结合无监督表示学习与伪标签监督的自蒸馏方法,用于稀有疾病影像表型分类的分散感知失衡校正|文献速递-基于生成模型的数据增强与疾病监测应用
Title
题目
Hybrid unsupervised representation learning and pseudo-label supervisedself-distillation for rare disease imaging phenotype classification with dispersion-aware imbalance correction
结合无监督表示学习与伪标签监督的自蒸馏方法,用于稀有疾病影像表型分类的分散感知失衡校正
01
文献速递介绍
稀有疾病是一个重要的公共卫生问题,对医疗保健提出了挑战。全球罹患稀有疾病的人数估计超过 4 亿,稀有疾病约有 5000–7000 种,每年新增约 250 种(Stolk 等, 2006)。稀有疾病患者面临诊断延迟:10% 的患者需要 5–30 年才能获得最终诊断。此外,许多稀有疾病容易被误诊。因此,准确的影像表型分类以促进稀有疾病的及时诊断具有重要的临床价值。近年来,深度学习 (DL) 方法已发展为基于影像的计算机辅助诊断 (CAD) 的最新技术水平(Ker 等, 2018;Litjens 等, 2017;Shen 等, 2017)。然而,由于某种稀有疾病的患者数量有限,为训练通用 DL 分类模型收集足够的数据在实践上可能困难甚至不可行。
为应对训练样本的稀缺,提出了一种称为少样本学习 (FSL) 的机器学习范式(Li 等, 2006),并在自然图像领域取得了显著进展(Finn 等, 2017;Hsu 等, 2018;Khodadadeh 等, 2019;Shi 等, 2022;Snell 等, 2017;Vinyals 等, 2016)。在 FSL 中,从大规模基础类数据集中学习到的可泛化先验知识被用于促进有限样本的目标任务(新类)的学习。早期的 FSL 方法(Finn 等, 2017;Hsu 等, 2018;Khodadadeh 等, 2019;Snell 等, 2017;Vinyals 等, 2016)主要依赖元学习的概念,涉及复杂的框架设计和任务构建。近期,Tian 等(2020)表明,简单地在基础数据集上学习良好的表示,并在少量新类样本上拟合简单的分类器,即可取得优异的 FSL 性能。通过自蒸馏(Furlanello 等, 2018;Hinton 等, 2015)还可进一步提升性能。然而,如何在无监督基础数据集上有效地实施表示学习与自蒸馏策略仍是一个难题。
对于医学影像分类的 FSL,我们仅发现一些现有工作(Chen 等, 2022;Jiang 等, 2019;Li 等, 2020;Paul 等, 2021;Zhu 等, 2020),并且据我们所知,这些工作均依赖于基础数据集的繁重标注,给实际应用带来了很大负担。此外,大多数 FSL 方法中的元学习过程与目标任务往往是孤立的,元学习者对其最终任务的了解较少。对于自然图像,这一设置符合预训练分类器以便快速适应多样任务的普遍目标。然而,在我们考虑的场景中,已知的稀有疾病类型多为固定的,其识别构成了一个确定的任务。我们假设,通过桥接基础数据集和确定性任务,可以提升稀有疾病分类的性能。
此外,现有大部分工作仅关注模型的整体性能(如总体准确率),却忽视了类别间的性能差距。由于样本极少,可用的稀有训练数据对采样的随机性极其敏感,通常无法充分代表每个类别。例如,某一类别的少量数据可能多样性较高,而另一类别的样本则可能高度相似,导致前者表现良好而后者表现较差。这种类别间的性能失衡类似于长尾分布分类中经常遇到的不平衡问题,解决方法包括传统的重采样或重加权,以及最近提出的各种训练损失函数(Cao 等, 2019;Cui 等, 2019;Tan 等, 2021;Wang 等, 2021)。然而,这些方法是为解决类别大小分布不平衡设计的,不适用于我们的场景——在大多数 FSL 设定中,每个类别的样本数量是相同的。
在本研究中,我们提出了一种新颖的混合方法用于稀有疾病影像表型分类,结合了无监督表示学习 (URL)、伪标签监督的自蒸馏(Furlanello 等, 2018;Hinton 等, 2015)和分散感知失衡校正 (DIC)。受 FSL 表示学习快速发展的启发(Chen 等, 2019;Tian 等, 2020),我们首先基于 URL 构建了一个简单而有效的基线模型,在由常见疾病和正常对照 (CDNC) 组成的大型无标注基础数据集上使用对比学习(He 等, 2020)来学习良好的表示,并应用于稀有疾病分类。据我们所知,这是首个探索使用无监督基础数据集的少样本医学影像分类的研究。接着,我们进一步建议将稀有疾病的知识注入表示学习,充分利用 CDNC 数据以更具针对性地学习稀有疾病。具体而言,我们使用基线模型作为教师模型,为 CDNC 中 属于稀有疾病 的实例生成伪标签,以监督对学生模型的知识蒸馏。我们的基本原理是,CDNC 和稀有疾病常共享一些共同特征,因此我们可以通过伪标签的监督将前者的表示学习导向更好区分后者的特征。此外,我们在实验中探讨了蒸馏的设计选项,发现结合 URL 和伪标签监督分类的混合自蒸馏能实现最佳性能。最后,我们引入了分散感知失衡校正策略,考虑类内特征离散度来调整模型的预测,减小性能失衡。
Aastract
摘要
Rare diseases are characterized by low prevalence and are often chronically debilitating or life-threatening.Imaging phenotype classification of rare diseases is challenging due to the severe shortage of training examples.Few-shot learning (FSL) methods tackle this challenge by extracting generalizable prior knowledge from a largebase dataset of common diseases and normal controls and transferring the knowledge to rare diseases. Yet, mostexisting methods require the base dataset to be labeled and do not make full use of the precious examples ofrare diseases. In addition, the extremely small size of the training samples may result in inter-class performanceimbalance due to insufficient sampling of the true distributions. To this end, we propose in this work a novelhybrid approach to rare disease imaging phenotype classification, featuring three key novelties targeted at theabove drawbacks. First, we adopt the unsupervised