self.theta
theta = theta - alpha * (1 / num_examples) * (np.dot(delta.T, self.data)).T
self.theta = theta
def cost_function(self, data, labels):
"""
计算损失值函数(最小二乘法)
:param data:当前数据
:param labels:当前标签
:return:预测损失值
"""
num_example = data.shape[0]
delta = LinearRegression.hypothesis(data, self.theta) - labels
cost = (1 / 2) * np.dot(delta.T, delta)
return cost[0][0]
@staticmethod
def hypothesis(data, theta):
"""
求预测值
:param data: 输入数据
:param theta: 当前参数
:return: 预测值
"""
prediction = np.dot(data, theta)
return prediction
def get_cost(self, data, labels):
"""
获取损失值
:param data: 传入的数据
:param labels: 数据的标签
:return: 当前模型预测数据的损失值
"""
(data_processed, _, _) = prepare_train.prepare_for_train(data, self.polynomial_degree, self.sinusoid_degree,
self.normalize_data)
return self.cost_function(data_processed, labels)
def predict(self, data):
"""
预测函数
:param data: 输入数据
:return: 预测的值
"""
(data_processed, _, _) = prepare_train.prepare_for_train(data, self.polynomial_degree, self.sinusoid_degree,
self.normalize_data)
predictions = LinearRegression.hypothesis(data_processed, self.theta)
return predictions今天在b站上刷到了唐宇迪博士数据分析与机器视频课程,并进行对应学习,捋了一天公式,概率论的好多公式都忘了,hhhh