数据源分层开发和连接池
1. javaweb中常见的分层结构
在 Java Web 应用 中,通常有以下常见的分层结构,每一层都有不同的职责:
1.1. 常见分层
1.1.1. 表现层(Presentation Layer):
- 主要用于处理用户界面和交互。
- 表现层包括 JSP 页面、HTML、CSS、JavaScript 等,用于显示数据和接收用户输入。
- 控制类(Servlet、Controller 等)会将请求转发到 JSP 或模板引擎进行页面渲染,形成最终的 HTML 响应。
1.1.2. 控制层(Controller Layer):
- 负责处理客户端请求、执行相应的业务逻辑,并将响应返回给客户端。
- 在 Java Web 中,控制层通常使用 Servlet,也可以使用 Spring MVC 的
@Controller注解。 - 控制层接收用户请求后,会将请求分发给合适的业务逻辑处理类,并根据业务处理结果转发到不同的页面。
这里咱们还没有学到spring 所以控制层就是servlet请求处理层
1.1.3. 业务逻辑层(Service Layer):
- 包含应用程序的核心业务逻辑,负责处理具体的业务需求。
- Service 层从控制层接收到请求后,调用数据访问层获取或处理数据。
- 业务逻辑层确保了数据的完整性和业务规则的执行。
- 这一层通常不直接与数据库交互,而是通过 DAO 层来操作数据。
1.1.4. 数据访问层(DAO/Data Access Object Layer):
- 负责与数据库进行交互,执行数据的增删改查操作。
- DAO 层使用 JDBC 或 ORM(如 Hibernate、MyBatis)等技术,将数据库表的数据封装成 Java 对象。
- 这一层对数据库操作进行了抽象,使得业务逻辑层不需要关注数据库细节,提高了系统的可维护性。
1.1.5. 实体层(Model 或 POJO 层):
- 实体层是一些 JavaBean 或 POJO(Plain Old Java Object),表示业务实体或数据库表。
- 每个实体类通常对应数据库中的一张表,封装了该表的字段及其访问方法(getter 和 setter)。
- 这些类在业务逻辑层和数据访问层之间传递数据,起到数据模型的作用
说白了主要用于数据的就收和传递
1.1.6. 工具层(Utilities Layer):
- 提供各种辅助工具类和方法,如字符串处理、日期转换、加密解密、日志记录等。
- 工具层中的类和方法一般是静态的,可以在整个应用程序中随时调用
比如:BaseDao工具类
1.1.7. 过滤器和监听器(Filters and Listeners):
- 过滤器(Filter):在请求到达 Servlet 之前进行预处理(如设置编码、权限验证),或在响应发出之前进行后处理。
- 监听器(Listener):监听应用范围内的特定事件,如会话创建、销毁,或 ServletContext 初始化、销毁等。
- 过滤器和监听器通常用来处理一些全局性、通用的需求。
1.1.8. 配置层(Configuration Layer):
- 包含应用程序的配置信息,如数据库连接信息、系统常量、应用程序的初始化参数等。
如:jdbc.properties
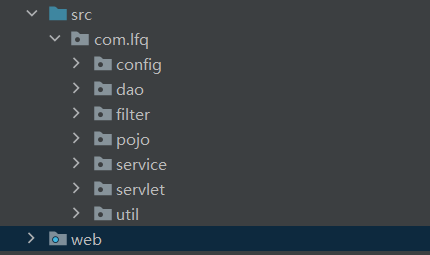
每个层次的具体内容这里不做一一列举了 后面我会发我最近敲的一个demo项目
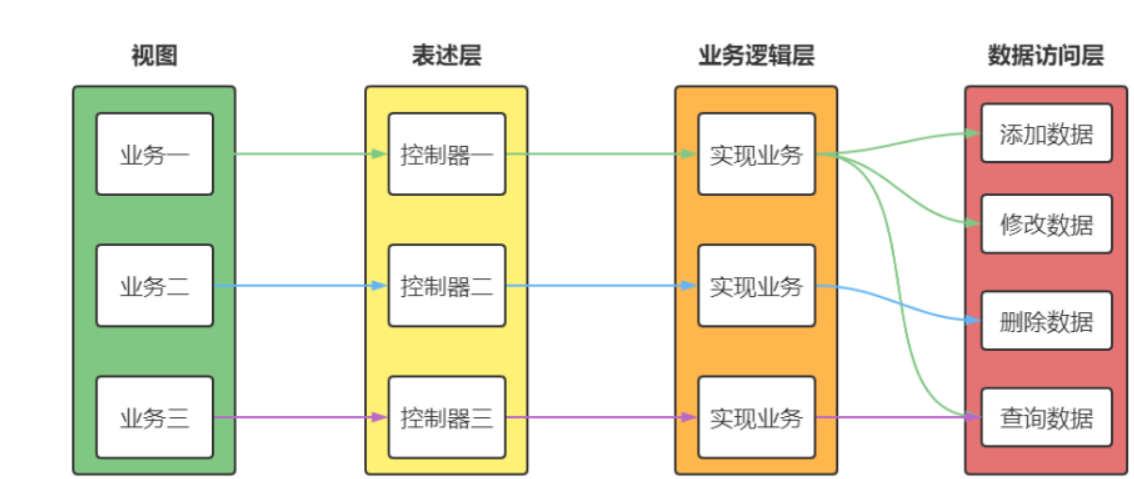
1.2. 三层结构
三层结构就是将整个业务应用划分为:表述层、业务逻辑层 、数据访问层。区分层次的目的即为了“高内 聚低耦合”的思想。在软件体 系架构设计中,分层式结构是最常见,也是最重要的一种结构。
2. 使用JavaBean封装数据
在 Java Web 开发中,JavaBean 是用于封装数据的类,一般用于表示业务实体或数据对象,通过其属性来传递和接收数据。
2.1. JavaBean 特性
- 类必须是公共的 (
public)。 - 必须有一个无参构造函数。
- 属性应通过
getter和setter方法来访问。 - 字段应使用
private访问修饰符来保护数据。
如:User类
public class User {
private int id;
private String name;
private String email;
// 无参构造函数
public User() {
}
// 带参构造函数(可选)
public User(int id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
// Getter 和 Setter 方法
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "User{id=" + id + ", name='" + name + "', email='" + email + "'}";
}
}
2.2. 使用 JavaBean 在 Servlet 中封装数据
import jakarta.servlet.ServletException;
import jakarta.servlet.annotation.WebServlet;