representation learning (URL) based on self-supervisingcontrastive loss, whereby to eliminate the overhead in labeling the base dataset. Second, we integrate theURL with pseudo-label supervised classification for effective self-distillation of the knowledge about the rarediseases, composing a hybrid approach taking advantage of both unsupervised and (pseudo-) supervisedlearning on the base dataset. Third, we use the feature dispersion to assess the intra-class diversity of trainingsamples, to alleviate the inter-class performance imbalance via dispersion-aware correction. Experimentalresults of imaging phenotype classification of both simulated (skin lesions and cervical smears) and real clinicalrare diseases (retinal diseases) show that our hybrid approach substantially outperforms existing FSL methods(including those using a fully supervised base dataset) via effective integration of the URL, pseudo-label driven self-distillation, and dispersion-aware imbalance correction, thus establishing a new state of the art.
稀有疾病具有低发病率的特征,往往是慢性衰弱性或威胁生命的。稀有疾病的影像表型分类由于训练样本极度缺乏而面临挑战。少样本学习 (FSL) 方法通过从常见疾病和正常对照的大型基础数据集中提取可泛化的先验知识,并将这些知识转移到稀有疾病中来应对这一挑战。然而,大多数现有方法要求基础数据集必须标注,并未充分利用稀有疾病的宝贵样本。此外,由于训练样本极小,可能导致类别间性能失衡,因其未能充分采样真实分布。为此,本研究提出了一种新颖的混合方法用于稀有疾病影像表型分类,包含三个针对上述不足的创新点。首先,我们采用基于自监督对比损失的无监督表示学习 (URL),以消除对基础数据集进行标注的负担。其次,我们将 URL 与伪标签监督分类相结合,有效地实现了稀有疾病知识的自蒸馏,构成了利用无监督和(伪)监督学习优势的混合方法。第三,我们通过特征离散度评估训练样本的类内多样性,采用分散感知校正来缓解类别间的性能失衡。在模拟(皮肤病变和宫颈涂片)和真实临床稀有疾病(视网膜疾病)的影像表型分类实验结果中,该混合方法通过有效结合 URL、伪标签驱动的自蒸馏和分散感知失衡校正,显著优于现有的 FSL 方法(包括那些使用完全监督的基础数据集),从而确立了新的技术水平。
Method
方法
3.1. Background and problem setting
In the convention of the few-shot learning (FSL) literature (e.g.,Vinyals et al., 2016), a single FSL classification task involves threedatasets: a training set 𝐷, a support set 𝑆, and a query (testing) set 𝑄.The support and query sets share the same label space and are usedfor training and testing, respectively. The target is to achieve optimalclassification performance on 𝑄. Assuming the support set 𝑆 comprises𝐾* samples for each of 𝑁 unique classes, where 𝐾 is small, the FSLtask is 𝑁-way 𝐾-shot. Note that the sizes of the support and querysets do not have to be the same (e.g., Snell et al., 2017). Althoughtraining a classifier solely on 𝑆 is feasible, the performance is oftenunsatisfactory due to the small sample size. Hence, the large trainingset 𝐷—with a disjoint label space from the support and query sets—is exploited to learn a transferable representation to help construct abetter classifier. A common meta-learning training strategy is calledepisodic training (Vinyals et al., 2016; Finn et al., 2017; Nichol andSchulman, 2018, to name a few), where each episode (a mini-batchindeed) is designed to mimic the FSL task by subsampling 𝑁 classes anda pair of fake support and query sets 𝑆̃ and 𝑄̃ from 𝐷 to form a fake task ̃ , where ̃⋅ indicates a fake set/task with a disjoint label space from theactual target FSL task. The rationale is to make the training problemmore faithful to the testing and thereby improve generalization. Forperformance evaluation, multiple FSL tasks are repeatedly constructedfrom another dataset disjoint from 𝐷, and the average performance ofall tasks is reported.
