大语言模型微调方法详解【全量微调、PEFT、LoRA、Adapter】
NLP-大语言模型学习系列目录
一、注意力机制基础——RNN,Seq2Seq等基础知识
二、注意力机制【Self-Attention,自注意力模型】
三、Transformer图文详解【Attention is all you need】
四、大语言模型的Scaling Law【Power Low】
五、大语言模型微调
文章目录
- NLP-大语言模型学习系列目录
- 一、为什么需要微调
- 二、微调简介
- 三、全参数微调
- 四、PEFT
- 1 Intuition behind PEFT
- 2 Prefix Tuning
- 3 Prompt Tuning
- 4 Adapter Tuning
- 5 LoRA
- (1)核心思想
- (2)图解
- 6 BitFit
- 7 多种不同的高效微调方法对比
- 8 关于PEFT的库
- 参考资料
一、为什么需要微调
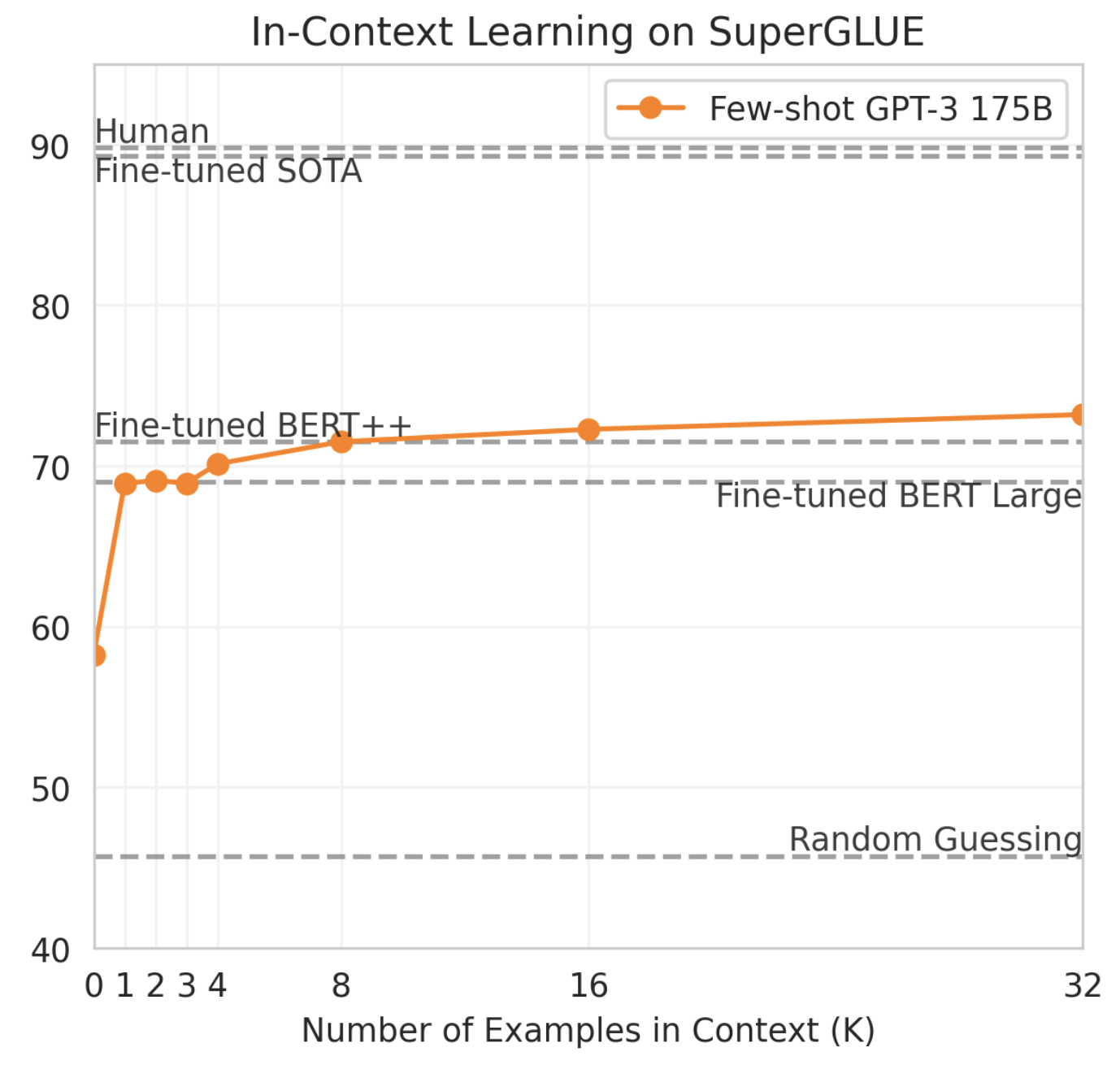
回顾GPT1,GPT2,GPT3,我们知道GPT3发现了Few-shot 的涌现能力,也就是说预训练好的模型,不用微调更新参数,仅仅通过Prompt 加入Few-shot,GPT3便可以在多个下游任务取得很好的效果。 如下图所示,GPT3在SuperGLUE测试集上,不用经过微调,仅通过Few-shot就能达到和微调后的BERT-Large一样的效果。
并且思维链(CoT)的发现,让我知道通过CoT的方式,LLM的效果还能提升。如下表所示,在需要推理的数学任务上,加入CoT效果可以得到极大的提升。

虽然Prompt Engineering很有效,但是也有一些缺陷:
- 可以放入上下文中的信息是有限的
- 复杂任务可能还是需要梯度更新步骤
- 没有通过指令微调的大模型,指令跟随效果不好(后训练的必要性)
如下图所示,仅通过预训练的语言模型并不一定能理解人类的意图并帮助我们(指令跟随效果不好)。

微调可以提升语言模型的指令跟随能力(指令微调),如下图所示,微调后的语言模型能正确回答提出的问题。

所以当前大模型的训练范式主流仍然是预训练+后训练(微调),下面本文详细的介绍两种微调方式,特别是各种参数高效微调的算法。
二、微调简介
微调主要包含两类:
- 全参数微调,一般称作Full Fine-Tuning
