科研项目:利用AI大模型获得基金资助的10个原则
我是娜姐 @迪娜学姐 ,一个SCI医学期刊编辑,探索用AI工具提效论文写作和发表。

以ChatGPT为代表的大语言模型的诞生后,在学术界这些大模型LLM驱动的聊天机器人已经成为大家撰写和修订论文、基金申请书的流行工具。这些LLM经过千亿文本训练,可以帮助你精准总结文本、简化段落,理顺逻辑,提升文本的清晰度和简洁性。
但是,另一方面,LLM并不真正“理解”你输入的内容和它输出的内容—它只是总结大量训练数据的特征,通过上文预测句子下一个单词。大模型的“幻觉”,和数据隐私性等问题,也提示科研人员要注意它的使用边界。
之前娜姐写过,斯坦福大学研究人员,推荐的课题申报AI提示词分享
这一篇,斯坦福大学医学院Elizabeth Secke总结了她们在使用这些大模型,成功申请基金时的10条原则:
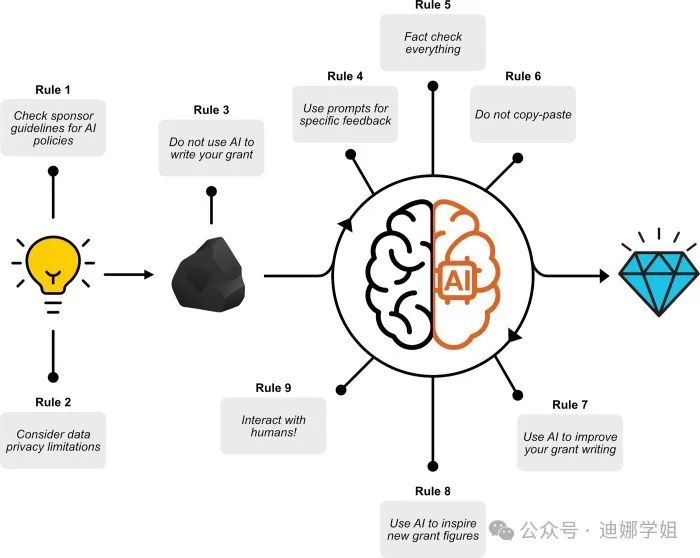
1 检查资助机构关于人工智能的指南
在学术论文的写作和发表过程中,top期刊和国际出版商的共识是“禁止将聊天机器人列为作者,但允许在适当承认的情况下在写作中使用。”
对于基金申请来说,美国心脏协会允许作者自由使用 AI,只要在提交时披露。国家科学基金会(National Science Foundation)鼓励提交者说明是否以及如何使用生成性 AI 技术来开发他们的提案,同时警告这种技术可能引入伪造、篡改或抄袭,这将构成研究不端行为。美国国立卫生研究院则表示,他们“不知道,也不询问,谁撰写了申请”,但警告科学家使用LLM时需自行承担风险。
目前我国的官方机构,仅有中国科学院道德委员会2024年9月份发布的“《关于在科研活动中规范使用人工智能技术的诚信提醒》的通知“。包含了一些鼓励使用,和禁止使用AI的详细边界。
娜姐看了一下这8条提醒,和本文斯坦福大学团队提出的10个原则有很多相似之处。
2 注意数据隐私限制
AI 聊天机器人通过与用户的互动学习而不断改进。实际上,所有公开可用的 AI 聊天机器人,包括 ChatGPT 和 Google Bard,都会保存您的提示和对话,明确的目标是改善其算法。因此,在使用任何聊天机器人之前,请始终检查数据存储设置。
3 用AI来改进文本而不是生成初稿
尽管从一个想法或几句话开始,请LLM为你生成初稿以避免 “空白页”是很诱人的,但我们不建议在你有初稿并准备开始修订之前与 AI 互动。最终,你的资助申请必须反映你作为研究人员的身份——使用你自己的语言来描述,你的科学想法、你的初步数据和你独特的方法。
4 缩小提示范围以获取具体反馈
根据我们的经验,将关注点缩小到特定任务或部分时,LLMs表现得更为出色。比如,写明您是一名申请美国心脏协会的博士后研究员,并希望获得关于您的文本与目标的对齐程度的反馈,可以帮助LLM提供更好和更恰当的评论和调整。然后,将LLM的关注点缩小到每个特定部分,而不是将整个申请书。
5 记得核实所有事实
由于大模型的工作原理,尽管这些模型正在稳步改进——据报道,ChatGPT 4.0 在幻觉方面比之前的版本提高了 40% ——但它们仍然有相当大的可能性会产生完全虚假的信息。因此,无论 AI 写得多么令人信服,都要始终进行事实核查。
6 将 AI 生成的文本作为灵感来源,而不是复制粘贴
更聪明的方法,是将LLM作为灵感来源,来对自己的草稿进行编辑(见下文规则 7),而不是直接复制粘贴LLM生成的内容。
7 将这个迭代过程用来提升自己的写作能力
像人工智能一样,你可以在和它的互动中提升自己的写作,监督自己的“强化学习”。通过与人工智能反复迭代,你将学会更清晰、简洁地表达自己的想法,并能够预见、回应和整合反馈,这些都是学术职业生涯中必不可少的技能。此外,你还可以开发自己的“训练集”,比如和你的领域相关的成功案例。
8 利用人工智能激发灵感以创建图表
生成性人工智能工具并不限于文本和单词。像 DALL-E-3 或 Midjourney 这样的工具可以根据文本提示创建图像。虽然LLM生成的图像不能直接用于学术论文或项目书中,但是可以用于激发你的资助申请中实际图形的灵感。或者,您可以提供你的图片,并询问人工智能如何改进。
9 与人类互动获得反馈
获得真实人类——同事和/或导师——的反馈仍然至关重要。这些人更能发现科学和技术上的错误,而这些错误可能只会在审查过程中被发现。对于刚接触资助申请的初级研究人员来说,这条建议尤为重要。
10 多玩多尝试
学习如何使用人工智能进行基金申请书写作的最佳方法是玩耍和尝试。使用不同的大模型和提示词进行对比,了解哪些效果最好。
毕竟,这些AI大模型将会长期存在并快速进化,越早熟悉它们的优缺点,你就能越快解锁它们的潜力,帮助你提升基金申请和其他学术文本写作。