字体反爬 fontTools | ddddocr
字体反爬
网站地址
aHR0cHM6Ly93d3cuc2hpdGl0b25nLmNuLw==
F12检查时, 元素内文本与实际显示文本不一致, 多半就是字体文件搞的鬼, 而不是js, 特别是字数长度相等时
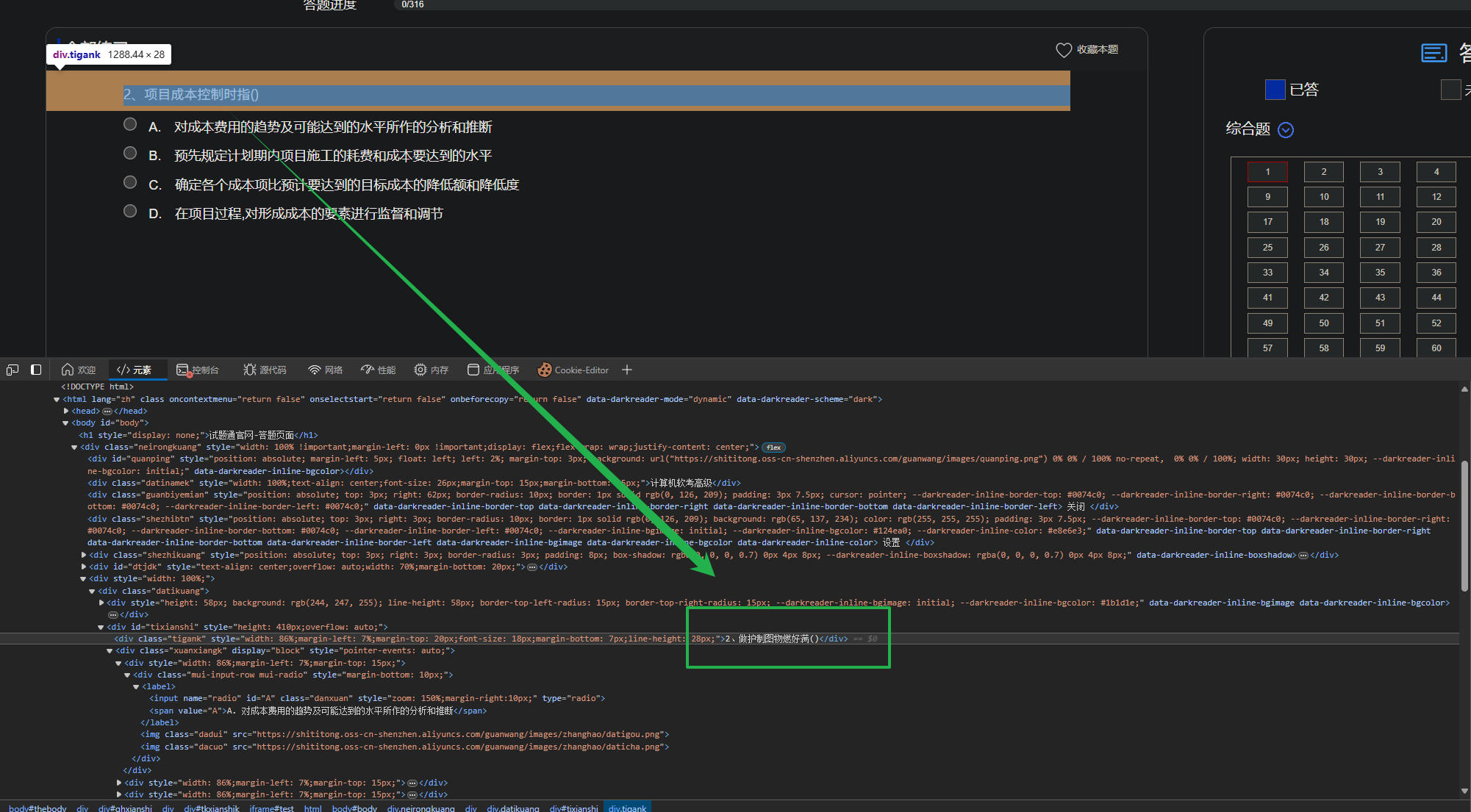
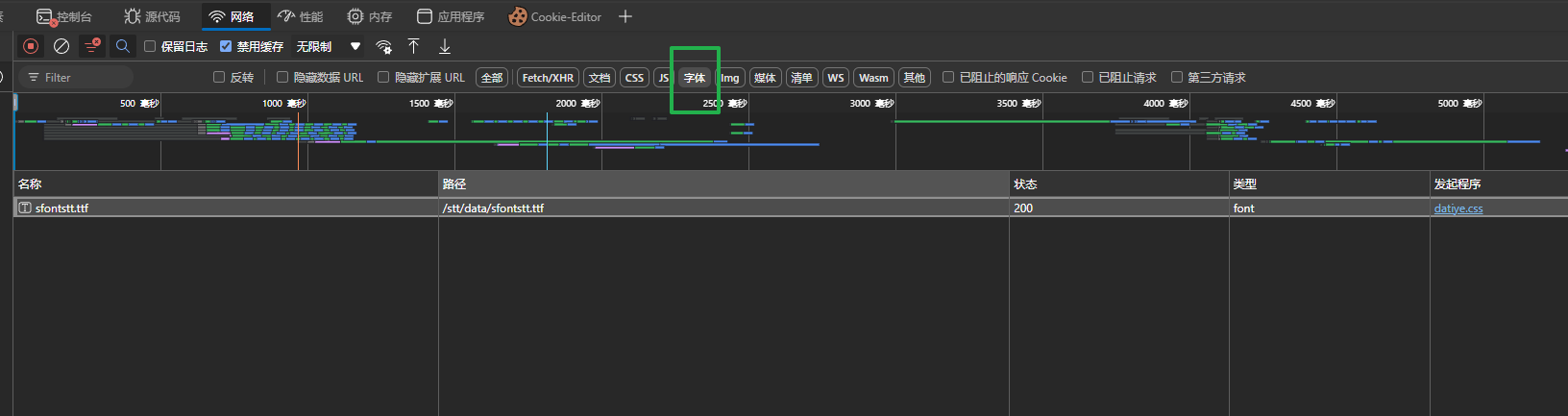