- 参数高效微调,Parameter-Efficient Fine-Tuning
全参数微调空间、时间代价高,参数高效微调是指微调少量或额外的模型参数,固定大部分预训练模型(LLM)参数,从而大大降低了计算和存储成本,同时,也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调效果更好,可以更好地泛化到域外场景。
| PEFT | 全参数微调 | |
|---|---|---|
| 目标 | 提高预训练模型在特定任务上的性能,使用有限的数据和计算资源 | 提高预训练模型在特定任务上的性能,使用有限的数据和充足的计算资源 |
| 训练时间 | 较快 | 较长 |
| 计算资源 | 较少 | 较多 |
| 模型参数 | 仅修改非常少量的参数 | 修改所有参数 |
| 过拟合 | 由于仅训练少量参数,较不容易过拟合 | 由于修改所有参数,更容易过拟合 |
| 性能 | 性能不如微调,但仍然足够好 | 性能更好 |
三、全参数微调
全参数微调(Full Fine-tuning)就是继续训练一个预训练语言模型,但这个方法可能需要大量的内存(取决于不同优化器、优化方法).下面以一个具有65B(650亿)参数的模型为例,展示使用16位混合精度(16-bit mixed precision)进行微调训练时的内存消耗情况。
Model
- 每个参数用16位,也就是2Byte,所以模型参数需要130GB内存
- 每个参数要存梯度,130GB
Optimizer
- 这里提到的 optimizer 存储 parameters 是因为在某些情况下,混合精度训练需要为模型参数同时保留两个版本,模型参数在更新的时候,要用高精度,所以要存一个副本,260GB:
- 低精度参数(16-bit):在实际的前向和后向传播过程中,模型的参数是以16位精度(16-bit)进行计算和存储的。这种精度可以减少内存占用,并加速计算过程。
- 高精度副本(32-bit):为了避免数值精度的损失,在混合精度训练中,优化器需要维护一个模型参数的高精度副本(通常是32-bit)。这个副本并不用于前向或后向传播的计算,而是用于在每次参数更新时执行更精确的累加操作,以确保最终更新的准确性和模型的稳定性。因此,虽然参数以16位精度参与计算,但优化器还需要保留一个高精度(32位)的版本来进行更新操作。因此,图中的“65B parameters * 4b = 260GB” 指的是这一部分的存储需求,它是优化器需要维护的模型参数的高精度副本。