import jakarta.servlet.http.HttpServlet;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebServlet("/userServlet")
public class UserServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 创建 User 对象并封装数据
User user = new User(1, "Alice", "alice@example.com");
// 将 User 对象放入 request 域中
request.setAttribute("user", user);
//当然这个可以进一步拓展调用Dao层操作进行数据库处理
// 转发请求到 JSP 页面
request.getRequestDispatcher("user.jsp").forward(request, response);
}
}
2.3. 在 JSP 页面中获取 JavaBean 数据
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<html>
<head>
<title>User Information</title>
</head>
<body>
<h2>User Information</h2>
<p>ID: ${user.id}</p>
<p>Name: ${user.name}</p>
<p>Email: ${user.email}</p>
</body>
</html>
3. JSP动作标签
通过动作标签,程序员可以在JSP页面中把页面的显示功能部分封装起来,使整个页面更简洁和易于维护
3.1.1. <jsp:useBean>
<jsp:useBean> 标签是 JSP 中用于创建或获取 JavaBean 的一个标准标签。它允许你在 JSP 页面中声明一个 JavaBean,自动处理 JavaBean 的创建、查找和绑定。
<jsp:useBean id="beanName" class="com.example.YourBeanClass" scope="request|session|application" />- id: 用于标识 JavaBean 实例的变量名。
- class: JavaBean 的全限定类名。
- scope: JavaBean 的作用域,通常是
request、session或application。如果不指定,则默认为request。
3.1.2. <jsp:include>
<jsp:include> 标签是 JSP 中用于在一个 JSP 页面中包含另一个 JSP 页面或静态资源(如 HTML 文件)的标准标签。
基本语法 :
<jsp:include page="relativeURL" flush="true|false" />
- page: 要包含的资源的相对 URL,可以是 JSP 页面、HTML 文件等。
- flush: 可选属性,指示是否在包含时刷新输出流。如果设置为
true,在执行包含之前会先将当前输出流的内容刷新;如果设置为false,则不会刷新。默认值为false。
工作原理
- 当 JSP 页面被请求时,
<jsp:include>标签会在响应生成过程中插入指定页面的内容。 - 包含的页面可以使用请求和响应对象,与原始页面共享同一请求。
<%@include%>:
<%@ include %> 是 JSP 中用于在编译时将一个 JSP 文件或其他资源的内容直接插入到另一个 JSP 文件中的指令。与 <jsp:include> 不同,<%@ include %> 在页面被请求之前就会被处理,这意味着被包含的页面的内容会在编译时静态地嵌入到主页面中。
<%@ include file="relativeURL" %>
file: 要包含的文件的相对路径,可以是 JSP 页面、HTML 文件等。
工作原理
- 当 JSP 页面被编译时,
<%@ include %>指令会将指定文件的内容插入到当前 JSP 页面中。这是一个静态包含,因此文件的内容在编译时就已经被复制到主页面中。
这也就意味着 你后面在修改<%@ include %>中嵌入jsp文件的代码 对被嵌入的jsp页面是没有影响的除非重新编译被嵌入页面

3.1.3. <jsp:forward>
<jsp:forward> 是 JSP 中用于请求转发的标签,它允许将请求从当前 JSP 页面转发到另一个资源(如另一个 JSP 页面、Servlet 或 HTML 文件)。与其他包含机制相比,<jsp:forward> 主要用于将请求处理的控制权转交给另一个资源,同时保留原请求的上下文。
语法 :
<jsp:forward page="relativeURL" />
page 属性是要转发到的目标资源的相对路径。
特点:
- 请求转发: 处理请求后,控制权转发到另一个资源,客户端不知情。
- 共享请求对象: 转发过程中,原请求的请求对象(
request)和响应对象(response)会传递给目标资源。这意味着在目标资源中可以访问原请求的所有属性。 - 不改变 URL: 客户端的 URL 不会改变,浏览器仍然显示原 URL。
4. 连接池
4.1. 连接池的理解