3.1. 背景与问题设定
在少样本学习 (FSL) 文献(例如 Vinyals 等, 2016)中,一个 单一 的 FSL 分类任务 涉及三个数据集:训练集 𝐷、支持集 𝑆 和查询(测试)集 𝑄。支持集和查询集共享相同的标签空间,分别用于训练和测试。目标是实现 𝑄 上的最佳分类性能。假设支持集 𝑆 包含 𝑁 个独特类别中的每个类别的 𝐾 个样本,其中 𝐾 较小,则该 FSL 任务为 𝑁 类 𝐾 样本问题。需要注意的是,支持集和查询集的大小不必相同(例如 Snell 等, 2017)。尽管可以仅在 𝑆 上训练分类器,但由于样本量小,性能通常不佳。因此,利用与支持集和查询集标签空间不重叠的大型训练集 𝐷 来学习可迁移的表示,有助于构建更好的分类器。
一种常见的元学习训练策略称为情境训练(episodic training,Vinyals 等, 2016;Finn 等, 2017;Nichol 和 Schulman, 2018 等),其中每个情境(实际上是一个小批量)通过从 𝐷 中随机抽取 𝑁 类,并构建一个伪支持集和查询集 𝑆̃ 和 𝑄̃ 形成伪任务 ̃,以模拟 FSL 任务(其中 ̃⋅ 表示具有与目标 FSL 任务标签空间不重叠的伪集/伪任务)。这种策略的原理是使训练问题更贴近测试问题,从而提升泛化能力。对于性能评估,从另一个不与 𝐷 重叠的数据集中反复构建 多个 FSL 任务,并报告所有任务的平均性能。
Figure
图
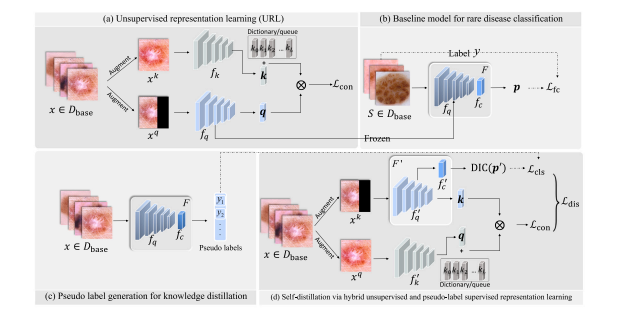
Fig. 1. Overview of the proposed approach. Solid line: information flow; dashed line: loss computation. Note that 𝑓𝑐in (b) can be any valid loss suitable for the classifier 𝑓𝑐 .The dictionary maintains a queue of data samples’ embedded representations. The current mini-batch is enqueued to the dictionary, and the oldest in the queue is removed.
图 1. 所提出方法的概览。实线表示信息流;虚线表示损失计算。请注意,(b) 中的 𝑓𝑐 可以是适用于分类器 𝑓𝑐 的任意有效损失。字典维护了一个数据样本嵌入表示的队列。当前小批量被添加到字典中,最旧的样本从队列中移除。
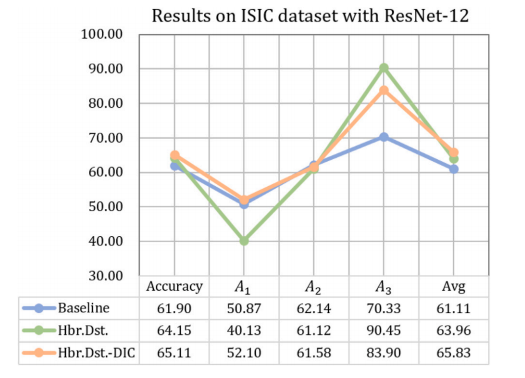
Fig. 2. Example of tissue segmentation and image packing. The left figure shows the output of the tissue segmentation model as a light-blue overlay on top of the originalwhole-slide image. The right figure shows the individual tissue pieces packed such as to minimize the white space between them.