- Adam的参数260GB+260GB
Activations
- 前向传播和后向传播的一些中间计算量

所以我们可以看到全参数微调对内存的需求很大,即使是65B的中等模型,需要很多张显卡才行(每张显卡80GB内存)。
四、PEFT
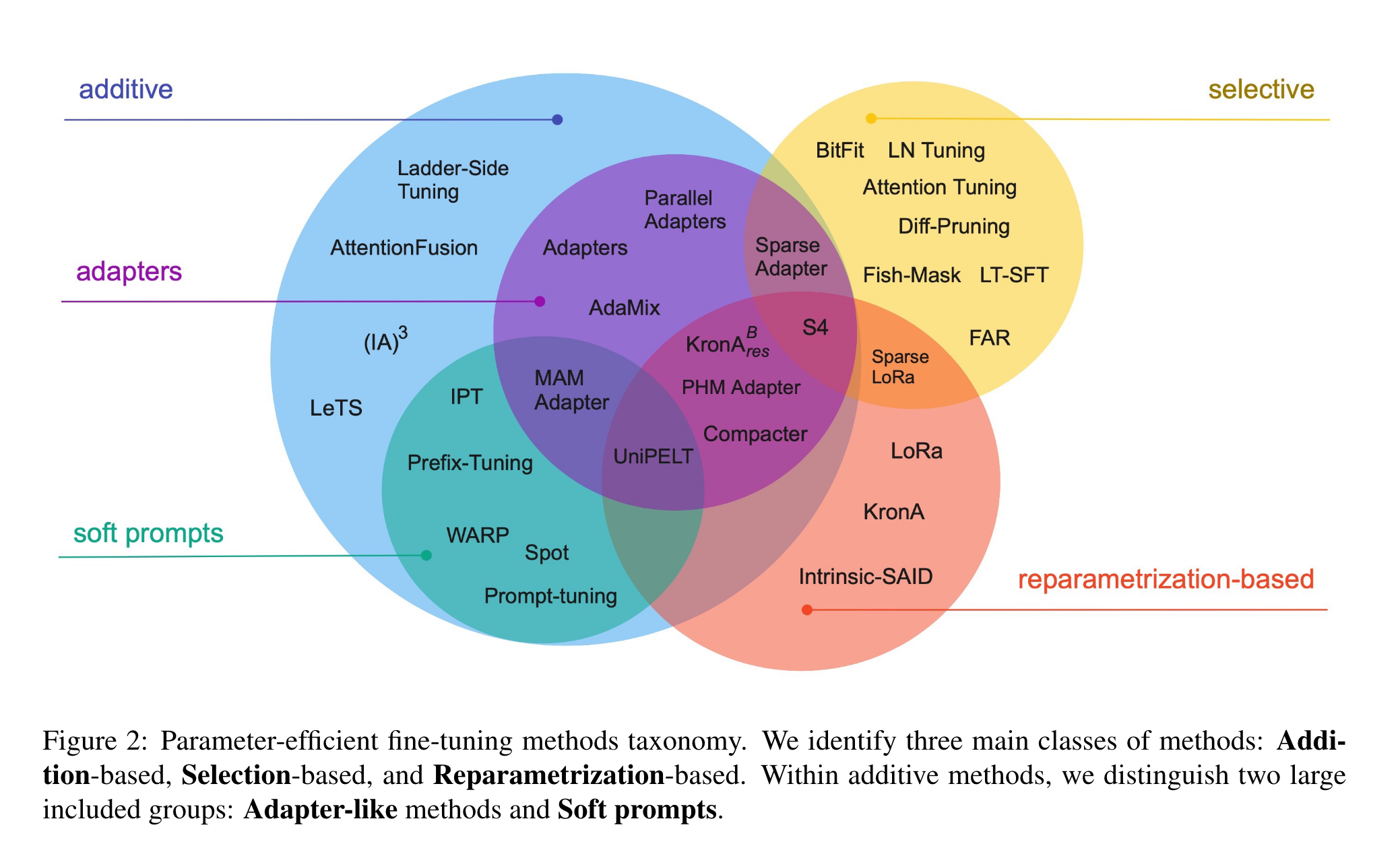
PEFT主要有如下几类1:
- 增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
- 引入重参数化,如:LoRA、AdaLoRA、QLoRA。
- 选取一部分参数更新,如:BitFit。
- 混合高效微调,如:MAM Adapter、UniPELT。
1 Intuition behind PEFT
模型微调的背后直觉:
- 微调具有低内在维度,意思是:为了达到令人满意的性能,模型实际需要调整的参数数量并不多。这表明,在一个庞大的模型中,并不需要修改所有的参数,只要修改其中一部分关键的参数就可以让模型获得不错的性能。这一发现是PEFT的核心思想。
- 我们可以用低维的代理参数来重新参数化模型中的一部分原始参数。这意味着在进行模型微调时,我们可以不必对模型的所有参数进行优化,只需找到一些“代理参数”(low-dimensional proxy parameters),这些代理参数是低维的,且能很好地代表原始模型的一部分,从而简化优化的过程。
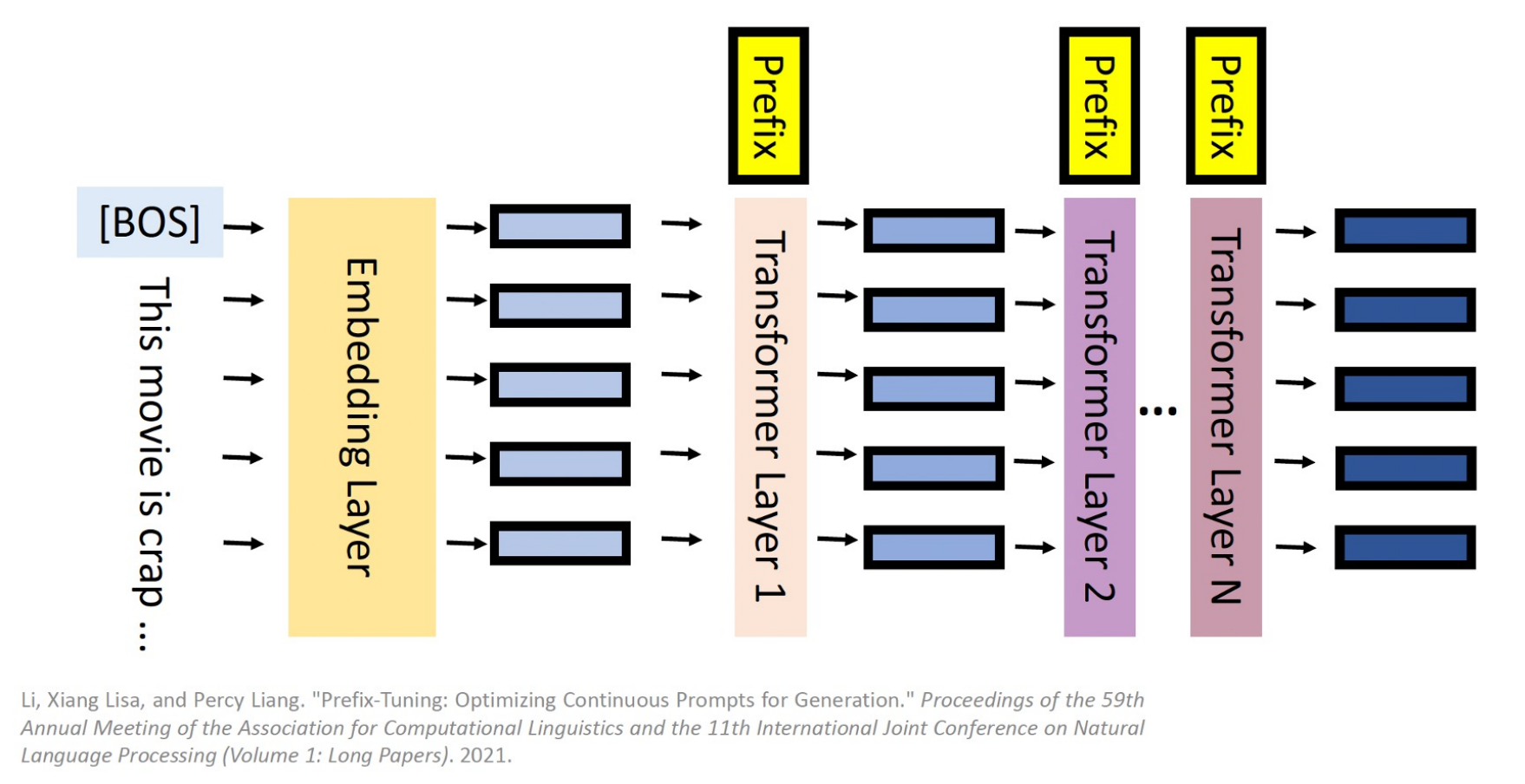
2 Prefix Tuning
如下图所示,Prefix Tuning在每一个Transformer层都加上一些可训练的virtual token作为前缀,以适应不同的任务。
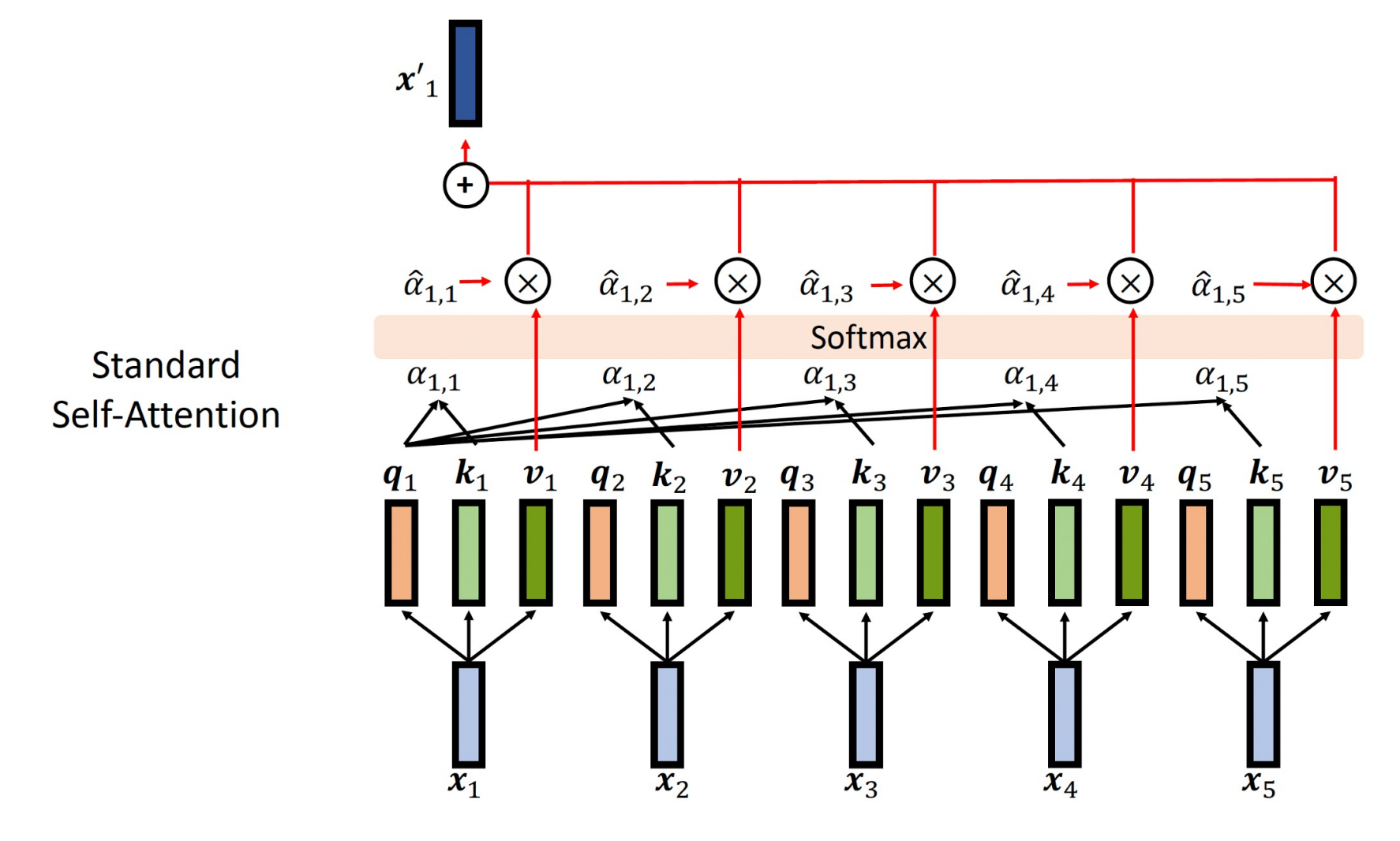
具体怎么做呢,下图是没有Prefix的注意力计算。
下图是加入Prefix的注意力计算,我们可以看到:
- 前缀不影响原始输入数据本身,在 Prefix Tuning 中 , 前缀 向量不会在模型输入之前直接添加,不会像 Prompt Tuning 会在输入前添加一个额外的提示词那样。相反,前缀向量是添加在模型的隐藏层(尤其是自注意力机制)中的,影响模型对输入数据的处理,但不改变输入数据本身。
