Nginx开发实战——网络通信(一)
文章目录
- Nginx开发框架
- 信号处理函数的进一步完善(避免僵尸子进程)(续)
- ngx_signal.cxx
- ngx_process_cycle.cxx
- 网络通信实战
- 客户端和服务端
- 1. 解析一个浏览器访问网页的过程
- 2.客户端服务器角色规律总结
- 网络模型
- OSI 7层网络模型
- TCP/IP 4层模型
- 3.TCP/IP的解释和比喻
- 最简单的客户端和服务器端程序实现代码
- 1.套接字socket概念
- 2.一个简单的服务器端通信程序范例
- struct sockaddr_in 结构体
- htonl(INADDR_ANY)
- htonl和htons的区别
- server.c
- 3.IP地址浅谈
- 4.一个简单的客户端通信程序范例
- client.c
- inet_pton函数
- TCP和UDP的区别
- TCP和UDP各有优缺点
- TCP和UDP各自的用途
- TCP连接的三次握手
- 1.最大传输单元MTU
- 2.TCP包头结构
- 3. TCP数据包收发之前的准备工作
- 4.TCP三次握手建立连接的过程
- 5.为什么 TCP握手是3次握手而不是2次
- telnet工具使用
- server.c
- read函数
- read 和 write 的区别
- Wireshark监视数据包
- TCP断开的四次挥手
- TCP状态转换
- server.c
- server.c
- TIME_WAIT状态
- RST 标志
- SO_REUSEADDR选项
- setsockopt 函数
- server.c
- 1. 2个进程,绑定同一个IP和端口
- 2.TIME_WAIT状态时的bind绑定
- listen 队列剖析
- 1.监听套接字队列
- 2.accept函数
- 3. SYN攻击
- 阻塞与非阻塞 I / O
- 1.阻塞I / O
- recvfrom 函数
- 2.非阻塞I / O
- 非阻塞模式有2个鲜明的特点
- 比较阻塞和非阻塞I/O模型在调用recvfrom时不同的代码执行表现
- 异步与同步 I / O
- 1.异步I / O
- 2.同步I / O
- I / O复用
- I/O 多路复用:select/poll/epoll
- 最基本的 Socket 模型
- 如何服务更多的用户?
- 多进程模型
- 多线程模型
- I/O 多路复用
- select/poll
- epoll
- 总结
- 监听端口
- config.mk
- nginx.conf
- ngx_c_socket.cxx
- delete 和 clear的区别
- ioctl 函数
- ioctl(sockfd, FIONBIO, &nb)
- epoll 技术
- epoll概述
- epoll 原理与函数
- epoll_create函数
- nty_epoll_inner.h
- nty_epoll_rb.c
- epoll_ctl函数
- epoll_wait函数
- 内核向双向链表增加节点
- 通信代码精粹之epoll函数实战
- ngx_c_socket.h
- unsigned
- 位域
- ngx_c_socket.cxx
- 指针最末尾一位绝对是0
- ngx_epolL_init函数的调用
- ngx_process_cycle.cxx
Nginx开发框架
信号处理函数的进一步完善(避免僵尸子进程)(续)
信号处理函数中的代码在编写时应坚持以下2个原则。
- (1)代码尽可能简单,让信号处理函数尽可能快速执行完毕后立刻返回(如只给某个用作标记的全局变量赋一个值,然后在主循环中再处理这些全局变量标记),在信号处理函数中尽量不调用其他函数。
- (2)不要在信号处理函数中执行太复杂的代码以免阻塞其他信号,甚至阻塞整个程序执行流程。
为了区分是master进程还是worker进程,引入全局量ngx_process(标记进程类型:master或worker),并在main主函数以及ngx_worker_process_cycle函数中为该全局量赋值
ngx_signal.cxx
//和信号有关的函数放这里
#include <string.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <signal.h> //信号相关头文件
#include <errno.h> //errno
#include <unistd.h>
#include <sys/wait.h>
#include "ngx_macro.h"
#include "ngx_func.h"
#include "ngx_global.h"
//一个信号有关的结构 ngx_signal_t
typedef struct {
int signo; //信号对应的数字编号 ,每个信号都有对应的#define
const char *signame; //信号对应的中文名字 ,比如SIGHUP
//信号处理函数,这个函数由我们自己来提供,但是它的参数和返回值是固定的【操作系统就这样要求】,大家写的时候就先这么写,也不用思考这么多;
void (*handler)(int signo, siginfo_t *siginfo, void *ucontext); //函数指针, siginfo_t:系统定义的结构
} ngx_signal_t;
//声明一个信号处理函数
//static表示该函数只在当前文件内可见
static void ngx_signal_handler(int signo, siginfo_t *siginfo, void *ucontext);
//获取子进程的结束状态,防止单独kill子进程时子进程变成僵尸进程
static void ngx_process_get_status(void);
//数组 ,定义本系统处理的各种信号,我们取一小部分nginx中的信号,并没有全部搬移到这里,日后若有需要根据具体情况再增加
//在实际商业代码中,你能想到的要处理的信号,都弄进来
ngx_signal_t signals[] = {
// signo signame handler
{ SIGHUP, "SIGHUP", ngx_signal_handler }, //终端断开信号,对于守护进程常用于reload重载配置文件通知--标识1
{ SIGINT, "SIGINT", ngx_signal_handler }, //标识2
{ SIGTERM, "SIGTERM", ngx_signal_handler }, //标识15
{ SIGCHLD, "SIGCHLD", ngx_signal_handler }, //子进程退出时,父进程会收到这个信号--标识17
{ SIGQUIT, "SIGQUIT", ngx_signal_handler }, //标识3
{ SIGIO, "SIGIO", ngx_signal_handler }, //指示一个异步I/O事件【通用异步I/O信号】
{ SIGSYS, "SIGSYS, SIG_IGN", NULL },
//我们想忽略这个信号,SIGSYS表示收到了一个无效系统调用,如果我们不忽略,进程会被操作系统杀死,--标识31
//所以我们把handler设置为NULL,代表 我要求忽略这个信号,请求操作系统不要执行缺省的该信号处理动作(杀掉我)
//...日后根据需要再继续增加
{ 0, NULL, NULL } //信号对应的数字至少是1,所以可以用0作为一个特殊标记
};
//初始化信号的函数,用于注册信号处理程序
//返回值:0成功 ,-1失败
int ngx_init_signals() {
//指向自定义结构数组的指针
ngx_signal_t *sig;
//sigaction:系统定义的跟信号有关的一个结构,我们后续调用系统的sigaction()函数时要用到这个同名的结构
struct sigaction sa;
//将signo == 0作为一个标记,因为信号的编号都不为0;
for (sig = signals; sig->signo != 0; sig++) {
//我们注意,现在要把一堆信息往 变量sa对应的结构里弄 ......
memset(&sa, 0, sizeof(struct sigaction));
if (sig->handler) //如果信号处理函数不为空,这当然表示我要定义自己的信号处理函数
{
sa.sa_sigaction = sig->handler;
//sa_sigaction:指定信号处理程序(函数),注意sa_sigaction也是函数指针,是这个系统定义的结构sigaction中的一个成员(函数指针成员);
sa.sa_flags = SA_SIGINFO;
//sa_flags:int型,指定信号的一些选项,设置了该标记(SA_SIGINFO),就表示信号附带的参数可以被传递到信号处理函数中
//说白了就是你要想让sa.sa_sigaction指定的信号处理程序(函数)生效,你就把sa_flags设定为SA_SIGINFO
} else {
sa.sa_handler = SIG_IGN;
//sa_handler:这个标记SIG_IGN给到sa_handler成员,表示忽略信号的处理程序,否则操作系统的缺省信号处理程序很可能把这个进程杀掉;
//其实sa_handler和sa_sigaction都是一个函数指针用来表示信号处理程序。只不过这两个函数指针他们参数不一样, sa_sigaction带的参数多,信息量大,
//而sa_handler带的参数少,信息量少;如果你想用sa_sigaction,那么你就需要把sa_flags设置为SA_SIGINFO;
} //end if
sigemptyset(&sa.sa_mask);
//比如咱们处理某个信号比如SIGUSR1信号时不希望收到SIGUSR2信号,那咱们就可以用诸如sigaddset(&sa.sa_mask,SIGUSR2);这样的语句针对信号为SIGUSR1时做处理
//这里.sa_mask是个信号集(描述信号的集合),用于表示要阻塞的信号,sigemptyset():把信号集中的所有信号清0,本意就是不准备阻塞任何信号;
//设置信号处理动作(信号处理函数),说白了这里就是让这个信号来了后调用我的处理程序,有个老的同类函数叫signal,不过signal这个函数被认为是不可靠信号语义,不建议使用,大家统一用sigaction
//参数1:要操作的信号
//参数2:主要就是那个信号处理函数以及执行信号处理函数时候要屏蔽的信号等等内容
//参数3:返回以往的对信号的处理方式【跟sigprocmask()函数边的第三个参数是的】,跟参数2同一个类型,我们这里不需要这个东西,所以直接设置为NULL;
if (sigaction(sig->signo, &sa, NULL) == -1) {
ngx_log_error_core(NGX_LOG_EMERG, errno, "sigaction(%s) failed", sig->signame); //显示到日志文件中去的
return -1; //有失败就直接返回
} else {
//ngx_log_error_core(NGX_LOG_EMERG,errno,"sigaction(%s) succed!",sig->signame); //成功不用写日志
ngx_log_stderr(0, "sigaction(%s) succeed!", sig->signame); //直接往屏幕上打印看看 ,不需要时可以去掉
}
} //end for
return 0; //成功
}
//信号处理函数
//siginfo:这个系统定义的结构中包含了信号产生原因的有关信息
static void ngx_signal_handler(int signo, siginfo_t *siginfo, void *ucontext) {
//printf("来信号了\n");
ngx_signal_t *sig; //自定义结构
char *action; //一个字符串,用于记录一个动作字符串以往日志文件中写
for (sig = signals; sig->signo != 0; sig++) //遍历信号数组
{
//找到对应信号,即可处理
if (sig->signo == signo) {
break;
}
} //end for
action = (char *)""; //目前还没有什么动作;
if(ngx_process == NGX_PROCESS_MASTER) //master进程,管理进程,处理的信号一般会比较多
{
//master进程的往这里走
switch (signo) {
case SIGCHLD: //一般子进程退出会收到该信号
ngx_reap = 1;
//标记子进程状态变化,日后master主进程的for(;;)循环中可能会用到这个变量【比如重新产生一个子进程】
break;
//.....其他信号处理以后待增加
default:
break;
} //end switch
} else if(ngx_process == NGX_PROCESS_WORKER) //worker进程,具体干活的进程,处理的信号相对比较少
{
//worker进程的往这里走
//......以后再增加
//....
} else {
//非master非worker进程,先啥也不干
//do nothing
} //end if(ngx_process == NGX_PROCESS_MASTER)
//这里记录一些日志信息
//siginfo这个
if(siginfo && siginfo->si_pid) //si_pid = sending process ID【发送该信号的进程id】
{
ngx_log_error_core(NGX_LOG_NOTICE, 0, "signal %d (%s) received from %P%s", signo, sig->signame, siginfo->si_pid, action);
} else {
//没有发送该信号的进程id,所以不显示发送该信号的进程id
ngx_log_error_core(NGX_LOG_NOTICE, 0, "signal %d (%s) received %s", signo, sig->signame, action);
}
//.......其他需要扩展的将来再处理;
//子进程状态有变化,通常是意外退出【既然官方是在这里处理,我们也学习官方在这里处理】
if (signo == SIGCHLD) {
ngx_process_get_status(); //获取子进程的结束状态
} //end if
return;
}
//获取子进程的结束状态,防止单独kill子进程时子进程变成僵尸进程
static void ngx_process_get_status(void) {
pid_t pid;
int status;
int err;
int one = 0; //抄自官方nginx,应该是标记信号正常处理过一次
//当你杀死一个子进程时,父进程会收到这个SIGCHLD信号。
for ( ;; ) {
//waitpid,有人也用wait,但掌握和使用waitpid即可;这个waitpid说白了获取子进程的终止状态,这样,子进程就不会成为僵尸进程了;
//第一次waitpid返回一个> 0值,表示成功,后边显示 2019/01/14 21:43:38 [alert] 3375: pid = 3377 exited on signal 9【SIGKILL】
//第二次再循环回来,再次调用waitpid会返回一个0(只有waitpid的第三个参数为WNOHANG时waitpid才会返回0),然后这里有return来退出;
//根据资料解释,返回的这个0表示worker子进程并不是立即可用的,waitpid不阻塞,立即返回0.
pid = waitpid(-1, &status, WNOHANG);
//第一个参数为-1,表示等待任何子进程,
//第二个参数:保存子进程的状态信息
//第三个参数:提供额外选项,WNOHANG表示不要阻塞,让这个waitpid()立即返回
if(pid == 0) {
return;
} //end if(pid == 0)
//-------------------------------
//这表示这个waitpid调用有错误,有错误也理解返回出去,我们管不了这么多
if(pid == -1) {
//这里处理代码抄自官方nginx,主要目的是打印一些日志。考虑到这些代码也许比较成熟,所以,就基本保持原样照抄吧;
err = errno;
//调用被某个信号中断
if(err == EINTR) {
continue;
}
//没有子进程
if(err == ECHILD && one) {
return;
}
//没有子进程
if (err == ECHILD)
{
ngx_log_error_core(NGX_LOG_INFO, err, "waitpid() failed!");
return;
}
ngx_log_error_core(NGX_LOG_ALERT, err, "waitpid() failed!");
return;
} //end if(pid == -1)
//-------------------------------
//走到这里,表示 成功【返回进程id】 ,这里根据官方写法,打印一些日志来记录子进程的退出
one = 1; //标记waitpid()返回了正常的返回值
//获取使子进程终止的信号编号
if(WTERMSIG(status)) {
ngx_log_error_core(NGX_LOG_ALERT, 0, "pid = %P exited on signal %d!", pid,WTERMSIG(status)); //获取使子进程终止的信号编号
} else {
ngx_log_error_core(NGX_LOG_NOTICE, 0, "pid = %P exited with code %d!",pid,WEXITSTATUS(status)); //WEXITSTATUS()获取子进程传递给exit或者_exit参数的低八位
}
} //end for
return;
}
ngx_signal_handler函数的源码和相关的注释。代码非常简单,有几点说明。
- (1)函数中,通过一个for语句for(sig= signals;sig>signo!=0;sig++)寻找收到的信号。
- (2)针对master进程,在收到SIGCHLD信号(子进程退出,父进程就会收到这个信号)后,会将一个全局标记(全局变量)ngx_reap设置为1。目前本项目中并没有用到该标记,但将来可能会用到,(如果worker子进程运行崩溃或者被杀掉后,master进程就可以通过该标记重新fork出一个worker子进程)。
- (3)真正处理僵尸子进程是通过调用ngx_process_get_status函数并在该函数中调用了系统函数waitpid来进行的。在该函数中还引入了for无限循环的写法,这种写法取自官方Nginx源码(其实调用一次waitpid就可以达到防止worker子进程成为僵尸进程的目的,但出于对官方Nginx源码的信任,相信这种经过长期考验的源代码一定考虑得更周全写得更好,尽量将源码引入本项目中),for无限循环会执行2次,第1次循环执行waitpid时返回结果大于0,所以再次循环;第2次循环执行waitpid时返回结果等于0并直接返回。
通过上面的代码,就实现了子进程一旦死掉(或被杀死),父进程可以通过调用waitpid,防止子进程变成僵尸进程
保存修改后的文件,用make重新编译,输入./nginx命令执行nginx可执行程序。用kill-9杀死一个子进程,不难发现,子进程已经消失不见,不再变成僵尸进程了,说明ngx_process_get_status函数工作正常。


接下来,向日志文件中写一些master进程和worker进程的启动信息,方便将来运营人员观察服务器各进程的启动时间。
ngx_process_cycle.cxx
//和开启子进程相关
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h> //信号相关头文件
#include <errno.h> //errno
#include <unistd.h>
#include "ngx_func.h"
#include "ngx_macro.h"
#include "ngx_c_conf.h"
#include "ngx_global.h"
//函数声明
static void ngx_start_worker_processes(int threadnums);
static int ngx_spawn_process(int threadnums,const char *pprocname);
static void ngx_worker_process_cycle(int inum,const char *pprocname);
static void ngx_worker_process_init(int inum);
//变量声明
static u_char master_process[] = "master process";
//描述:创建worker子进程
void ngx_master_process_cycle() {
sigset_t set; //信号集
sigemptyset(&set); //清空信号集
//下列这些信号在执行本函数期间不希望收到 (保护不希望由信号中断的代码临界区)
//建议fork()子进程时学习这种写法,防止信号的干扰;
sigaddset(&set, SIGCHLD); //子进程状态改变
sigaddset(&set, SIGALRM); //定时器超时
sigaddset(&set, SIGIO); //异步I/O
sigaddset(&set, SIGINT); //终端中断符
sigaddset(&set, SIGHUP); //连接断开
sigaddset(&set, SIGUSR1); //用户定义信号
sigaddset(&set, SIGUSR2); //用户定义信号
sigaddset(&set, SIGWINCH); //终端窗口大小改变
sigaddset(&set, SIGTERM); //终止
sigaddset(&set, SIGQUIT); //终端退出符
//.........可以根据开发的实际需要往其中添加其他要屏蔽的信号......
//设置,此时无法接受的信号;阻塞期间,你发过来的上述信号,多个会被合并为一个,暂存着,等你放开信号屏蔽后才能收到这些信号。。。
if (sigprocmask(SIG_BLOCK, &set, NULL) == -1)
//第一个参数用了SIG_BLOCK表明设置 进程 新的信号屏蔽字 为 “当前信号屏蔽字 和 第二个参数指向的信号集的并集
{
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_master_process_cycle()中sigprocmask()失败!");
}
//即便sigprocmask失败,程序流程 也继续往下走
//首先设置主进程标题---------begin
size_t size;
int i;
size = sizeof(master_process); //注意这里用的是sizeof,所以字符串末尾的\0是被计算进来了的
size += g_argvneedmem; //argv参数长度加进来
if(size < 1000) //长度小于这个,才设置标题
{
char title[1000] = {0};
strcpy(title, (const char *)master_process); //"master process"
strcat(title, " "); //跟一个空格分开一些,清晰 //"master process "
for (i = 0; i < g_os_argc; i++) //"master process ./nginx"
{
strcat(title, g_os_argv[i]);
}//end for
ngx_setproctitle(title); //设置标题
ngx_log_error_core(NGX_LOG_NOTICE,0,"%s %P 启动并开始运行......!",title,ngx_pid); //设置标题时顺便记录下来进程名,进程id等信息到日志
}
//首先设置主进程标题---------end
//从配置文件中读取要创建的worker进程数量
CConfig *p_config = CConfig::GetInstance(); //单例类
//从配置文件中得到要创建的worker进程数量
int workprocess = p_config->GetIntDefault("WorkerProcesses", 1);
ngx_start_worker_processes(workprocess); //这里要创建worker子进程
//创建子进程后,父进程的执行流程会返回到这里,子进程不会走进来
sigemptyset(&set); //信号屏蔽字为空,表示不屏蔽任何信号
//sigaddset(&set, SIGHUP); //-1
//setvbuf(stdout,NULL,_IONBF,0); //这个函数. 直接将printf缓冲区禁止, printf就直接输出了。
for ( ;; ) {
// usleep(100000);
// ngx_log_error_core(0, 0, "haha--这是父进程, pid为 %P", ngx_pid);
//a)根据给定的参数设置新的mask 并阻塞当前进程【因为是个空集,所以不阻塞任何信号】
//b)此时,一旦收到信号,便恢复原先的信号屏蔽【我们原来的mask在上边设置的,阻塞了多达10个信号,从而保证我下边的执行流程不会再次被其他信号截断】
//c)调用该信号对应的信号处理函数
//d)信号处理函数返回后,sigsuspend返回,使程序流程继续往下走
//printf("for进来了!\n"); //发现,如果print不加\n,无法及时显示到屏幕上,是行缓存问题,以往没注意;可参考https://blog.csdn.net/qq_26093511/article/details/53255970
sigsuspend(&set);
//阻塞在这里,等待一个信号,此时进程是挂起的,不占用cpu时间,只有收到信号才会被唤醒(返回);
//此时master进程完全靠信号驱动干活
// printf("执行到sigsuspend()下边来了\n");
// ngx_log_stderr(0, "haha--这是父进程, pid为%P", ngx_pid);
// printf("master进程休息1秒\n");
sleep(1); //休息1秒
//以后扩充.......
}// end for(;;)
return;
}
//描述:根据给定的参数创建指定数量的子进程,因为以后可能要扩展功能,增加参数,所以单独写成一个函数
//threadnums:要创建的子进程数量
static void ngx_start_worker_processes(int threadnums) {
int i;
//master进程在走这个循环,来创建若干个子进程
for (i = 0; i < threadnums; i++) {
ngx_spawn_process(i, "worker process");
} //end for
return;
}
//描述:产生一个子进程
//inum:进程编号【0开始】
//pprocname:子进程名字"worker process"
static int ngx_spawn_process(int inum, const char *pprocname) {
pid_t pid;
pid = fork(); //fork()系统调用产生子进程
switch (pid) //pid判断父子进程,分支处理
{
case -1: //产生子进程失败
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_spawn_process()fork()产生子进程num=%d, procname=\"%s\"失败!", inum, pprocname);
return -1;
case 0: //子进程分支
ngx_parent = ngx_pid; //因为是子进程了,所有原来的pid变成了父pid
ngx_pid = getpid(); //重新获取pid,即本子进程的pid
ngx_worker_process_cycle(inum, pprocname);
//希望所有worker子进程,在这个函数里不断循环着不出来,也就是说,子进程流程不往下边走;
break;
default: //这个应该是父进程分支,直接break;,流程往switch之后走
break;
}//end switch
//父进程分支会走到这里,子进程流程不往下边走-------------------------
//若有需要,以后再扩展增加其他代码......
return pid;
}
//描述:worker子进程的功能函数,每个woker子进程,就在这里循环着了(无限循环【处理网络事件和定时器事件以对外提供web服务】)
// 子进程分叉才会走到这里
//inum:进程编号【0开始】
static void ngx_worker_process_cycle(int inum, const char *pprocname) {
//重新为子进程设置进程名,不要与父进程重复------
ngx_worker_process_init(inum);
ngx_setproctitle(pprocname); //设置标题
ngx_log_error_core(NGX_LOG_NOTICE, 0, "%s %P 启动并开始运行......!", pprocname, ngx_pid); //设置标题时顺便记录下来进程名,进程id等信息到日志
//暂时先放个死循环,我们在这个循环里一直不出来
// setvbuf(stdout, NULL, _IONBF, 0); //这个函数. 直接将printf缓冲区禁止, printf就直接输出了。
for(;;) {
//先sleep一下 以后扩充.......
// printf("worker进程休息1秒");
// fflush(stdout); //刷新标准输出缓冲区,把输出缓冲区里的东西打印到标准输出设备上,则printf里的东西会立即输出;
sleep(1); //休息1秒
//usleep(100000);
// ngx_log_error_core(0, 0, "good--这是子进程, 编号为%d, pid为%P!", inum, ngx_pid);
//printf("1212");
//if(inum == 1)
//{
//ngx_log_stderr(0,"good--这是子进程,编号为%d,pid为%P",inum,ngx_pid);
//printf("good--这是子进程,编号为%d,pid为%d\r\n",inum,ngx_pid);
//ngx_log_error_core(0,0,"good--这是子进程,编号为%d",inum,ngx_pid);
//printf("我的测试哈inum=%d",inum++);
//fflush(stdout);
//}
// ngx_log_stderr(0, "good--这是子进程, 编号为%d, pid为%P", inum, ngx_pid);
//ngx_log_error_core(0,0,"good--这是子进程,编号为%d,pid为%P",inum,ngx_pid);
} //end for(;;)
return;
}
//描述:子进程创建时调用本函数进行一些初始化工作
static void ngx_worker_process_init(int inum) {
sigset_t set; //信号集
sigemptyset(&set); //清空信号集
if (sigprocmask(SIG_SETMASK, &set, NULL) == -1) //原来是屏蔽那10个信号【防止fork()期间收到信号导致混乱】,现在不再屏蔽任何信号【接收任何信号】
{
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_worker_process_init()中sigprocmask()失败!");
}
//....将来再扩充代码
//....
return;
}