Connection对象是重量级对象,创建Connection对象就是建立两个进程之间的通信,非常耗费资源。一次完整的数据库操作,大部分时间都耗费在连接对象的创建。
第一个问题:每一次请求都创建一个Connection连接对象,效率较低。
第二个问题:连接对象的数量无法限制。如果连接对象的数量过高,会导致mysql数据库服务器崩溃。
4.2. 使用连接池来解决什么问题
提前创建好N个连接对象,将其存放到一个集合中(这个集合就是一个缓存)。
用户请求时,需要连接对象直接从连接池中获取,不需要创建连接对象,因此效率较高。
另外,连接对象只能从连接池中获取,如果没有空闲的连接对象,只能等待,这样连接对象创建的数量就得到了控制。
4.3. javax.sql.DataSource
连接池有很多,不过所有的连接池都实现了 javax.sql.DataSource 接口。也就是说我们程序员在使用连接池的时候,不管使用哪家的连接池产品,只要面向javax.sql.DataSource接口调用方法即可。
另外,实际上我们也可以自定义属于我们自己的连接池。只要实现DataSource接口即可。
4.4. 连接池的属性
对于一个基本的连接池来说,一般都包含以下几个常见的属性:
- 初始化连接数(initialSize):连接池初始化时创建的连接数。
- 最大连接数(maxActive):连接池中最大的连接数,也就是连接池所能容纳的最大连接数量,当连接池中的连接数量达到此值时,后续请求会被阻塞并等待连接池中有连接被释放后再处理。
- 最小空闲连接数量(minIdle): 指连接池中最小的空闲连接数,也就是即使当前没有请求,连接池中至少也要保持一定数量的空闲连接,以便应对高并发请求或突发连接请求的情况。
- 最大空闲连接数量(maxIdle): 指连接池中最大的空闲连接数,也就是连接池中最多允许保持的空闲连接数量。当连接池中的空闲连接数量达到了maxIdle设定的值后,多余的空闲连接将会被连接池释放掉。
- 最大等待时间(maxWait):当连接池中的连接数量达到最大值时,后续请求需要等待的最大时间,如果超过这个时间,则会抛出异常。
- 连接有效性检查(testOnBorrow、testOnReturn):为了确保连接池中只有可用的连接,一些连接池会定期对连接进行有效性检查,这里的属性就是配置这些检查的选项。
- 连接的driver、url、user、password等。
以上这些属性是连接池中较为常见的一些属性,不同的连接池在实现时可能还会有其他的一些属性,不过大多数连接池都包含了以上几个属性,对于使用者来说需要根据自己的需要进行灵活配置。
4.5. 连接池的使用
4.5.1. Druid的使用
第一步:引入Druid的jar包

第二步:配置文件
在类的根路径下创建一个属性资源文件:jdbc.properties
url=jdbc:mysql://localhost:3306/jdbc
username=root
password=1234
driverClassName=com.mysql.cj.jdbc.Driver
initialSize=5
minIdle=10
maxActive=20第三步:编写代码,从连接池中获取连接对象
// 读取属性配置文件
InputStream in = DruidConfig.class.getClassLoader().getResourceAsStream("jdbc.properties");
Properties props = new Properties();
props.load(in);
// 创建连接池
DataSource dataSource = DruidDataSourceFactory.createDataSource(props);
Connection conn = dataSource.getConnection();第四步:关闭连接
仍然调用Connection的close()方法,但是这个close()方法并不是真正的关闭连接,只是将连接归还到连接池,让其称为空闲连接对象。这样其他线程可以继续使用该空闲连接。
4.5.2. HikariCP的使用
第一步:引入jar包
第二步:编写配置文件
在类的根路径下创建一个属性资源文件:jdbc2.properties
jdbcUrl=jdbc:mysql://localhost:3306/jdbc
username=root
password=1234
driverClassName=com.mysql.cj.jdbc.Driver
minimumIdle=5
maximumPoolSize=20第三步:编写代码,从连接池中获取连接
InputStream in = HikariConfig.class.getClassLoader().getResourceAsStream("jdbc2.properties");
Properties props = new Properties();
props.load(in);
HikariConfig config = new HikariConfig(props);
DataSource dataSource = new HikariDataSource(config);
Connection conn = dataSource.getConnection();第四步:关闭连接(调用conn.close(),将连接归还到连接池,连接对象为空闲状态。)