- 比如,假设你有一个输入句子 “Starbucks serves coffee”,这个句子作为输入传入模型,Prefix Tuning 的前缀不会直接拼接在这个句子前,加入到每层自注意力机制的 Key 和 Value 中,从而影响模型的内部计算
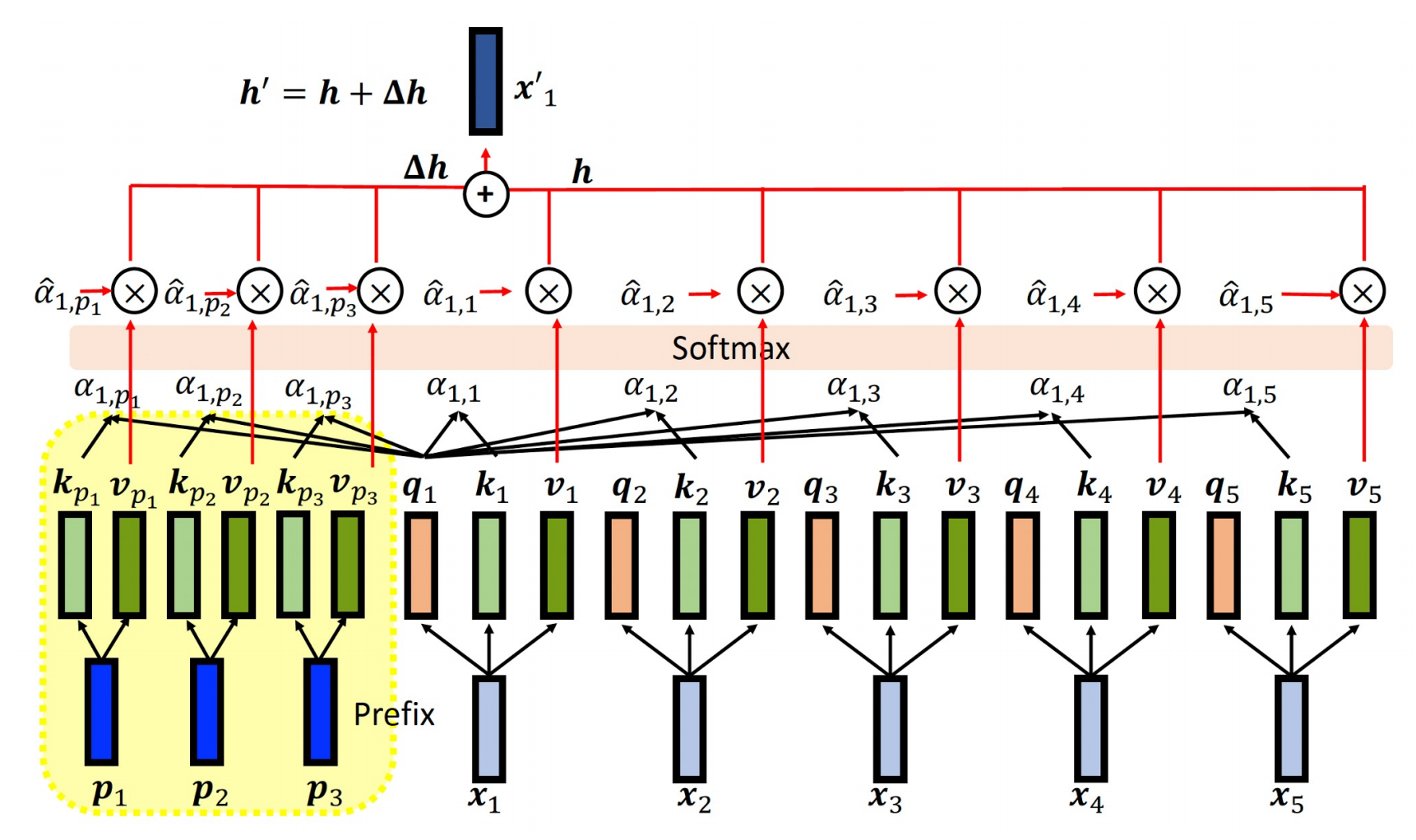
在微调时,我们只会更新Prefix这些参数,所以前缀向量的作用是增强自注意力机制中的上下文信息:
- 在 Transformer 模型中,注意力机制的核心在于通过每个 token 之间的关联性来构建上下文。Prefix Tuning 通过给每层 Transformer 添加一组可训练的前缀向量,这些向量与输入的 token 一起作为注意力机制的输入,但它们不对应输入的具体 token,而是额外的信息源。
- 具体来说,在计算注意力分数时,前缀向量作为额外的注意力查询键(key)和值(value)参与自注意力的计算。这意味着,输入的 token 不仅会彼此之间产生注意力分数,还会与这些前缀向量产生注意力,从而增强模型对任务相关上下文的理解。
3 Prompt Tuning
该方法可以看着是Prefix Tuning的简化版本,针对不同的任务,仅在输入层引入virtual token形式的软提示(soft prompt),如下图所示:
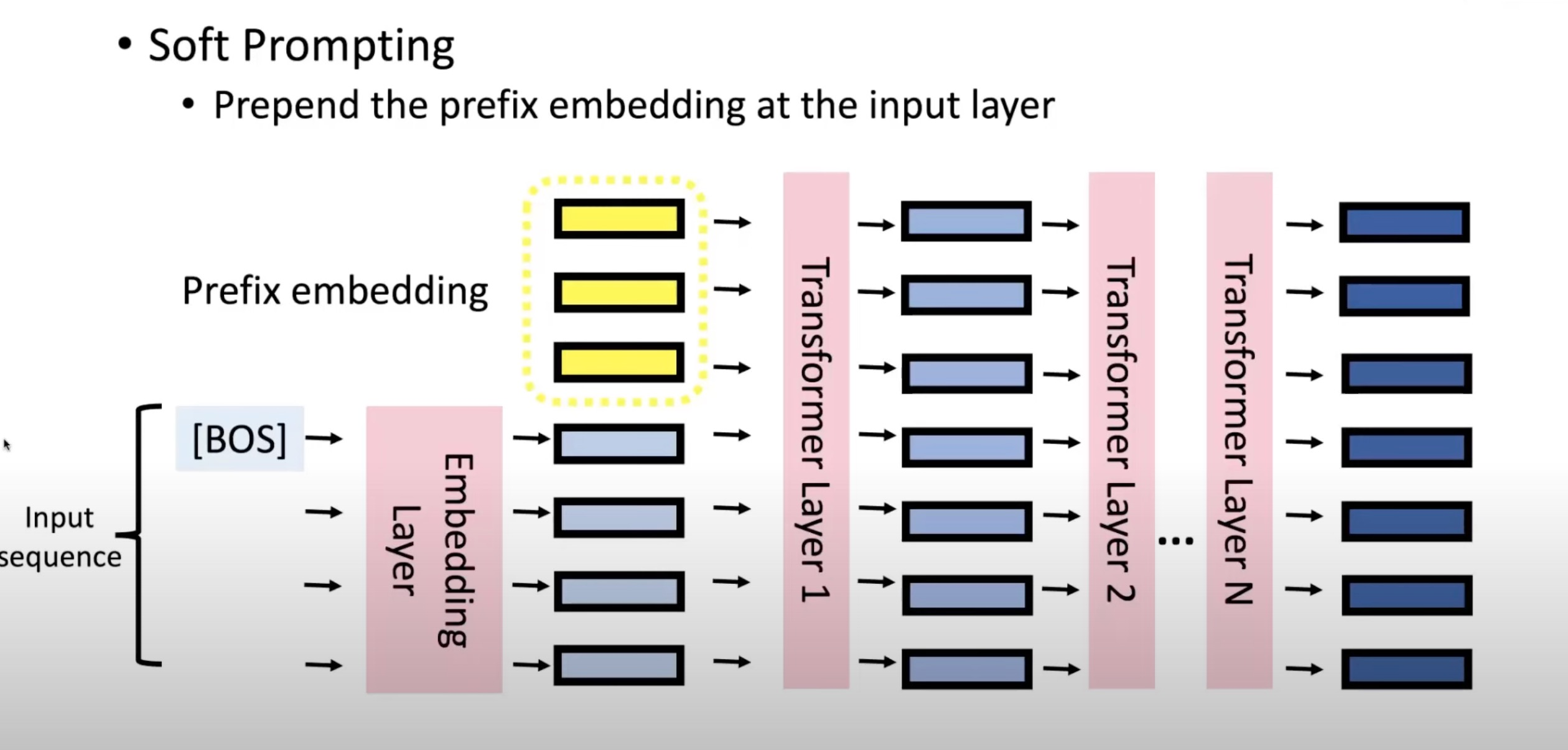
特点:
- 相对于Prefix Tuning,参与训练的参数量和改变的参数量更小,更节省显存。
- 对一些简单的NLU 任务还不错,但对硬序列标记任务(即序列标注)表现欠佳。
4 Adapter Tuning
该方法设计了Adapter结构,并将其嵌入Transformer的结构里面,针对每一个Transformer层,增加了两个Adapter结构,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构和Layer Norm 层进行微调。 Adapter结构如下图右边所示:
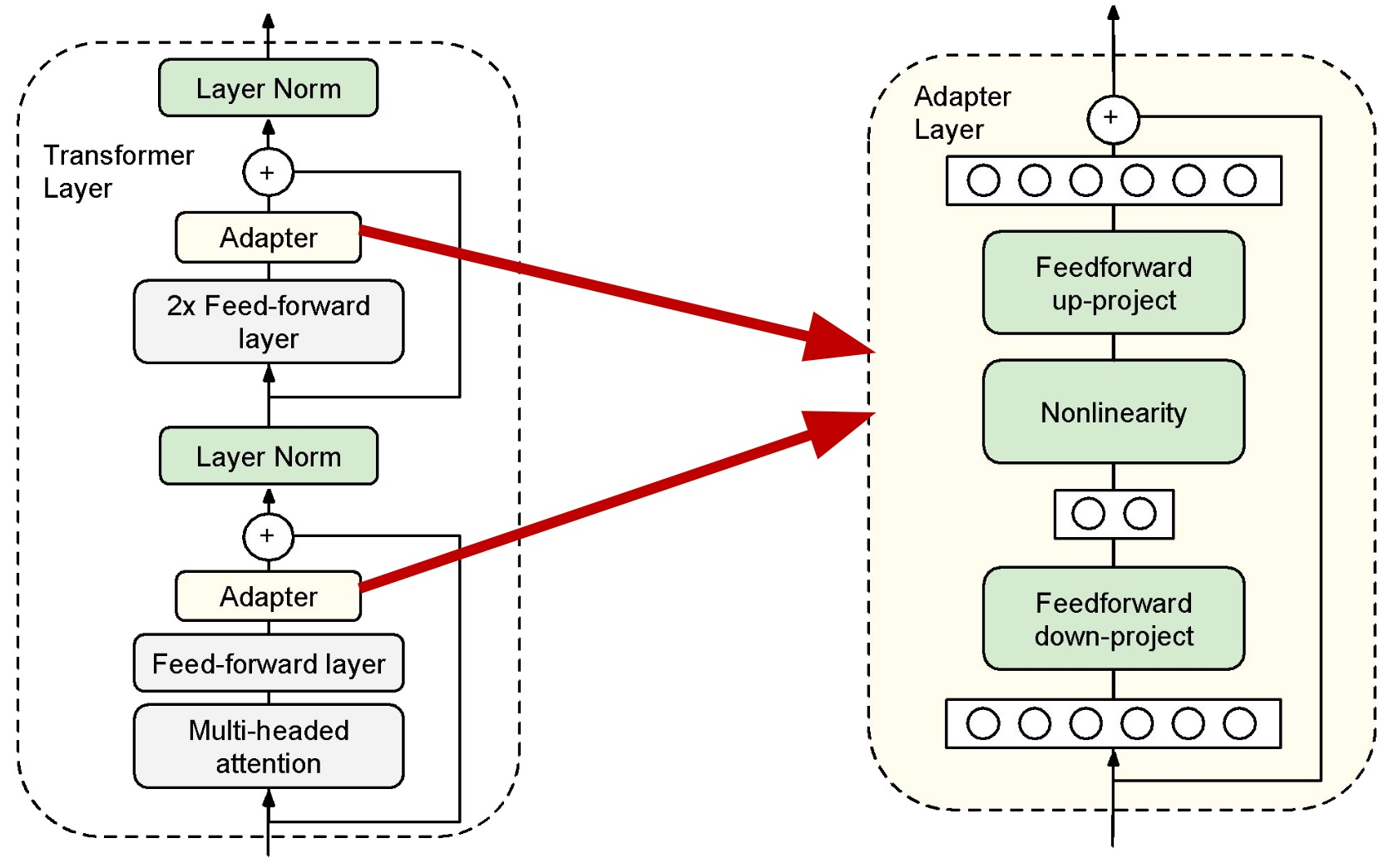
如下图所示,Adapter可以加在每个Transformer Layer.