网络通信实战
客户端和服务端
1. 解析一个浏览器访问网页的过程
访问网络用的计算机或手机,统称为硬件设备。要访问淘宝网,就要在这些硬件设备上打开一个浏览器。浏览器是什么呢?就是一个可执行程序,运行时就是一个进程,与程序员自己开发的其他普通可执行程序没什么区别。
在客户端浏览器中输人www.taobao.com并按回车键,浏览器就开始工作了。浏览器实际上是向淘宝网(服务器)发送了一个数据包,大概意思是告诉淘宝网:“我需要访问你,请把你的网页内容传递给我。”淘宝网服务器收到这个请求之后,就把某个约定好的网页内容传递到客户端浏览器上。因为根据规定,互联网上的数据包大小最大为1.5KB左右,而淘宝网页面上内容如此之多,可能有成百上千个1.5KB,所以,淘宝网就向客户端的浏览器发送成百上千个数据包。在收取数据包的过程中,浏览器也要不断地发送一些回应包告诉淘宝网服务器:“我收到了一些数据包,请继续发送给我下面的数据包。”因为淘宝网服务器也不能一股脑地把所有数据包都塞给浏览器,以免浏览器处理不过来。因为浏览器收到数据包也需要处理,如解析、不断显示等。这就像喂孩子吃饭一样,这里的孩子就是浏览器,喂饭的家长就是淘宝网服务器。孩子饿了,家长要喂孩子吃饭,但不能不停地喂,那会把孩子噎死的,要喂一口观察一下孩子的反应,看孩子吃完了还要吃,再喂下一口。
淘宝网服务器给浏览器返回数据包,浏览器收到后会给淘宝网服务器回应一个数据包,然后淘宝网服务器才会继续给浏览器返回剩余的数据包,有来有往,有发送,有回应
最终,数据传递完毕之后,双方发送一些特殊标志的数据包,来标识所有数据全部传送完毕,本次浏览器和淘宝网服务器之间的数据通信就结束了
2.客户端服务器角色规律总结
- (1)数据通信总在两端(双方)之间进行,其中一端称为客户端,另外一端称为服务器端。那么谁是客户端,谁是服务器端呢?
- (2)数据通信的双方,总有一方先发起第1个数据包,发起第1个数据包的一方称为客户端;被动收到第1个数据包的一方就称为服务器端。图中浏览器就是客户端,淘宝网服务器就是服务器端。
- (3)客户端主动发起连接,发出数据请求,建立和服务器端的数据通信;服务器被动接收客户端发起的连接请求,并和客户端建立连接。然后,数据就可以从客户端发送到服务器,也可以从服务器发送到客户端,可以双向流动了,这叫双工(彼此都可以发送数据包给对方)。
- (4)服务器与客户端的关系,是一对多的关系。一个服务器,可以同时服务成千上万个客户端,利用后续谈到的epoll编程技术,一台服务器甚至可以同时为数万数十万客户端服务。epoll技术就是这样强大,所以,核心服务器编程技术就是epoll技术,只有这种技术,才支持单台服务器同时为这么多的客户端服务。epoll编程技术也是所有网络通信编程技术中最不容易写、挑战性最大的
既然服务器被动接收连接,那么客户端必须能找到服务器在哪里。
现实生活中,给一个人写信,必须在信封上提供2个最重要的信息,一个是收信人的地址,另一个是收信人的姓名,这2个信息少了哪一个,收信人都收不到信。回到网络通信,同理,浏览器要访问淘宝网服务器,也要知道淘宝网服务器的地址和姓名,只不过在网络术语中,淘宝网服务器的地址(收信人地址)被称为IP地址(可以理解成是个字符串,如192.168.1.100 这种用3个点分开的4个数字就是一个IP地址),淘宝网服务器的姓名称为端口号或端口(端口号是一个无符号数字,取值范围为0~65535)。
所以,只要知道了淘宝网服务器的IP地址,以及淘宝网服务器的端口号,客户端就可以和淘宝网服务器通信了。
在浏览器中输人www.taobao.com并按回车键,浏览器内部有一些工作机制,能把www.taobao.com(域名)转换成IP地址,这样就有了淘宝网服务器的IP地址,然后浏览器默认连接的是对方的80端口,这样就等于知道了淘宝网服务器的端口。有了IP地址,有了端口,就能够跟淘宝网服务器通信(能访问淘宝网页面)了。
淘宝网服务器也是个程序,淘宝网服务器运行的实际上就是官方Nginx程序。官方Nginx程序在启动过程中会调用listen函数监听80端口,这样,当浏览器把数据发送到淘宝网服务器的80端口时,Nginx程序(实际是Nginx中的worker进程)就能收到数据包。
为什么必须有“端口”这个概念呢?一个服务器上(如淘宝网服务器),可以运行多个(如3个)官方Nginx程序,其中一个在监听80端口,一个在监听90端口,一个在监听100端口。客户端用浏览器向淘宝网服务器发送数据时,如果向它的80端口发送数据,监听80端口的Nginx程序就能收到数据,而监听90和100端口的Nginx程序都收不到数据;如果向淘宝网服务器的90端口发送数据,只有监听90端口的Nginx程序能够收到数据,而监听80和100端口的Nginx程序都收不到数据;如果向淘宝网服务器的100端口发送数据,只有监听100端口的Nginx程序能够收到数据,而监听80和90端口的Nginx程序都收不到数据。这就是端口号的作用(区别不同的服务端应用程序)。给人起名字最主要的作用是用于区别不同的人。当然有人说:我的班级就有2个叫张三的。那也要有所区别,如一个叫大张三,另一个叫小张三。计算机上不允许2个不同的应用程序都去监听同一个端口号,就好像一个班级里只有一个人能叫张三,如果再来一个叫张三的人,必须改名,这是强制规定。

浏览器与淘宝网服务器之间的通信是双工的,即两端都可以收发数据,数据是双向流动的。很容易联想到,客户端计算机肯定也要有一个IP地址和一个端口号,这样数据才能双向流动。换句话说,只要有网络通信,通信的两端每一端都要有一个IP地址和一个端口号。
但是这里要注意,因为服务器是被动等待连接的,所以服务器的IP地址和端口必须是所有人都知道的(周知),只有知道了服务器的这两个信息,才能和服务器联系上。
客户端用浏览器(也适用于所有客户端通信程序)访问淘宝网服务器时,客户端程序的IP地址和端口则不需要专门指定,客户端程序本身就知道自己所在的计算机的IP地址,操作系统也会自动为客户端分配一个临时的端口号,让客户端与淘宝网服务器通信。换句话说,在编写网络通信程序的客户端程序时,只需要指定要访问的淘宝网服务器的IP地址和淘宝网服务器的端口号,就能够和淘宝网服务器通信。
网络模型
OSI 7层网络模型

TCP/IP 4层模型

TCP/IP的4层模型就比OSI7层模型简单不少。请注意,OSI模型的1、2层(物理层、数据链路层)合并成了TCP/IP的链路层,网络层不变,传输层不变,OSI模型的5、6、7层(会话层、表示层、应用层)合并成了TCP/IP的应用层。
TCP/IP的4层模型可以说得具体一点,细化一下。刚才说过,TCP/IP是一组协议,这四层模型,每1层都对应一些协议

显示了TCP/IP4层模型对应的协议。最上方就是本项目运行后的进程(用户进程),下面有TCP和UDP,往下有IP等协议,再往下有以太网帧,最后是网卡网线,表示数据包通过网卡和网线(无线也算网线)发送出去。
TCP和IP这2个协议需要优先和重点理解 。另外图中有很多箭头,这些箭头表示数据包的一些包装规则和行走路线,不必在意,但要重点关注比较粗的线所代表的路径,本项目中网络通信数据包要走的流程和路线正是粗线标记的路线——也就是从用户进程,遵循TCP,遵循IP,用以太网网帧(包装),最终通过物理介质(网卡和网线)把数据包发送到网络上。
3.TCP/IP的解释和比喻
这里以日常生活中的人出门上街为例,把人看成要发送出去的数据包,把外面的街道看成网络。所以,人出门上街,就等于把数据包发送到互联网上。
人不能光着身子上街,那样有伤风化,违反了人类社会的规则(人类社会也有一些约定俗成的规则,就像互联网世界也有协议)。
那么,人要上街怎么办,要穿点什么,怎么穿呢?不能直接套外衣和外裤就上街,要先穿内衣内裤(相当于TCP),再套上衬衣衬裤(相当于IP),然后套外衣外裤(相当于以太网帧),就可以出门了。
要发送一个数据包,数据包里包含3个字母——abc。不能直接把3个字母扔到网络上,就像人不能光着身子上街一样,这违反TCP/IP。那怎么办呢?先给这3个字母前面加一个TCP头(这就是给abc这3个字母穿了内衣内裤)。现在能不能出门上街?不能,还得穿衬衣衬裤,所以,给abc3个字母前面再加IP头。现在能不能出门上街?不能,还得穿个外衣外裤,所以,给这abc3个字母前面再加以太网帧头,后面加以太网帧尾。加了这3个头1个尾之后,就认为这个数据包符合了TCP/IP的要求,就能被发送到网上了(就像人穿好了衣服,可以出门上街了)

最简单的客户端和服务器端程序实现代码
《UNIX网络编程卷1》里,有众多演示用的小程序(客户端程序和服务器端程序都有),可以参考这本书进一步学习。
请留意一个简单的能够进行TCP/IP通信的客户端程序和服务器程序都要调用哪些主要的API函数,要理解和记忆对这些API函数的调用,面试时可能会用到,对后续编写本项目的网络部分代码也有实际帮助。
1.套接字socket概念
套接字就是一个数字,调用socket函数时,就能够生成(返回)这样一个数字。该数字具有唯一性,操作系统保证,该数字一旦被某个程序调用socket函数返回,就一直给这个程序用,直到该程序调用close函数关闭对该数字的调用,该数字才被系统回收(回收后如果该程序或其他程序又调用了socket函数,该数字可以给该程序或者其他程序复用)。只要该数字没有被系统回收,不管哪个程序调用’socket函数,都不可能返回一个和该数字一样的数字,这就是唯一性。
这里也可以把socket看成一个文件描述符。既然是文件描述符,创建之后就可以用这个socket来收发数据:调用send函数并把socket当作参数,就把数据发送到了对端;调用recv并把socket当作参数,就能够从对端接收数据。
2.一个简单的服务器端通信程序范例
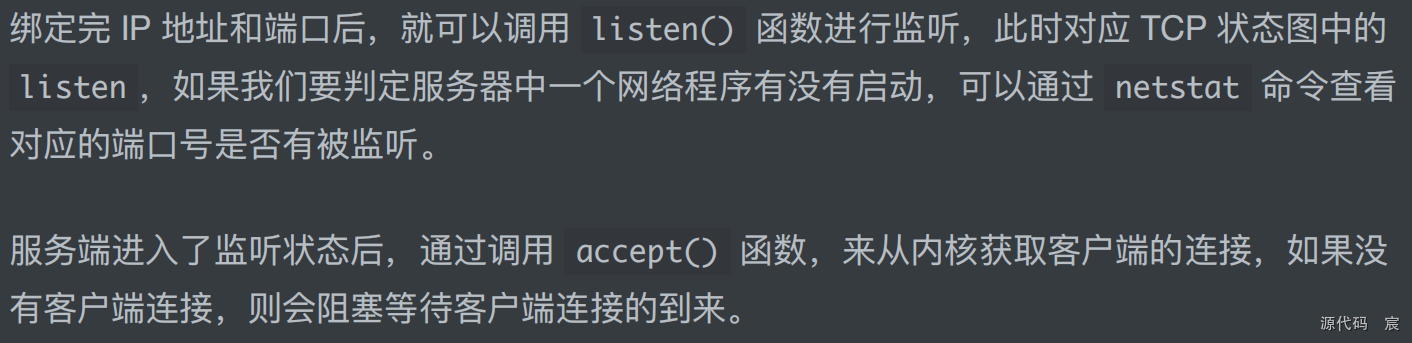
API调用(如客户端调用的socket、connect,以及服务器端调用的socket、bind、listen、accept)的顺序和写法都比较固定。

struct sockaddr_in 结构体
struct sockaddr_in {
short int sin_family; // 地址族(例如 AF_INET 表示 IPv4)
unsigned short int sin_port; // 端口号(需要通过 htons() 转换为网络字节顺序)
struct in_addr sin_addr; // IP地址(需要通过适当的转换函数转换为网络字节顺序)
unsigned char sin_zero[8]; // 填充字段,使结构体大小与 struct sockaddr 保持一致
};
htonl(INADDR_ANY)

htonl和htons的区别

server.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
//本服务器要监听的端口号,一般1024以下的端口很多都是属于周知端口,所以我们一般采用1024之后的数字做端口号
#define SERV_PORT 9000
int main(int argc, char *const *argv) {
//服务器的socket套接字【文件描述符】
//创建服务器的socket
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
//服务器的地址结构体
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
//绑定我们自定义的端口号,客户端程序和我们服务器程序通讯时,就要往这个端口连接和传送数据
// 端口号使用htons函数转换为网络字节序(大端字节序)
serv_addr.sin_port = htons(SERV_PORT);
// IP地址设置为INADDR_ANY表示监听所有本地IP地址。
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));//绑定服务器地址结构体
//参数2表示服务器可以积压的未处理完的连入请求总个数,客户端来一个未连入的请求,请求数+1,连入请求完成,c/s之间进入正常通讯后,请求数-1
listen(listenfd, 32);
int connfd;
const char *pcontent = "I sent sth to client!"; //指向常量字符串区的指针
for(;;) {
//卡在这里,等客户单连接,客户端连入后,该函数走下去【注意这里返回的是一个新的socket——connfd,后续本服务器就用connfd和客户端之间收发数据,而原有的lisenfd依旧用于继续监听其他连接】
connfd = accept(listenfd, (struct sockaddr*)NULL, NULL);
//发送数据包给客户端
write(connfd, pcontent, strlen(pcontent)); //注意第一个参数是accept返回的connfd套接字
//只给客户端发送一个信息,然后直接关闭套接字连接;
close(connfd);
} //end for
close(listenfd); //实际本简单范例走不到这里,这句暂时看起来没啥用
return 0;
}
- (1)核心代码位于main(主函数)中。
- (2)调用socket函数来创建一个socket(数字/文件描述符)。
- (3)定义监听的端口(SERV_PORT,被定义为9000端口)。
- (4)调用bind函数将端口、IP地址与socket绑到一起,让这三者产生关联关系。
- (5)调用listen函数开始监听这个socket(等同于监听SERV_PORT端口)。此时,任何往SERV_PORT端口发送的数据,这个服务器程序都将收到。
- (6)用一个for无限循环一直循环,调用accept函数等待客户端连入。程序执行流程会卡在accept函数调用这里等待客户端连入。
- (7)当有客户端连入时,accept函数会返回,程序执行流程会往下走。注意这里accept 函数返回了一个新socket,这个新socket就能用来与连入的客户端通信(原来的socket继续在那里监听其他即将连人的客户端)。
- (8)通过write函数向accept函数返回的socket上写内容,就等价于给真正的客户端发送数据。
- (9)服务器端调用close主动关闭与该客户端的连接。然后开始新一轮的for无限循环(服务器端又卡到accept这里等待客户端的连入)
总结一下服务器端做的事情:服务器发现一个客户端连入后,给该客户端发送一个字符串“I sent sth to client!”,然后关闭该客户端到本服务器的连接
3.IP地址浅谈
我们知道了192.168.1.100这种形式的写法表示一个IP 地址。如果要访问淘宝网服务器,淘宝网服务器必须有个固定的IP地址,我们才能找到它。所以网络上的IP地址,可以理解成对应于现实社会中的居住地址。
确切地说,常见的形如192.168.1.100的地址,称为IPV4地址,也就是第4个版本的IP地址格式。该版本有一些限制,如每个用点分开的数字都不能超过255。在互联网上,每一个提供对外服务的服务器(如淘宝网服务器)都需要有一个独立且不重复的IP地址,所以IPv4这种地址快被用光了。于是就发展出了新的IP地址版本——第6版(中间跳过了第5 版),称为IPv6。IPv6地址非常复杂,估计在地球毁灭之前都不会被用光。可以简单了解这种地址的表示方法,但不用详细研究。

4.一个简单的客户端通信程序范例
- (1)核心代码位于main主函数中。
- (2)调用socket函数来创建一个socket(数字/文件描述符)。
- (3)调用inet_pton设定要连接的服务器的IP地址和端口号。
- (4)调用connect来真正连接服务器端程序,此时,卡在accept函数的服务器端程序的执行流程就会从accept函数返回(服务器端向客户端发送一个字符串)。
- (5)客户端调用read(卡在read函数这里等待)来接收服务器端发送过来的内容。客户端第一次调用read,收到了服务器端发送过来的字符串,但循环一次(客户端这里是while循环)再次调用read时,因为服务端调用了close函数,导致客户端的read函数返回一个小于或等于0的值(表示服务器端关闭了对应的socket连接),这会使客户端跳出while循环,程序执行流程跳到了while后面。
- (6)调用close关闭socket,输出信息“程序执行完毕,退出!\n”。
- (7)整个客户端程序执行完毕。
注意:客户端和服务器之间建立连接时,双方都要有IP地址和端口号,但连接一且建立,双方的通信(双工的收发)只用对应的socket(套接字)即可。
client.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
#define SERV_PORT 9000 //要连接到的服务器端口,服务器必须在这个端口上listen着
int main(int argc, char *const *argv) {
//这些演示代码的写法都是固定套路,一般都这么写
//创建客户端的socket
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置要连接到的服务器的信息
//选择协议族为IPV4
serv_addr.sin_family = AF_INET;
//连接到的服务器端口,服务器监听这个地址
serv_addr.sin_port = htons(SERV_PORT);
//这里为了方便演示,要连接的服务器地址固定写
//IP地址转换函数,把第二个参数对应的ip地址转换第三个参数里边去,固定写法
if(inet_pton(AF_INET, "10.0.20.6", &serv_addr.sin_addr) <= 0) {
printf("调用inet_pton()失败,退出!\n");
exit(1);
}
//连接到服务器
if(connect(sockfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) < 0) {
printf("调用connect()失败,退出!\n");
exit(1);
}
int n;
char recvline[1000 + 1];
//仅供演示,非商用,所以不检查收到的宽度,实际商业代码,不可以这么写
while(( n = read(sockfd, recvline, 1000)) > 0) {
//实际商业代码要判断是否收取完毕等等,所以这个代码只有学习价值,并无商业价值
recvline[n] = 0;
printf("收到的内容为:%s\n", recvline);
}
close(sockfd); //关闭套接字
printf("程序执行完毕,退出!\n");
return 0;
}


inet_pton函数

TCP和UDP的区别
传输层有2种协议,分别是TCP和UDP。TCP 是最常用的协议,UDP次之,但也比较常用。
(1)TCP(Transmission Control Protocol),又称传输控制协议。(2)UDP(User Datagram Protocol),又称用户数据报协议。
只要在调用socket函数时指定不同的参数,就等于指定了使用TCP还是UDP来传输数据。当然用这2个不同的协议写通信程序的代码也不同,但是现在不关心细节,只关心TCP和UDP这2种协议的区别。
前面把TCP比喻成内衣内裤,而UDP和TCP同属于传输层,因此UDP也可以比喻成内衣内裤。
(1)TCP这种内衣内裤是大品牌,售后服务质量好,晾晒时如果丢失,厂家会派人帮忙寻找,实在找不到,厂家也只能遗憾地通知客户:不好意思没找到。
(2)UDP这种内衣内裤是小品牌,没什么售后服务,晾晒时如果丢失,不好意思,和生”产厂家没啥关系。
总结一下
- (1)TCP是一种可靠的、面向连接的协议。采用TCP发送数据包如果数据在网络上传输丢失,发送方操作系统底层能感知到并重新发送丢失的数据包,这些事情不用程序员操心。如果再丢失,操作系统底层再重新发送(包重传机制)。如此反复尝试几次,实在发送不成功,操作系统会通知程序员(应用程序):对不起,数据包实在发送不出去。
- (2)UDP是一种不可靠的、无连接的协议。发送出去一个数据包,对方收没收到,谁都不得而知,除非约定对方收到数据包时要发送回应包。发送方操作系统也不可能替程序员重新发送该数据包。
TCP和UDP各有优缺点
- (1)TCP是可靠协议,需要耗费更多系统资源以确保数据传输的可靠性。优点是只要连接不断线(如果断线会收到对方断线通知),传输给对方的数据一定是正确的(哪怕发送了100G的数据,也1字节都不会有差错)发送方和接收方操作系统共同协作,保证数据包无差错,不丢失,不重复,按顺序到达目的地。
- (2)UDP是不可靠协议,发送数据的速度可能更快,因为它不需要确保数据的可靠性,不需要接收方回应,所以发送效率高,但是接收方接收到的数据顺序可能与发送方发送的数据顺序并不一样,如先发送abc,再发送def,接收方有可能先收到dei,再收到abc。另外UDP不保证数据传输的可靠性,如发送abc和def,对方很可能只收到def,而abc丢失了(TCP绝不会出现这种情况)。网络繁忙时,利用UDP发送的数据包丢包的概率更高。
TCP和UDP各自的用途
- (1)TCP适用于文件传输、收发邮件等需要准确率高、但效率可以相对较差的场合。与UDP相比,TCP应用范围更广。
- (2)UDP适用于聊天软件(如QQ,当然QQ里面也用了部分TCP),这种网络聊天信息量巨大,服务器压力相当沉重,所以需要采用效率更高、对资源消耗更低的UDP。当然,QQ内部也采用很多算法和优化机制来弥补UDP先天的不足,如丢包问题(在开发层面,也就是应用层编写程序代码,实现对UDP先天不足的弥补)
其他各种TCP和UDP的应用场合还有很多。随着硬件的发展,UDP的稳定性不断增强,丢包率不断下降,预计未来使用UDP的场合会越来越多。
TCP连接的三次握手
只有TCP有三次握手,UDP没有,UDP是不可靠的、无连接的协议,不存在三次握手来建立连接的问题,UDP数据包是直接发出去,不用建立所谓的连接
1.最大传输单元MTU
MTU(Maximum Transfer Unit,最大传输单元),可以理解为最大传输单元就是每个数据包所能包含的最大字节数,该值约为1.5KB。因为一个数据包中还包含TCP头、IP头等内容,所以,每个数据包中,真正能够容纳的有效数据内容可能无法达到1.5KB,应该在1.46KB左右。
要发送100KB数据会怎样呢?当把这100KB数据发送出去时,操作系统会把100KB数据拆成若干个数据包(这叫分片),每个数据包大小约为1.5KB(大概会被拆成68个数据包),然后发出去,对端的操作系统收到后再重组这些数据包。拆包、重组的细节不用理会,这68个数据包发到网络上后,中间可能要经过各种路由器、交换机等网络设备,68个数据包走的路径也可能不一样,并且因为一些硬件差异,这些数据包可能会被路由器、交换机等再次拆分。上面这些描述,只需要知道有这回事即可,不用了解其中的细节。总之,TCP最终保证了收发数据的顺序性以及可靠性。
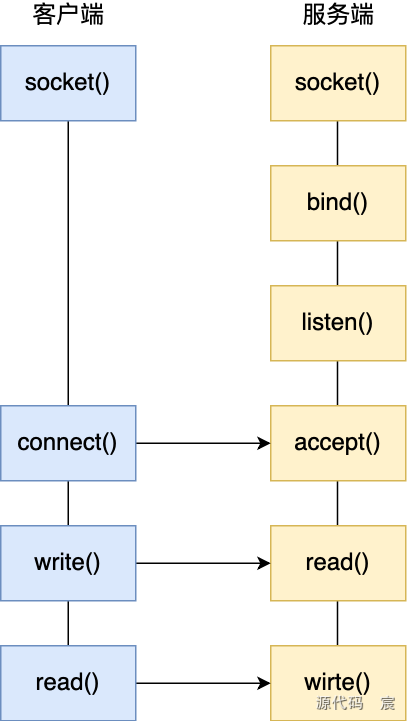
2.TCP包头结构
每个要发送到网络上去的数据包,操作系统都会为其套三头一尾(1 个TCP头、1个IP头、1个以太网帧头和1个以太网帧尾)。这里主要研究TCP头
TCP头,实际就是一个结构,C++中用struct定义结构,结构中有各种成员

- (1)TCP头中有很多内容,值得注意的是源端口号和目标端口号都在里面。
- (2)注意一些标志位(URG、ACK、PSH、RST、SYN和FIN),每个标志位都像个开关,处于开启或关闭状态。重点注意SYN和ACK这2个标志位,三次握手的时候会发现这2个标志位是开启的。
- (3)TCP头部结构之后,紧邻的就是程序员要发送的数据。但是,如果一个数据包中没有要发送的数据(如该数据包只需发送TCP头部的一些标志位信息),就属于没有包体、只有包头的数据包,一般用于控制信息的传输,不用于数据传输。总之,并不是所有TCP数据包里都会包含具体的要传输的数据,也可能只发送控制信息。
3. TCP数据包收发之前的准备工作
在Linux操作系统上,一切皆文件,所以TCP数据包的收发,也可以看成是文件的收发。TCP数据包的收发是双工的,也就是说,数据通信的两端,每一端都可以收数据,也都可以发数据。可以总结出TCP数据包收发的三大步骤:
- ①建立TCP连接(connect);
- ②多次反复的数据收发(read/write);
- ③关闭TCP连接(close)。
4.TCP三次握手建立连接的过程
当客户端程序调用connect函数连接服务器端程序时,TCP的三次握手就发生了