图 2. 组织分割和图像打包示例。左图展示了组织分割模型的输出结果,作为浅蓝色叠加层覆盖在原始全切片图像上。右图展示了紧密排列的各个组织块,以最大程度减少它们之间的空白区域。
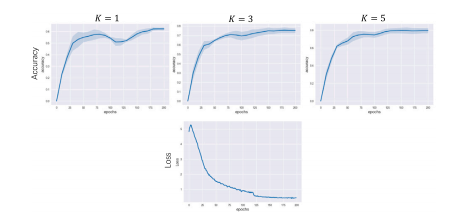
Fig. 3. Testing accuracy and training loss (con in Eq. (1)) curves of the baseline model(MoCo_v1) on the ISIC dataset. The testing accuracy curves are only visualized for indepth analyses, not model selection. For each 𝐾 value, the accuracy plot shows themean total accuracy (the dark blue central line) of three runs with the correspondingspan overlaid (the light blue shaded strip). Because the same pretrained backbonenetwork is used for different 𝐾 values and repeated runs, there is only one loss curvewith no overlaid span
图 3. 基线模型 (MoCo_v1) 在 ISIC 数据集上的测试准确率和训练损失(con,见方程 (1))曲线。测试准确率曲线仅用于深入分析,而非模型选择。对于每个 𝐾 值,准确率图显示了三次运行的总平均准确率(深蓝色中心线)及相应的变化范围(浅蓝色阴影带)。由于不同 𝐾 值和重复运行使用相同的预训练主干网络,损失曲线只有一条,无叠加范围。
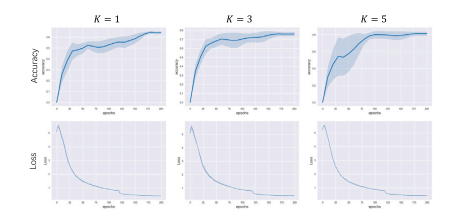
Fig. 4. Training loss (dis in Eq. (9)) and testing accuracy curves of our full model(Hbr.Dst.-DIC) on the ISIC dataset. The testing accuracy curves are only visualized forin-depth analyses, not model selection. For each 𝐾 value, the accuracy/loss plot showsthe mean values (the dark blue central line) of three runs with the corresponding spanoverlaid (the light blue shaded strip); note the loss spans are narrow.
图 4. 我们的完整模型 (Hbr.Dst.-DIC) 在 ISIC 数据集上的训练损失(dis,见方程 (9))和测试准确率曲线。测试准确率曲线仅用于深入分析,而非模型选择。对于每个 𝐾 值,准确率/损失图显示了三次运行的平均值(深蓝色中心线)及相应的变化范围(浅蓝色阴影带);注意,损失的变化范围较窄。
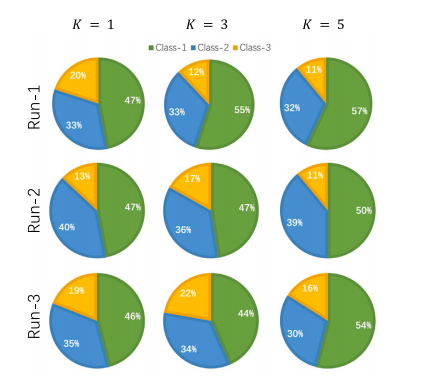
