【力扣 + 牛客 | SQL题 | 每日4题】牛客大厂面试真题W3,W10
1. 牛客大厂面试真题SQLW3:分析客户逾期情况
1.1 题目:
描述
有贷款信息表:loan_tb(agreement_id:合同id,customer_id:客户id,loan_amount:贷款金额,pay_amount:已还金额,overdue_days:逾期天数)
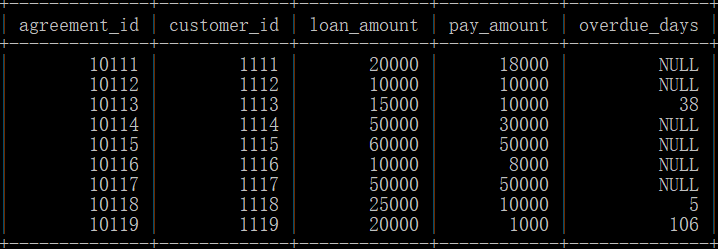
客户信息表:customer_tb(customer_id:客户id,customer_age:客户年龄,pay_ability:还款能力级别)
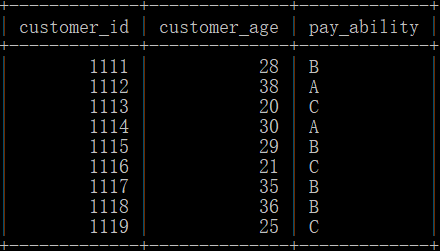
请根据以上数据分析各还款能力级别的客户逾期情况,按照还款能力级别统计有逾期行为客户占比?
要求输出还款能力级别、逾期客户占比;
注:逾期客户占比要求按照百分数形式输出并四舍五入保留 1 位小数,最终结果按照占比降序排序;
示例数据结果如下:
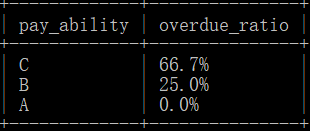
结果解释:
还款能力级别为 C 的客户有1113、1116、1119,其中有逾期行为的客户为 1113、1119,故结果为 2/3=66.7%;
其他结果同理。
示例1
输入:
drop table if exists `loan_tb` ;
CREATE TABLE `loan_tb` (
`agreement_id` int(11) NOT NULL,
`customer_id` int(11) NOT NULL,
`loan_amount` int(11) NOT NULL,
`pay_amount` int(11) NOT NULL,
`overdue_days` int(11),
PRIMARY KEY (`agreement_id`));
INSERT INTO loan_tb VALUES(10111,1111,20000,18000,null);
INSERT INTO loan_tb VALUES(10112,1112,10000,10000,null);
INSERT INTO loan_tb VALUES(10113,1113,15000,10000,38);
INSERT INTO loan_tb VALUES(10114,1114,50000,30000,null);
INSERT INTO loan_tb VALUES(10115,1115,60000,50000,null);
INSERT INTO loan_tb VALUES(10116,1116,10000,8000,null);
INSERT INTO loan_tb VALUES(10117,1117,50000,50000,null);
INSERT INTO loan_tb VALUES(10118,1118,25000,10000,5);
INSERT INTO loan_tb VALUES(10119,1119,20000,1000,106);
drop table if exists `customer_tb` ;
CREATE TABLE `customer_tb` (
`customer_id` int(11) NOT NULL,
`customer_age` int(11) NOT NULL,
`pay_ability` varchar(2) NOT NULL,
PRIMARY KEY (`customer_id`));
INSERT INTO customer_tb VALUES(1111,28,'B');
INSERT INTO customer_tb VALUES(1112,38,'A');
INSERT INTO customer_tb VALUES(1113,20,'C');
INSERT INTO customer_tb VALUES(1114,30,'A');
INSERT INTO customer_tb VALUES(1115,29,'B');
INSERT INTO customer_tb VALUES(1116,21,'C');
INSERT INTO customer_tb VALUES(1117,35,'B');
INSERT INTO customer_tb VALUES(1118,36,'B');
INSERT INTO customer_tb VALUES(1119,25,'C');
复制输出:
pay_ability|overdue_ratio
C|66.7%
B|25.0%
A|0.0%1.2 思路:
分组以后就是简单的计算。
1.3 题解:
with tep1 as (
-- 先将两表连接
select pay_ability, overdue_days
from loan_tb t1
join customer_tb t2
on t1.customer_id = t2.customer_id
)
-- 分组,然后就是简单的计算。
select pay_ability,
concat(round((select count(*) from tep1 t2 where overdue_days is not null and t1.pay_ability=t2.pay_ability) /
count(*) * 100, 1), '%') overdue_ratio
from tep1 t1
group by pay_ability
order by overdue_ratio desc2. 牛客大厂面试真题SQLW10:统计各岗位员工平均工作时长
2.1 题目:
描述
某公司员工信息数据及单日出勤信息数据如下:
员工信息表staff_tb(staff_id-员工id,staff_name-员工姓名,staff_gender-员工性别,post-员工岗位类别,department-员工所在部门),如下所示:
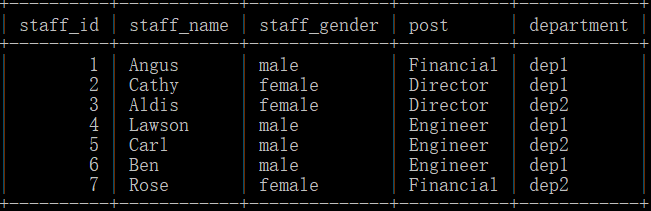
出勤信息表attendent_tb(info_id-信息id,staff_id-员工id,first_clockin-上班打卡时间,last_clockin-下班打卡时间),如下所示:
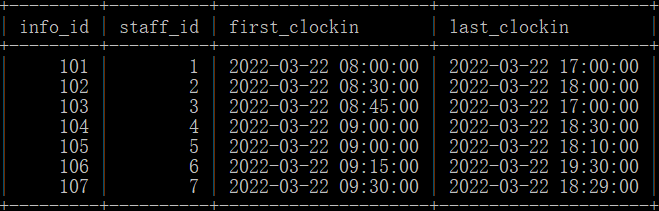
问题:请统计该公司各岗位员工平均工作时长?