可以注意到三次握手就是发送3个数据包而已,而且这3个数据包都是没有包体的数据包。
- (1)第1次握手。客户端主动向服务器发送了一个SYN标志位置位的TCP数据包。SYN被置位,就表示要发起一个TCP 连接。
- (2)第2次握手。服务器端收到SYN 标志位置位的包后,向客户端返回一个SYN 和ACK标志位都置位的TCP数据包。
- (3)第3次握手:客户端收到服务器发送回来的数据包之后,再次发送ACK标志位置位的数据包,服务器端收到该数据包后,客户端和服务器端就正式建立TCP连接后续双方就可以进行数据的收发了。
5.为什么 TCP握手是3次握手而不是2次

如果没有第3次握手,就存在一个问题,你说你是张三你就是张三?如果第1次握手,客户端伪造一个IP地址(这个IP地址可能并不真实存在),发送给服务器一个SYN标志位置位的数据包,那么服务器会返回SYN和ACK标志位都置位的数据包给客户端,并认为这个连接已经建立了,而实际上客户端这个地址根本就不存在,更不可能建立连接。那这个服务器就白白浪费了一个连接。如果伪造大量的SYN标志位置位的数据包不断给服务器发送连接请求,服务器端的资源就会大量消耗甚至枯竭,正常的连接请求可能就连不上服务器,这就是人们常说的拒绝服务攻击了。
所以,三次握手的第3次不能省,服务器端只有收到了客户端发来的第3次握手,才认为这个TCP连接建立起来了。
第2次握手时服务器会发送给客户端一个序列号,只有客户端真实存在,并将从服务器端收到的序列号通过第3次握手正确地返回服务器时,服务器才认为TCP连接真正建立起来了,如果客户端是伪造的IP地址,客户端肯定收不到服务器在第2次握手时发送的序列号信息,从而无法正确返回给服务器端第3次握手包所需的序列号。所以,这种3次握手的方式,能够确保客户端真实存在,杜绝用伪造的客户端IP地址成功连接服务器的可能性。
telnet工具使用
从事网络通信服务器开发的,都需要了解telnet工具的使用。这是一款以命令行方式运行的客户端TCP通信工具,是一个客户端工具程序,可以连接服务器端,向服务器端发送数据,也可以接收服务器端发送过来的数据。
telnet的功能类似于client.c程序,telnet工具能够非常方便地测试服务端的某个TCP端口是否通畅(是否允许被连入)、数据能否正常收发等,是一个非常常用、实用和重要的工具。

在cmd命令行提示符(黑窗口)下,输人telnet并按回车键,就可以执行了。输入quit并按回车键退出telnet。
telnet工具以命令行的方式使用最方便,命令行格式如下:

先在SecureCRT终端窗口运行编译出的服务器端程序server。在Windows计算机上的cmd命令行提示符下,输入如下命令并按回车键:
C:\Users\lenovo>telnet 203.195.208.44 9000

从结果可以看到,telnet端(相当于客户端程序)收到了服务器发送过来的信息,然后就断开了连接,信息看起来不太醒目。修改服务器程序代码,让服务器发送信息后等待客户端发送过来一个信息,然后给客户端发送一个反馈信息后再关闭(本程序代码只用于演示,不用于实际商业目的)。
server.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
//本服务器要监听的端口号,一般1024以下的端口很多都是属于周知端口,所以我们一般采用1024之后的数字做端口号
#define SERV_PORT 9000
int main(int argc, char *const *argv) {
//服务器的socket套接字【文件描述符】
//创建服务器的socket
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
//服务器的地址结构体
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
//绑定我们自定义的端口号,客户端程序和我们服务器程序通讯时,就要往这个端口连接和传送数据
// 端口号使用htons函数转换为网络字节序(大端字节序)
serv_addr.sin_port = htons(SERV_PORT);
// IP地址设置为INADDR_ANY表示监听所有本地IP地址。
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
int result = bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));//绑定服务器地址结构体
//参数2表示服务器可以积压的未处理完的连入请求总个数,客户端来一个未连入的请求,请求数+1,连入请求完成,c/s之间进入正常通讯后,请求数-1
result = listen(listenfd, 32);
int connfd;
const char *pcontent = "I sent sth to client!"; //指向常量字符串区的指针
for(;;) {
//卡在这里,等客户单连接,客户端连入后,该函数走下去【注意这里返回的是一个新的socket——connfd,后续本服务器就用connfd和客户端之间收发数据,而原有的lisenfd依旧用于继续监听其他连接】
connfd = accept(listenfd, (struct sockaddr*)NULL, NULL);
//发送数据包给客户端
//write(connfd,pcontent,strlen(pcontent)); //注意第一个参数是accept返回的connfd套接字
//以下代码非常不完善,纯粹用于演示目的,完全不可以商用
char recvline[1000 + 1];
read(connfd, recvline, 1000); //卡在这,从客户端收点东西
//往客户端发送点东西
write(connfd, pcontent, strlen(pcontent));
//只给客户端发送一个信息,然后直接关闭套接字连接;
close(connfd);
} //end for
close(listenfd); //实际本简单范例走不到这里,这句暂时看起来没啥用
return 0;
}
输入cls可以清空cmd上面的内容
在Windows计算机的cmd命令行提示符下,输人如下命令并按回车键:
C:\Users\lenovo>telnet 203.195.208.44 9000
光标出现在左上角,表示telnet已经连通了服务器端。从键盘输入一个字符,不用按回车键盘,该字符就会被自动发送到服务器端,服务器端收到来自客户端的内容后,立即返回字符串“I sent sth to client!”并关闭与客户端的socket连接。
如果在SecureCRT中使用telnet工具,结果又将不同。试一下,重新打开一个SecureCRT窗口,输入:
ubuntu@VM-20-6-ubuntu:~/myProj$ telnet 203.195.208.44 9000

有Connected字样,表示成功连入了203.195.208.44服务器的9000端口。此时可以从键盘输入字符,但是,必须按回车键后,输入的字符才会被发送到服务器端。此时服务器端返回字符串“I sent sth to client!”并关闭与客户端的socket连接
以后可以用这个工具测试服务器端是否能连通,服务器端口是否开放等,这非常方便。
read函数

read 和 write 的区别

Wireshark监视数据包
确认一下,目前Linux计算机(乌班图Linux)上的server进程仍处于正常运行状态。在Windows计算机的cmd命令行提示符下,输入如下命令并按回车键:
C:\Users\lenovo>telnet 203.195.208.44 9000
连接成功后,输入1个字母,会收到服务器端发送回来的1个字符串,然后socket连接会被服务器程序主动切断。
此时Wireshark窗口会显示收到了10个数据包,注意其中前3个数据包的方向(Source列和Destination列),以及在Info列中的标志(分别为[SYN][SYN,ACK][ACK]),这就是TCP建立连接时,通信的双方进行三次握手时涉及的3个相关的数据包。

观察数据包。在Wireshark中单击每个数据包(也可以单击每个数据包内的以太网帧、IP头、TCP头单独查看),可以看到每个数据的TCP头、IP头、以太网帧头(看起来没有以太网帧尾,也许以太网帧尾过时了,已经不需要了。这对本项目不重要,只需要知道以太网帧尾可有可无就够了),有些数据包还带有具体发送的内容(包体)



TCP断开的四次挥手
根据目前的程序代码server.c设定,本次由服务器端主动断开连接(谁主动断开连接,谁先发第1个挥手包)



- (1)第1次挥手,主动断开连接的一方(这里是服务器端),发送FIN和ACK标志位都置位的TCP包给对端(FIN标志位被置位,就表示本方要断开TCP连接)。
- (2)第2次挥手,被动断开连接的一方(这里是客户端)发送ACK标志位置位的TCP 包回应对端。
- (3)第3次挥手,被动断开连接的一方发送FIN标志和ACK标志位都置位的TCP包给对端。
- (4)第4次挥手,主动断开连接的一方发送ACK标志位置位的TCP包回应对端。
TCP状态转换
server.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
//本服务器要监听的端口号,一般1024以下的端口很多都是属于周知端口,所以我们一般采用1024之后的数字做端口号
#define SERV_PORT 9000
int main(int argc, char *const *argv) {
//服务器的socket套接字【文件描述符】
//创建服务器的socket
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
//服务器的地址结构体
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
//绑定我们自定义的端口号,客户端程序和我们服务器程序通讯时,就要往这个端口连接和传送数据
// 端口号使用htons函数转换为网络字节序(大端字节序)
serv_addr.sin_port = htons(SERV_PORT);
// IP地址设置为INADDR_ANY表示监听所有本地IP地址。
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
//绑定服务器地址结构体
int result = bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("bind返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno, perrorinfo);
close(listenfd);
return -1;
}
//参数2表示服务器可以积压的未处理完的连入请求总个数,客户端来一个未连入的请求,请求数+1,连入请求完成,c/s之间进入正常通讯后,请求数-1
result = listen(listenfd, 32);
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("listen返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno,perrorinfo);
close(listenfd);
return -1;
}
int connfd;
const char *pcontent = "I sent sth to client!"; //指向常量字符串区的指针
for(;;) {
//卡在这里,等客户单连接,客户端连入后,该函数走下去【注意这里返回的是一个新的socket——connfd,后续本服务器就用connfd和客户端之间收发数据,而原有的lisenfd依旧用于继续监听其他连接】
connfd = accept(listenfd, (struct sockaddr*)NULL, NULL);
//发送数据包给客户端
//write(connfd,pcontent,strlen(pcontent)); //注意第一个参数是accept返回的connfd套接字
//以下代码非常不完善,纯粹用于演示目的,完全不可以商用
char recvline[1000 + 1];
read(connfd, recvline, 1000); //卡在这,从客户端收点东西
//往客户端发送点东西
write(connfd, pcontent, strlen(pcontent));
//只给客户端发送一个信息,然后直接关闭套接字连接;
close(connfd);
} //end for
close(listenfd); //实际本简单范例走不到这里,这句暂时看起来没啥用
return 0;
}
在SecureCRT终端窗口编译、链接,生成可执行程序并运行

打开一个新的SecureCRT终端窗口,再次运行这个服务器程序。这次运行会得到如下信息:

从结果可以看到,bind失败(也就是绑定失败),错误信息是“地址已经被使用”。也就是说,作为服务器程序,在某个IP地址监听某个端口,等待客户端连接,相同的IP地址(源码中的INADDR_ANY)和相同的端口(源码中的SERV_PORT),只能被绑定(bind)1次,第2次绑定不上。这个话题在前面已经谈过:一个班级里,只能有1个叫张三的人,不能有2个,不然没法区别这2个人。
目前得到的结论是:相同的IP地址(INADDR_ANY)和相同的端口(SERV_PORT),只能被绑定(bind)1次,第2次绑定(bind)会失败
命令netstat。这是一个重要的命令,用来显示网络相关信息,如显示端口状态等。现在,服务器正在监听9000端口,可以通过netstat命令观察9000端口的状态

ubuntu@VM-20-6-ubuntu:~/myProj$ netstat -anp | grep -E 'State|9000'

Local Address(本地地址)列显示的内容是“0.0.0.0:9000”,其中的“0.0.0.0”代表本机可用的任意地址(因为源码中用的是INADDR_ANY),State(状态)列显示的是LISTEN,表示监听中
服务器上可以有多块网卡,每块网卡可以配置不同的IP地址(甚至1块网卡可以配置多个IP地址),所以,在服务器程序中绑定端口时,可以把端口与某个指定的IP地址绑定。当然,如果程序中使用INADDR_ANY;就表示把端口和所有该计算机的IP地址(不管有几块网卡、几个IP地址)都绑定,这就意味着不管从哪个网卡(IP地址)发来的数据包,只要是发往该端口的,该服务器程序就都能收到,所以,server.c用的就是INADDR_ANY
server.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
//本服务器要监听的端口号,一般1024以下的端口很多都是属于周知端口,所以我们一般采用1024之后的数字做端口号
#define SERV_PORT 9000
int main(int argc, char *const *argv) {
//服务器的socket套接字【文件描述符】
//创建服务器的socket
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
//服务器的地址结构体
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
//绑定我们自定义的端口号,客户端程序和我们服务器程序通讯时,就要往这个端口连接和传送数据
// 端口号使用htons函数转换为网络字节序(大端字节序)
serv_addr.sin_port = htons(SERV_PORT);
// IP地址设置为INADDR_ANY表示监听所有本地IP地址。
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
//绑定服务器地址结构体
int result = bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("bind返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno, perrorinfo);
close(listenfd);
return -1;
}
//参数2表示服务器可以积压的未处理完的连入请求总个数,客户端来一个未连入的请求,请求数+1,连入请求完成,c/s之间进入正常通讯后,请求数-1
result = listen(listenfd, 32);
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("listen返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno,perrorinfo);
close(listenfd);
return -1;
}
int connfd;
const char *pcontent = "I sent sth to client!"; //指向常量字符串区的指针
for(;;) {
//卡在这里,等客户单连接,客户端连入后,该函数走下去【注意这里返回的是一个新的socket——connfd,后续本服务器就用connfd和客户端之间收发数据,而原有的lisenfd依旧用于继续监听其他连接】
connfd = accept(listenfd, (struct sockaddr*)NULL, NULL);
//发送数据包给客户端
//注意第一个参数是accept返回的connfd套接字
write(connfd, pcontent, strlen(pcontent));
printf("本服务器给客户端发送了一串字符~~~~~~~~~~~!\n");
//以下代码非常不完善,纯粹用于演示目的,完全不可以商用
char recvline[1000 + 1];
read(connfd, recvline, 1000); //卡在这,从客户端收点东西
//往客户端发送点东西
// write(connfd, pcontent, strlen(pcontent));
//只给客户端发送一个信息,然后直接关闭套接字连接;
close(connfd);
} //end for
close(listenfd); //实际本简单范例走不到这里,这句暂时看起来没啥用
return 0;
}
额外打开2个SecureCRT终端(现在有了4个SecureCRT终端窗口,1个运行服务器程序,2个运行telnet,1个运行netstat),在1个终端上运行服务器程序server;在另外2个终端上分别执行telnet 203.195.208.44 9000命令;在第4个终端上执行netstat -anp l grep -E 'Statel9000’命令
可以看到,有3条与9000端口相关的结果,其中一条结果状态列(State)显示为LISTEN,表示9000端口一直处于监听状态(客户端可以连接),但是因为刚刚telnet了9000端口2次,就又产生了2条和9000端口相关的结果,但是这2条结果,状态列(State)显示的却是TIME_WAIT。
ubuntu@VM-20-6-ubuntu:~/myProj$ netstat -anp | grep -E 'State|9000'

原来监听的端口一直在监听(LISTEN),来了2个连接(telnet),即多了2个和9000端口的连接,并且这2个连接都已经被服务器程序调用close函数关闭掉,但是依旧产生了2条与9000端口相关的状态为TIME_WAIT的信息,这就是当前观察到的内容。
此时,快速来到服务器程序所在的SecureCRT窗口,按Ctrl+C组合键停止该服务器进程,然后再次执行,发现会执行失败

可以看到绑定(bind)失败。前面演示时,如果没有任何客户端用telnet连接服务器,那么多次按Ctrl+C组合键关闭服务器进程,再重新执行服务器进程,就不会产生9000端口的TIME_WAIT状态;服务器关闭之后,也能正常重启。
现在,因为使用了telnet工具连接服务器端,使服务器端产生了与9000端口相关的TIME_WAIT状态,导致关闭再重启服务器进程时,bind调用失败(错误信息为Address already in use,翻译成中文是“地址已经被使用”)。所以,坏事就坏在用telnet连接了服务端程序,导致9000端口产生了TIME_WAIT状态的条目,从而使再次启动服务器进程时bind失败。
TIME_WAIT到底是什么?这就涉及TCP状态转换
《Unix网络编程卷1》(第3版)的2.6.4节,有一个TCP状态转换图。刚才演示的9000端口本来处于LISTEN状态,客户端连入后是怎样变成TIME_WAIT状态(怎样多出来TIME_WAIT状态连接)的,通过状态转换图。就能找到答案。同时在该书的2.7节,专门介绍了TIME_WAIT状态
TCP为一个连接定义了11种状态(长六边形内就是状态,CLOSED、LISTEN、SYN_RCVD……)。TCP/IP会根据程序的各种行为(如accept、write、read等)自动在这11种状态之间切换。

图最上方为起始点,即无论客户端程序还是服务器程序,最初都处于CLOSED状态。
- (1)对于服务器端程序,调用了listen函数,就进入LISTEN状态。前面使用netstat 时,9000端口就进入了LISTEN状态(图上方标识为1的虚线)。
对于客户端程序,调用connect函数开始和服务器进行3次握手:①图右上位置标识为1的实线;②图左上标识为2的虚线;③图右中位置标识为2的实线。 - (2)观察客户端的3次握手:进入SYN_SENT状态,3次握手结束之后,又进入ESTABLISHED状态,表示这个TCP连接成功建立,可以进行数据收发了。
- (3)再观察服务器端:服务器端端口开始LISTEN后,等待客户端3次握手的第1次握手到来,第1次握手后,服务器会发送SYN、ACK应答,同时TCP连接会进入SYN_RCVD状态(图左上位置标识为2的虚线),并且该连接等待客户端发来的第3次握手。如果此时收到了一个ACK,该连接也进入ESTABLISHED状态(图左中位置标识为3的虚线),表示该TCP连接成功建立,可以进行数据收发了。
值得一提的是,客户端连入后,服务器端为客户端单独产生一个能和服务器通信的socket连接,该连接进入ESTABLISHED状态,而服务器端处于LISTEN(监听)状态的socket依旧处于监听状态(每接到一个连接,服务器就生成一个新的socket连接用于与客户端通信,而最早产生的监听socket一直处于监听状态)。

- (4)现在,服务端程序根据代码write了一些内容给客户端,然后关闭了(TCP断开连接)。前面讲过TCP在断开连接时有个四次挥手,也就是说,谁主动断开,谁会先发一个标志位FIN置位(其实通过Wireshark观察到的是FIN、ACK都置位,不过可以忽略ACK,重点是FIN)的数据包给对方。这里是服务器主动断开,所以服务器发送了一个FIN标志位置位的数据包给客户端(图上方最后4个包就是四次挥手包)。
- (5)观察四次挥手。
①处于ESTABLISHED状态时,要求主动关闭的一方(服务器端)发送FIN包,同时进入FIN_WAIT_1状态并等待对方回应ACK包(图左中下位置标识为4的虚线)。
②被动关闭方(客户端)收到FIN包后发送ACK包,同时进入CLOSE_WAIT状态(图右中下位置标识为3的实线)同时发送一个FIN包给服务器端(即主动关闭方,图右中下位置标识为4的实线)。
被动关闭方理论上应该不断调用read处理数据,当收到FIN包后,read会返回0,此时被动关闭方也应该调用close,立即由刚刚进入的CLOSE_WAIT状态转换成LAST_ACK状态。如果不调用read或不调用close,很可能导致被动关闭方一直处于CLOSE_WAIT状态,无法达到LAST_ACK状态(netstat观察时出现大量CLOSE_WAIT状态连接的程序员是不是忘记调用read或者close了?)。
处于LAST_ACK状态后,等待对方回应ACK包。
- ③主动关闭的一方(服务器端)收到对方的ACK包之后,进入FIN_WAIT_2状态(图左下位置标识为5的虚线)并继续等待对方的FIN包。收到FIN包之后进入TIME_WAIT状态,同时发送一个ACK包给客户端(即被动关闭方,图左下位置标识为6的虚线)。这就是前面看到的使用netstat命令的时候,9000端口的2个连接处于TIME_WAIT状态的原因
- ④被动关闭的一方(客户端)收到对方的ACK包后,从LAST_ACK状态切换回图最上方的CLOSED状态(图右下位置标识为5的实线)。
TIME_WAIT状态
现在主动关闭的一方(服务器端)已经进入TIME_WAIT状态了。如果按照前面的方法再次测试,不难发现,即便服务器进程server已经退出,短时间(1~4min)内用netstat命令依然能看到2个连接在9000端口上处于TIME_WAIT状态
就像服务器程序没退利索一样,残留了一些内容(残留了2个处于TIME_WAIT状态的TCP连接)。残留了这种状态的TCP,服务器端程序重新启动时,绑定9000端口会失败,无法成功启动。

最上方表示客户端和服务器的连接已经建立,正在进行正常的数据收发。然后,服务器发送FIN包关闭连接,客户端回应ACK包,并再次发送FIN包。然后服务器返回一个ACK,双方的连接关闭。从图中可以看到,服务端进入了TIME_WAIT状态,这个状态大概会持续2MSL(最长数据包生命周期,约1~4min数据包在网络上存活有时间限制,超时将被路由器丢弃)。
前面通过Wireshark分析和netstat查看已经知道,主动关闭socket连接的一端(这里是服务器这端)的TCP连接会处于该状态,停留在这个状态的时间有限制,一般为1~4min。
TCP/IP中引人TIME_WAIT状态,并在该状态停留1~4min,有其用意和目的。根据权威资料,将TIME_WAIT状态存在的理由,总结成如下2点:可靠地实现TCP全双工的终止;允许老的重复的TCP数据包在网络中消逝(丢弃)。
- (1)什么叫可靠的实现TCP全双工的终止?怎么体现出“可靠”二字?
如果服务器最后发送的ACK(应答)包因为某种原因丢失了,客户端没有收到,那么客户端一定会向服务器端重新发送第3次挥手的FIN包,处于TIME_WAIT状态的服务器就会向客户端重新发送ACK包。
如果没有TIME_WAIT,那么无论客户有没有收到ACK,服务器都已经发送RST(连接复位)包并关闭连接了,此时客户重新发送FIN,服务器将不会返回ACK,从而使客户端报错(正常是4次挥手结束连接,这种报错并结束连接很不友好)。所以,TIME_WAIT有助于可靠地实现TCP全双工连接的终止。
发送数据给对端时,操作系统需将待发送数据复制到操作系统的缓冲区。对于每一个TCP连接,操作系统都要开辟出一个收发缓冲区用于处理数据的收和发,当关闭一个TCP 连接时,如果发送缓冲区内有数据,操作系统会很优雅地把发送缓冲区内的数据发送完毕,最后再发FIN包表示连接关闭。
总结:FIN是个优雅关闭的标志,表示正常关闭一个TCP连接。
RST 标志
反观RST标志。这不是个善良的标志,出现这个标志的包,一般都是非正常关闭连接,发生了某些异常情况,一般都会导致数据包的丢失(发送缓冲区中的数据无法全部发送)。
刚才已经看到,服务器调用close关闭TCP连接时,操作系统实际向客户端发送的是FIN包(默认行为),但是,如果在代码中用函数setsockopt开启一个SO_LINGER选项,调用close时操作系统实际向客户端发送的就是RST包,此时如果服务器端发送缓冲区有数据,这些数据会被直接丢弃,根本就不会像FIN这么优雅地先把数据发送完。所以,RST包很粗暴,而且,这种关闭TCP连接的方式也不叫四次挥手(四次挥手是正常的TCP连接关闭的步骤,然后主动发起关闭的一端会进入TIME_WAIT状态,而RST的关闭方式是异常关闭,是粗暴关闭,主动发起关闭的一端不会进入TIME_WAIT状态)。
- (2)什么叫允许旧的重复的TCP数据包在网络中消逝(丢弃)?
如果没有TIME_WAIT状态,主动关闭端(服务器端)可以在发送完最后一个ACK包(四次挥手的第4个包),但该包还没有到达对端(客户端)时,接受另外一个新客户端连入服务器建立一个新连接(假设新连接的源端口、目的端口,源IP、目的IP碰巧和旧连接完全一样),服务器端发送的最后一个ACK包有可能恰好被这个新连接收到,导致新连接所在的客户端发生混乱(新连接被搞糊涂了)。
所以服务器端TCP连接的TIME_WAIT状态有存在的必要,并且需要持续一定的时间,这个时间应超过一个数据包(在这里是ACK包)在网络上的生命周期,以确保ACK包消失不见。此后再建立源端口、目的端口,源IP、目的IP和旧连接完全相同的新连接,新连接就不会收到旧连接发送来的ACK包(不光是ACK包,一些迷途的、路由太慢迟到的包都算)而引起混乱。
也就是说,TCP连接关闭后,主动关闭的一方保持TIME_WAIT状态一定的时间,等候针对该TCP连接的残留的、重复的包过来(迷途刚找到路的,或由于某个途径的路由器太慢而姗姗来迟的)。