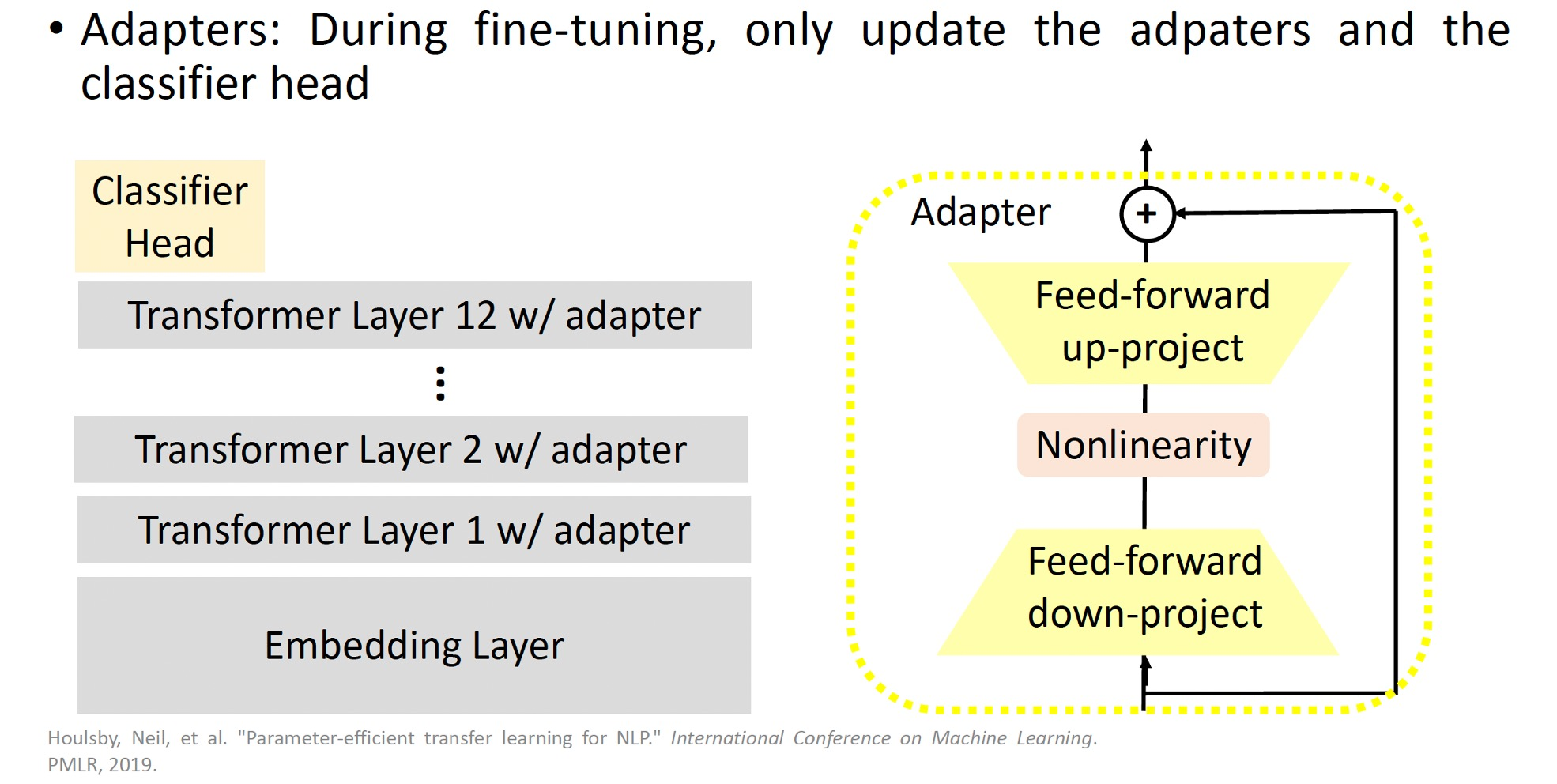
Adapter的缺点:
- 添加新层会导致推理速度变慢。
- 这也会使模型变大(可能更难适应现有的GPU资源)。
- 适配器层在推理时需要顺序处理,这可能会破坏模型的并行性。
5 LoRA
LoRA的主要特点为:
- LoRA通过冻结预训练模型的权重,并在Transformer架构的每一层中注入可训练的低秩分解矩阵来解决上述问题。
- 这种方法显著减少了下游任务的可训练参数数量。例如,与GPT-3 175B的全参数微调相比,LoRA将可训练参数数量减少了10,000倍,GPU内存需求减少了3倍。
(1)核心思想
在Transformer中有很多全连接层,这些全连接层涉及到矩阵相乘的运算。论文的一个核心假设是针对于特定的任务,这些全连接层的权重矩阵在低秩的情况下,模型的效果也很好。
所以作者提出在微调时,可以学习模型中全连接矩阵增量的一个低秩表示,同时这里还用到了类似“残差”的思想,不重新学习整个
W
W
W,而是学习一个增量
Δ
W
=
A
⋅
B
\Delta W=A\cdot B