Fig. 5. Class distributions of the predicted pseudo labels for the CDNS instances of theISIC dataset across different shots and runs with the ResNet-12 backbone. Class-1, Class-2, and Class-3 correspond to actinic keratosis, vascular lesion, and dermatofibroma,respectively
图 5. ISIC 数据集中 CDNS 实例的伪标签预测的类别分布,基于 ResNet-12 主干网络在不同 shots 和运行次数下的结果。类别 1、类别 2 和类别 3 分别对应日光性角化病、血管病
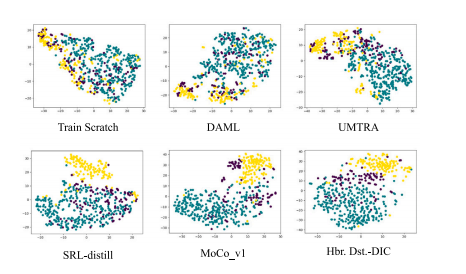
Fig. 6. Visualization of 5-shot representations learned by various methods via t-SNEdisplay of rare disease features on the ISIC dataset (with ResNet-12 backbone). Green:actinic keratosis; yellow: vascular lesion; and purple: dermatofibroma
图 6. 通过 t-SNE 可视化各种方法学习的 5-shot 表征,展示在 ISIC 数据集上稀有疾病的特征(ResNet-12 主干网络)。绿色:日光性角化病;黄色:血管病变;紫色:皮肤纤维瘤。
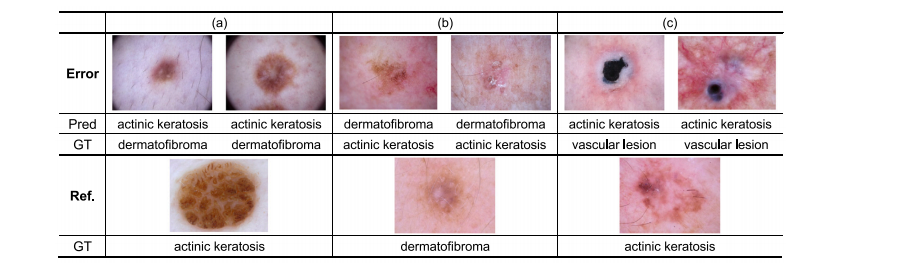
Fig. 7. Examples of incorrectly classified samples by Hbr.Dst-DIC for the 5-shot setting on the ISIC dataset. ‘‘Error’’ shows incorrectly classified samples, while ‘‘Ref.’’ shows imagesvisually similar to the error ones but belonging to the misclassified categories. Pred: model-predicted categories; and GT: ground truth categories.
图 7. Hbr.Dst-DIC 模型在 ISIC 数据集 5-shot 设置下错误分类样本的示例。“Error” 显示了错误分类的样本,而 “Ref.” 显示了视觉上与错误样本相似但属于误分类类别的图像。Pred:模型预测的类别;GT:真实类别。
Table
表
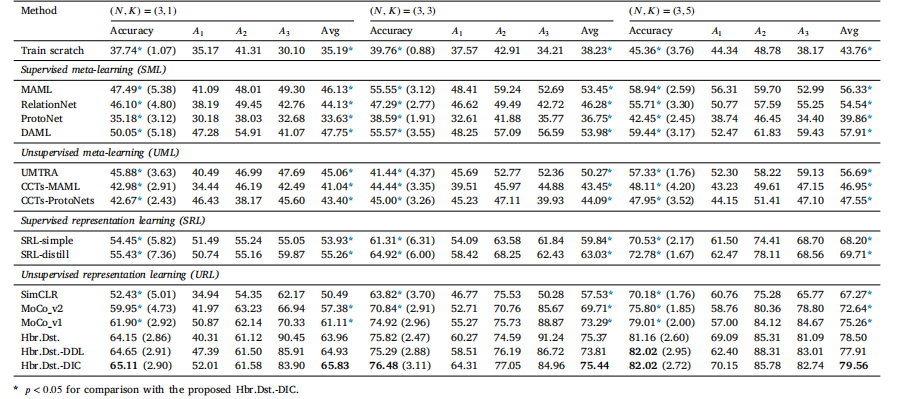
Table 1Evaluation results (in %) and comparison with SOTA FSL methods on the ISIC dataset (ResNet-12 backbone). Standard deviation of the accuracy is parenthesized. 𝐴1 , 𝐴2 , and 𝐴3correspond to dermatofibroma, actinic keratosis, and vascular lesion, respectively
表 1 在 ISIC 数据集上与最新少样本学习 (FSL) 方法的评估结果(以 % 表示)和比较(ResNet-12 主干网络)。准确率的标准差用括号表示。𝐴1、𝐴2 和 𝐴3 分别对应皮肤纤维瘤、日光性角化病和血管病变。