SO_REUSEADDR选项
SO_REUSEADDR选项,实际是在setsockopt函数中使用的,而setsocketopt函数一般用于在socket和bind函数之间调用。setsocketopt函数就是为了解决上面谈到的,处于TIME_WAIT状态时bind调用会提示失败的情况的。
该选项有4种不同的能力
- (1)SO_REUSEADDR允许启动一个监听服务器并捆绑其所要监听的端口,即使此前建立的将该端口用作其本地端口的连接(图显示的Local Address列)仍存在。
- (2)允许在同一端口上启动同一服务器的多个实例,只要每个实例捆绑一个不同的本地IP地址即可(一个计算机有多个IP地址时允许捆绑不同IP地址的同一个端口)。
(3)允许单个进程捆绑同一端口到多个套接字上,只要每次捆绑指定不同的本地IP地址即可。
(4)SO_REUSEADDR允许完全重复的捆绑:当一个IP地址和端口号已绑定到某个套接字上时,如果传输协议支持,同样的IP地址和端口还可以捆绑到另一个套接字上。本特性一般仅支持UDP套接字。
setsockopt 函数


server.c
#include <stdio.h>
#include <ctype.h>
#include <unistd.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
//本服务器要监听的端口号,一般1024以下的端口很多都是属于周知端口,所以我们一般采用1024之后的数字做端口号
#define SERV_PORT 9000
int main(int argc, char *const *argv) {
//服务器的socket套接字【文件描述符】
//创建服务器的socket
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
//服务器的地址结构体
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
//绑定我们自定义的端口号,客户端程序和我们服务器程序通讯时,就要往这个端口连接和传送数据
// 端口号使用htons函数转换为网络字节序(大端字节序)
serv_addr.sin_port = htons(SERV_PORT);
// IP地址设置为INADDR_ANY表示监听所有本地IP地址。
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
//setsockopt():设置一些套接字参数选项;
//参数2:是表示级别,和参数3配套使用,也就是说,参数3如果确定了,参数2就确定了;
//参数3:允许重用本地地址
int reuseaddr = 1; //开启
if(setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, (const void *) &reuseaddr, sizeof(reuseaddr)) == -1) {
char *perrorinfo = strerror(errno);
printf("setsockopt(SO_REUSEADDR)返回值为%d, 错误码为:%d, 错误信息为: %s;\n", -1,errno, perrorinfo);
}
//绑定服务器地址结构体
int result = bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("bind返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno, perrorinfo);
close(listenfd);
return -1;
}
//参数2表示服务器可以积压的未处理完的连入请求总个数,客户端来一个未连入的请求,请求数+1,连入请求完成,c/s之间进入正常通讯后,请求数-1
result = listen(listenfd, 32);
if(result == -1) {
char *perrorinfo = strerror(errno);
printf("listen返回的值为%d, 错误码为:%d, 错误信息为:%s;\n", result, errno,perrorinfo);
close(listenfd);
return -1;
}
/*
{
//再绑定一个
int listenfd2 = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in serv_addr2;
memset(&serv_addr2,0,sizeof(serv_addr2));
serv_addr2.sin_family = AF_INET;
serv_addr2.sin_port = htons(SERV_PORT); //端口重复,bind会失败
serv_addr2.sin_addr.s_addr = htonl(INADDR_ANY);
result = bind(listenfd2, (struct sockaddr*)&serv_addr2, sizeof(serv_addr2));
char *perrorinfo = strerror(errno); //根据资料不会返回NULL;
printf("bind返回的值为%d,错误码为:%d,错误信息为:%s;\n",result,errno,perrorinfo); //bind返回的值为-1,错误码为:98,错误信息为:Address already in use;
}*/
int connfd;
const char *pcontent = "I sent sth to client!"; //指向常量字符串区的指针
for(;;) {
//卡在这里,等客户单连接,客户端连入后,该函数走下去【注意这里返回的是一个新的socket——connfd,后续本服务器就用connfd和客户端之间收发数据,而原有的lisenfd依旧用于继续监听其他连接】
connfd = accept(listenfd, (struct sockaddr*)NULL, NULL);
//发送数据包给客户端
//注意第一个参数是accept返回的connfd套接字
write(connfd, pcontent, strlen(pcontent));
printf("本服务器给客户端发送了一串字符~~~~~~~~~~~!\n");
//以下代码非常不完善,纯粹用于演示目的,完全不可以商用
// char recvline[1000 + 1];
// read(connfd, recvline, 1000); //卡在这,从客户端收点东西
//往客户端发送点东西
// write(connfd, pcontent, strlen(pcontent));
//只给客户端发送一个信息,然后直接关闭套接字连接;
close(connfd);
} //end for
close(listenfd); //实际本简单范例走不到这里,这句暂时看起来没啥用
return 0;
}
1. 2个进程,绑定同一个IP和端口

重新打开一个SecureCRT终端窗口,再次运行server, 出现如下结果:

从结果中可以看到bind失败,因为端口(SERV_PORT)和IP(INADDR_ANY)是重复的。这种情况只有针对UDP时会bind成功,而这里是TCP,所以bind不成功是在意料之中的。
由此得出结论,对于TCP,开2个进程,绑定(bind)同一个IP和端口会失败。
2.TIME_WAIT状态时的bind绑定


此时,在运行server进程的SecureCRT窗口,可以按Ctrl+C组合键结束该进程,然后再次运行server进程,发现可以运行成功。这一点符合前面SO_REUSEADDR选项的第1种说法——SO_REUSEADDR允许启动一个监听服务器并捆绑其所要监听的端口,即使此前建立的将该端口用作其本地端口的连接仍存在
当然,再次成功运行server进程后,快速使用netstat命令查看连接,那个处于TIME_WAIT状态的连接应该还在(重启进程并不能使以往处于TIME_WAIT状态的连接消失,所以TIME_WAIT状态等待的1~4min无法避免)。
所以,SO_REUSEADDR选项,主要用于解决TIME_WAIT状态导致bind失败的问题。但它并不能解决用同一个端口同一个地址再次绑定失败的问题(所以同一个班级里,还是不能有2个叫张三的人)。
当一个连接回到图中最上方的CLOSED状态,就意味着该连接的资源被系统回收(前面说过,套接字是个数字,该数字会被系统回收)了,同时也意味着使用netstat命令无法看到这个连接的状态了(连接已经被回收)。
listen 队列剖析
listen函数是用来监听端口的,是用在TCP网络通信的服务器角色程序中(注意措辞:TCP连接,服务器角色),UDP和客户端都不用该函数。
调用socket函数创建一个socket 传输通道之后,这个socket传输通道(TCP连接)状态属于CLOSED(关闭)状态,一旦调用listen函数,就变成了LISTEN(监听)状态。

在该调用格式中,第1个参数是监听套接字(用socket函数返回的)。这里需要深入理解的是backlog参数,要谈这个参数,必须先谈一谈监听套接字队列。
1.监听套接字队列
对于一个调用listen进行监听的套接字,操作系统会为其维护2个队列:未完成连接队列和已完成连接队列。
- (1)未完成连接队列中的连接
当客户端发送TCP连接三次握手的第1次(即SYN包)时,服务器端会在未完成连接队列中创建一个与该SYN包对应的项,可以把该项看成一个半连接(因为连接尚未建立),该半连接的状态会从LISTEN变成SYN_RCVD,同时向客户端返回第2次握手的包(SYN,ACK),而此时服务器正在等待完成第3次握手。

- (2)已完成连接队列中的连接
3次握手完成后,该连接就变成ESTABLISHED状态,每个已经完成3次握手的客户端连接(完整说法应该是“服务器端的与客户端对应的socket连接”)都放在这个队列中作为一项。

客户端发送的三次握手的第1个SYN包从图的下方发送过来,在三次握手完成之前,连接都会在未完成连接队列中;三次握手完成后,该连接就从未完成连接队列转移到已完成连接队列。
listen函数的第2个参数backlog含义曾经是:图中这2个队列之和不超过backlog(其实操作系统内部实现时,2个队列之和往往允许比backlog设置的值稍多)。注意这里用了“曾经”,说明它现在不是了,这个后续说

- (1)客户端的connect调用是什么时候返回的?其实是收到三次握手的第2次握手包(即收到服务器返回的SYN、ACK包)之后就返回了。
- (2)RTT代表未完成连接队列中的任意一项在未完成队列中留存的时间,时间长短取决于客户端和服务器。所以图中,对于客户端(因为客户端只有1个连接,RTT在客户端代表的是该连接从未完成状态到连接建立状态所经历的时间),RTT是第1次和第2次握手的时间总和;而对于服务器,RTT是第2次握手和第3次握手加起来的时间总和
如果这三次握手包传得特别快,大概187ms就能建立起连接,也就是说三次握手这3个包从开始发送到连接建立(客户端和服务器都达到ESTABLISHED状态)大概需要187ms(挺慢,所以建立TCP连接的成本还是挺高的)。
- (3)如果一个恶意客户,迟迟不发送三次握手的第3个包,TCP连接就建立不起来,服务器端处于SYN_RCVD的这一项半连接就会停留在未完成连接队列中,停留时间大概是75s,超过这个时间,这一项半连接就会被操作系统删除。
2.accept函数
accept函数用于从已完成连接队列中的队首(队头)位置取出一项,返回给进程(服务器程序)。
如果已完成连接队列是空的,accept函数调用就会卡在这里等待(休眠),直到已完成连接队列中有一项内容时才会被唤醒。
正常编写程序时,需要尽快调用accept把已完成连接队列中的项取走,要有这个认识。
accept返回的是一个套接字(socket),该套接字代表已经用三次握手建立起来的TCP连接(因为accept是从已完成连接队列中取到的连接项)。
换句话说,服务器程序必须严格区分2个套接字。
- (1)监听9000端口的套接字叫监听套接字,只要服务器程序在,该套接字就应该一直存在,目的是随时准备接受(监听到)客户端的连接。
- (2)当有客户端连接,操作系统会为每个成功完成三次握手的客户再创建一个套接字(当然是一个已连接套接字),这个套接字其实就是accept返回的套接字,也就是从已完成连接队列中取得的一项。随后,服务器用accept返回的套接字和客户端进行通信。
(1)如果已完成连接队列和未完成连接队列之和达到了listen所指定的第2参数,即队列满了,此时客户端再发送来一个SYN连接请求,服务器端会怎样反应呢?
服务器端会忽略该SYN,不给回应。客户端发现SYN没有回应,过一会就会重发这个SYN包。重发几次如果都没回应,就认为连接失败(connect失败)。
(2)三次握手完成,连接放到了已完成连接队列中,等着accept函数从已完成连接队列中把连接取走。试想,当accept还没来得及取走这个连接的时候,因为三次握手已经建立了,客户端如果此时发送数据过来,该数据就会被保存在已经连接的套接字的接收缓冲区里,该接收缓冲区的大小就是能接受的最大数据量。
3. SYN攻击
SYN攻击英文叫作syn flood,这是一个很恶心的攻击,也是一些黑客常用的手段之一,是一种典型的利用TCP/IP设计的一些弱点进行攻击的手段。
如果某个恶意的黑客通过一些特殊手段,伪造自己的IP地址和端口(源端口,源IP地址全部是伪造的),不停地给服务器发送SYN包(注意,该黑客只给服务器发送SYN包,也就是三次握手中的第1次握手包,不发送的第3个包,即ACK包),就会导致服务器端未完成连接队列中的条目越来越多,当未完成连接队列和已完成连接队列满了,服务器就会忽略后续再发来的SYN包,无法建立正常的TCP连接了,因为正常TCP连接的三次握手的第1次握手包(SYN包)被忽略了。换句话说,合法的用户无法得到服务了,这就是拒绝服务攻击的一种手段。
已完成连接队列和未完成连接队列之和曾经被限定不超过backlog,如果这样,SYN攻击可能就把服务器攻击死了,因为backlog这个数字也有最大值限制。
所以,后来将backlog参数的含义修改为:指定给定套接字(服务器端的监听套接字)上内核为其排队的最大已完成连接数已完成连接队列中允许存放的最大条数)。这样规定就不用担心SYN攻击把未完成连接队列塞满的问题了——塞满就塞满,操作系统会去处理的,除非程序员不用accept从已完成队列中取走已完成连接导致已完成连接数超过这个数字,新连接进不来。只要注意尽快用accept函数把已完成连接队列里的连接取走,尽快腾出地方来,已完成连接队列一般就不会被塞满。
阻塞与非阻塞 I / O
阻塞和非阻塞主要是对调用一个系统功能函数时,该函数是否会导致进程进入sleep (睡眠)状态而言的。
1.阻塞I / O
阻塞,就是调用一个函数,该函数就卡在这里,整个程序流程不往下走了(此时进程进入休眠状态)。该函数卡在这里等待一个事件发生,只有这个事件发生了,该函数才会继续往下走(进程才会继续运行)。
这种函数就是阻塞函数,如服务器端使用的accept函数。调用accept时,程序执行流程就卡在accept这里,等待客户端连接,只有客户端连接,三次握手成功,accept才会返回。
这种阻塞并不好,效率很低,为什么呢?操作系统是通过给每个进程分配一段执行时间的手段来轮流执行每个进程,这一段执行时间叫作“时间片”。每个进程要想充分运行,就应该尽量把操作系统为其分配的时间片用完。而现在程序执行流程卡在这里,阻塞了,操作系统就会立即从当前进程切换到另一个进程去执行了,当前进程此时就成了活雷锋——把属于自己的时间片拱手送给了别人。
所以优质程序一般都不会用阻塞的方式来编写代码。
accept函数本身可以阻塞,也可以不阻塞,主要取决于调用accept函数时所提供的第1个参数,即监听套接字(服务器端程序代码中listenfd)。程序员调用socket函数创建套接字时,默认情况下,这些套接字都是阻塞的,用一个阻塞的套接字调用accept函数,accept函数就变成阻塞的函数了。
这里以recvfrom函数(用于接收对方发送过来的数据)为例来描述阻塞式I/O模型

recvfrom 函数

2.非阻塞I / O
还以accept为例,如果通过调用某个函数,把监听套接字listenfd设置成非阻塞,那么调用accept的时候,就算是没有客户端连接,这个accept调用也不会卡住,会立即返回(当然返回时有一个错误码,程序员通过该错误码就能判断accept返回的原因)。这样就能够充分利用操作系统给进程分配的时间片来做别的事(而不是卡在这里把本属于自己的时间片拱手送人),执行效率更高。
非阻塞模式有2个鲜明的特点

- (1)要不断调用该函数(如图中的recvfrom所示)检查有没有数据到来,如果没有,函数会返回一个特殊的错误标记来告诉程序员,这种错误标记可能是图中的EWOULDBLOCK,也可能是EAGAIN
- (2)如果数据到来,就要把数据从内核缓冲区复制到用户缓冲区,所以,即便是非阻塞模式,复制数据阶段也是卡着完成的。
比较阻塞和非阻塞I/O模型在调用recvfrom时不同的代码执行表现

异步与同步 I / O
1、当接受缓存中无数据时:如果用户程序一直等待直到新数据到来,是阻塞。如果程序不等待,继续向下执行,是非阻塞。
2、当缓存中有数据时:对该数据的读写操作由用户程序自己来完成,是同步;如果读写操作是别人帮忙完成的,是异步。
所以就类似于取快递:
阻塞:快递还没到菜鸟驿站,你就待在那等快递来
非阻塞:快递还没到驿站,你就先去看京东的快递到了没
同步:快递到驿站了,你自己去取
异步:快递到驿站了,快递小哥给你送上门
1.异步I / O
调用一个异步I / O函数接收数据时,不管有没有数据,该函数都会立即返回。但是,程序员在调用异步I/O函数时要指定一个接收数据的缓冲区(buffer),还要指定一个回调函数,其他的事情操作系统去做了,程序可以自由地干其他事情。
操作系统会判断数据是否到来,如果到来了,操作系统会把数据复制到程序员指定的接收数据的缓冲区(buffer),然后调用程序员所指定的回调函数来通知程序。
这时就很容易区分非阻塞I/O与异步I/O的差别了
- (1)非阻塞I/O要不停地调用I/O函数检查数据是否到来,如果数据到来,就要卡在I/0函数这里把数据从内核缓冲区复制到用户缓冲区,然后该I/O函数才能返回。
- (2)异步I/O不需要不停地调用I/O函数检查数据是否到来,只需要调用1次,然后就做其他事情去了,内核检查数据的到来,内核负责把数据复制到指定缓冲区(复制期间完全不会卡住应用程序的执行流程),然后内核负责通知程序员数据到来。在整个事情的过程中,进程并没有被卡在那里,甚至就算是收到数据,也是内核把数据复制到程序员提供的buffer中,不会卡住进程。
2.同步I / O
系统函数select和poll用的就是同步I/O,甚至作为重点的epoll,也可以划分到同步I/O范畴。

可以看到,这里涉及2个函数,首先调用select函数,判断是否有数据(该函数只能判断是否有数据,并不能去取数据),如果没有数据就卡在那等;如果有数据,select返回,之后调用recvfrom函数去取数据。取数据涉及数据从内核空间复制到用户空间,所以复制数据时还是要卡着。
所以,同步I/O更麻烦,需要调用2个函数才能取到数据,其优点就是得到了所谓I/O 复用的能力。
所谓I/O复用,就是多个socket(多个TCP连接)可以绑在一起,程序员可以使用同步I/O的函数(如select)等待接收数据。换句话说,select的能力是等多条TCP连接上的任意一条有数据到来,然后程序员再使用具体函数(如recvfrom)去收。这就是同步I/O要调用2个函数来收数据的原因

许多书籍把阻塞I/O、非阻塞I/O、同步I/O归为一类,因为它们多少都存在阻塞行为(部分资料甚至直接把阻塞I/O、非阻塞I/O模型都归为同步I/O模型),而把异步I/O单独归结为一类,因为异步I/O没有阻塞行为发生。
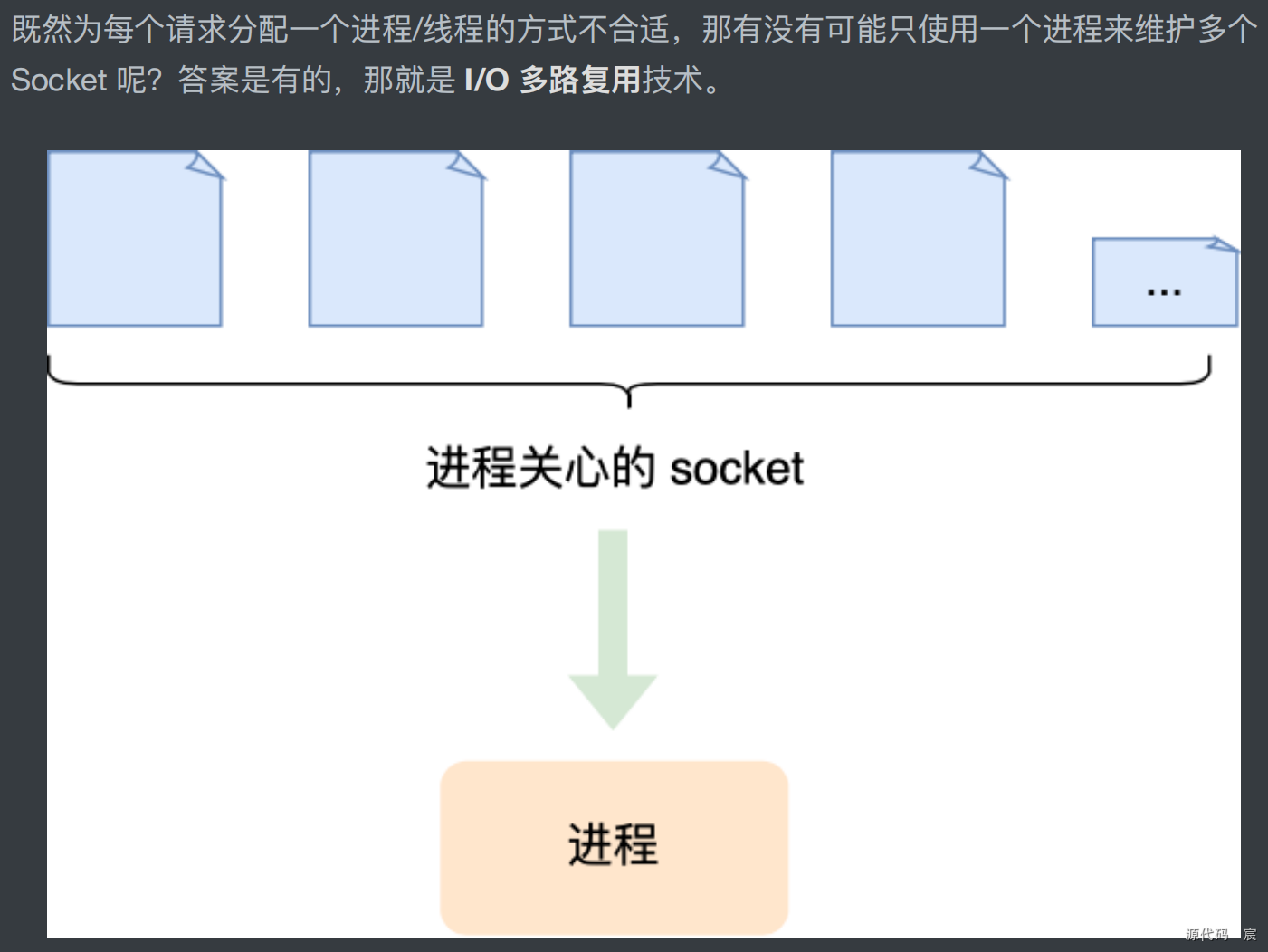
I / O复用
这种调用1个函数就能判断一批TCP连接是否有数据到的能力,就叫I/O复用(I/O multiplexing,全称“I/O多路复用”)。

I/O 多路复用:select/poll/epoll

最基本的 Socket 模型







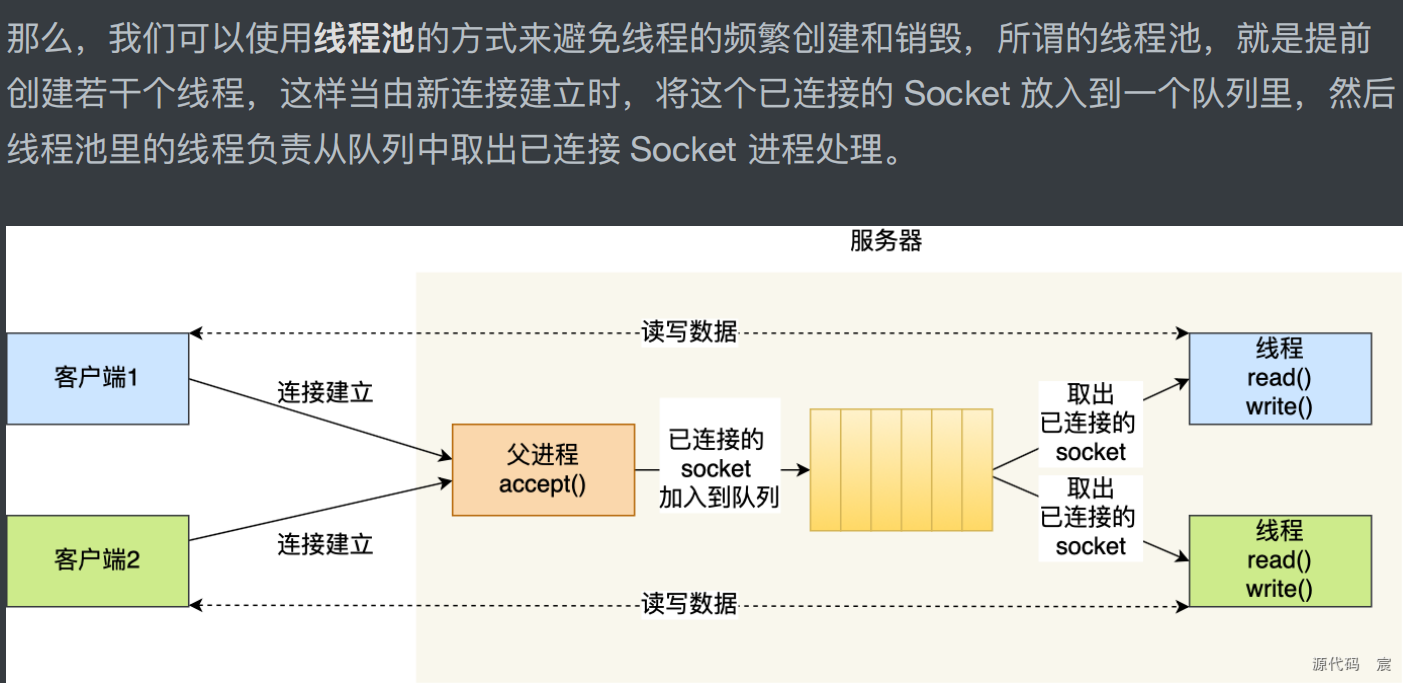
如何服务更多的用户?