ΔW=A⋅B,最终的参数为:
W
T
=
W
+
Δ
W
W_T=W+\Delta W
WT=W+ΔW
其中
W
W
W是预训练模型的原始参数。同时,原论文只关注注意力层的权重矩阵,如下图所示:
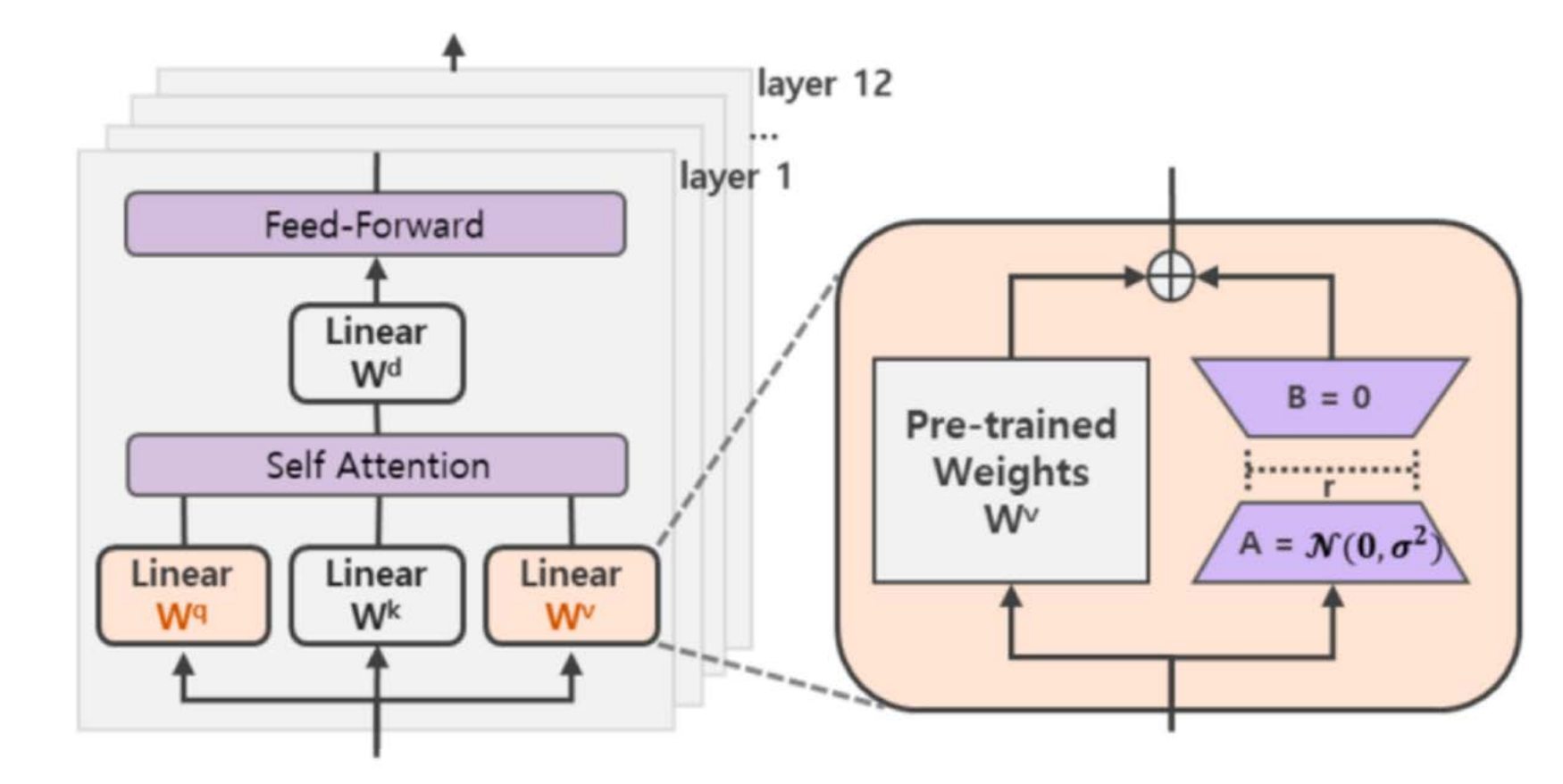
上图右边部分更加具体的结构如下图所示:
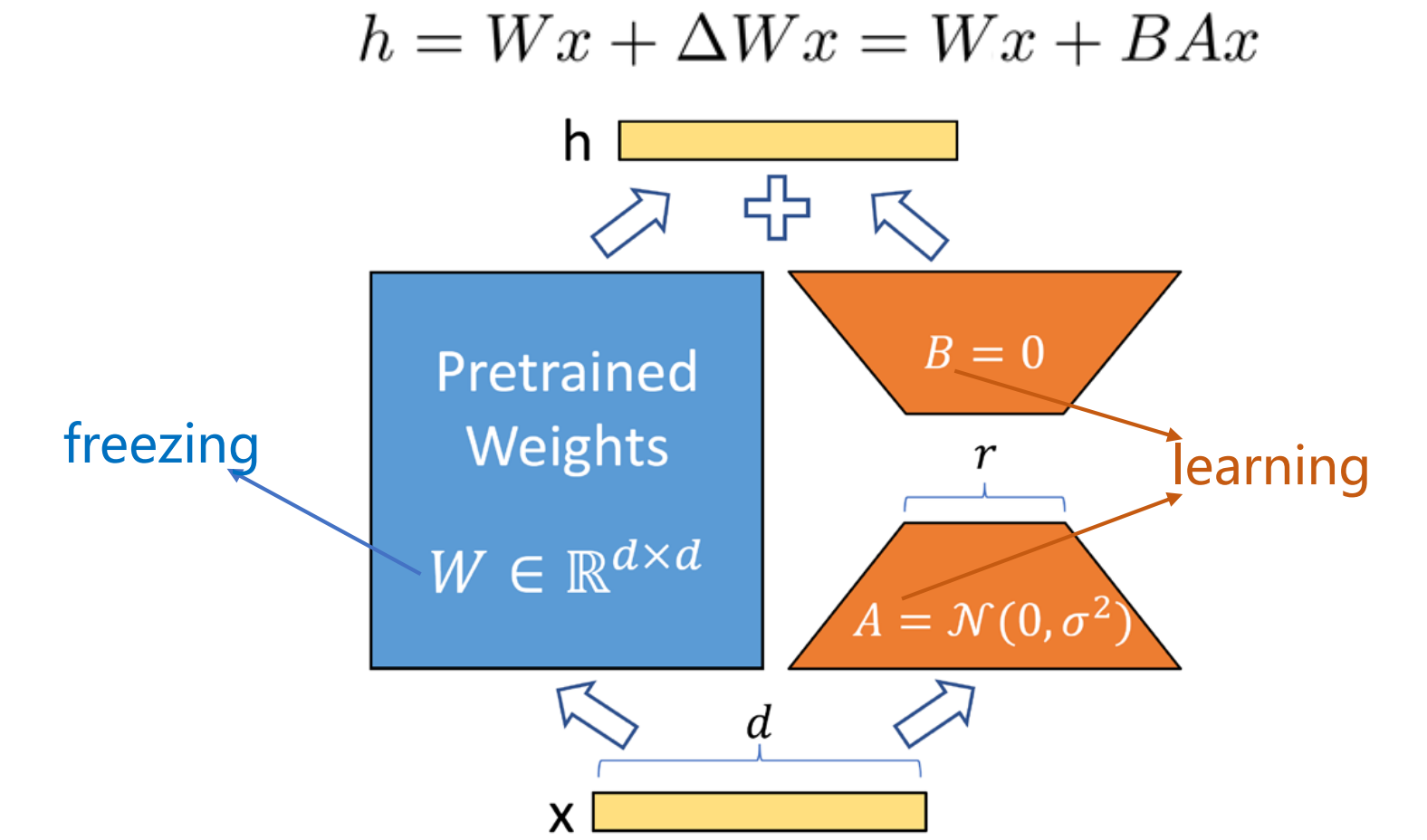
这里 r r r远小于 d d d,假设 d = 1000 d=1000 d=1000, W W W矩阵参数量为 1000 × 1000 1000\times1000 1000×1000,若采用低秩分解,设 r = 2 r=2 r=2,则 A 、 B A、B A、B矩阵参数量为 1000 × 2 × 2 = 4000 1000\times2\times 2=4000 1000×2×2=4000远小于 W W W,训练的参数量大大减小!
(2)图解
原论文是对Attention的权重矩阵做Lora分解,实际应用也可以对Feed-forward层做,如下图所示。