注:如员工未打卡该字段数据会存储为NULL,那么不计入在内;
要求输出:员工岗位类别、平均工作时长(以小时为单位输出并保留三位小数),按照平均工作时长降序排序;
示例数据结果如下:

解释:Engineer类岗位有4、5、6共计3名员工,工作时长分别为:9.500、9.167、10.250,则平均工作时长为 (9.500+9.167+10.250)/3=9.639小时
其他结果同理.....
示例1
输入:
drop table if exists `staff_tb` ;
CREATE TABLE `staff_tb` (
`staff_id` int(11) NOT NULL,
`staff_name` varchar(16) NOT NULL,
`staff_gender` char(8) NOT NULL,
`post` varchar(11) NOT NULL,
`department` varchar(16) NOT NULL,
PRIMARY KEY (`staff_id`));
INSERT INTO staff_tb VALUES(1,'Angus','male','Financial','dep1');
INSERT INTO staff_tb VALUES(2,'Cathy','female','Director','dep1');
INSERT INTO staff_tb VALUES(3,'Aldis','female','Director','dep2');
INSERT INTO staff_tb VALUES(4,'Lawson','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(5,'Carl','male','Engineer','dep2');
INSERT INTO staff_tb VALUES(6,'Ben','male','Engineer','dep1');
INSERT INTO staff_tb VALUES(7,'Rose','female','Financial','dep2');
drop table if exists `attendent_tb` ;
CREATE TABLE `attendent_tb` (
`info_id` int(11) NOT NULL,
`staff_id` int(11) NOT NULL,
`first_clockin` datetime NULL,
`last_clockin` datetime NULL,
PRIMARY KEY (`info_id`));
INSERT INTO attendent_tb VALUES(101,1,'2022-03-22 08:00:00','2022-03-22 17:00:00');
INSERT INTO attendent_tb VALUES(102,2,'2022-03-22 08:30:00','2022-03-22 18:00:00');
INSERT INTO attendent_tb VALUES(103,3,'2022-03-22 08:45:00','2022-03-22 17:00:00');
INSERT INTO attendent_tb VALUES(104,4,'2022-03-22 09:00:00','2022-03-22 18:30:00');
INSERT INTO attendent_tb VALUES(105,5,'2022-03-22 09:00:00','2022-03-22 18:10:00');
INSERT INTO attendent_tb VALUES(106,6,'2022-03-22 09:15:00','2022-03-22 19:30:00');
INSERT INTO attendent_tb VALUES(107,7,'2022-03-22 09:30:00','2022-03-22 18:29:00');
复制输出:
post|work_hours
Engineer|9.639
Financial|8.992
Director|8.8752.2 思路:
使用timestampdiff函数可以计算两个日期的相差秒数,再除以3600得到小时。
然后就是常规的分组计算。
2.3 题解:
with tep1 as (
-- 先求出每个人的工作时长
select staff_id, round(timestampdiff(second, first_clockin, last_clockin) / 3600, 3) time_diff
from attendent_tb
where first_clockin is not null
and last_clockin is not null
)
-- 然后以post分组计算平均值
select post, round(avg(time_diff), 3) work_hours
from tep1 t1
join staff_tb t2
on t1.staff_id = t2.staff_id
group by post
order by work_hours desc3. 牛客SQL热题196:查找入职员工时间排名倒数第三的员工的所有信息
3.1 题目:
描述
有一个员工employees表简况如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 |
| 10004 | 1954-05-01 | Christian | Koblick | M | 1986-12-01 |
请你查找employees里入职员工时间排名倒数第三的员工所有信息,以上例子输出如下:
| emp_no | birth_date | first_name | last_name | gender | hire_date |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
注意:可能会存在同一个日期入职的员工,所以入职员工时间排名倒数第三的员工可能不止一个。
示例1
输入:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
复制输出:
10005|1955-01-21|Kyoichi|Maliniak|M|1989-09-123.2 思路:
排名倒三 => 窗口函数 => 结果不止一个 => dense_rank
3.3 题解:
with tep1 as (
-- 倒数第三 => 窗口函数 => 可能不止一个 => dense_rank
select emp_no, birth_date, first_name, last_name, gender, hire_date,