多进程模型




多线程模型


I/O 多路复用

select/poll

epoll










总结




监听端口
config.mk
#定义项目编译的根目录,通过export把某个变量声明为全局的[其他文件中可以用],这里获取当前这个文件所在的路径作为根目录;
#BUILD_ROOT = /mnt/hgfs/linux/nginx
export BUILD_ROOT = $(shell pwd)
#定义头文件的路径变量
export INCLUDE_PATH = $(BUILD_ROOT)/_include
#定义我们要编译的目录
BUILD_DIRS = $(BUILD_ROOT)/signal/ \
$(BUILD_ROOT)/proc/ \
$(BUILD_ROOT)/net/ \
$(BUILD_ROOT)/app/
#编译时是否生成调试信息。GNU调试器可以利用该信息
#很多调试工具,包括Valgrind工具集都会因为这个为true能够输出更多的调试信息;
export DEBUG = true
nginx.conf
#是注释行,
#每个有效配置项用 等号 处理,等号前不超过40个字符,等号后不超过400个字符;
#[开头的表示组信息,也等价于注释行
[Socket]
ListenPort = 5678
DBInfo = 127.0.0.1;1234;myr;123456;mxdb_g
#日志相关
[Log]
#日志文件输出目录和文件名
Log=logs/error.log
# Log=error.log
#只打印日志等级<= 数字 的日志到日志文件中 ,日志等级0-8,0级别最高,8级别最低。
LogLevel = 8
#进程相关
[Proc]
#创建 这些个 worker进程
WorkerProcesses = 2
#是否按守护进程方式运行,1:按守护进程方式运行,0:不按守护进程方式运行
Daemon = 1
#和网络相关
[Net]
#监听的端口数量,一般都是1个,当然如果支持多于一个也是可以的
ListenPortCount = 2
#ListenPort+数字【数字从0开始】,这种ListenPort开头的项有几个,取决于ListenPortCount的数量
ListenPort0 = 80
ListenPort1 = 443
本服务器项目的体系结构是1个master进程和多个worker进程,主要做事的就是和客户端通信的worker进程。服务器是被动等待连接的,需要在一些端口上进行监听并等待客户端连接,所以首先要编写监听端口相关的代码。
监听端口相关的初始化代码,实际上在创建worker进程之前就执行了,也就是说,创建worker进程之前,监听端口就已经开始监听了。
ngx_c_socket.cxx
- (1)因为配置文件中一共需要开启2个端口,所以利用for循环来实现多个监听端口的开启;
- (2)对于每个要监听的端口都需要调用socket、setsockopt、setnonblocking(自定义函数,设置非阻塞socket)、bind和listen函数;
- (3)每个监听的端口信息都放m_ListenSocketList容器中保存,该容器中的每一项的内存都是新建的,所以记得在CSocket类的析构函数中释放内存。
//和网络 有关的函数放这里
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h> //uintptr_t
#include <stdarg.h> //va_start....
#include <unistd.h> //STDERR_FILENO等
#include <sys/time.h> //gettimeofday
#include <time.h> //localtime_r
#include <fcntl.h> //open
#include <errno.h> //errno
#include <sys/socket.h>
#include <sys/ioctl.h> //ioctl
#include <arpa/inet.h>
#include "ngx_c_conf.h"
#include "ngx_macro.h"
#include "ngx_global.h"
#include "ngx_func.h"
#include "ngx_c_socket.h"
//构造函数
CSocekt::CSocekt() {
m_ListenPortCount = 1; //监听一个端口
return;
}
//释放函数
CSocekt::~CSocekt() {
//释放必须的内存
std::vector<lpngx_listening_t>::iterator pos;
for(pos = m_ListenSocketList.begin(); pos != m_ListenSocketList.end(); ++pos) {
delete (*pos); //一定要把指针指向的内存干掉,不然内存泄漏
}//end for
m_ListenSocketList.clear();
return;
}
//初始化函数【fork()子进程之前干这个事】
//成功返回true,失败返回false
bool CSocekt::Initialize() {
bool reco = ngx_open_listening_sockets();
return reco;
}
//监听端口【支持多个端口】,这里遵从nginx的函数命名
//在创建worker进程之前就要执行这个函数;
bool CSocekt::ngx_open_listening_sockets() {
CConfig *p_config = CConfig::GetInstance();
m_ListenPortCount = p_config->GetIntDefault("ListenPortCount",m_ListenPortCount); //取得要监听的端口数量
int isock; //socket
struct sockaddr_in serv_addr; //服务器的地址结构体
int iport; //端口
char strinfo[100]; //临时字符串
//初始化相关
memset(&serv_addr, 0, sizeof(serv_addr)); //先初始化一下
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听。
//要监听这么多个端口
for(int i = 0; i < m_ListenPortCount; i++) {
//参数1:AF_INET:使用ipv4协议,一般就这么写
//参数2:SOCK_STREAM:使用TCP,表示可靠连接【相对还有一个UDP套接字,表示不可靠连接】
//参数3:给0,固定用法,就这么记
isock = socket(AF_INET, SOCK_STREAM, 0); //系统函数,成功返回非负描述符,出错返回-1
if(isock == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中socket()失败, i=%d.", i);
//其实这里直接退出,那如果以往有成功创建的socket呢?就没得到释放吧,当然走到这里表示程序不正常,应该整个退出,也没必要释放了
return false;
}
//setsockopt():设置一些套接字参数选项;
//参数2:是表示级别,和参数3配套使用,也就是说,参数3如果确定了,参数2就确定了;
//参数3:允许重用本地地址
//设置 SO_REUSEADDR,目的第五章第三节讲解的非常清楚:主要是解决TIME_WAIT这个状态导致bind()失败的问题
int reuseaddr = 1; //1:打开对应的设置项
if(setsockopt(isock, SOL_SOCKET, SO_REUSEADDR, (const void *) &reuseaddr, sizeof(reuseaddr)) == -1) {
ngx_log_stderr(errno,"CSocekt::Initialize()中setsockopt(SO_REUSEADDR)失败,i = %d.",i);
close(isock); //无需理会是否正常执行了
return false;
}
//设置该socket为非阻塞
if(setnonblocking(isock) == false) {
ngx_log_stderr(errno, "CSocekt::Initialize()中setnonblocking()失败, i = %d.", i);
close(isock);
return false;
}
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
strinfo[0] = 0;
sprintf(strinfo, "ListenPort%d", i);
iport = p_config->GetIntDefault(strinfo, 10000);
//in_port_t其实就是uint16_t
serv_addr.sin_port = htons((in_port_t)iport);
//绑定服务器地址结构体
if(bind(isock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中bind()失败, i = %d.", i);
close(isock);
return false;
}
//开始监听
if(listen(isock, NGX_LISTEN_BACKLOG) == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中listen()失败,i=%d.", i);
close(isock);
return false;
}
//可以,放到列表里来
//千万不要写错,注意前边类型是指针,后边类型是一个结构体
lpngx_listening_t p_listensocketitem = new ngx_listening_t;
//注意后边用的是 ngx_listening_t而不是lpngx_listening_t
memset(p_listensocketitem, 0, sizeof(ngx_listening_t));
//记录下所监听的端口号
p_listensocketitem->port = iport;
//套接字句柄保存下来
p_listensocketitem->fd = isock;
//显示一些信息到日志中
ngx_log_error_core(NGX_LOG_INFO, 0, "监听%d端口成功!", iport);
//加入到队列中
m_ListenSocketList.push_back(p_listensocketitem);
} //end for(int i = 0; i < m_ListenPortCount; i++)
return true;
}
//设置socket连接为非阻塞模式【这种函数的写法很固定】:非阻塞,概念在五章四节讲解的非常清楚【不断调用,不断调用这种:拷贝数据的时候是阻塞的】
bool CSocekt::setnonblocking(int sockfd) {
// 1,表示要设置非阻塞模式。如果设置为 0,表示清除非阻塞模式。
int nb = 1;
//FIONBIO:设置/清除非阻塞I/O标记:0:清除,1:设置
if(ioctl(sockfd, FIONBIO, &nb) == -1) {
return false;
}
return true;
//如下也是一种写法,跟上边这种写法其实是一样的,但上边的写法更简单
/*
//fcntl:file control【文件控制】相关函数,执行各种描述符控制操作
//参数1:所要设置的描述符,这里是套接字【也是描述符的一种】
int opts = fcntl(sockfd, F_GETFL); //用F_GETFL先获取描述符的一些标志信息
if(opts < 0)
{
ngx_log_stderr(errno,"CSocekt::setnonblocking()中fcntl(F_GETFL)失败.");
return false;
}
opts |= O_NONBLOCK; //把非阻塞标记加到原来的标记上,标记这是个非阻塞套接字【如何关闭非阻塞呢?opts &= ~O_NONBLOCK,然后再F_SETFL一下即可】
if(fcntl(sockfd, F_SETFL, opts) < 0)
{
ngx_log_stderr(errno,"CSocekt::setnonblocking()中fcntl(F_SETFL)失败.");
return false;
}
return true;
*/
}
//关闭socket,什么时候用,我们现在先不确定,先把这个函数预备在这里
void CSocekt::ngx_close_listening_sockets() {
//要关闭这么多个监听端口
for(int i = 0; i < m_ListenPortCount; i++) {
//ngx_log_stderr(0,"端口是%d,socketid是%d.",m_ListenSocketList[i]->port,m_ListenSocketList[i]->fd);
close(m_ListenSocketList[i]->fd);
ngx_log_error_core(NGX_LOG_INFO, 0, "关闭监听端口%d!", m_ListenSocketList[i]->port); //显示一些信息到日志中
}//end for(int i = 0; i < m_ListenPortCount; i++)
return;
}
delete 和 clear的区别

ioctl 函数

ioctl(sockfd, FIONBIO, &nb)

epoll 技术
epoll概述
I/O多路复用技术用于监控多个TCP 连接上的数据收发,而epoll就是一种在Linux上使用的I/O多路复用并支持高并发的典型技术。传统的select、poll也是I/O多路复用技术,但这2种技术受内部实现的限制,不支持高并发,如同时连入超过1000个客户端,性能就会明显下降。
所以,每一种类UNIX操作系统又都引入了支持高并发的网络通信技术,如epoll、kqueue等,其中kqueue一般用在freebsd等操作系统上。epoll技术从Linux内核2.6开始才引入,2.6之前是没有的。
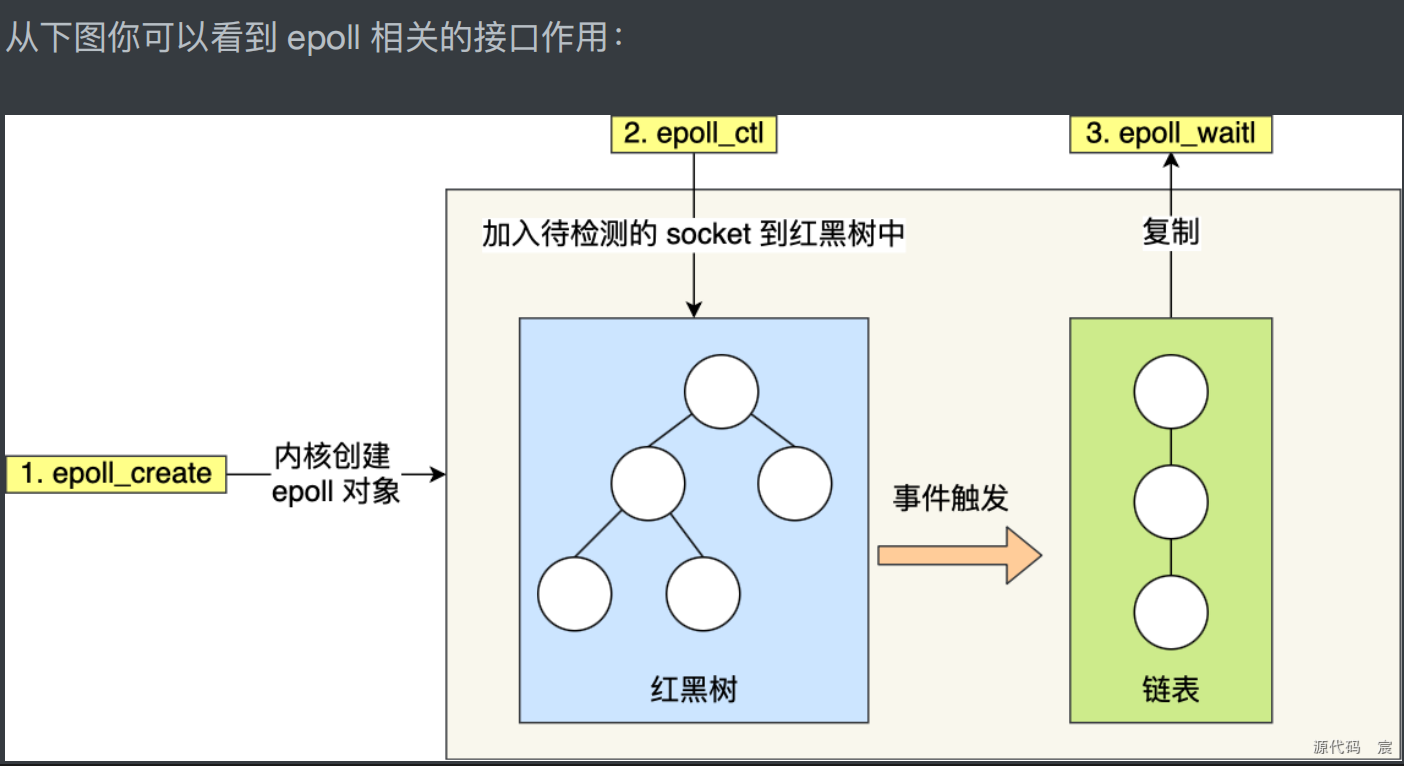
epoll技术也是通过3个专门的函数来实现I/O多路复用
(2)epoll技术的性能和kqueue类似,可以说非常惊艳,它是能使单台计算机支撑数万甚至数十万上百万并发的核心技术,远优于其他I/O模型或I/O函数(如select、poll函数),select和poll这类技术因为系统内部实现问题,当并发(客户端同时连入)数量超过1000~2000时性能就开始急剧下降,但epoll技术完全没有这种问题(性能不会随着并发数量的提高而出现明显下降)。当然,并发数高,需要的内存也更大,所以,即便是并发数量的急剧提高对性能影响不大,但是内存总是有限的,换句话说,并发数也总是有限制的,不可能无限增加。
(3)即使有10万个并发连接(同一时刻有10万个客户端保持和服务器的连接),这10万个连接通常也不可能在同一时刻都在收发数据,一般在同一时刻通常只有其中几十或几百个连接在收发数据,其他连接可能处于只连接而没有收发数据的状态。如果以100ms 为间隔判断一次,可能这100ms内只有100个活跃连接(有数据收发的连接),把这100个活跃连接的数据放在一个专门的地方,后续到这个专门的地方来,只需要处理100条数据,处理起来是不是没有压力呀?这就是epoll的处理方式。而select和poll是依次判断这10万个连接上有没有发来数据(实际上有数据的只有100个连接),有数据则处理。不难想象,每次检查10万个连接与每次检查100个连接相比,是巨大的资源和时间浪费,所以并发数超过1000~2000的时候,select和poll这种技术(或者说这种函数、这种模型)的性能将急剧下降。
(4)很多处理网络通信的服务器程序都是多进程(每个进程对应一个客户端的连接)的,也有多线程(每个线程对应一个客户端的连接)的,但是,如果进程或者线程增多,即使不计进程或者线程本身的消耗,进程或线程之间的时间片/上下文频繁切换,也非常消耗性能。而epoll技术是一种简单粗暴有效的技术,采用事件驱动机制,只在单独的进程或线程里收集和处理各种事件,没有进程或线程之间的切换消耗。
总结:epoll技术非常适合用于高并发处理,本项目选择的正是epoll技术,将该技术的相关功能融合到本项目中
值得一提的是,高并发技术,比如epoll,如果难度分100级,只写一个演示程序进行简单的数据收发,难度只有1~10,但真正支持高并发在商业环境中稳妥地运行,难度会骤增到100。
epoll 原理与函数
epoll_create函数

