深入RAG:知识密集型NLP任务的解决方案

在当今知识密集型任务日益增多的时代,如何有效地利用外部知识来增强语言模型的生成能力成为了一个重要的研究方向。RAG技术应运而生,通过从外部记忆源中检索相关信息,RAG不仅提高了模型生成的精准性和相关性,还解决了大型语言模型在数据隐私、实时数据处理和幻觉问题等方面的局限。本文将详细介绍RAG的工作原理、应用场景、限制及挑战,帮助读者更好地理解和应用这一前沿技术。

什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种通过从外部记忆源中检索相关信息来增强模型生成能力的技术。
“检索增强生成”一词是在《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(Lewis et al., 2020)中首次提出的。该论文将RAG提议作为一种针对知识密集型任务(knowledge-intensive tasks)的解决方案,因为无法将所有可用知识直接输入到模型中。
通过RAG,仅检索和召回与query最相关的信息,并将其输入到模型中,从而提高模型response的精准性和相关性,属于in-context learning范畴。RAG系统由两个组成部分构成:一个检索器,从外部记忆源中检索信息;一个生成器,基于检索到的信息生成响应。
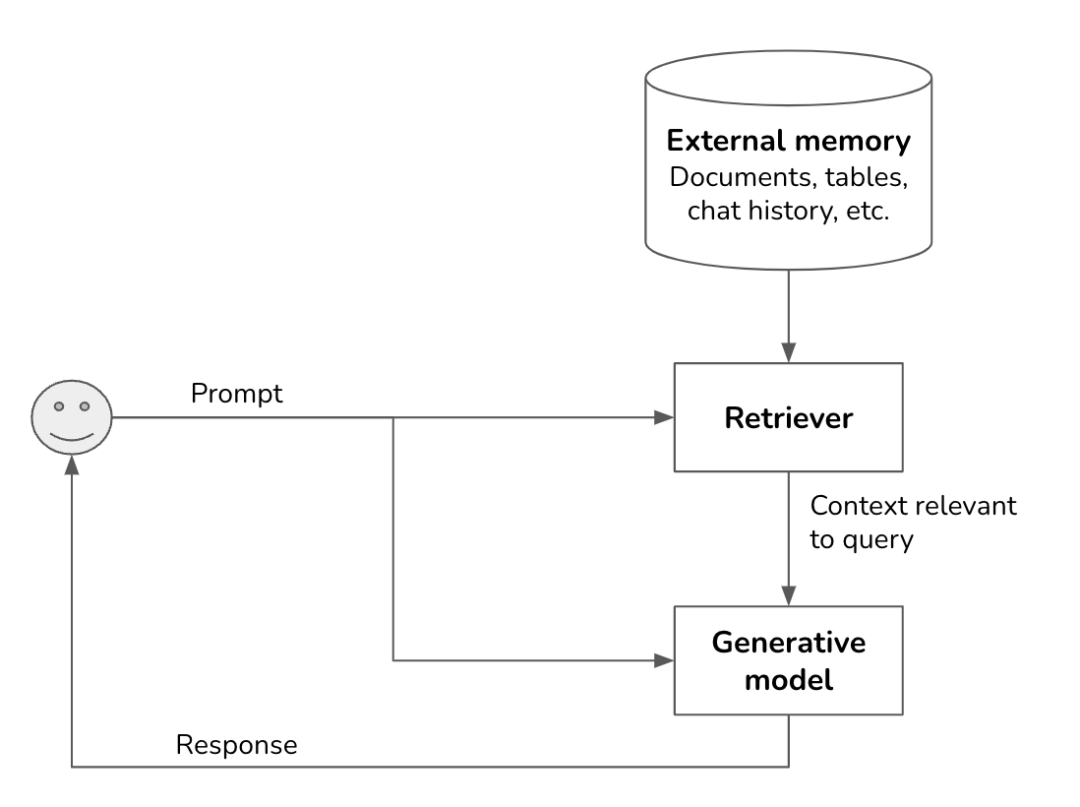
RAG链路图示
RAG系统的成功依赖于其检索器的质量。检索器有两个主要功能:索引和查询。索引主要是关注如何处理数据,生成关键标识,以便以后快速检索;查询主要是根据query的信息检索并且找回关联的数据,如何索引数据取决于你想要如何在后续检索它。
▐ 检索