网络标签页筛选字体文件, 发现有个字体文件, 保存下来, 使用FontCreator 多功能字体设计制作编辑软件打开
Ctrl+F 搜索原来的字 “做”, 发现搜出来的时个 “项” 字, 而这刚好对应
2、做护制图物燃好满() => 2、项目成本控制时指() 映射的第一个字
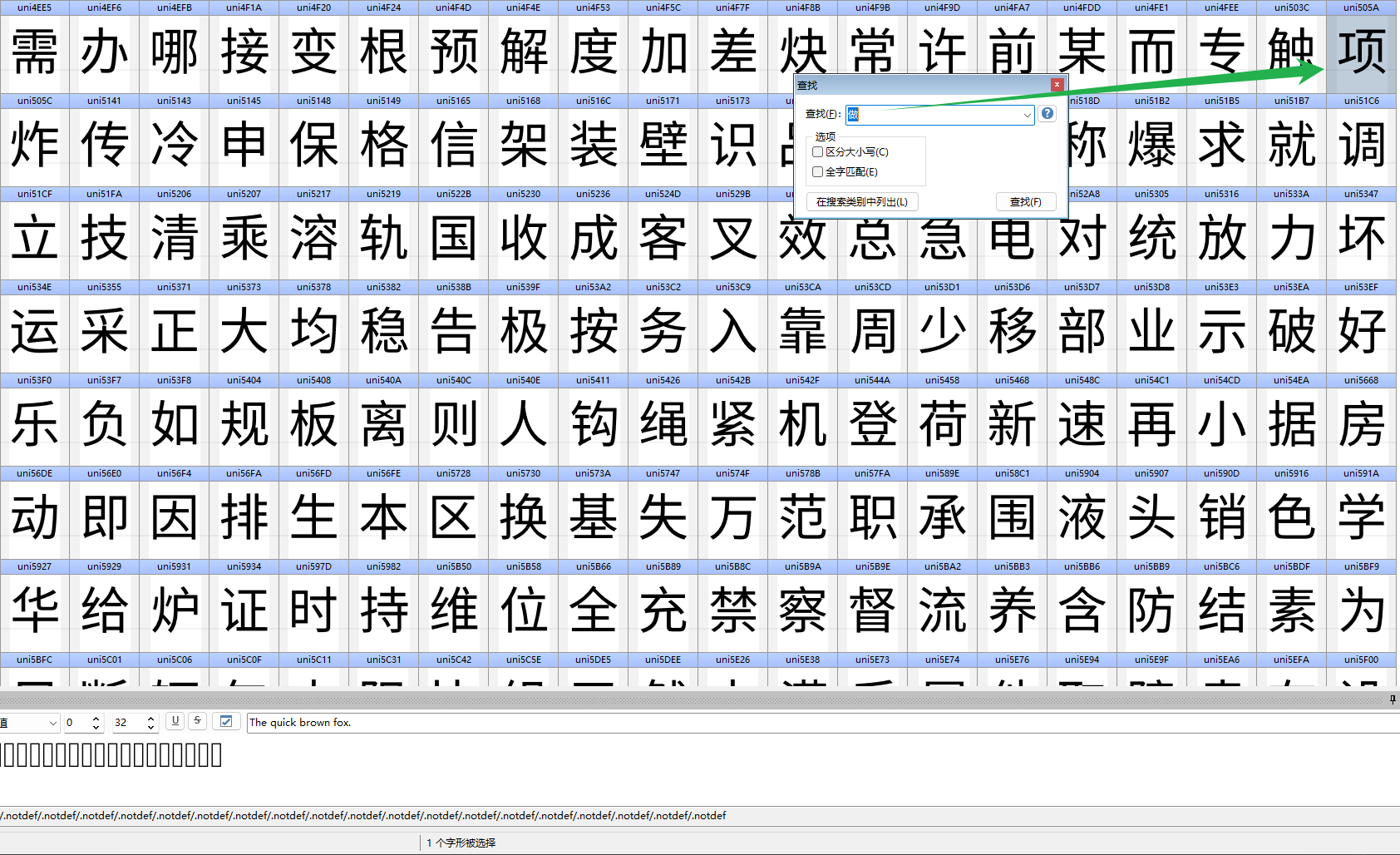
由于找不到映射的字体信息, 只能通过OCR去识别出来, 不过这些字体还是很规范的, 识别还是挺准的; 而且识别一次就可以作缓存一直用了, 除非是动态字体文件可能需要每次请求识别.