功能。创建一个epoll对象,返回一个对象(文件)描述符来标识该epoll对象,后续要通过操作该描述符来进行数据的收发。
该对象最终要用close关闭,因为它是个描述符,或者说是个句柄,总是要关闭的。
nty_epoll_inner.h
/*
* MIT License
*
* Copyright (c) [2018] [WangBoJing]
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software.
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*
*
*
*
*/
#ifndef __NTY_EPOLL_INNER_H__
#define __NTY_EPOLL_INNER_H__
#include "nty_socket.h"
#include "nty_epoll.h"
#include "nty_buffer.h"
#include "nty_header.h"
typedef struct _nty_epoll_stat {
uint64_t calls;
uint64_t waits;
uint64_t wakes;
uint64_t issued;
uint64_t registered;
uint64_t invalidated;
uint64_t handled;
} nty_epoll_stat;
typedef struct _nty_epoll_event_int {
nty_epoll_event ev;
int sockid;
} nty_epoll_event_int;
typedef enum {
USR_EVENT_QUEUE = 0,
USR_SHADOW_EVENT_QUEUE = 1,
NTY_EVENT_QUEUE = 2
} nty_event_queue_type;
typedef struct _nty_event_queue {
nty_epoll_event_int *events;
int start;
int end;
int size;
int num_events;
} nty_event_queue;
typedef struct _nty_epoll {
nty_event_queue *usr_queue;
nty_event_queue *usr_shadow_queue;
nty_event_queue *queue;
uint8_t waiting;
nty_epoll_stat stat;
pthread_cond_t epoll_cond;
pthread_mutex_t epoll_lock;
} nty_epoll;
int nty_epoll_add_event(nty_epoll *ep, int queue_type, struct _nty_socket_map *socket, uint32_t event);
int nty_close_epoll_socket(int epid);
int nty_epoll_flush_events(uint32_t cur_ts);
#if NTY_ENABLE_EPOLL_RB
//这是个节点相关的结构
//作为红黑树的一个节点
struct epitem {
RB_ENTRY(epitem) rbn;
/* RB_ENTRY相当如定义了如下的一个结构成员变量
struct {
struct type *rbe_left; //指向左子树
struct type *rbe_right; //指向右子树
struct type *rbe_parent; //指向父节点
int rbe_color; //该红黑树节点颜色
} rbn*/
LIST_ENTRY(epitem) rdlink;
/*
struct {
struct type *le_next; //指向下个元素
struct type **le_prev; //前一个元素的地址
}*/
int rdy; //exist in list 是否这个节点是同时在双向链表中【这个节点刚开始是在红黑树中】
int sockfd;
struct epoll_event event;
};
static int sockfd_cmp(struct epitem *ep1, struct epitem *ep2) {
if (ep1->sockfd < ep2->sockfd) return -1;
else if (ep1->sockfd == ep2->sockfd) return 0;
return 1;
}
RB_HEAD(_epoll_rb_socket, epitem);
/*
#define RB_HEAD(_epoll_rb_socket, epitem) 等价于定义了如下这个结构
struct _epoll_rb_socket {
struct epitem *rbh_root;
}
*/
RB_GENERATE_STATIC(_epoll_rb_socket, epitem, rbn, sockfd_cmp);
typedef struct _epoll_rb_socket ep_rb_tree;
//调用epoll_create()的时候我们会创建这个结构的对象
struct eventpoll {
ep_rb_tree rbr; //ep_rb_tree是个结构,所以rbr是结构变量,这里代表红黑树的根;
int rbcnt;
LIST_HEAD( ,epitem) rdlist; //rdlist是结构变量,这里代表双向链表的根;
/* 这个LIST_HEAD等价于下边这个
struct {
struct epitem *lh_first;
}rdlist;
*/
int rdnum; //双向链表里边的节点数量(也就是有多少个TCP连接来事件了)
int waiting;
pthread_mutex_t mtx; //rbtree update
pthread_spinlock_t lock; //rdlist update
pthread_cond_t cond; //block for event
pthread_mutex_t cdmtx; //mutex for cond
};
int epoll_event_callback(struct eventpoll *ep, int sockid, uint32_t event);
#endif
#endif
nty_epoll_rb.c
/*
* MIT License
*
* Copyright (c) [2018] [WangBoJing]
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software.
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*
*
*
*
*/
#include "nty_tree.h"
#include "nty_queue.h"
#include "nty_epoll_inner.h"
#include "nty_config.h"
#if NTY_ENABLE_EPOLL_RB
#include <pthread.h>
#include <stdint.h>
#include <time.h>
#include <linux/time.h>
//static pthread_mutex_t epmutex;
extern nty_tcp_manager *nty_get_tcp_manager(void);
//创建epoll对象,创建一颗空红黑树,一个空双向链表
int epoll_create(int size) {
if (size <= 0) return -1;
nty_tcp_manager *tcp = nty_get_tcp_manager();
if (!tcp) return -1;
struct _nty_socket *epsocket = nty_socket_allocate(NTY_TCP_SOCK_EPOLL);
if (epsocket == NULL) {
nty_trace_epoll("malloc failed\n");
return -1;
}
//(1)相当于new了一个eventpoll对象【开辟了一块内存】
struct eventpoll *ep = (struct eventpoll*)calloc(1, sizeof(struct eventpoll)); //参数1:元素数量 ,参数2:每个元素大小
if (!ep) {
nty_free_socket(epsocket->id, 0);
return -1;
}
ep->rbcnt = 0;
//(2)让红黑树根节点指向一个空
RB_INIT(&ep->rbr); //等价于ep->rbr.rbh_root = NULL;
//(3)让双向链表的根节点指向一个空
LIST_INIT(&ep->rdlist); //等价于ep->rdlist.lh_first = NULL;
if (pthread_mutex_init(&ep->mtx, NULL)) {
free(ep);
nty_free_socket(epsocket->id, 0);
return -2;
}
if (pthread_mutex_init(&ep->cdmtx, NULL)) {
pthread_mutex_destroy(&ep->mtx);
free(ep);
nty_free_socket(epsocket->id, 0);
return -2;
}
if (pthread_cond_init(&ep->cond, NULL)) {
pthread_mutex_destroy(&ep->cdmtx);
pthread_mutex_destroy(&ep->mtx);
free(ep);
nty_free_socket(epsocket->id, 0);
return -2;
}
if (pthread_spin_init(&ep->lock, PTHREAD_PROCESS_SHARED)) {
pthread_cond_destroy(&ep->cond);
pthread_mutex_destroy(&ep->cdmtx);
pthread_mutex_destroy(&ep->mtx);
free(ep);
nty_free_socket(epsocket->id, 0);
return -2;
}
tcp->ep = (void*)ep;
epsocket->ep = (void*)ep;
return epsocket->id;
}
//往红黑树中加每个tcp连接以及相关的事件
int epoll_ctl(int epid, int op, int sockid, struct epoll_event *event) {
nty_tcp_manager *tcp = nty_get_tcp_manager();
if (!tcp) return -1;
nty_trace_epoll(" epoll_ctl --> 1111111:%d, sockid:%d\n", epid, sockid);
struct _nty_socket *epsocket = tcp->fdtable->sockfds[epid];
//struct _nty_socket *socket = tcp->fdtable->sockfds[sockid];
//nty_trace_epoll(" epoll_ctl --> 1111111:%d, sockid:%d\n", epsocket->id, sockid);
if (epsocket->socktype == NTY_TCP_SOCK_UNUSED) {
errno = -EBADF;
return -1;
}
if (epsocket->socktype != NTY_TCP_SOCK_EPOLL) {
errno = -EINVAL;
return -1;
}
nty_trace_epoll(" epoll_ctl --> eventpoll\n");
struct eventpoll *ep = (struct eventpoll*)epsocket->ep;
if (!ep || (!event && op != EPOLL_CTL_DEL)) {
errno = -EINVAL;
return -1;
}
if (op == EPOLL_CTL_ADD) {
//添加sockfd上关联的事件
pthread_mutex_lock(&ep->mtx);
struct epitem tmp;
tmp.sockfd = sockid;
struct epitem *epi = RB_FIND(_epoll_rb_socket, &ep->rbr, &tmp); //先在红黑树上找,根据key来找,也就是这个sockid,找的速度会非常快
if (epi) {
//原来有这个节点,不能再次插入
nty_trace_epoll("rbtree is exist\n");
pthread_mutex_unlock(&ep->mtx);
return -1;
}
//只有红黑树上没有该节点【没有用过EPOLL_CTL_ADD的tcp连接才能走到这里】;
//(1)生成了一个epitem对象,大家注意这个结构epitem,这个结构对象,其实就是红黑的一个节点,也就是说,红黑树的每个节点都是 一个epitem对象;
epi = (struct epitem*)calloc(1, sizeof(struct epitem));
if (!epi) {
pthread_mutex_unlock(&ep->mtx);
errno = -ENOMEM;
return -1;
}
//(2)把socket(TCP连接)保存到节点中;
epi->sockfd = sockid; //作为红黑树节点的key,保存在红黑树中
//(3)我们要增加的事件也保存到节点中;
memcpy(&epi->event, event, sizeof(struct epoll_event));
//(4)把这个节点插入到红黑树中去
epi = RB_INSERT(_epoll_rb_socket, &ep->rbr, epi); //实际上这个时候epi的rbn成员就会发挥作用,如果这个红黑树中有多个节点,那么RB_INSERT就会epi->rbi相应的值:可以参考图来理解
assert(epi == NULL);
ep->rbcnt ++;
pthread_mutex_unlock(&ep->mtx);
} else if (op == EPOLL_CTL_DEL) {
//把红黑树节点从红黑树上删除
pthread_mutex_lock(&ep->mtx);
struct epitem tmp;
tmp.sockfd = sockid;
struct epitem *epi = RB_FIND(_epoll_rb_socket, &ep->rbr, &tmp);//先在红黑树上找,根据key来找,也就是这个sockid,找的速度会非常快
if (!epi) {
nty_trace_epoll("rbtree no exist\n");
pthread_mutex_unlock(&ep->mtx);
return -1;
}
//只有在红黑树上找到该节点【用过EPOLL_CTL_ADD的tcp连接才能走到这里】;
//(1)从红黑树上把这个节点干掉
epi = RB_REMOVE(_epoll_rb_socket, &ep->rbr, epi);
if (!epi) {
nty_trace_epoll("rbtree is no exist\n");
pthread_mutex_unlock(&ep->mtx);
return -1;
}
ep->rbcnt --;
free(epi);
pthread_mutex_unlock(&ep->mtx);
} else if (op == EPOLL_CTL_MOD) {
//修改红黑树某个节点的内容
struct epitem tmp;
tmp.sockfd = sockid;
struct epitem *epi = RB_FIND(_epoll_rb_socket, &ep->rbr, &tmp); //先在红黑树上找,根据key来找,也就是这个sockid,找的速度会非常快
if (epi) {
//(1)红黑树上有该节点,则修改对应的事件
epi->event.events = event->events;
epi->event.events |= EPOLLERR | EPOLLHUP;
} else {
errno = -ENOENT;
return -1;
}
} else {
nty_trace_epoll("op is no exist\n");
assert(0);
}
return 0;
}
//到双向链表中去取相关的事件通知
int epoll_wait(int epid, struct epoll_event *events, int maxevents, int timeout) {
nty_tcp_manager *tcp = nty_get_tcp_manager();
if (!tcp) return -1;
//nty_socket_map *epsocket = &tcp->smap[epid];
struct _nty_socket *epsocket = tcp->fdtable->sockfds[epid];
if (epsocket == NULL) return -1;
if (epsocket->socktype == NTY_TCP_SOCK_UNUSED) {
errno = -EBADF;
return -1;
}
if (epsocket->socktype != NTY_TCP_SOCK_EPOLL) {
errno = -EINVAL;
return -1;
}
struct eventpoll *ep = (struct eventpoll*)epsocket->ep;
if (!ep || !events || maxevents <= 0) {
errno = -EINVAL;
return -1;
}
if (pthread_mutex_lock(&ep->cdmtx)) {
if (errno == EDEADLK) {
nty_trace_epoll("epoll lock blocked\n");
}
assert(0);
}
//(1)这个while用来等待一定的时间【在这段时间内,发生事件的TCP连接,相关的节点,会被操作系统扔到双向链表去【当然这个节点同时也在红黑树中呢】】
while (ep->rdnum == 0 && timeout != 0) {
ep->waiting = 1;
if (timeout > 0) {
struct timespec deadline;
clock_gettime(CLOCK_REALTIME, &deadline);
if (timeout >= 1000) {
int sec;
sec = timeout / 1000;
deadline.tv_sec += sec;
timeout -= sec * 1000;
}
deadline.tv_nsec += timeout * 1000000;
if (deadline.tv_nsec >= 1000000000) {
deadline.tv_sec++;
deadline.tv_nsec -= 1000000000;
}
int ret = pthread_cond_timedwait(&ep->cond, &ep->cdmtx, &deadline);
if (ret && ret != ETIMEDOUT) {
nty_trace_epoll("pthread_cond_timewait\n");
pthread_mutex_unlock(&ep->cdmtx);
return -1;
}
timeout = 0;
} else if (timeout < 0) {
int ret = pthread_cond_wait(&ep->cond, &ep->cdmtx);
if (ret) {
nty_trace_epoll("pthread_cond_wait\n");
pthread_mutex_unlock(&ep->cdmtx);
return -1;
}
}
ep->waiting = 0;
}
pthread_mutex_unlock(&ep->cdmtx);
//等一小段时间,等时间到达后,流程来到这里。。。。。。。。。。。。。。
pthread_spin_lock(&ep->lock);
int cnt = 0;
//(1)取得事件的数量
//ep->rdnum:代表双向链表里边的节点数量(也就是有多少个TCP连接来事件了)
//maxevents:此次调用最多可以收集到maxevents个已经就绪【已经准备好】的读写事件
int num = (ep->rdnum > maxevents ? maxevents : ep->rdnum); //哪个数量少,就取得少的数字作为要取的事件数量
int i = 0;
while (num != 0 && !LIST_EMPTY(&ep->rdlist)) { //EPOLLET
//(2)每次都从双向链表头取得 一个一个的节点
struct epitem *epi = LIST_FIRST(&ep->rdlist);
//(3)把这个节点从双向链表中删除【但这并不影响这个节点依旧在红黑树中】
LIST_REMOVE(epi, rdlink);
//(4)这是个标记,标记这个节点【这个节点本身是已经在红黑树中】已经不在双向链表中;
epi->rdy = 0; //当这个节点被操作系统 加入到 双向链表中时,这个标记会设置为1。
//(5)把事件标记信息拷贝出来;拷贝到提供的events参数中
memcpy(&events[i++], &epi->event, sizeof(struct epoll_event));
num --;
cnt ++; //拷贝 出来的 双向链表 中节点数目累加
ep->rdnum --; //双向链表里边的节点数量减1
}
pthread_spin_unlock(&ep->lock);
//(5)返回 实际 发生事件的 tcp连接的数目;
return cnt;
}
/*
* insert callback inside to struct tcp_stream
*
*/
//当发生客户端三路握手连入、可读、可写、客户端断开等情况时,操作系统会调用这个函数,用以往双向链表中增加一个节点【该节点同时 也在红黑树中】
int epoll_event_callback(struct eventpoll *ep, int sockid, uint32_t event) {
struct epitem tmp;
tmp.sockfd = sockid;
//(1)根据给定的key【这个TCP连接的socket】从红黑树中找到这个节点
struct epitem *epi = RB_FIND(_epoll_rb_socket, &ep->rbr, &tmp);
if (!epi) {
nty_trace_epoll("rbtree not exist\n");
assert(0);
}
//(2)从红黑树中找到这个节点后,判断这个节点是否已经被连入到双向链表里【判断的是rdy标志】
if (epi->rdy) {
//这个节点已经在双向链表里,那无非是把新发生的事件标志增加到现有的事件标志中
epi->event.events |= event;
return 1;
}
//走到这里,表示 双向链表中并没有这个节点,那要做的就是把这个节点连入到双向链表中
nty_trace_epoll("epoll_event_callback --> %d\n", epi->sockfd);
pthread_spin_lock(&ep->lock);
//(3)标记这个节点已经被放入双向链表中,我们刚才研究epoll_wait()的时候,从双向链表中把这个节点取走的时候,这个标志被设置回了0
epi->rdy = 1;
//(4)把这个节点链入到双向链表的表头位置
LIST_INSERT_HEAD(&ep->rdlist, epi, rdlink);
//(5)双向链表中的节点数量加1,刚才研究epoll_wait()的时候,从双向链表中把这个节点取走的时候,这个数量减了1
ep->rdnum ++;
pthread_spin_unlock(&ep->lock);
pthread_mutex_lock(&ep->cdmtx);
pthread_cond_signal(&ep->cond);
pthread_mutex_unlock(&ep->cdmtx);
return 0;
}
static int epoll_destroy(struct eventpoll *ep) {
//remove rdlist
while (!LIST_EMPTY(&ep->rdlist)) {
struct epitem *epi = LIST_FIRST(&ep->rdlist);
LIST_REMOVE(epi, rdlink);
}
//remove rbtree
pthread_mutex_lock(&ep->mtx);
for (;;) {
struct epitem *epi = RB_MIN(_epoll_rb_socket, &ep->rbr);
if (epi == NULL) break;
epi = RB_REMOVE(_epoll_rb_socket, &ep->rbr, epi);
free(epi);
}
pthread_mutex_unlock(&ep->mtx);
return 0;
}
int nty_epoll_close_socket(int epid) {
nty_tcp_manager *tcp = nty_get_tcp_manager();
if (!tcp) return -1;
struct eventpoll *ep = (struct eventpoll *)tcp->fdtable->sockfds[epid]->ep;
if (!ep) {
errno = -EINVAL;
return -1;
}
epoll_destroy(ep);
pthread_mutex_lock(&ep->mtx);
tcp->ep = NULL;
tcp->fdtable->sockfds[epid]->ep = NULL;
pthread_cond_signal(&ep->cond);
pthread_mutex_unlock(&ep->mtx);
pthread_cond_destroy(&ep->cond);
pthread_mutex_destroy(&ep->mtx);
pthread_spin_destroy(&ep->lock);
free(ep);
return 0;
}
#endif
struct eventpoll *ep = (struct eventpoll*)calloc(1, sizeof(struct eventpoll));
生成一个eventpoll对象(eventpoll想象成系统定义的一个结构)
eventpoll对象中有很多成员,这里只关心其中的rbr和rdlist.
//调用epoll_create()的时候我们会创建这个结构的对象
struct eventpoll {
ep_rb_tree rbr; //ep_rb_tree是个结构,所以rbr是结构变量,这里代表红黑树的根;
int rbcnt;
LIST_HEAD( ,epitem) rdlist; //rdlist是结构变量,这里代表双向链表的根;
/* 这个LIST_HEAD等价于下边这个
struct {
struct epitem *lh_first;
}rdlist;
*/
int rdnum; //双向链表里边的节点数量(也就是有多少个TCP连接来事件了)
int waiting;
pthread_mutex_t mtx; //rbtree update
pthread_spinlock_t lock; //rdlist update
pthread_cond_t cond; //block for event
pthread_mutex_t cdmtx; //mutex for cond
};
(1)rbr。可以将该成员理解成代表一棵红黑树根节点。
这里把rbr理解成指向红黑树根节点的指针,可能更容易理解,所以建议,还是把它理解成指向红黑树根节点的指针。
红黑树是一种数据结构,用于保存数据,一般都是存“键/值(key/value)对”。红黑树的特点是能够极快速地根据给的key(键)找到并取出value(值)。这里的key一般是个数字,value代表的可能是一批数据。如果value是一个结构,通过一个数字(key)在红黑树里查找,就可以快速找到value(一个结构,里面有一批数据)。因为红黑树查找速度快,效率高,所以在epoll技术中是引入了红黑树的。


(2)rdlist。可以将该成员理解成代表一个双向链表的表头指针。
双向链表也是一种数据结构,特点是顺序访问里面的节点速度非常快,沿着它的链往下走(遍历)就可以。与上面的红黑树比,红黑树随机查找任意一个节点块,双向链表顺序往下访问每个节点块,各有特点和用途。

总结一下epoll_create函数:
- (1)创建了一个eventpoll结构对象,被系统保存起来。
- (2)对象中的rbr成员被初始化成指向一颗红黑树的根(有了这个根,就可以向红黑树中插入节点,或者说插入数据了)。想象现在有了一颗红黑树。
- (3)对象中的rdlist成员被初始化成指向一个双向链表的根(有了这个根,就可以向双向链表中插入节点,或者说插入数据了)。想象现在有了一个双向链表。
epoll_ctl函数

(2)功能。
把一个socket及该socket相关的事件添加到epoll对象描述符中,以通过该epoll对象来监视该socket(也就是该TCP连接)上数据的来往情况,当有数据来往时,系统会通知程序。
程序员会通过epoll_ctl函数把程序中需要关注(感兴趣)的事件添加到epoll对象描述符中,当这些事件到来时,系统就会通知程序。
- ①参数efpd。从epoll_create返回的epoll对象描述符。
- ②参数op。一个操作类型,可以理解成是一个数字,一般是1、2或3。
数字1:添加sockid上关联的事件,对应一个宏定义EPOLL_CTL_ADD。
数字2:删除sockid上关联的事件,对应一个宏定义EPOLL_CTL_DEL。
数字3:修改sockid上关联的事件,对应一个宏定义EPOLL_CTL_MOD。
添加事件(数字1)之后,当这种事件到来,系统会通知程序去处理。所谓添加事件,就是在图中的红黑树上添加一个节点。每一个客户端连入服务器之后,服务器都会创建一个对应的socket(accept函数返回值)用于与客户端通信,因为操作系统会保证每个连入服务器的socket值都不重复,所以系统就会以socket值为key,把节点添加到红黑树中(红黑树的key要求不能重复)。
修改事件(数字3)就是修改红黑树节点中的一些值。所以要想修改事件,必须先调用EPOLL_CTL_ADD把事件添加到红黑树上。如原来添加到epoll对象描述符中3个事件,现在想修改成只关注2个事件,这就需要调用EPOLL_CTL_MOD。
删除事件(数字2)怎么理解?如原本关注3个事件,现在想减少1个,变成关注2个事件,就需要调用EPOLL_CTL_MOD而不是EPOLL_CTL_DEL。EPOLL_CTL_DEL的真实动作是从红黑树中删除节点(不是关闭这个TCP连接),这会导致程序无法收到所有该TCP连接上的事件通知,所以这一项只有在需要时才用。
- ③参数sockid。一个TCP连接。添加事件(往红黑树中增加节点)时,就是用sockid 作为key往红黑树中增加节点的。
- ④参数event。向epoll_ctl函数传递信息。如要增加一些事件,就可以通过event参数将具体事件传递进epoll_etl函数。后续写实战代码时,再详细讲解。
(3)原理。在 nty_epoll_rb.c 中,查找epoll_ctl找到该函数的实现源码。注意看注释,分析一下重要内容。
①如果传递进来的是一个EPOLL_CTL_ADD,则观察if(op== EPOLL_CTL ADD)条件成立时所执行的代码。
代码首先使用RB_FIND来查找红黑树上是否已经有了该节点,如果有了,则直接返回;没有,程序流程才继续往下走。
确认红黑树上没有该节点的情况下,执行代码行epi =(struct epitem*)calloc(1,sizeof(struct epitem));来生成一个epitem对象 (epitem可以想象成系统定义的一个结构),该 epitem对象就是后续增加到红黑树中的一个节点。该结构中有很多成员,都很重要。

图中就是即将向红黑树中插一个节点,该节点的key保存在成员sockfd中,要增加的事件保存在成员event中,然后使用RB_INSERT 宏将该节点插入红黑树中。所以上上图中红黑树的每一个节点(红色或者黑色的圆球)就是上图的样子。
对于红黑树来讲,每个节点都要记录自己的左子树、右子树和父节点,所以上图所示的结构也就必须有能力指向左子树、右子树及父节点,所以,上图中的rbn成员本身又是个结构类型,该结构中包含指向左子树、右子树、父节点的指针成员。如果将来多个用户连入服务器,需要向这颗红黑树中加入很多节点,这些节点彼此也要连接起来。如加入3个节点,结果可能如下图所示。

总之,对于红黑树的每个节点,通过rbn成员,做到有父节点的就指向父节点,有子节点的就指向子节点,父节点、子节点都有,就既指向父节点又指向子节点即可。
由谁向红黑树中增加节点呢?实际上是epoll_ctl(EPOLL_CTL_ADD),每个红黑树节点其实就代表一个TCP连接。
②如果传递进来的是一个EPOLL_CTL_DEL,则观察else if (op== EPOLL_CTL_DEL)条件成立时所执行的代码。
从红黑树中使用RB_FIND查找出某个红黑树节点,然后直接使用RB_REMOVE从红黑树中删除该节点,释放对应的内存(就是epi所指向的内存)。可想而知,把某个节点从红黑树上删除之后,该节点对应的TCP连接所发生的事件就没办法知道了。
EPOLL_CTL_DEL,这不是用来删除某个或者某些感兴趣的事件的,而是用来从红黑树中删除某个红黑树节点的。
③如果传递进来的是一个EPOLL_CTL_MOD,则观察else if(op==EPOLL_CTL_MOD)条件成立时所执行的代码。
源码比较简单,无非就是使用RB_FIND找到某个已经存在的红黑树节点,把该节点中的一些数据(event)做一些修改。
总结:EPOLL_CTL_ADD,等价于往红黑树中增加节点;EPOLL_CTL_DEL,等价于从红黑树中删除节点;EPOLL_CTL_MOD,等价于修改红黑树的节点。
所以,每一个连入的客户端都应该调用epoll_ctl向红黑树增加一个红黑树节点,如果有100万个并发连接,红黑树上就会有100万个节点。
现在,这100万个连接增加到红黑树中来了,相关的程序感兴趣的事件也一起增加到了红黑树的节点中,当某些TCP连接上发生这些事件(比如连入、断开、有数据收发等)时;操作系统就会通知程序。程序如何接收到这些操作系统的通知呢?就是用下面介绍的epoll_wait函数。
epoll_wait函数

功能。阻塞一小段时间并等待事件发生,返回事件集合,即获取内核的事件通知。换句话说就是遍历双向链表,把双向链表中节点相关的数据复制出去,并从双向链表中删除该节点。因为所有有数据的socket(TCP连接)都在双向链表里记录着。
- ①参数efpd。从epoll_create返回的epoll对象描述符。
- ②参数events。一个数组,长度为maxevents,表示此次调用epoll_wait函数最多可以收集到maxevents个已经就绪(已经准备好)的读写事件。实际的读写事件由本函数的返回值决定(换句话说,返回的是有事件发生的TCP连接的数目,但因为内存所限,可能100个TCP上有事件发生,但返回的数字却是80——小于100)。
- ③参数timeout。阻塞等待的时长
总体来说,该函数就是到双向链表中去,把此刻同时连入的连接中有事件发生的连接拿过来,后续用read、write或send、recv之类的函数收发数据。某个socket只要在双向链表中,该socket上一定发生了某个/某些事件,换句话说,只有发生了某个/某些事件的socket,才会在双向链表中出现。
这就是epoll高效的原因,因为epoll每次只遍历发生事件的一小部分socket连接(这些socket都在这个双向链表中),而不用到全部socket连接中去逐个遍历以判断事件是否到来。
前面看过,epitem是一个红黑树节点,同时也是一个双向链表节点,所以这个epitem节点设计得非常巧妙,很通用,既能作为红黑树的一个节点加到红黑树中,也能作为双向链表的一个节点加到双向链表中,所以,通过epoll_wait函数到双向链表中取节点时,取出来的依旧是epitem节点。
epitem的rbn成员,有了该成员,就相当于有了3个指针,从而能够把该epitem 节点插入红黑树中去

有了这个rdlink成员,相当于又有了2个指针,这样就能够把epitem节点插入双向链表当中

所以,epitem结构的设计高明之处就在于既能作为红黑树节点插入红黑树中,又能作为双向链表的节点插入双向链表中。不需要在创建红黑树节点时设计一个结构,创建双向链表节点时再设计一个结构,这就是程序设计的艺术。
如果把这个epitem节点同时也插人双向链表中,结果就可能是下图所示,假如有3个TCP连接上都收到了事件,那么这3个TCP连接肯定都待在双向链表里了(当然它们同时也待在红黑树里,但图中只绘制了它们待在双向链表里的情形,以免图形绘制得太复杂,看起来太乱)。


(3)原理。可以看看epoll_wait内部做了一些什么事,在 nty_epoll_rb.c 中,查找epoll_wait找到该函数的实现源码。
① while(ep> rdnum==0&& timeout!= 0)循环,用于等待一小段时间(如100ms)。这一小段时间内发生的事件的节点(socket连接),就会被操作系统放到双向链表中。
②等待的时间到达后,确定本次返回给调用本函数(epoll_wait)的调用者程序的事件数量。
用一个while循环把这一批事件的信息返回给调用者程序。注意从双向链表中移除返回给调用者程序的节点(节点始终在红黑树中存着,但是否在双向链表中取决于该节点是否收到了事件)。另外,epitem结构中的rdy成员用于标记该节点是否存在于双向链表中,所以,当节点从双向链表中移除时,rdy成员被设置为0。

epoll是一种典型的在Linux上使用的I/O多路复用并支持高并发的技术,正是通过函数epoll_wait来在这等数据的到来。针对“同步I/O(I/O复用)”这一项,epoll_wait应该处的位置如下图所示

内核向双向链表增加节点
epoll_wait函数实际是去双向链表中取节点,那么,是谁把这些节点插入双向链表中的呢?显然是操作系统(内核)。操作系统什么时候向双向链表中插入的节点呢?显然是某个TCP连接上有事件到来时(这些事件是程序员用epoll_ctl登记到红黑树里面的),操作系统就会向双向链表中插入节点。
一般分4种情况, 事件会使操作系统把节点插入双向链表里面去
- (1)客户端完成三次握手时,操作系统会向双向链表插入节点,这时服务器往往要调用accept函数把该连接从已完成连接队列中取走。
- (2)当客户端关闭连接时,操作系统会向双向链表插入节点,这时服务器也要调用close关闭对应的socket。
- (3)当客户端发送来数据时,操作系统会向双向链表插入节点,这时服务器要调用read 或者recv来收数据。
- (4)当可以发送数据时,操作系统会向双向链表插入节点,这时服务器可以调用send 或者write向客户端发送数据。这一条稍抽象,可以这么理解:如果客户端接收数据慢,服务器端发送数据快,那么服务器就得等客户端收完一批数据后才能再发下一批。在之前举过一个喂孩子吃饭的例子,这里就是当操作系统通知服务器可以给客户端发送数据时,服务器才能发送数据,以免将客户端“噎死”。
当上面这4种情况之一发生时,操作系统会调用epoll_event_callback函数向双向链表中插入一个节点。
- ①使用RB_FIND在红黑树中寻找节点。
- ②如果节点已经在双向链表中,则叠加事件后返回:

- ①通过代码“epi->rdy=1;”把该节点是否在双向链表中的标记设置为1(表示在双向链表中)。
- ②执行代码LIST_INSERT_HEAD(&ep-> rdlist,epi,rdlink);把这个节点链入双向链表的表头位置。
- ③另外,epoll_wait函数,如果双向链表中有数据,可能不需要等待参数timeout中指定的时间,可能epoll_wait会立即返回;如果没数据,才会等待timeout这么长时间。
这套epoll源码实现中有很多加锁机制。因为不排除Linux 内核中有多个线程同时操作红黑树和双向链表,所以读者往往能看到这些函数的源码中有很多以pthread_开头的函数(如pthread_mutex_init),专门用于处理多线程的临界、互斥等问题。
通信代码精粹之epoll函数实战
服务端程序理论上要求7×24小时不间断运行,而且不止服务1个用户,而是服务千千万万用户(每分每秒都有用户连接上来要求服务,同时也有已连接的用户断开连接),所以,一个微小的瑕疵随着程序运行时间的推移都会被放大,直至最终导致整个服务程序崩溃。所以,写服务器程序,程序员几乎不能犯任何错误,这就是服务器程序和客户端程序的不同——客户端程序一般运行少则几分钟,多则几小时,编码时只要不出现致命问题(如内存泄漏都是小问题),到时候程序一关闭就完事,泄漏的内存系统回收——但服务器程序显然不可以这样。
请记住一句话:服务器的开发难度,一般要比客户端开发难度高一大截(虽然服务器程序一般运行在后台,用户看不到界面)。一个网络项目实际上线时,最紧张的实际就是服务器端程序员,如果服务器程序不稳定,频繁崩溃,对于服务器程序员,甚至整个公司,就是最黑暗的时候。
ngx_c_socket.h
#ifndef __NGX_SOCKET_H__
#define __NGX_SOCKET_H__
#include <vector>
#include <sys/epoll.h> //epoll
#include <sys/socket.h>
//一些宏定义放在这里-----------------------------------------------------------
#define NGX_LISTEN_BACKLOG 511
//已完成连接队列,nginx给511,我们也先按照这个来
#define NGX_MAX_EVENTS 512
//epoll_wait一次最多接收这么多个事件,nginx中缺省是512,我们这里固定给成512就行,没太大必要修改
typedef struct ngx_connection_s ngx_connection_t, *lpngx_connection_t;
typedef class CSocekt CSocekt;
typedef void (CSocekt::*ngx_event_handler_pt)(lpngx_connection_t c);
//定义成员函数指针
//一些专用结构定义放在这里,暂时不考虑放ngx_global.h里了-------------------------
//和监听端口有关的结构
typedef struct ngx_listening_s {
int port; //监听的端口号
int fd; //套接字句柄socket
lpngx_connection_t connection; //连接池中的一个连接,注意这是个指针
} ngx_listening_t, *lpngx_listening_t;
//以下三个结构是非常重要的三个结构,我们遵从官方nginx的写法;
//(1)该结构表示一个TCP连接【客户端主动发起的、Nginx服务器被动接受的TCP连接】
struct ngx_connection_s
{
//套接字句柄socket
int fd;
//如果这个链接被分配给了一个监听套接字,那么这个里边就指向监听套接字对应的那个lpngx_listening_t的内存首地址
lpngx_listening_t listening;
//------------------------------------
unsigned instance:1;
//【位域】失效标志位:0:有效,1:失效【这个是官方nginx提供,到底有什么用,ngx_epoll_process_events()中详解】
uint64_t iCurrsequence;
//我引入的一个序号,每次分配出去时+1,此法也有可能在一定程度上检测错包废包,具体怎么用,用到了再说
//保存对方地址信息用的
struct sockaddr s_sockaddr;
//char addr_text[100]; //地址的文本信息,100足够,一般其实如果是ipv4地址,255.255.255.255,其实只需要20字节就够
//和读有关的标志-----------------------
//uint8_t r_ready; //读准备好标记【暂时没闹明白官方要怎么用,所以先注释掉】
uint8_t w_ready; //写准备好标记
ngx_event_handler_pt rhandler; //读事件的相关处理方法
ngx_event_handler_pt whandler; //写事件的相关处理方法
//--------------------------------------------------
//这是个指针【等价于传统链表里的next成员:后继指针】,指向下一个本类型对象,用于把空闲的连接池对象串起来构成一个单向链表,方便取用
lpngx_connection_t data;
};
/*
//(2)每个TCP连接至少需要一个读事件和一个写事件,所以定义事件结构
typedef struct ngx_event_s
{
}ngx_event_t,*lpngx_event_t;*/
//socket相关类
class CSocekt {
public:
CSocekt(); //构造函数
virtual ~CSocekt(); //释放函数
public:
virtual bool Initialize(); //初始化函数
public:
//epoll功能初始化
int ngx_epoll_init();
//监听端口开始工作
//void ngx_epoll_listenportstart();
//epoll增加事件
int ngx_epoll_add_event(int fd, int readevent, int writeevent, uint32_t otherflag, uint32_t eventtype, lpngx_connection_t c);
//epoll等待接收和处理事件
int ngx_epoll_process_events(int timer);
private:
//专门用于读各种配置项
void ReadConf();
//监听必须的端口【支持多个端口】
bool ngx_open_listening_sockets();
//关闭监听套接字
void ngx_close_listening_sockets();
//设置非阻塞套接字
bool setnonblocking(int sockfd);
//一些业务处理函数handler
void ngx_event_accept(lpngx_connection_t oldc); //建立新连接
void ngx_wait_request_handler(lpngx_connection_t c); //设置数据来时的读处理函数
void ngx_close_accepted_connection(lpngx_connection_t c); //用户连入,我们accept4()时,得到的socket在处理中产生失败,则资源用这个函数释放【因为这里涉及到好几个要释放的资源,所以写成函数】
//获取对端信息相关
size_t ngx_sock_ntop(struct sockaddr *sa,int port,u_char *text,size_t len); //根据参数1给定的信息,获取地址端口字符串,返回这个字符串的长度
//连接池 或 连接 相关
lpngx_connection_t ngx_get_connection(int isock); //从连接池中获取一个空闲连接
void ngx_free_connection(lpngx_connection_t c); //归还参数c所代表的连接到到连接池中
private:
//epoll连接的最大项数
int m_worker_connections;
//所监听的端口数量
int m_ListenPortCount;
//epoll_create返回的句柄
int m_epollhandle;
//和连接池有关的
//注意这里可是个指针,其实这是个连接池的首地址
lpngx_connection_t m_pconnections;
//空闲连接链表头,连接池中总是有某些连接被占用,为了快速在池中找到一个空闲的连接,我把空闲的连接专门用该成员记录;
lpngx_connection_t m_pfree_connections;
//【串成一串,其实这里指向的都是m_pconnections连接池里的没有被使用的成员】
//lpngx_event_t m_pread_events; //指针,读事件数组
//lpngx_event_t m_pwrite_events; //指针,写事件数组
//当前进程中所有连接对象的总数【连接池大小】
int m_connection_n;
//连接池中可用连接总数
int m_free_connection_n;
//监听套接字队列
std::vector<lpngx_listening_t> m_ListenSocketList;
//用于在epoll_wait()中承载返回的所发生的事件
struct epoll_event m_events[NGX_MAX_EVENTS];
};
#endif
unsigned

位域

ngx_c_socket.cxx
epoll_create函数的调用代码就在CSocket::ngx_epolLinit函数中, 有几点说明。
- (1)调用了epoll_create,使用的参数是配置文件中的worker_connections配置选项。
- (2)通过代码“m_pconnections = new ngx_connection_t[m_connection_n];”创建了一个连接池,即一个结构数组,其大小就是worker_connections(配置文件中连接的数量)。数组中每个元素(称连接池中的元素)的类型是ngx_connection_s(一个结构,参考_include子目录下的ngx_c_socket.h文件)。
引入该连接池(结构数组)的目的是什么?目前项目中有2个监听套接字,以后客户端连入后,每个用户还会产生1个套接字。套接字本身只是一个数字,但往往需要保存很多与该数字相关的信息,这就需要把套接字数字本身与一块内存捆绑起来。所以,引入连接池的目的就是把套接字与连接池中的某个元素捆绑起来,将来就可以通过套接字取得该连接池中的元素(内存),以方便读写其中的数据。紧接着利用一个do…while循环,把连接池中的各元素串起来(像一个链表一样)。注意核心代码“c[i].data= next;”和“next =&c[i];”。

其实连接池(结构数组)元素本身就是一个挨着一个,为什么这里又需要设一个链将各结构数组元素链在一起呢?当一个用户连入服务器时,服务器需要从连接池中找到一个空闲元素与连入的socket绑定。如果从c[0]开始逐个遍历到c[1023]来找空闲元素(不断有新用户连入,不断有老用户断开,所以连接池中的元素是否被使用就会变得杂乱,需要逐个遍历),太耗费时间,所以,专门设一个空闲链把所有空闲的连接池元素串到一起。因为该连接池刚刚初始化,所以每个元素都是空闲的,就把它们都串到一起。取空闲元素时,只需到该空闲链中把表头元素拿出来,并让m_pfree_connects指向空闲链的下一个元素(相当于把空闲链链表头元素从空闲链中拿走)。这样,在整个内存池中找一个空闲元素就非常快。
当某个用户断开,需要回收该元素的时候,直接把该元素放进整个空闲链的链头,然后用m_pfree_connects直接指向该元素就可以了。
用m_free_connection_n变量记录空闲链中的元素数目。
//和网络 有关的函数放这里
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h> //uintptr_t
#include <stdarg.h> //va_start....
#include <unistd.h> //STDERR_FILENO等
#include <sys/time.h> //gettimeofday
#include <time.h> //localtime_r
#include <fcntl.h> //open
#include <errno.h> //errno
#include <sys/socket.h>
#include <sys/ioctl.h> //ioctl
#include <arpa/inet.h>
#include "ngx_c_conf.h"
#include "ngx_macro.h"
#include "ngx_global.h"
#include "ngx_func.h"
#include "ngx_c_socket.h"
//构造函数
CSocekt::CSocekt() {
//配置相关
m_worker_connections = 1; //epoll连接最大项数
m_ListenPortCount = 1; //监听一个端口
//epoll相关
m_epollhandle = -1; //epoll返回的句柄
m_pconnections = NULL; //连接池【连接数组】先给空
m_pfree_connections = NULL; //连接池中空闲的连接链
//m_pread_events = NULL; //读事件数组给空
//m_pwrite_events = NULL; //写事件数组给空
return;
}
//释放函数
CSocekt::~CSocekt() {
//释放必须的内存
//(1)监听端口相关内存的释放--------
std::vector<lpngx_listening_t>::iterator pos;
for(pos = m_ListenSocketList.begin(); pos != m_ListenSocketList.end(); ++pos) {
delete (*pos); //一定要把指针指向的内存干掉,不然内存泄漏
}//end for
m_ListenSocketList.clear();
//(2)连接池相关的内容释放---------
//if(m_pwrite_events != NULL)//释放写事件数组
// delete [] m_pwrite_events;
//if(m_pread_events != NULL)//释放读事件数组
// delete [] m_pread_events;
if(m_pconnections != NULL)//释放连接池
delete [] m_pconnections;
return;
}
//初始化函数【fork()子进程之前干这个事】
//成功返回true,失败返回false
bool CSocekt::Initialize() {
ReadConf(); //读配置项
bool reco = ngx_open_listening_sockets();
return reco;
}
//专门用于读各种配置项
void CSocekt::ReadConf()
{
CConfig *p_config = CConfig::GetInstance();
m_worker_connections = p_config->GetIntDefault("worker_connections",m_worker_connections); //epoll连接的最大项数
m_ListenPortCount = p_config->GetIntDefault("ListenPortCount",m_ListenPortCount); //取得要监听的端口数量
return;
}
//监听端口【支持多个端口】,这里遵从nginx的函数命名
//在创建worker进程之前就要执行这个函数;
bool CSocekt::ngx_open_listening_sockets() {
int isock; //socket
struct sockaddr_in serv_addr; //服务器的地址结构体
int iport; //端口
char strinfo[100]; //临时字符串
//初始化相关
memset(&serv_addr, 0, sizeof(serv_addr)); //先初始化一下
serv_addr.sin_family = AF_INET; //选择协议族为IPV4
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
//监听本地所有的IP地址;INADDR_ANY表示的是一个服务器上所有的网卡(服务器可能不止一个网卡)多个本地ip地址都进行绑定端口号,进行侦听
//中途用到一些配置信息
CConfig *p_config = CConfig::GetInstance();
//要监听这么多个端口
for(int i = 0; i < m_ListenPortCount; i++) {
//参数1:AF_INET:使用ipv4协议,一般就这么写
//参数2:SOCK_STREAM:使用TCP,表示可靠连接【相对还有一个UDP套接字,表示不可靠连接】
//参数3:给0,固定用法,就这么记
isock = socket(AF_INET, SOCK_STREAM, 0); //系统函数,成功返回非负描述符,出错返回-1
if(isock == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中socket()失败, i=%d.", i);
//其实这里直接退出,那如果以往有成功创建的socket呢?就没得到释放吧,当然走到这里表示程序不正常,应该整个退出,也没必要释放了
return false;
}
//setsockopt():设置一些套接字参数选项;
//参数2:是表示级别,和参数3配套使用,也就是说,参数3如果确定了,参数2就确定了;
//参数3:允许重用本地地址
//设置 SO_REUSEADDR,目的:主要是解决TIME_WAIT这个状态导致bind()失败的问题
int reuseaddr = 1; //1:打开对应的设置项
if(setsockopt(isock, SOL_SOCKET, SO_REUSEADDR, (const void *) &reuseaddr, sizeof(reuseaddr)) == -1) {
ngx_log_stderr(errno,"CSocekt::Initialize()中setsockopt(SO_REUSEADDR)失败,i = %d.",i);
close(isock); //无需理会是否正常执行了
return false;
}
//设置该socket为非阻塞
if(setnonblocking(isock) == false) {
ngx_log_stderr(errno, "CSocekt::Initialize()中setnonblocking()失败, i = %d.", i);
close(isock);
return false;
}
//设置本服务器要监听的地址和端口,这样客户端才能连接到该地址和端口并发送数据
strinfo[0] = 0;
sprintf(strinfo, "ListenPort%d", i);
iport = p_config->GetIntDefault(strinfo, 10000);
//in_port_t其实就是uint16_t
serv_addr.sin_port = htons((in_port_t)iport);
//绑定服务器地址结构体
if(bind(isock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)) == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中bind()失败, i = %d.", i);
close(isock);
return false;
}
//开始监听
if(listen(isock, NGX_LISTEN_BACKLOG) == -1) {
ngx_log_stderr(errno, "CSocekt::Initialize()中listen()失败,i=%d.", i);
close(isock);
return false;
}
//可以,放到列表里来
//千万不要写错,注意前边类型是指针,后边类型是一个结构体
lpngx_listening_t p_listensocketitem = new ngx_listening_t;
//注意后边用的是 ngx_listening_t而不是lpngx_listening_t
memset(p_listensocketitem, 0, sizeof(ngx_listening_t));
//记录下所监听的端口号
p_listensocketitem->port = iport;
//套接字句柄保存下来
p_listensocketitem->fd = isock;
//显示一些信息到日志中
ngx_log_error_core(NGX_LOG_INFO, 0, "监听%d端口成功!", iport);
//加入到队列中
m_ListenSocketList.push_back(p_listensocketitem);
} //end for(int i = 0; i < m_ListenPortCount; i++)
//不可能一个端口都不监听吧
if(m_ListenSocketList.size() <= 0)
return false;
return true;
}
//设置socket连接为非阻塞模式【这种函数的写法很固定】:非阻塞,概念在五章四节讲解的非常清楚【不断调用,不断调用这种:拷贝数据的时候是阻塞的】
bool CSocekt::setnonblocking(int sockfd) {
// 1,表示要设置非阻塞模式。如果设置为 0,表示清除非阻塞模式。
int nb = 1;
//FIONBIO:设置/清除非阻塞I/O标记:0:清除,1:设置
if(ioctl(sockfd, FIONBIO, &nb) == -1) {
return false;
}
return true;
//如下也是一种写法,跟上边这种写法其实是一样的,但上边的写法更简单
/*
//fcntl:file control【文件控制】相关函数,执行各种描述符控制操作
//参数1:所要设置的描述符,这里是套接字【也是描述符的一种】
int opts = fcntl(sockfd, F_GETFL); //用F_GETFL先获取描述符的一些标志信息
if(opts < 0)
{
ngx_log_stderr(errno,"CSocekt::setnonblocking()中fcntl(F_GETFL)失败.");
return false;
}
opts |= O_NONBLOCK; //把非阻塞标记加到原来的标记上,标记这是个非阻塞套接字【如何关闭非阻塞呢?opts &= ~O_NONBLOCK,然后再F_SETFL一下即可】
if(fcntl(sockfd, F_SETFL, opts) < 0)
{
ngx_log_stderr(errno,"CSocekt::setnonblocking()中fcntl(F_SETFL)失败.");
return false;
}
return true;
*/
}
//关闭socket,什么时候用,我们现在先不确定,先把这个函数预备在这里
void CSocekt::ngx_close_listening_sockets() {
//要关闭这么多个监听端口
for(int i = 0; i < m_ListenPortCount; i++) {
//ngx_log_stderr(0,"端口是%d,socketid是%d.",m_ListenSocketList[i]->port,m_ListenSocketList[i]->fd);
close(m_ListenSocketList[i]->fd);
ngx_log_error_core(NGX_LOG_INFO, 0, "关闭监听端口%d!", m_ListenSocketList[i]->port); //显示一些信息到日志中
}//end for(int i = 0; i < m_ListenPortCount; i++)
return;
}
//--------------------------------------------------------------------
//(1)epoll功能初始化,子进程中进行 ,本函数被ngx_worker_process_init()所调用
int CSocekt::ngx_epoll_init() {
//(1)很多内核版本不处理epoll_create的参数,只要该参数>0即可
//创建一个epoll对象,创建了一个红黑树,还创建了一个双向链表
//直接以epoll连接的最大项数为参数,肯定是>0的;
m_epollhandle = epoll_create(m_worker_connections);
if (m_epollhandle == -1) {
//这是致命问题了,直接退,资源由系统释放吧,这里不刻意释放了,比较麻烦
ngx_log_stderr(errno,"CSocekt::ngx_epoll_init()中epoll_create()失败.");
exit(2);
}
//(2)创建连接池【数组】、创建出来,这个东西后续用于处理所有客户端的连接
//记录当前连接池中连接总数
m_connection_n = m_worker_connections;
//连接池【数组,每个元素是一个对象】
//new不可以失败,不用判断结果,如果失败直接报异常更好一些
// lpngx_connection_t
m_pconnections = new ngx_connection_t[m_connection_n];
//m_pread_events = new ngx_event_t[m_connection_n];
//m_pwrite_events = new ngx_event_t[m_connection_n];
//for(int i = 0; i < m_connection_n; i++)
//{
// m_pconnections[i].instance = 1; //失效标志位设置为1【失效】,此句抄自官方nginx,这句到底有啥用,后续再研究
//} //end for
int i = m_connection_n; //连接池中连接数
lpngx_connection_t next = NULL;
lpngx_connection_t c = m_pconnections; //连接池数组首地址
do {
i--; //注意i是数字的末尾,从最后遍历,i递减至数组首个元素
//从尾往头来---------
c[i].data = next; //设置连接对象的next指针,注意第一次循环时next = NULL;
c[i].fd = -1; //初始化连接,无socket和该连接池中的连接【对象】绑定
c[i].instance = 1; //失效标志位设置为1【失效】,此句抄自官方nginx,这句到底有啥用,后续再研究
c[i].iCurrsequence = 0; //当前序号统一从0开始
//----------------------
next = &c[i]; //next指针前移
} while (i); //循环直至i为0,即数组首地址
//设置空闲连接链表头指针,因为现在next指向c[0],注意现在整个链表都是空的
m_pfree_connections = next;
//空闲连接链表长度,因为现在整个链表都是空的,这两个长度相等
m_free_connection_n = m_connection_n;
//(3)遍历所有监听socket【监听端口】,我们为每个监听socket增加一个 连接池中的连接【说白了就是让一个socket和一个内存绑定,以方便记录该sokcet相关的数据、状态等等】
std::vector<lpngx_listening_t>::iterator pos;
for(pos = m_ListenSocketList.begin(); pos != m_ListenSocketList.end(); ++pos) {
c = ngx_get_connection((*pos)->fd); //从连接池中获取一个空闲连接对象
if (c == NULL) {
//这是致命问题,刚开始怎么可能连接池就为空呢?
ngx_log_stderr(errno,"CSocekt::ngx_epoll_init()中ngx_get_connection()失败.");
exit(2); //这是致命问题了,直接退,资源由系统释放吧,这里不刻意释放了,比较麻烦
}
c->listening = (*pos); //连接对象 和监听对象关联,方便通过连接对象找监听对象
(*pos)->connection = c; //监听对象 和连接对象关联,方便通过监听对象找连接对象
//rev->accept = 1; //监听端口必须设置accept标志为1 ,这个是否有必要,再研究
//对监听端口的读事件设置处理方法,因为监听端口是用来等对方连接的发送三次握手的,所以监听端口关心的就是读事件
c->rhandler = &CSocekt::ngx_event_accept;
//往监听socket上增加监听事件,从而开始让监听端口履行其职责【如果不加这行,虽然端口能连上,但不会触发ngx_epoll_process_events()里边的epoll_wait()往下走】
if(ngx_epoll_add_event((*pos)->fd, //socekt句柄
1,0, //读,写【只关心读事件,所以参数2:readevent=1,而参数3:writeevent=0】
0, //其他补充标记
EPOLL_CTL_ADD, //事件类型【增加,还有删除/修改】
c //连接池中的连接
) == -1)
{
exit(2); //有问题,直接退出,日志 已经写过了
}
} //end for
return 1;
}
/*
//(2)监听端口开始工作,监听端口要开始工作,必须为其增加读事件,因为监听端口只关心读事件
void CSocekt::ngx_epoll_listenportstart()
{
std::vector<lpngx_listening_t>::iterator pos;
for(pos = m_ListenSocketList.begin(); pos != m_ListenSocketList.end(); ++pos) //vector
{
//本函数如果失败,直接退出
ngx_epoll_add_event((*pos)->fd,1,0); //只关心读事件
} //end for
return;
}
*/
//epoll增加事件,可能被ngx_epoll_init()等函数调用
//fd:句柄,一个socket
//readevent:表示是否是个读事件,1是,0不是
//writeevent:表示是否是个写事件,1是,0不是
//otherflag:其他需要额外补充的标记,弄到这里
//eventtype:事件类型 ,一般就是用系统的枚举值,增加,删除,修改等;
//c:对应的连接池中的连接的指针
//返回值:成功返回1,失败返回-1;
int CSocekt::ngx_epoll_add_event(int fd,
int readevent,int writeevent,
uint32_t otherflag,
uint32_t eventtype,
lpngx_connection_t c
)
{
struct epoll_event ev;
//int op;
memset(&ev, 0, sizeof(ev));
if(readevent==1) {
//读事件,这里发现官方nginx没有使用EPOLLERR,因此我们也不用【有些范例中是使用EPOLLERR的】
ev.events = EPOLLIN|EPOLLRDHUP;
//EPOLLIN读事件,也就是read ready【客户端三次握手连接进来,也属于一种可读事件】 EPOLLRDHUP 客户端关闭连接,断连
//似乎不用加EPOLLERR,只用EPOLLRDHUP即可,EPOLLERR/EPOLLRDHUP 实际上是通过触发读写事件进行读写操作recv write来检测连接异常
//ev.events |= (ev.events | EPOLLET); //只支持非阻塞socket的高速模式【ET:边缘触发】,就拿accetp来说,如果加这个EPOLLET,则客户端连入时,epoll_wait()只会返回一次该事件,
//如果用的是EPOLLLT【水平触发:低速模式】,则客户端连入时,epoll_wait()会被触发多次,一直到用accept()来处理;
//https://blog.csdn.net/q576709166/article/details/8649911
//找下EPOLLERR的一些说法:
//a)对端正常关闭(程序里close(),shell下kill或ctr+c),触发EPOLLIN和EPOLLRDHUP,但是不触发EPOLLERR 和EPOLLHUP。
//b)EPOLLRDHUP 这个好像有些系统检测不到,可以使用EPOLLIN,read返回0,删除掉事件,关闭close(fd);如果有EPOLLRDHUP,检测它就可以直到是对方关闭;否则就用上面方法。
//c)client 端close()联接,server 会报某个sockfd可读,即epollin来临,然后recv一下 , 如果返回0再掉用epoll_ctl 中的EPOLL_CTL_DEL , 同时close(sockfd)。
//有些系统会收到一个EPOLLRDHUP,当然检测这个是最好不过了。只可惜是有些系统,上面的方法最保险;如果能加上对EPOLLRDHUP的处理那就是万能的了。
//d)EPOLLERR 只有采取动作时,才能知道是否对方异常。即对方突然断掉,是不可能有此事件发生的。只有自己采取动作(当然自己此刻也不知道),read,write时,出EPOLLERR错,说明对方已经异常断开。
//e)EPOLLERR 是服务器这边出错(自己出错当然能检测到,对方出错你咋能知道啊)
//f)给已经关闭的socket写时,会发生EPOLLERR,也就是说,只有在采取行动(比如读一个已经关闭的socket,或者写一个已经关闭的socket)时候,才知道对方是否关闭了。
//这个时候,如果对方异常关闭了,则会出现EPOLLERR,出现Error把对方DEL掉,close就可以了。
} else {
//其他事件类型待处理
//.....
}
if(otherflag != 0) {
ev.events |= otherflag;
}
//以下这段代码抄自nginx官方,因为指针的最后一位【二进制位】肯定不是1,所以 和 c->instance做 |运算;到时候通过一些编码,既可以取得c的真实地址,又可以把此时此刻的c->instance值取到
//比如c是个地址,可能的值是 0x00af0578,对应的二进制是101011110000010101111000,而 | 1后是0x00af0579
//把对象弄进去,后续来事件时,用epoll_wait()后,这个对象能取出来用
ev.data.ptr = (void *)( (uintptr_t)c | c->instance);
//但同时把一个 标志位【不是0就是1】弄进去
if(epoll_ctl(m_epollhandle, eventtype, fd, &ev) == -1) {
ngx_log_stderr(errno, "CSocekt::ngx_epoll_add_event()中epoll_ctl(%d, %d, %d, %u, %u)失败.", fd, readevent, writeevent, otherflag, eventtype);
//exit(2); //这是致命问题了,直接退,资源由系统释放吧,这里不刻意释放了,比较麻烦,后来发现不能直接退;
return -1;
}
return 1;
}
//开始获取发生的事件消息
//参数unsigned int timer:epoll_wait()阻塞的时长,单位是毫秒;
//返回值,1:正常返回 ,0:有问题返回,一般不管是正常还是问题返回,都应该保持进程继续运行
//本函数被ngx_process_events_and_timers()调用,而ngx_process_events_and_timers()是在子进程的死循环中被反复调用
int CSocekt::ngx_epoll_process_events(int timer) {
//等待事件,事件会返回到m_events里,最多返回NGX_MAX_EVENTS个事件【因为我只提供了这些内存】;
//阻塞timer这么长时间除非:a)阻塞时间到达 b)阻塞期间收到事件会立刻返回c)调用时有事件也会立刻返回d)如果来个信号,比如你用kill -1 pid测试
//如果timer为-1则一直阻塞,如果timer为0则立即返回,即便没有任何事件
//返回值:有错误发生返回-1,错误在errno中,比如你发个信号过来,就返回-1,错误信息是(4: Interrupted system call)
// 如果你等待的是一段时间,并且超时了,则返回0;
// 如果返回>0则表示成功捕获到这么多个事件【返回值里】
int events = epoll_wait(m_epollhandle,m_events,NGX_MAX_EVENTS,timer);
if(events == -1) {
//有错误发生,发送某个信号给本进程就可以导致这个条件成立,而且错误码根据观察是4;
//#define EINTR 4,EINTR错误的产生:当阻塞于某个慢系统调用的一个进程捕获某个信号且相应信号处理函数返回时,该系统调用可能返回一个EINTR错误。
//例如:在socket服务器端,设置了信号捕获机制,有子进程,当在父进程阻塞于慢系统调用时由父进程捕获到了一个有效信号时,内核会致使accept返回一个EINTR错误(被中断的系统调用)。
if(errno == EINTR) {
//信号所致,直接返回,一般认为这不是毛病,但还是打印下日志记录一下,因为一般也不会人为给worker进程发送消息
ngx_log_error_core(NGX_LOG_INFO,errno,"CSocekt::ngx_epoll_process_events()中epoll_wait()失败!");
return 1; //正常返回
} else {
//这被认为应该是有问题,记录日志
ngx_log_error_core(NGX_LOG_ALERT,errno,"CSocekt::ngx_epoll_process_events()中epoll_wait()失败!");
return 0; //非正常返回
}
}
if(events == 0) //超时,但没事件来
{
if(timer != -1) {
//要求epoll_wait阻塞一定的时间而不是一直阻塞,这属于阻塞到时间了,则正常返回
return 1;
}
//无限等待【所以不存在超时】,但却没返回任何事件,这应该不正常有问题
ngx_log_error_core(NGX_LOG_ALERT,0,"CSocekt::ngx_epoll_process_events()中epoll_wait()没超时却没返回任何事件!");
return 0; //非正常返回
}
//会惊群,一个telnet上来,4个worker进程都会被惊动,都执行下边这个
//ngx_log_stderr(errno,"惊群测试1:%d",events);
//走到这里,就是属于有事件收到了
lpngx_connection_t c;
uintptr_t instance;
uint32_t revents;
for(int i = 0; i < events; ++i) //遍历本次epoll_wait返回的所有事件,注意events才是返回的实际事件数量
{
c = (lpngx_connection_t)(m_events[i].data.ptr); //ngx_epoll_add_event()给进去的,这里能取出来
instance = (uintptr_t) c & 1; //将地址的最后一位取出来,用instance变量标识, 见ngx_epoll_add_event,该值是当时随着连接池中的连接一起给进来的
c = (lpngx_connection_t) ((uintptr_t)c & (uintptr_t) ~1); //最后1位干掉,得到真正的c地址
//仔细分析一下官方nginx的这个判断
if(c->fd == -1) //一个套接字,当关联一个 连接池中的连接【对象】时,这个套接字值是要给到c->fd的,
//那什么时候这个c->fd会变成-1呢?关闭连接时这个fd会被设置为-1,哪行代码设置的-1再研究,但应该不是ngx_free_connection()函数设置的-1
{
//比如我们用epoll_wait取得三个事件,处理第一个事件时,因为业务需要,我们把这个连接关闭,那我们应该会把c->fd设置为-1;
//第二个事件照常处理
//第三个事件,假如这第三个事件,也跟第一个事件对应的是同一个连接,那这个条件就会成立;那么这种事件,属于过期事件,不该处理
//这里可以增加个日志,也可以不增加日志
ngx_log_error_core(NGX_LOG_DEBUG,0,"CSocekt::ngx_epoll_process_events()中遇到了fd=-1的过期事件:%p.",c);
continue; //这种事件就不处理即可
}
if(c->instance != instance) {
//--------------------以下这些说法来自于资料--------------------------------------
//什么时候这个条件成立呢?【换种问法:instance标志为什么可以判断事件是否过期呢?】
//比如我们用epoll_wait取得三个事件,处理第一个事件时,因为业务需要,我们把这个连接关闭【麻烦就麻烦在这个连接被服务器关闭上了】,但是恰好第三个事件也跟这个连接有关;
//因为第一个事件就把socket连接关闭了,显然第三个事件我们是不应该处理的【因为这是个过期事件】,若处理肯定会导致错误;
//那我们上述把c->fd设置为-1,可以解决这个问题吗? 能解决一部分问题,但另外一部分不能解决,不能解决的问题描述如下【这么离奇的情况应该极少遇到】:
//a)处理第一个事件时,因为业务需要,我们把这个连接【假设套接字为50】关闭,同时设置c->fd = -1;并且调用ngx_free_connection将该连接归还给连接池;
//b)处理第二个事件,恰好第二个事件是建立新连接事件,调用ngx_get_connection从连接池中取出的连接非常可能就是刚刚释放的第一个事件对应的连接池中的连接;
//c)又因为a中套接字50被释放了,所以会被操作系统拿来复用,复用给了b)【一般这么快就被复用也是醉了】;
//d)当处理第三个事件时,第三个事件其实是已经过期的,应该不处理,那怎么判断这第三个事件是过期的呢? 【假设现在处理的是第三个事件,此时这个 连接池中的该连接 实际上已经被用作第二个事件对应的socket上了】;
//依靠instance标志位能够解决这个问题,当调用ngx_get_connection从连接池中获取一个新连接时,我们把instance标志位置反,所以这个条件如果不成立,说明这个连接已经被挪作他用了;
//--------------------我的个人思考--------------------------------------
//如果收到了若干个事件,其中连接关闭也搞了多次,导致这个instance标志位被取反2次,那么,造成的结果就是:还是有可能遇到某些过期事件没有被发现【这里也就没有被continue】,照旧被当做没过期事件处理了;
//如果是这样,那就只能被照旧处理了。可能会造成偶尔某个连接被误关闭?但是整体服务器程序运行应该是平稳,问题不大的,这种漏网而被当成没过期来处理的的过期事件应该是极少发生的
ngx_log_error_core(NGX_LOG_DEBUG,0,"CSocekt::ngx_epoll_process_events()中遇到了instance值改变的过期事件:%p.",c);
continue; //这种事件就不处理即可
}
//能走到这里,我们认为这些事件都没过期,就正常开始处理
revents = m_events[i].events;//取出事件类型
//例如对方close掉套接字,这里会感应到【换句话说:如果发生了错误或者客户端断连】
if(revents & (EPOLLERR|EPOLLHUP)) {
//这加上读写标记,方便后续代码处理
revents |= EPOLLIN|EPOLLOUT; //EPOLLIN:表示对应的链接上有数据可以读出(TCP链接的远端主动关闭连接,也相当于可读事件,因为本服务器小处理发送来的FIN包)
//EPOLLOUT:表示对应的连接上可以写入数据发送【写准备好】
//ngx_log_stderr(errno,"2222222222222222222222222.");
}
//如果是读事件
if(revents & EPOLLIN) {
//一个客户端新连入,这个会成立
//c->r_ready = 1; //标记可以读;【从连接池拿出一个连接时这个连接的所有成员都是0】
(this->* (c->rhandler) )(c); //注意括号的运用来正确设置优先级,防止编译出错;【如果是个新客户连入
//如果新连接进入,这里执行的应该是CSocekt::ngx_event_accept(c)】
//如果是已经连入,发送数据到这里,则这里执行的应该是 CSocekt::ngx_wait_request_handler
}
//如果是写事件
if(revents & EPOLLOUT) {
//....待扩展
ngx_log_stderr(errno,"111111111111111111111111111111.");
}
} //end for(int i = 0; i < events; ++i)
return 1;
}
- (3)对于如何从空闲链中获取一个元素以及如何将一个不再使用的元素放回到空闲链中,可详细阅读ngx_c_socket_conn.cxx文件中的CSocket;:ngx_get_connection和CSocket::ngx_free_connection函数。这2个函数都很重要。
- (4)对监听端口要做一些额外的处理,所以使用一个for循环遍历并处理所有监听端口——把监听套接字与连接池中的某个元素绑定到一起。
“c->rhandler = &CSocekt::ngx_event_accept;”是一句重要代码。rhandler被定义为成员函数指针,而CSocket::ngx_event_accept是一个成员函数,该函数做什么先不管。
- (5)当一个客户端连入本服务器之后,操作系统如何通知程序有新用户连入了呢?必须把监听套接字相关的信息作为一个红黑树节点增加到红黑树中,当监听套接字收到连接时,系统才能通知程序。所以,调用自定义函数CSocket::ngx_epoll_add_event是最重要的。其中调用了系统函数epoll_ctl向红黑树中增加节点(同时增加到节点中的还有该socket连接感兴趣的事件)。注意,分析调用该自定义函数时所使用的参数,仔细阅读其中的代码和注释。
- ①用户三次握手连入时对于服务器是一种需要读的事件,所以增加的事件实际是EPOLLIN | EPOLLRDHUP(系统定义的事件)。
- ② CSocket::ngx_epoll_add_event的参数中使用了EPOLL_CTL_ADD表示向红黑树中增加节点。
通过上述一系列代码,当监听套接字上有可以读的事件(如三次握手的连入),该监听套接字就能够得到内核的通知
- (6)在CSocket::ngx_epoll_add_event函数中,有这样一行代码:
ev.data.ptr = (void *)( (uintptr_t)c | c->instance); 该技巧代码行源于官方Nginx源码。
目前是把一个socket和一个结构数组元素(连接池中的一个连接,也就是一块内存)绑到一起。将来该socket上来事件时,如何快速获取该socket所绑定的内存呢?如果让ev.data.ptr指向这块内存,将来就可以从ev.data.ptr中获取该内存。所以,上面这行代码,可以看成做了2件事。- ①第1件事。“ev.data.ptr =c;”,将来通过ev.data.ptr就能获取socket所绑定的内存,该内存中的数据就可以为程序员所用。这就是epoll的友好之处——让程序员指定一块自己的内存,将来socket上产生事件的时候,程序员就能够获取自己指定的这块内存。
- ②第2件事。注意“|c> instance”这个写法,这是个小技巧,在ngx_e_socket.h中,结构ngx_connection_s里定义的“unsigned instance:1;”只占了1位(1/8字节),要么是0,要么是1。代码中的c是个指针,指针用于指向一个地址,但也可以将其看成一个数字。但是指针这种数字有个特点,其最末尾一位(二进制位)绝对是个0,不会是个1(这主要是因为内存地址一般是4字节或者8字节对齐的 )。基于这点,最末尾这位拿出来保存一个只有一个位大小的变量值还是可以的,于是,就拿来保存了变量c->instance的值。所以代码“ev.data.ptr =(void*)((uintptr_t)c | c>instance);”同时把一个地址和一个位信息保存到了ev.data.ptr,将来可以从ev.data.ptr中同时取出地址(内存池中元素代表的那部分内存)以及一个位信息。
指针最末尾一位绝对是0