检索在大类上主要有两类:基于关键字词的检索(Term-based Retrival)和基于语义的检索(Semantic Retrival)。
基于关键字词的检索 | 基于语义的检索 | |
查询速度 | 比基于语义检索的快很多 | 需要对query进行embedding转化到向量,然后在向量存储(Vector DB)中进行向量搜索 |
应用表现 | 使用方便,但难以改进; 由于query的一些表达存在歧义,可能会检索到错误的文档,对于query输入有比较高的要求; | 检索效果上比基于术语的检索更好; 允许使用更自然的查询,因为它专注于语义而不是具体的字词; |
开销 | 比基于语义检索便宜 | Embedding,向量存储(Vector Storage)以及向量搜索(Vector Search)都是比较消耗资源的 |
从上述的比对来看,基于语义的检索其实更贴合LLM的使用场景,因为人和大模型交互的时候,使用的是自然语言,非传统搜索使用中的关键字词,同时在效果上,也是Semantic Retrival更好,当然也具有更多的资源开销;下面的链路图示是Semantic Retrival中比较主流的Embedding-Based Retrival,其实在上述表格比对的时候,就是基于此,其他语义类的检索方式当然也是可以的,但是基本不常见。
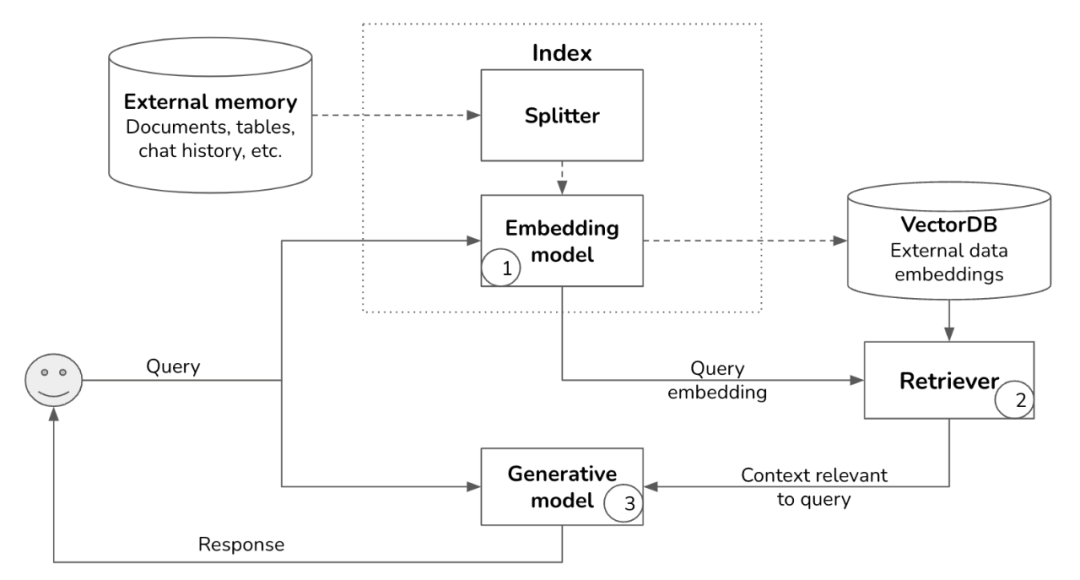
RAG链路 (Embedding-based Retrival)
检索本质上就是快速获取和query关联的信息,当做上下文的补充,一起当成输入给到大模型,以期得到更好的结果,所以这里的数据、索引、检索方式的组合可以是多种多样,只要在检索速度、召回数据关联性和充分性上能够符合要求,都是OK的;比如使用opensearch做查询召回也是比较常用的,同时还有一些多模态数据的检索,这里举两个例子:
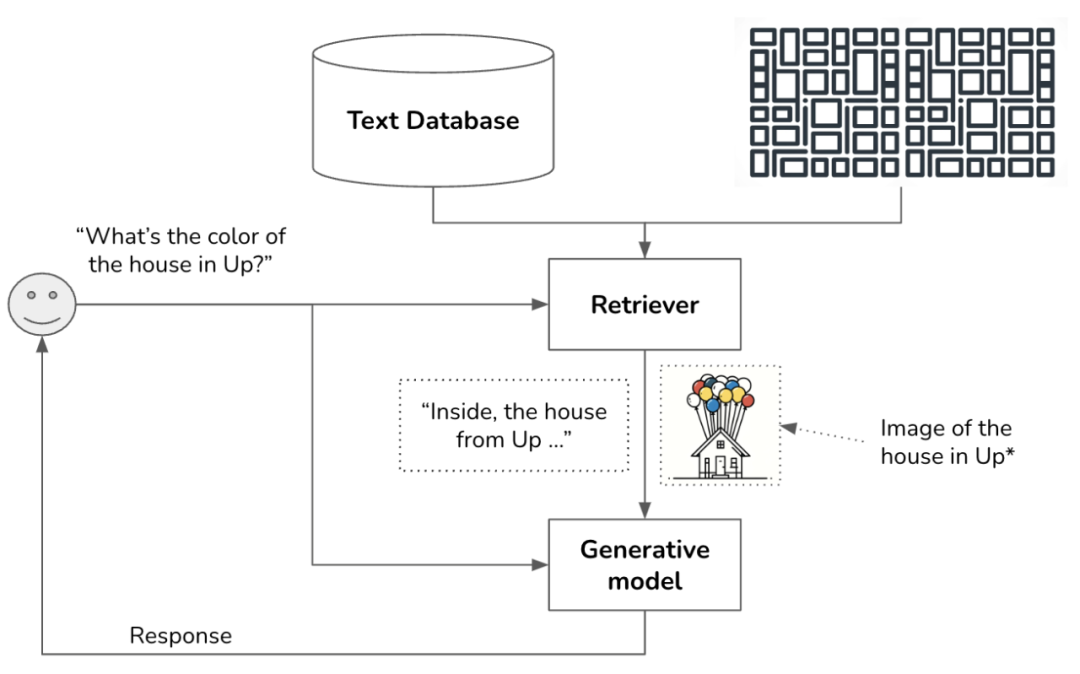
RAG中多模态的数据前置检索
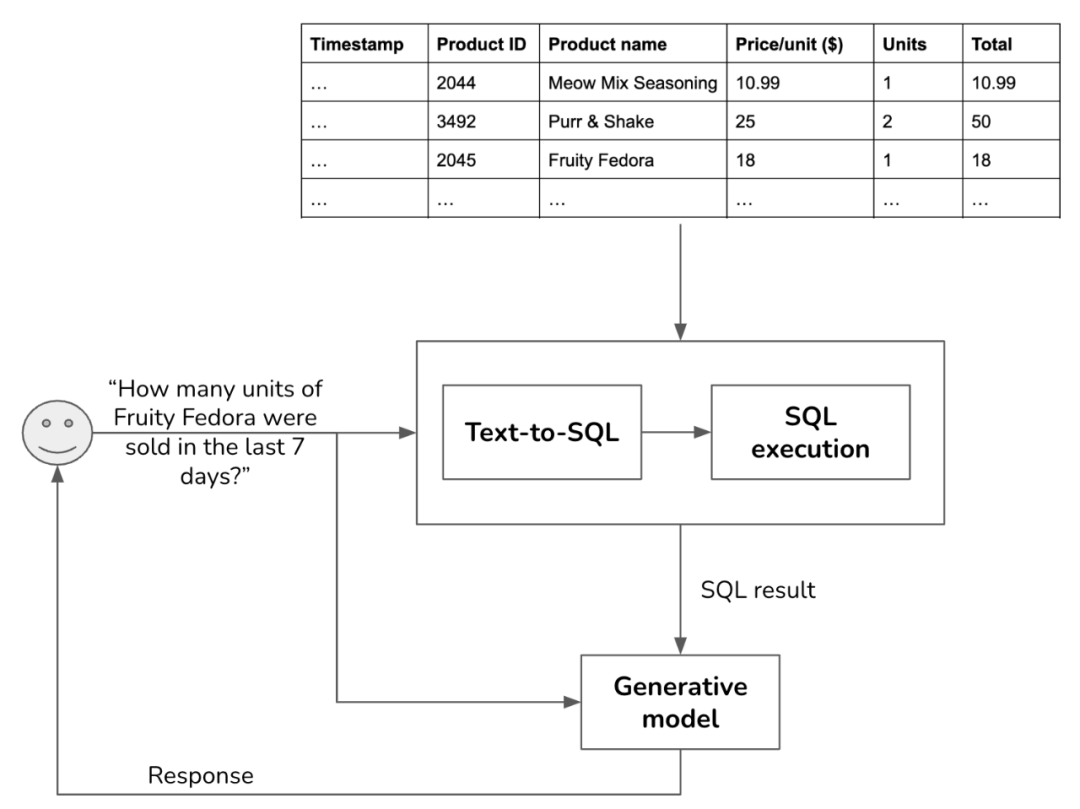
RAG中表格数据的检索
其实不管是基于关键字词的检索,还是基于语义的检索,都不是一种非此即彼的方案选型,两者也是可以相互结合,去面向使用场景做设计的,比如可以先使用基于关键字词的检索做文档的粗筛,然后基于粗筛之后的结果做基于语义检索,选出最终的文档列表作为放入到prompt context中的内容。
为什么需要RAG?当前的LLMs在使用中存在下面一些缺点或者说约束:
1.【数据隐私】我们需要大型语言模型(LLMs)访问我们的私人/专有数据,或那些不在大型语言模型预训练数据集中的数据;
2.【实时数据】我们希望大型语言模型能够回答关于近期事件和在大型语言模型预训练后出现的新概念的问题;比如最近的实事,每日的天气,最新的动态,偏实时的统计;
3.【幻觉】“幻觉”通常指的是模型生成的内容与现实不符或是虚构的信息,幻觉出现的原因大致有这么几个方面:
领域知识不足(Domain knowledge deficit):语言模型可能缺乏对特定领域的全面专业知识;
信息过时(Outdated Information):LLM通常具有由其训练数据集决定的截止日期,同时它无法主动感知过时这件事,就会非常自信的把“错误”的信息当成答案来回答;
未记忆(Immemorization):有些在LLM训练过程中接触到知识和信息,会因为权重问题并未保留下来;
遗忘(Forgetting):这个情况主要是发生在对预训练模型做微调(Fine-tuning)之后,可能会出现一种称为灾难性遗忘(catastrophic forgetting)现象,即模型失去了一些在微调过程之前掌握的知识;