dense_rank() over (order by hire_date desc) ranks
from employees
)
select emp_no, birth_date, first_name, last_name, gender, hire_date
from tep1
where ranks = 3
4. 力扣2175:世界排名的变化
4.1 题目:
表:TeamPoints
+-------------+---------+ | Column Name | Type | +-------------+---------+ | team_id | int | | name | varchar | | points | int | +-------------+---------+ team_id 包含唯一值。 这张表的每一行均包含了一支国家队的 ID,它所代表的国家,以及它在全球排名中的得分。没有两支队伍代表同一个国家。
表:PointsChange
+---------------+------+ | Column Name | Type | +---------------+------+ | team_id | int | | points_change | int | +---------------+------+ team_id 包含唯一值。 这张表的每一行均包含了一支国家队的 ID 以及它在世界排名中的得分的变化。 分数的变化分以下情况: - 0:代表分数没有改变 - 正数:代表分数增加 - 负数:代表分数降低 TeamPoints 表中出现的每一个 team_id 均会在这张表中出现。
国家队的全球排名是按 降序排列 所有队伍的得分后所得出的排名。如果两支队伍得分相同,我们将按其名称的 字典顺序 排列以打破平衡。
每支国家队的分数应根据其相应的 points_change 进行更新。
编写解决方案来计算在分数更新后,每个队伍的全球排名的变化。
以 任意顺序 返回结果。
查询结果的格式如下例所示:
示例 1:
输入: TeamPoints 表: +---------+-------------+--------+ | team_id | name | points | +---------+-------------+--------+ | 3 | Algeria | 1431 | | 1 | Senegal | 2132 | | 2 | New Zealand | 1402 | | 4 | Croatia | 1817 | +---------+-------------+--------+ PointsChange 表: +---------+---------------+ | team_id | points_change | +---------+---------------+ | 3 | 399 | | 2 | 0 | | 4 | 13 | | 1 | -22 | +---------+---------------+ 输出: +---------+-------------+-----------+ | team_id | name | rank_diff | +---------+-------------+-----------+ | 1 | Senegal | 0 | | 4 | Croatia | -1 | | 3 | Algeria | 1 | | 2 | New Zealand | 0 | +---------+-------------+-----------+ 解释: 世界排名如下所示: +---------+-------------+--------+------+ | team_id | name | points | rank | +---------+-------------+--------+------+ | 1 | Senegal | 2132 | 1 | | 4 | Croatia | 1817 | 2 | | 3 | Algeria | 1431 | 3 | | 2 | New Zealand | 1402 | 4 | +---------+-------------+--------+------+ 在更新分数后,世界排名变为下表: +---------+-------------+--------+------+ | team_id | name | points | rank | +---------+-------------+--------+------+ | 1 | Senegal | 2110 | 1 | | 3 | Algeria | 1830 | 2 | | 4 | Croatia | 1830 | 3 | | 2 | New Zealand | 1402 | 4 | +---------+-------------+--------+------+ 由于在更新分数后,Algeria 和 Croatia 的得分相同,因此根据字典顺序对它们进行排序。 Senegal 丢失了22分但他们的排名没有改变。 Croatia 获得了13分但是他们的排名下降了1名。 Algeria 获得399分,排名上升了1名。 New Zealand 没有获得或丢失分数,他们的排名也没有发生变化。
4.2 思路:
注意窗口函数得到的排名的类型是unsigned,需要转换为signed类型才能参与运算。
4.3 题解:
with tep1 as (
-- 先求出初始时每个国家队的排名
select team_id, name, points,
rank() over (order by points desc, name) ranks1
from TeamPoints
), tep2 as (
-- 求出更新分数后国家队的分数
select t1.team_id, name,
points_change+points points
from TeamPoints t1
join PointsChange t2
on t1.team_id = t2.team_id
), tep3 as (
-- 求出更新后的国家队的排名
select team_id, name, points,
rank() over (order by points desc, name) ranks2
from tep2
)
select t1.team_id, t1.name,
-- 排名类型为unsigned
-- 需要用cast函数转换
cast(ranks1 as signed) - cast(ranks2 as signed) rank_diff
from tep1 t1
join tep3 t2
on t1.team_id = t2.team_id