下面补充讲解一个乌班图Linux操作系统的小知识。
在SecureCRT中连入乌班图Linux虚拟机后观察,一般来说命令行提示符都是“$”,表示当前的权限是普通用户权限。可以进人root权限(最高权限),root权限的提示符是“#”符。
root权限如何进入呢,可以输入如下命令:
ubuntu@VM-20-6-ubuntu:~$ sudo su

因为本项目中bind等函数的执行需要管理员权限,所以必须使用sudo来启动本项目。

ubuntu@VM-20-6-ubuntu:~$ ps -eo pid,ppid,sid,tty,pgrp,comm,cmd,stat | grep -E 'bash|PID|nginx'

根据现在的代码,本项目当前有3个进程都在监听80和443端口。
查看某个端口被哪些进程所监听(占用)需要root权限(否则无法列出结果)或使用sudo。在管理员权限的SecureCRT窗口中执行如下命令:
root@VM-20-6-ubuntu:/home/ubuntu# lsof -i:80

lsof(list open files)是用于列出当前系统打开文件的工具。从图中可以看到,这3个进程(1个master进程和2个worker进程)都在监听80端口,也都在监听443端口。
root@VM-20-6-ubuntu:/home/ubuntu# netstat -tunlp | grep 80

netstat命令的问题在于只能显示正在监听该端口的进程中的某一个,不能显示所有。
- (1) 调用epoll_create函数,同时针对每个监听套接字,调用epoll_ctl把读事件增加到红黑树中,这样,当客户端连人时,本项目(服务端程序)才能通过后续的epoll_wait得到通知(感知到)。
- (2) 连接池技巧。每个套接字需要绑定一个连接池中的连接(一个结构数组中的元素),如何快速地从该连接池中找到一个空闲连接分配给该套接字呢?引入了2个函数:CSocket::ngx_get_connection和CSocket::ngx_free_connection。找空闲连接这段代码编写得非常有技巧,
- ①epoll技术原理就是:创建红黑树,把套接字感兴趣的事件作为红黑树的节点加到红黑树中,接收到事件时,有事件的套接字会被内核放进双向队列中。
- ②连接池(结构数组)的设计中,数组元素必然在数组中,这就相当于epoll中的红黑树,然后专门用该数组中空闲的元素构成一个单向链表从而达到极快速找到空闲元素(只需从空闲链表的链表头拿出该元素即可)的目的。这里这个单向链表是不是跟epoll中的双向链表设计很类似呢?
- ③同时传递指针和一个二进制数字技巧:在CSocket::ngx_epoll_add_event中,利用了指针的最后一个二进制位肯定不是1的技巧,把一个额外的二进制位传递给一个void *。后续看 CSocket::ngx_epoll_process_events时,会看到如何从void *中把指针及该二进制位拆解出来。这种技巧,如果不看到实际的项目,可能很难学到。
ngx_epolL_init函数的调用
对CSocket::ngx_epoll_init函数的调用,正是在ngx_worker_process_init函数(worker子进程执行分支)中进行的。 本项目中,真正对外通信并完成业务的是worker进程而不是master进程,master进程本身只是一个管理进程,所以,CSocket::nginx_epoll_init函数的调用肯定是要放入子进程执行分支中的。

也就是说,每个worker子进程都会执行该函数,通过该函数来初始化epoll,为后续客户端连接做准备。
ngx_process_cycle.cxx
//和开启子进程相关
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h> //信号相关头文件
#include <errno.h> //errno
#include <unistd.h>
#include "ngx_func.h"
#include "ngx_macro.h"
#include "ngx_c_conf.h"
#include "ngx_global.h"
#include "ngx_c_socket.h"
//函数声明
static void ngx_start_worker_processes(int threadnums);
static int ngx_spawn_process(int threadnums,const char *pprocname);
static void ngx_worker_process_cycle(int inum,const char *pprocname);
static void ngx_worker_process_init(int inum);
//变量声明
static u_char master_process[] = "master process";
extern CSocekt g_socket;
//描述:创建worker子进程
void ngx_master_process_cycle() {
sigset_t set; //信号集
sigemptyset(&set); //清空信号集
//下列这些信号在执行本函数期间不希望收到 (保护不希望由信号中断的代码临界区)
//建议fork()子进程时学习这种写法,防止信号的干扰;
sigaddset(&set, SIGCHLD); //子进程状态改变
sigaddset(&set, SIGALRM); //定时器超时
sigaddset(&set, SIGIO); //异步I/O
sigaddset(&set, SIGINT); //终端中断符
sigaddset(&set, SIGHUP); //连接断开
sigaddset(&set, SIGUSR1); //用户定义信号
sigaddset(&set, SIGUSR2); //用户定义信号
sigaddset(&set, SIGWINCH); //终端窗口大小改变
sigaddset(&set, SIGTERM); //终止
sigaddset(&set, SIGQUIT); //终端退出符
//.........可以根据开发的实际需要往其中添加其他要屏蔽的信号......
//设置,此时无法接受的信号;阻塞期间,你发过来的上述信号,多个会被合并为一个,暂存着,等你放开信号屏蔽后才能收到这些信号。。。
if (sigprocmask(SIG_BLOCK, &set, NULL) == -1)
//第一个参数用了SIG_BLOCK表明设置 进程 新的信号屏蔽字 为 “当前信号屏蔽字 和 第二个参数指向的信号集的并集
{
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_master_process_cycle()中sigprocmask()失败!");
}
//即便sigprocmask失败,程序流程 也继续往下走
//首先设置主进程标题---------begin
size_t size;
int i;
size = sizeof(master_process); //注意这里用的是sizeof,所以字符串末尾的\0是被计算进来了的
size += g_argvneedmem; //argv参数长度加进来
if(size < 1000) //长度小于这个,才设置标题
{
char title[1000] = {0};
strcpy(title, (const char *)master_process); //"master process"
strcat(title, " "); //跟一个空格分开一些,清晰 //"master process "
for (i = 0; i < g_os_argc; i++) //"master process ./nginx"
{
strcat(title, g_os_argv[i]);
}//end for
ngx_setproctitle(title); //设置标题
ngx_log_error_core(NGX_LOG_NOTICE,0,"%s %P 启动并开始运行......!",title,ngx_pid); //设置标题时顺便记录下来进程名,进程id等信息到日志
}
//首先设置主进程标题---------end
//从配置文件中读取要创建的worker进程数量
CConfig *p_config = CConfig::GetInstance(); //单例类
//从配置文件中得到要创建的worker进程数量
int workprocess = p_config->GetIntDefault("WorkerProcesses", 1);
ngx_start_worker_processes(workprocess); //这里要创建worker子进程
//创建子进程后,父进程的执行流程会返回到这里,子进程不会走进来
sigemptyset(&set); //信号屏蔽字为空,表示不屏蔽任何信号
//sigaddset(&set, SIGHUP); //-1
//setvbuf(stdout,NULL,_IONBF,0); //这个函数. 直接将printf缓冲区禁止, printf就直接输出了。
for ( ;; ) {
// usleep(100000);
// ngx_log_error_core(0, 0, "haha--这是父进程, pid为 %P", ngx_pid);
//a)根据给定的参数设置新的mask 并阻塞当前进程【因为是个空集,所以不阻塞任何信号】
//b)此时,一旦收到信号,便恢复原先的信号屏蔽【我们原来的mask在上边设置的,阻塞了多达10个信号,从而保证我下边的执行流程不会再次被其他信号截断】
//c)调用该信号对应的信号处理函数
//d)信号处理函数返回后,sigsuspend返回,使程序流程继续往下走
//printf("for进来了!\n"); //发现,如果print不加\n,无法及时显示到屏幕上,是行缓存问题,以往没注意;可参考https://blog.csdn.net/qq_26093511/article/details/53255970
sigsuspend(&set);
//阻塞在这里,等待一个信号,此时进程是挂起的,不占用cpu时间,只有收到信号才会被唤醒(返回);
//此时master进程完全靠信号驱动干活
// printf("执行到sigsuspend()下边来了\n");
// ngx_log_stderr(0, "haha--这是父进程, pid为%P", ngx_pid);
// printf("master进程休息1秒\n");
sleep(1); //休息1秒
//以后扩充.......
}// end for(;;)
return;
}
//描述:根据给定的参数创建指定数量的子进程,因为以后可能要扩展功能,增加参数,所以单独写成一个函数
//threadnums:要创建的子进程数量
static void ngx_start_worker_processes(int threadnums) {
int i;
//master进程在走这个循环,来创建若干个子进程
for (i = 0; i < threadnums; i++) {
ngx_spawn_process(i, "worker process");
} //end for
return;
}
//描述:产生一个子进程
//inum:进程编号【0开始】
//pprocname:子进程名字"worker process"
static int ngx_spawn_process(int inum, const char *pprocname) {
pid_t pid;
pid = fork(); //fork()系统调用产生子进程
switch (pid) //pid判断父子进程,分支处理
{
case -1: //产生子进程失败
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_spawn_process()fork()产生子进程num=%d, procname=\"%s\"失败!", inum, pprocname);
return -1;
case 0: //子进程分支
ngx_parent = ngx_pid; //因为是子进程了,所有原来的pid变成了父pid
ngx_pid = getpid(); //重新获取pid,即本子进程的pid
ngx_worker_process_cycle(inum, pprocname);
//希望所有worker子进程,在这个函数里不断循环着不出来,也就是说,子进程流程不往下边走;
break;
default: //这个应该是父进程分支,直接break;,流程往switch之后走
break;
}//end switch
//父进程分支会走到这里,子进程流程不往下边走-------------------------
//若有需要,以后再扩展增加其他代码......
return pid;
}
//描述:worker子进程的功能函数,每个woker子进程,就在这里循环着了(无限循环【处理网络事件和定时器事件以对外提供web服务】)
// 子进程分叉才会走到这里
//inum:进程编号【0开始】
static void ngx_worker_process_cycle(int inum, const char *pprocname) {
//重新为子进程设置进程名,不要与父进程重复------
ngx_worker_process_init(inum);
ngx_setproctitle(pprocname); //设置标题
ngx_log_error_core(NGX_LOG_NOTICE, 0, "%s %P 启动并开始运行......!", pprocname, ngx_pid); //设置标题时顺便记录下来进程名,进程id等信息到日志
//暂时先放个死循环,我们在这个循环里一直不出来
// setvbuf(stdout, NULL, _IONBF, 0); //这个函数. 直接将printf缓冲区禁止, printf就直接输出了。
for(;;) {
//先sleep一下 以后扩充.......
// printf("worker进程休息1秒");
// fflush(stdout); //刷新标准输出缓冲区,把输出缓冲区里的东西打印到标准输出设备上,则printf里的东西会立即输出;
sleep(1); //休息1秒
//usleep(100000);
// ngx_log_error_core(0, 0, "good--这是子进程, 编号为%d, pid为%P!", inum, ngx_pid);
//printf("1212");
//if(inum == 1)
//{
//ngx_log_stderr(0,"good--这是子进程,编号为%d,pid为%P",inum,ngx_pid);
//printf("good--这是子进程,编号为%d,pid为%d\r\n",inum,ngx_pid);
//ngx_log_error_core(0,0,"good--这是子进程,编号为%d",inum,ngx_pid);
//printf("我的测试哈inum=%d",inum++);
//fflush(stdout);
//}
// ngx_log_stderr(0, "good--这是子进程, 编号为%d, pid为%P", inum, ngx_pid);
//ngx_log_error_core(0,0,"good--这是子进程,编号为%d,pid为%P",inum,ngx_pid);
} //end for(;;)
return;
}
//描述:子进程创建时调用本函数进行一些初始化工作
static void ngx_worker_process_init(int inum) {
sigset_t set; //信号集
sigemptyset(&set); //清空信号集
if (sigprocmask(SIG_SETMASK, &set, NULL) == -1) //原来是屏蔽那10个信号【防止fork()期间收到信号导致混乱】,现在不再屏蔽任何信号【接收任何信号】
{
ngx_log_error_core(NGX_LOG_ALERT, errno, "ngx_worker_process_init()中sigprocmask()失败!");
}
//如下这些代码参照官方nginx里的ngx_event_process_init()函数中的代码
g_socket.ngx_epoll_init();
//初始化epoll相关内容,同时 往监听socket上增加监听事件,从而开始让监听端口履行其职责
//g_socket.ngx_epoll_listenportstart();//往监听socket上增加监听事件,从而开始让监听端口履行其职责【如果不加这行,虽然端口能连上,但不会触发ngx_epoll_process_events()里边的epoll_wait()往下走】
//....将来再扩充代码
//....
return;
}
之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!