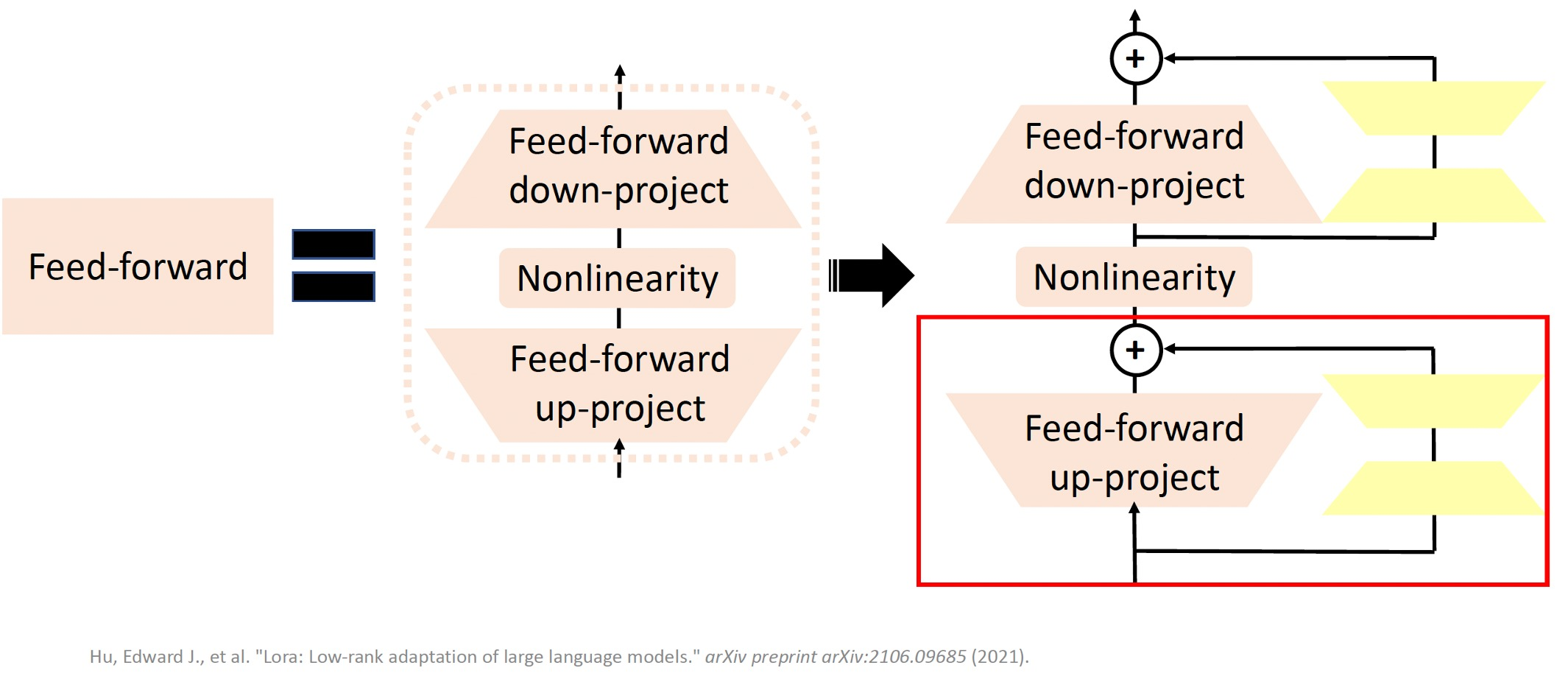
全连接层一般有两个矩阵,一个上投影矩阵 H × 4 H H\times 4H H×4H,一个下投影矩阵 4 H × H 4H\times H 4H×H,可以对每个矩阵做Lora,如下图所示:
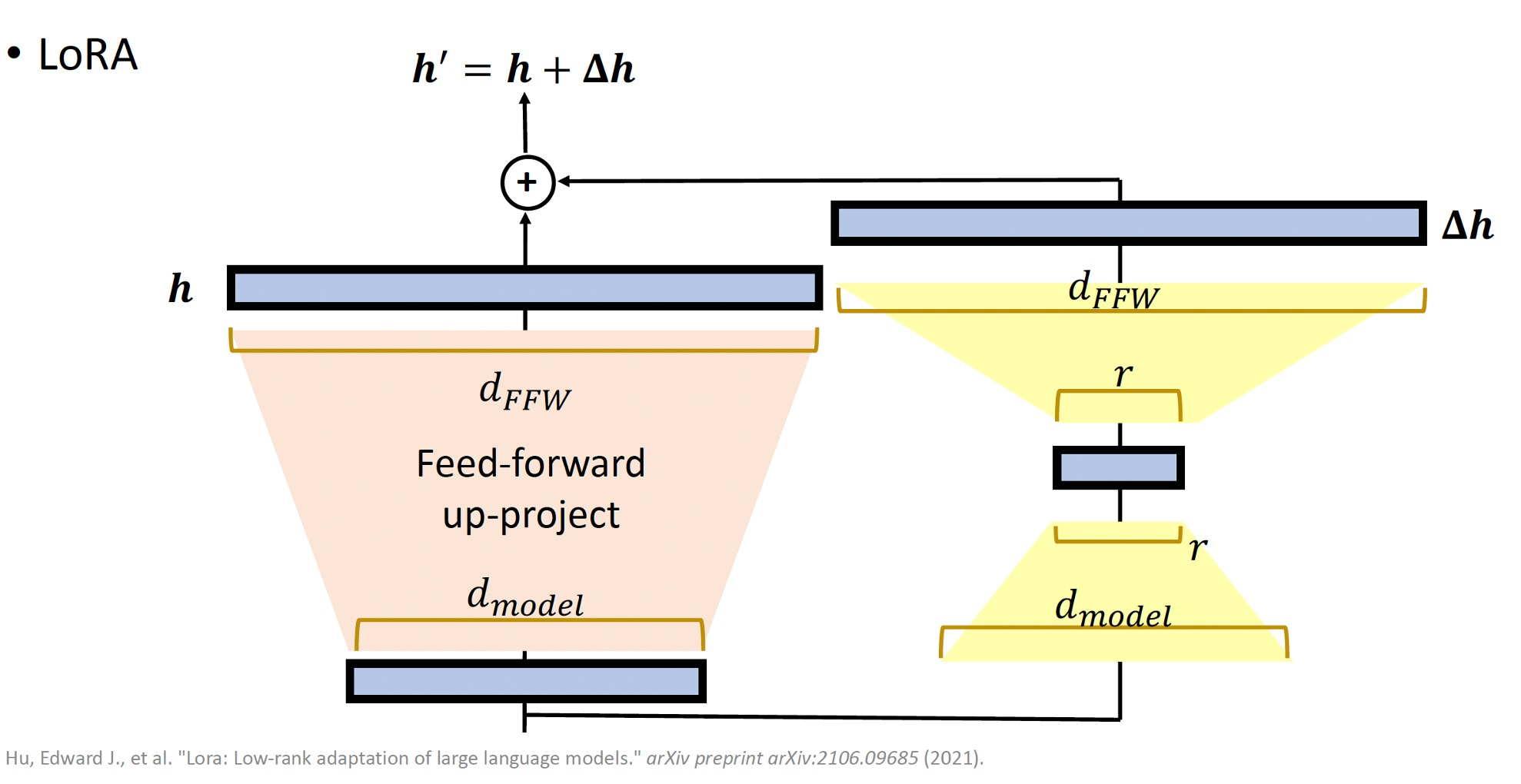
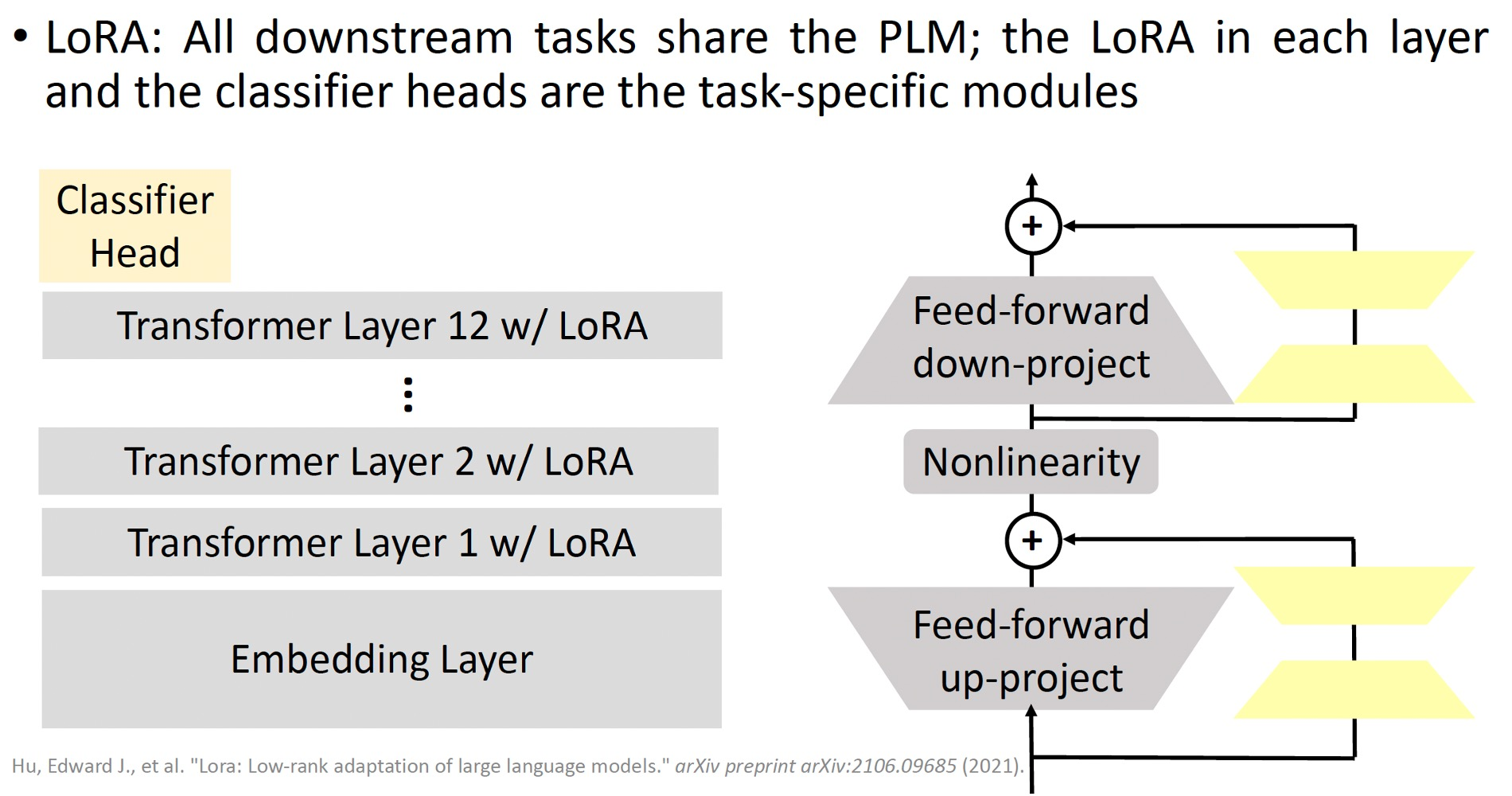
同理,Lora也可以在每个Transformer层加,如下图所示:
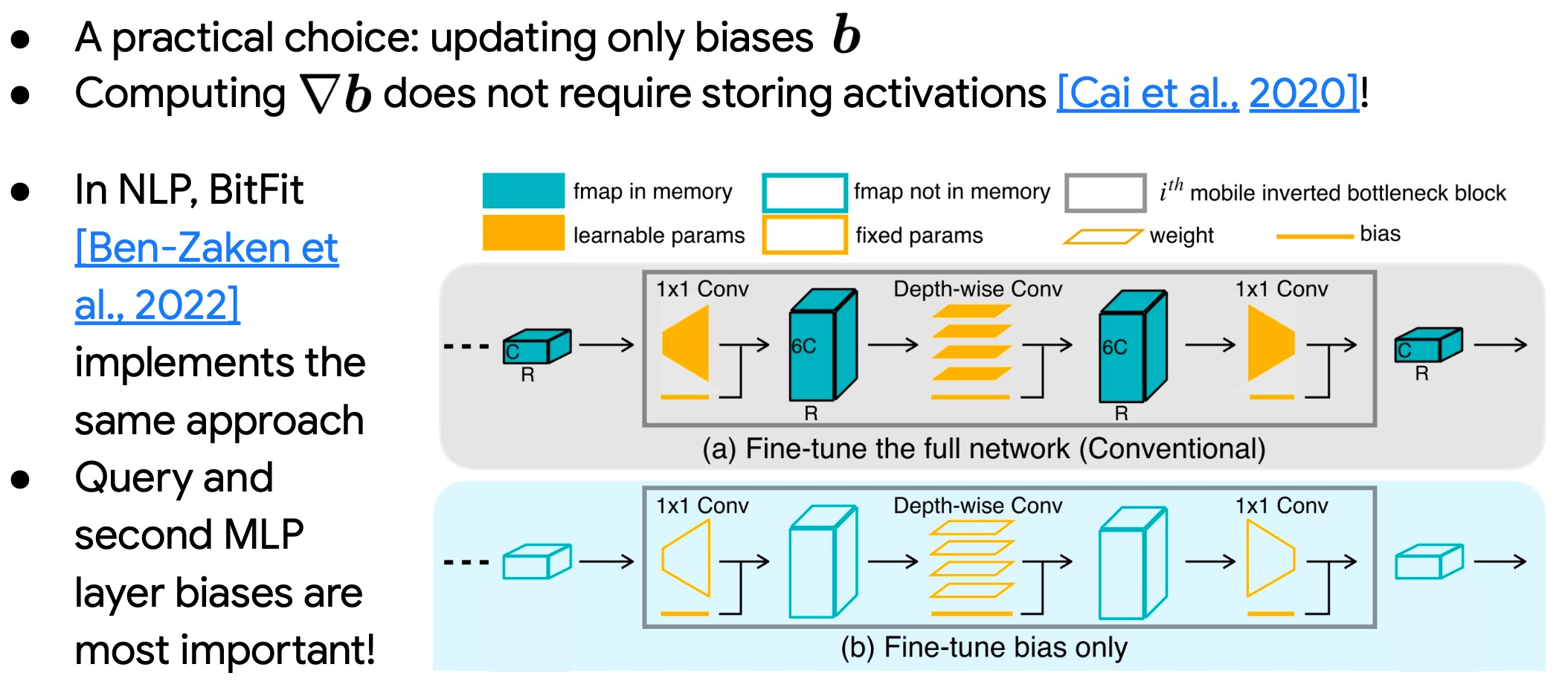
6 BitFit
BitFit( Bias-terms Fine-tuning),顾名思义,仅更新Bias项的微调技术。

如下图所示,仅更新Bias项,所需要的内存大大减少。
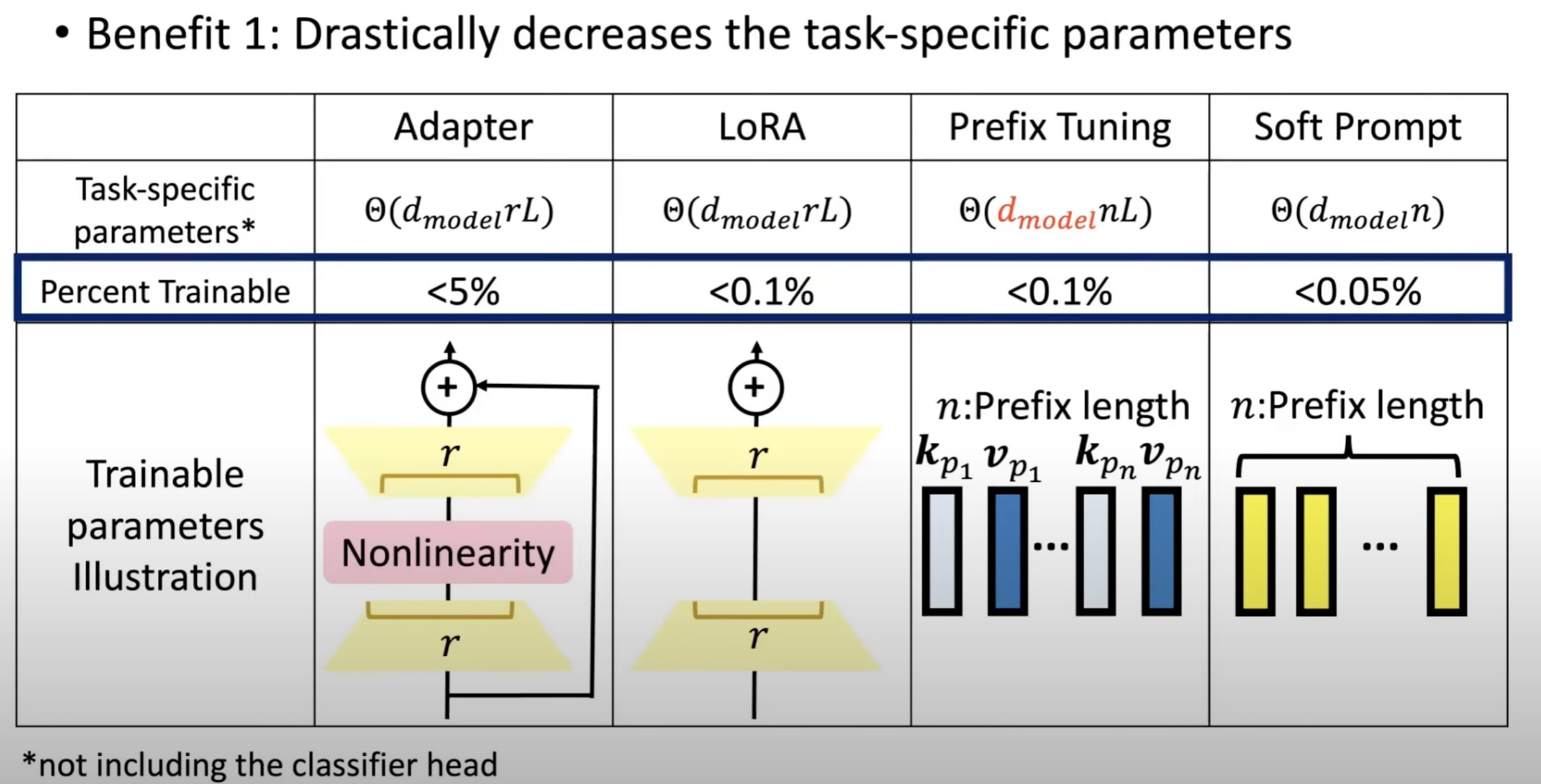
7 多种不同的高效微调方法对比
如下图所示,PEFT需要更新的参数比例非常小!
多种PEFT方法和全参数微调效果对比2:
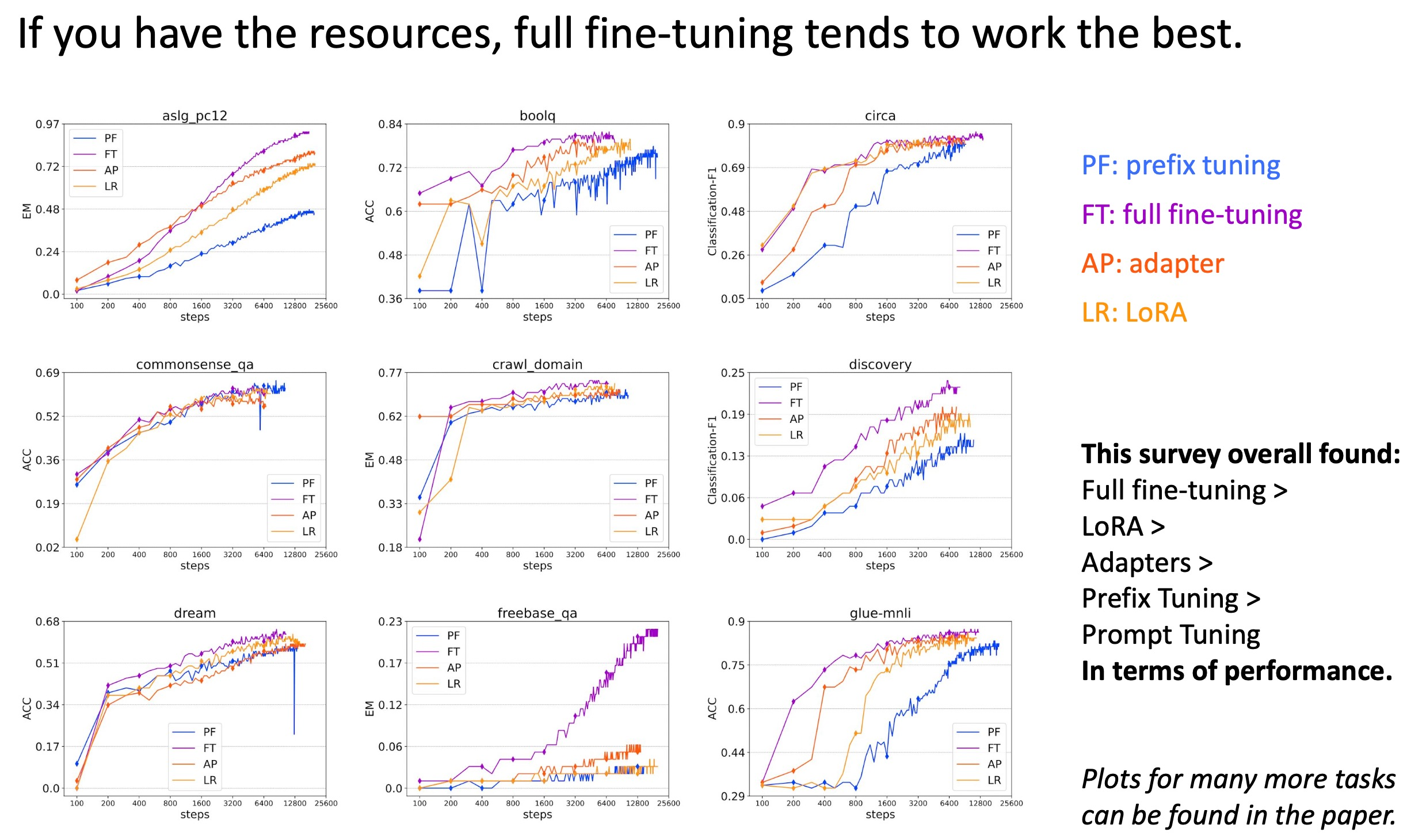
总的来说,全参数微调效果最好,如果资源足够首选全参数微调。像LoRA、P-Tuning v2等都是综合评估很不错的高效微调技术。如果显存资源有限可以考虑QLoRA;如果只是解决一些简单任务场景,可以考虑P-Tuning、Prompt Tuning也行。
8 关于PEFT的库
-
OpenAI 微调 API
- 可用的模型:gpt-3.5-turbo-0613,babbage-002 和 davinci-002.
-
HuggingFace PEFT 库
- 实现了 LoRA,Prefix Tuning,Prompt Tuning等;
- 有多种不同的模型可供适配.
参考资料
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning ↩︎
Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models.” Ding et al. 2023 ↩︎