推理失败(Reasoning Failure):在某些情况下,语言模型可能掌握关于某个事实的相关知识,但未能正确利用。
上述这几点,可以通过RAG在一定程度上进行补充或者解决。
哪些场景可以使用RAG?▐ 检索外部知识
这个应用场景是RAG的一个主要范式,在一些实际使用中取得了比较大的成功;如上描述的LLMs在当前应用下的一些不足点,包括隐私数据的使用、实时数据的补充以及幻觉问题,都可以通过使用RAG的方案来填补LLMs的知识空白或减少幻觉风险。
▐ 检索上下文历史
LLM的上下文窗口(Context Window)是有限,但是我们可能在实际应用中,需要LLM在回答或者解决问题的时候,使用更多的上下文会话记录或者是往前关联更多的会话内容,在这类情况下,我们可以使用外部存储来保存历史会话内容,并且在query查询之前,先检索和召回相关的会话,然后提供给LLMs。
▐ 检索上下文中的训练示例
有时候,我们需要提供给LLMs一些回答的例子,来引导大模型给出的答案是按照我们想要的视角和范式来的,这样的方式叫Few-shot Learning,少量学习是一种有效的方法,有助于LLM熟悉任务的输入输出映射;这里使用RAG,可以根据当前输入动态选择少量示例,作为模型输入的一部分。
▐ 检索工具相关信息
有些场景,在调用LLM获取回答之前,需要调用一些工具或者接口,然后把工具或接口返回的数据当成上下文传入LLM中,在这类场景中,可用把工具的列表及其描述存储在工具库中,然后LLM可以根据工具相关的信息或API文档来检索工具,从而选择最适合该任务的工具;这里使用RAG所达到的效果和lang-chain中的Agent比较类似。

RAG的限制有哪些?