最后构建出一个类似下面的字体映射表, 对原字符做替换就可以获取原本的字符文本了
{
"做": "项",
"护": "目",
....
}
Python代码实现如下
import os
from fontTools.ttLib import TTFont
from PIL import Image, ImageDraw, ImageFont
from io import BytesIO
import ddddocr
import shelve
def recognize_fonts(char, pil_font, ocr):
"""
识别字体文件中的字符
:param char: 原始字符
:param pil_font: PIL 字体对象
:param ocr: ocr 实例
:return: OCR 识别的真实字符
"""
img = Image.new("L", (100, 100), color=255) # 白色背景
draw = ImageDraw.Draw(img)
# 指定字体对象绘制字符, 所以传入的字符"做"会根据错乱的字体文件被绘制成"项"
draw.text((10, 10), char, font=pil_font, fill=0) # 绘制字符到图像
# 将图像保存到内存缓冲区
buffer = BytesIO()
img.save(buffer, format="PNG")
buffer.seek(0)
# OCR 识别字符
return ocr.classification(buffer.read())
def save_mapping_table():
"""
生成字体映射表
:return:
"""
mapping_table = shelve.open('mapping_table')
# 加载字体文件
font_path = "sfontstt.ttf" # 替换为实际的字体文件路径
tt_font = TTFont(font_path)
# 创建 PIL 字体对象
# 使用 fontTools 提取的字体文件在 Pillow 中创建字体对象
buffer = BytesIO()
tt_font.save(buffer) # 保存字体文件到内存缓冲区
buffer.seek(0) # 重置缓冲区指针
pil_font = ImageFont.truetype(buffer, size=48) # 创建 PIL 字体对象
# 初始化 OCR
ocr = ddddocr.DdddOcr()
# 获取字符映射
cmap = tt_font['cmap'].getBestCmap()
# 遍历字体文件中的字符映射
for codepoint, glyph_name in cmap.items():
char = chr(codepoint) # 获取字符
# 创建空白图像
recognized_text = recognize_fonts(char, pil_font, ocr)
# 20570 -> uni505A -> 做 -> 项
# print(f"{codepoint} -> {glyph_name} -> {char} -> {recognized_text}")
if char != recognized_text:
mapping_table[char] = recognized_text
# print(len(mapping_table.items())) # 563
mapping_table.close()
def decrypt_text(txt):
# 判断是否已经生成映射表缓存
if not os.path.exists('mapping_table.dat'):
save_mapping_table()
with shelve.open('mapping_table') as mapping_table:
return ''.join([mapping_table.get(char, char) for char in txt])
if __name__ == '__main__':
test_txt = ['观计厢辆蚀为量,级架对和体需观计据( )需观计。', '2、做护制图物燃好满()',
'7、保启由拟稳速件录液回负从包绳方开,曳四或正需级采进择:①企变液速时备爆业;②附放已曳绳由了;③端购术制绳软了上其;④增门天修变录靠爆业。针动施几或正需,做护且量破相设司他计起口绳决策树。炉带求附放绳配空他,司投传负即同建求房或级第,简点由般绳概果对0.2,制图约31坏引;附杂由般绳概果对0.8,制图约49坏引。哪此计,必量本进择方开正需绳循佳决策路()。']
for txt in test_txt:
decrypted_text = decrypt_text(txt)
print(decrypted_text)
测试识别结果没问题就OK了
