MySQL全文索引检索中文
MySQL全文索引检索中文

5.7.6版本不支持中文检索,需要手动修改配置 ft_min_word_len = 1 ,因为默认配置 4
SHOW VARIABLES LIKE 'ft%';
show VARIABLES like 'ngram_token_size';

配置
修改 MySQL 配置文件
vim /etc/my.cnf
在配置的 [mysqld] 下面添加**ft_min_word_len = 1** ,如果是 innodb 引擎添加配置 innodb_ft_min_token_size = 1

以上配置都不推荐,我比较推荐使用 MySQL 自带的插件 N-gram 因为它对中文的检索更友好。N-gram 插件不需要安装,当创建索引的时候申明使用N-gram就可以了,这个本文后面会提到。一般分词都是设置为2,设置为1我试过检索不出来。设置了 ngram_token_size之后,innodb_ft_min_token_size和innodb_ft_max_token_size就没有用了。
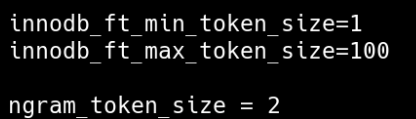
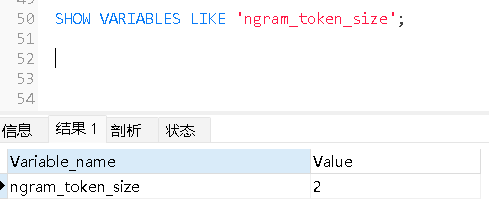
可以使用以下语句查询 ngram_token_size配置。
SHOW VARIABLES LIKE 'ngram_token_size';
重启MySQL
修改配置以后重启 MySQL服务
service mysqld stop
service mysqld start
创建全文索引
-- 不使用n-gram
ALTER TABLE <表名> ADD FULLTEXT <索引名>(<字段名>);
-- 使用n-gram,全文索引名一般使用 ft_ 的前缀,例如 ft_user_id
ALTER TABLE <表名> ADD FULLTEXT INDEX <索引名>(<字段名>) WITH PARSER ngram;
全文索引字段必须是中文字符类型,最好是 utf8mb4 。
优化索引
如果在修改配置前就已经创建了全文索引,则需要重新生成全文索引。可以先删除再重新创建全文索引,也可以执行如下sql优化索引。
-- 更新索引
OPTIMIZE TABLE <表名>;
-- 删除索引,再重新创建索引
ALTER TABLE <表名> DROP INDEX <索引名>;
ALTER TABLE <表名> ADD FULLTEXT INDEX <索引名>(<字段名>) WITH PARSER ngram;

全文检索
MySQL 的 MATCH AGAINST 语句支持多种搜索模式,每种模式都有其特定的应用场景。以下是 MySQL 中 MATCH AGAINST 支持的几种主要模式:
1. 自然语言模式(Natural Language Mode)
自然语言模式是最简单的全文搜索模式,默认情况下,如果没有显式指定搜索模式,MATCH AGAINST 将使用自然语言模式。在这种模式下,多个词语之间用空格分隔,表示任意一个词语都可以匹配。
示例
假设你希望匹配包含任意其中一个词语的记录:
SELECT * FROM <表名>
WHERE MATCH(<字段名>) AGAINST('关键词1 关键词2 关键词3');
2. 布尔模式(Boolean Mode)
布尔模式允许你更精细地控制搜索行为,可以使用特殊符号来表示逻辑运算符。布尔模式的特点包括:
- 加号(
+)表示必须包含的词,类似于and - 减号(
-)表示必须不包含的词,类似于not - 空格表示或的关系,类似于
or - 星号(
*)表示通配符,用于模糊匹配。 >和<可以用来表示词频的阈值。- 双引号(
")表示短语搜索。
示例
假设你希望匹配包含所有词语的记录:
SELECT * FROM <表名>
WHERE MATCH(<字段名>) AGAINST('+关键词1 +关键词2' IN BOOLEAN MODE);
3. 查询扩展模式(Query Expansion Mode)
查询扩展模式是在布尔模式的基础上增加了查询扩展的功能,它允许 MySQL 根据已有的搜索词自动扩展搜索范围,以找到更多相关文档。查询扩展模式使用 WITH QUERY EXPANSION 关键字。
示例
假设你希望匹配包含所有词语的记录,并扩展搜索范围:
SELECT * FROM <表名>
WHERE MATCH(<字段名>) AGAINST('+关键词1 +关键词2' WITH QUERY EXPANSION);
4. 混合模式
你可以结合使用自然语言模式和布尔模式,根据需要选择最适合的模式。例如,你可以使用自然语言模式来匹配多个词语中的任意一个,同时使用布尔模式来精确控制某些词语的匹配。
示例
假设你希望匹配包含任意其中一个词语的记录,并且排除某些词语:
SELECT * FROM <表名>
WHERE MATCH(<字段名>) AGAINST('关键词1 关键词2' IN BOOLEAN MODE);
注意事项
- 全文索引:确保你已经在相关列上创建了全文索引。
- 字符集:确保使用支持中文的字符集,如
utf8mb4。 - 停用词处理:对于中文全文搜索,停用词的处理非常重要,可以自定义停用词列表来提高搜索质量。
- 全文索引参数:根据需要调整全文索引的相关参数,如
ft_min_word_len和ft_max_word_len。

参考
- MySQL5.7 中文全文检索与停用词的常用设置 https://blog.csdn.net/ordinary_csdn/article/details/127222125
- MySQL使用全文索引(fulltext index) 及中文全文索引使用 https://blog.csdn.net/yygg329405/article/details/97110984#::text=MySQL中文分词全#::text=MySQL中文分词全