大模型面试题持续更新_Moe(2024-10-30)
扫一扫下方,获取更多面试真题的集合

Moe和集成学习方法有什么异同?
MoE和集成学习的思想异曲同工,都是集成了多个模型的方法,Moe主要是将预测任务分为多个子任务,然后通过路由网络的形式决定对于当前的数据该使用哪个专家,在现有的Moe实现中,通常激活部分专家,也即模型是稀疏的;集成学习主要对于当前的预测任务使用多个基模型进行学习,然后通过bagging或bosting方法融合结果,其模型结构是稠密的。
传统MOE和现在主流Moe是如何选择expert的?
传统Moe选择方法:学习一个gate网络,令其为$W_g$,$W_g$和输入x乘积的softmax记为G,则G就为每个专家的权重,多个专家聚合的时候按照稠密的方式进行聚合。也即$y = \sum\limits_{i = 1}^n {G{{(x)}_i}{E_i}(x)}$ 主流Moe选择方法:使用Noise-top k gating来计算,通过可学习的权重矩阵$W_g$和噪音矩阵$W_n$来得到Topk的logit值,并去TopK,对着TopK个位置计算softmax,然后和上面的专家聚合方式一样。
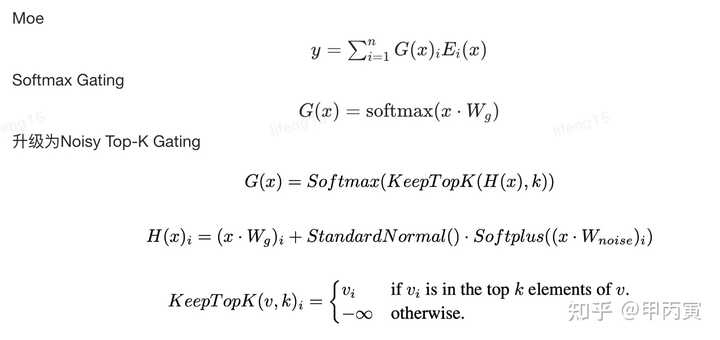
示例
如何解决Moe中训练不均衡现象?
-
gate网络softmax之后加dropout
MoE的稀疏性与dropout的原理类似,MoE是根据任务的具体情况选择激活一定数量的专家模型来完成这个任务,而dropout则是对神经网络中的神经元进行随机性失活,每次训练的时候只保留一定的参数,这不但让网络具备了稀疏性特征,减轻了整个网络的参数压力,还会降低模型发生过拟合的概率,提高模型的泛化能力。 -
软性约束方法 也即添加辅助Loss,具体的一些做法如下
-
Sparsely-gated MoE layer(2017)为了鼓励gating function给每个expert平均分配logits,作者提出了imporant loss,为了鼓励最后每个expert拿到相同数量的样本进行计算,作者提出了load loss
-
Switch Transformer(2021)改进了Load Balance的设计,同时提出了Capacity Factor的概念
-
ST-MoE提出了router-z loss的概念,总loss是load balance loss和router-z loss的加权
Moe算法为何训练时候容易不稳定?
-
要设计好门控来控制进入的expert,不然容易导致模型坍塌到一个expert上去
-
稀疏模型的输出具有高方差,其对随机种子敏感(确定初始参数值,训练数据改组,要剔除的值等),因此有不同训练会导致不同的表现。
-
现在都是混合精度训练,一些低精度的格式会影响梯度不稳定,从而导致训练不稳定。4. 在训练过程中,由于每个输入样本仅触发部分专家,导致不同专家的梯度更新频率不同,这种不均衡的梯度更新可能会导致模型参数更新不稳定,影响整体模型的收敛性。
Moe算法优缺点?
MoE的优点:
-
提高预训练速度:MoE模型能够在比稠密模型更少的计算资源下进行有效的预训练,这意味着在相同的计算预算下,可以显著扩大模型或数据集的规模,并且通常能够更快地达到与稠密模型相同的性能水平。
-
更快的推理速度:由于在推理过程中只激活部分专家,MoE模型的推理速度通常比具有相同参数数量的稠密模型更快。
-
提升模型扩展性:MoE架构允许模型在保持计算成本不变的情况下增加参数数量,这使得它能够扩展到非常大的模型规模,如万亿参数模型。
-
多任务学习能力:MoE在多任务学习中表现出色,例如Switch Transformer在所有101种语言上都显示出了性能提升,证明了其在多任务学习中的有效性。
MoE面临的挑战:
-
训练不稳定性:在训练过程中,由于每个输入样本仅触发部分专家,导致不同专家的梯度更新频率不同,这种不均衡的梯度更新可能会导致模型参数更新不稳定,影响整体模型的收敛性。
-
负载均衡问题:由于路由机制的随机性和输入数据的特性,可能导致某些专家承载的计算负载远高于其他专家,这种负载不均衡不仅会影响计算效率,还可能导致模型的训练效果不佳。
-
微调挑战:MoE模型在微调时可能会面临迁移学习效果不确定的问题。由于专家的选择可能与特定任务密切相关,微调时某些专家可能并未得到充分训练,从而影响模型在新任务上的表现。
-
推理效率:在推理阶段,MoE模型需要根据输入选择合适的专家,这种选择过程增加了计算复杂度,尤其是在实时推理的场景中,可能会影响推理速度。
-
部署复杂性:MoE模型通常比传统的稠密模型更加复杂,在实际部署中可能需要针对不同硬件环境进行优化。此外,不同专家之间的通信成本和数据传输延迟也会影响模型的部署效率。 模型大小和计算资源:MoE模型通常包含大量参数,这对计算资源提出了极高的要求。训练和推理阶段都需要高效的分布式计算框架来支持。