1. 依赖文本片段的检索可能使LLM仅依赖表面信息来回答问题,而不是深入理解问题本身;这个点也是区别于Fine-Tuning的核心的点,ICL(In-Context Learning)目前看只能解决知识或者信息面的问题,但是做不到把知识内化到模型的能力中去,让这部分内容和LLM本身的知识做有效的关联和推演;
2. 检索成为了整个流程的限制因素。如果检索过程未能提取出合适的候选文本,那么所返回的结果将较预期偏差很大,没有充分使用LLM的强大能力,当然这里可以通过流程链路的设计,来校验比较差的结果,然后绕过RAG直接通过LLM来进行结果的产出;
3. 检索过程可能提取出与LLM的参数记忆中所包含的知识相矛盾的文档,由于无法获取真实信息,LLM很难解决这些矛盾。
上述三点是RAG当前比较明显的短板,不过limitation更多的是提供更好的权衡,因为不管什么解决方案都是有利弊的,如何利用好技术方案的优点,同时通过有效的方式去减弱或者弥补方案的缺陷,才是我们重点要去看的。

RAG方案下有哪些挑战?
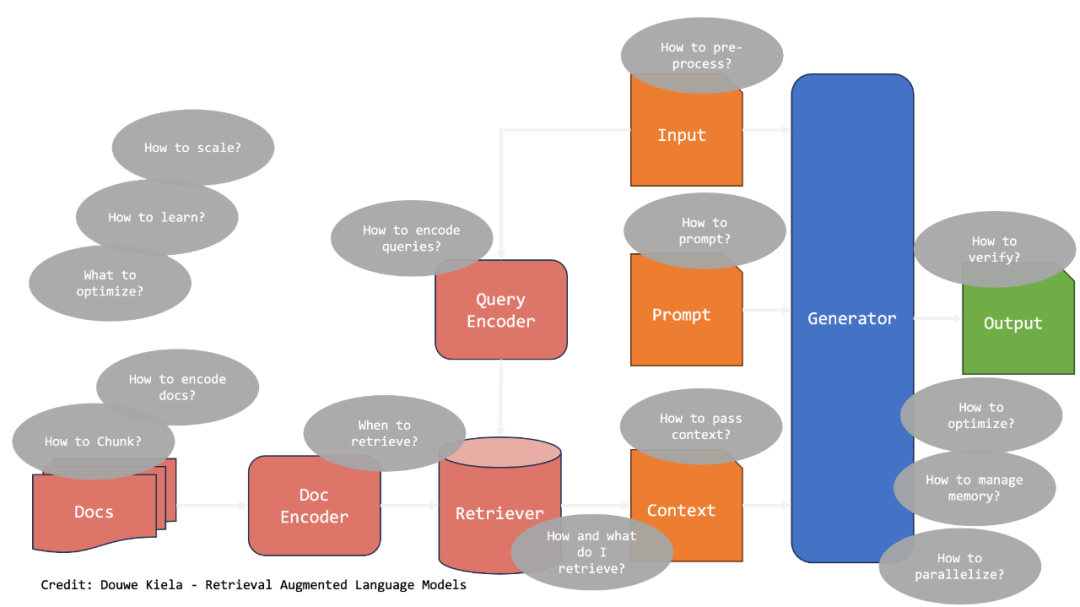
RAG的应用门槛其实不高,但是要使用RAG技术,并且能把使用场景的效果做好,越到后面越考验细节,会有越来越多的概念浮现,一开始可能就是扔些文档到知识库里面,然后不管是内部的AI Studio还是lang-chain和llama-index这类的开发框架,都对RAG有很好的支持,一顿操作之后,发现效果果然比单纯调用LLM要好,但是也还没到非常能用的程度,这个时候,冰山下面的事物就该浮出水面了。
RAG在实际落地深入使用中,会面临下面一些挑战:
▐ 延迟问题 (Latency Issues)
虽然向量存储一般效率较高,但检索信息可能会引入延迟,特别是当数据量庞大或网络基础设施未优化时,延迟可能会很显著。
▐ 成本考虑 (Cost Considerations)
实施和维护外部存储系统可能会产生显著的成本,因为支持大规模向量存储解决方案所需的硬件和软件基础设施通常是相当可观的。
▐ 事实错误和幻觉 (Factual Incorrectness and Hallucination)
RAG 方法减少了幻觉,但需要仔细实施和调整才能有效。确保模型检索和使用准确的信息而不引入错误仍然是一个重要挑战。
▐ 技术和优化挑战 (Technical and Optimization Challenges)
文档编码 (Document Encoding)
在对文档进行编码前,会涉及文档的切分(Chunking),小文本块,比如句子或短语这样的粒度,虽然可以提供更精细的控制,但可能导致信息丢失和上下文碎片化;大文本块,比如段落或多段乃至整个原始文档,虽然可以更多的保持上下文关联信息,但可能超出大语言模型的处理能力;因此针对文本块(chunks)大小,需要结合文档内容以及召回内容和最终生成的结果进行权衡;
文档切分的方式主要有三种:
1. 固定大小的分块:简单高效,但有可能破坏句子并失去上下文,这一种方式在应用中使用比较多;
2. 基于句子的分块:内容感知的分块方式允许将文本拆分为独立的句子;
3. 递归分块:此分块过程通过不同的标准迭代地将文本拆分为更小的部分,直到达到相似但不完全相同的块的大小,从而允许结构上的灵活性;
文档切分的方式和上面说的检索的几种类型一样,都是可以进行组合使用,比如面向一些复杂的场景,可以按照基于固定大小来进行分块,但是在召回某块文档的时候,可以增加召回该块文档在原始文档中的上下两块亦或是整个原始文档,具体方式比较灵活,最终目标还是使最终的模型返回结果和应用场景最契合。
文档合理分块之后要对文档分块进行编码,如何编码文档至关重要,这涉及选择适当的Embedding模型,以捕捉特定领域知识的细微差别;面向文本的Embedding模型有:Word Embeddings(Word2Vec、GloVe、FastText等),Sentence and Document Embeddings(Sentence-BERT、Universal Sentence Encoder等),Contextualized Embeddings(BERT、ELMo等)。
检索机制
选择在何时以及如何检索文档对于效率和准确性至关重要,查询编码器必须能够将用户查询转换为与存储文档匹配的嵌入;Meta提供的FAISS开源库,在向量快速搜索和相似计算上比较高效,使用比较广泛。
提示设计
这就是最近提的比较多的Prompt Engineering,提示设计能够有效引导LLM的提示对于生成准确和相关的响应至关重要,提示需要提供足够的上下文和指引;好的提示的设计需要包括一个角色定位、明确上下文信息、明确的指令,以及可能涉及一些回答案例(question and answer mapping)、思维链的设计(CoT,Chain of Thought)等。
上下文管理
需要有效传递上下文以保持交互的连贯性和相关性,上下文管理技术能够确保 LLM 能够在多轮对话中保持重要信息,这里上下文管理有LLM自身的context window,以及可以通过RAG来实现相关会话检索和召回,还有像lang-chain等开发框架也提供Memory模块来存储交互中的会话内容。
输出后处理
后处理涉及对生成的输出进行精炼以满足质量标准,此步骤包括验证事实准确性、更正错误以及确保响应适合给定上下文;对于一些面向用户的应用场景,也许错误的回答会带来比较大的后果,这个时候需要对LLM给出的结果做后置校验,如果不通过,可以使用兜底答案,或者可以做人工流程转交。
动态数据集成
动态添加新数据到外部存储需要一个强大的嵌入和集成流程,系统必须支持增量更新,以确保在特定领域数据发展过程中,系统保持当前性和准确性,同时还需要对整体性能、效果做持续监测,建立数据版本机制,因为质量差或者噪声数据的引入,会影响整体链路的表现。

结语
RAG的出现,让我们基于LLM之上去面向特定的业务领域去做应用的门槛相对变低,因为不管是重新训练模型还是基于预训练模型来做FT,相对来说成本都要更高,对于人的要求也更高。
RAG的应用,可以在某种程度上对于一些场景有一些工具或者产品创新应用,可以带来一些效率的提升,不过要精益求精地去持续提升效果,还是需要花比较大的精力去熟悉里面的各类细节,不过不管怎么说,在当前门槛不高的情况下,大家都可以尝试使用去面向自己遇到的问题或者想尝试的方向跨出AI应用的第一步。
参考资料RAGs and Agents:
https://learning.oreilly.com/library/view/ai-engineering/9781098166298/ch06.html#6_rag_overview_1726600321985229
Customizing Contextual LLMs:
https://learning.oreilly.com/library/view/llms-in-enterprise/9781836203070/text/ch005.xhtml#summary-3
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法