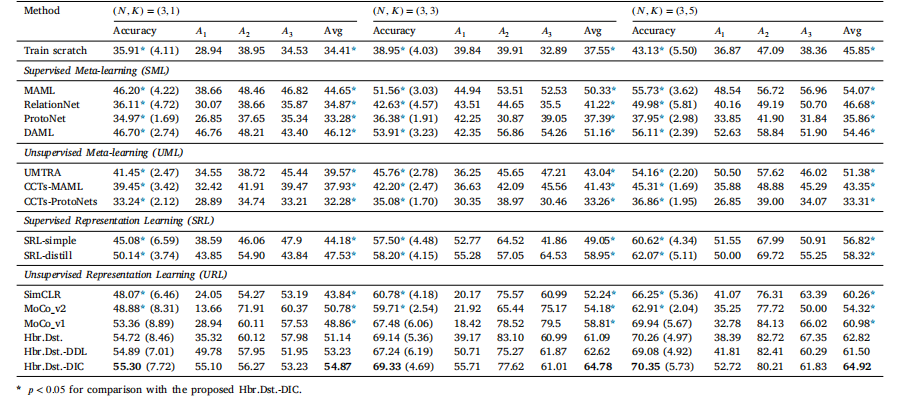
Table 2Evaluation results (in %) and comparison with SOTA FSL methods on the ISIC dataset (the 4-conv-block backbone). Standard deviation of the accuracy is parethesized. 𝐴1 , 𝐴2 ,and 𝐴3 correspond to dermatofibroma, actinic keratosis, and vascular lesion, respectively
表 2 在 ISIC 数据集上与最新少样本学习 (FSL) 方法的评估结果(以 % 表示)和比较(4 个卷积块主干网络)。准确率的标准差用括号表示。𝐴1、𝐴2 和 𝐴3 分别对应皮肤纤维瘤、日光性角化病和血管病变。
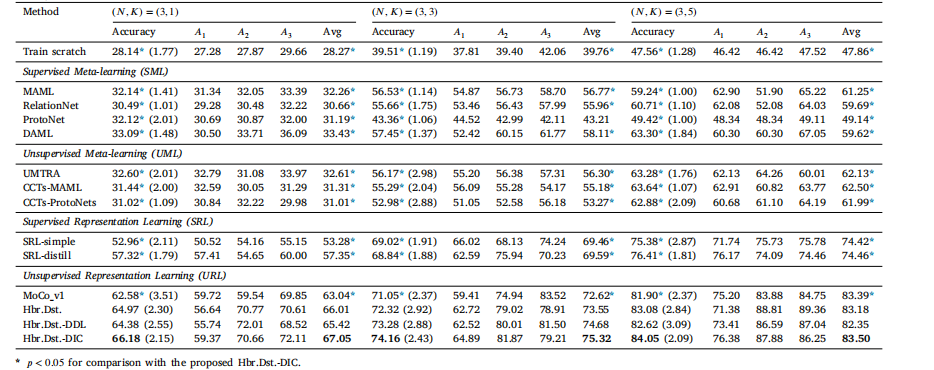
Table 3Evaluation results (in %) and comparison with SOTA FSL methods on the Pap-smear dataset (ResNet-12 backbone). Standard deviation of the accuracy is parenthesized. 𝐴1 , 𝐴2 ,and 𝐴3 correspond to columnar epithelial, superficial squamous epithelial, and intermediate squamous epithelial, respectively.
表 3 在宫颈涂片数据集上与最新少样本学习 (FSL) 方法的评估结果(以 % 表示)和比较(ResNet-12 主干网络)。准确率的标准差用括号表示。𝐴1、𝐴2 和 𝐴3 分别对应柱状上皮、表层鳞状上皮和中间鳞状上皮。
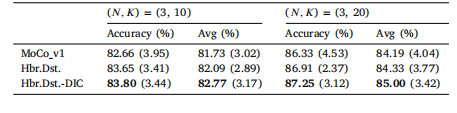
Table 4Evaluation results with more support data (i.e., larger 𝐾 values) on the ISIC dataset(ResNet-12 backbone). Format: mean (standard deviation).
表 4在 ISIC 数据集上使用更多支持数据(即更大的 𝐾 值)进行评估的结果(ResNet-12 主干网络)。格式:平均值(标准差)。

Table 5Evaluation results (in %) and comparison with SOTA FSL methods on the Pap-smear dataset (the 4-conv-block backbone). Standard deviation of the accuracy is parenthesized. 𝐴1 ,𝐴2 , and 𝐴3 correspond to columnar epithelial, superficial squamous epithelial, and intermediate squamous epithelial, respectively
表 5在宫颈涂片数据集上与最新少样本学习 (FSL) 方法的评估结果(以 % 表示)和比较(4 个卷积块主干网络)。准确率的标准差用括号表示。𝐴1、𝐴2 和 𝐴3 分别对应柱状上皮、表层鳞状上皮和中间鳞状上皮。
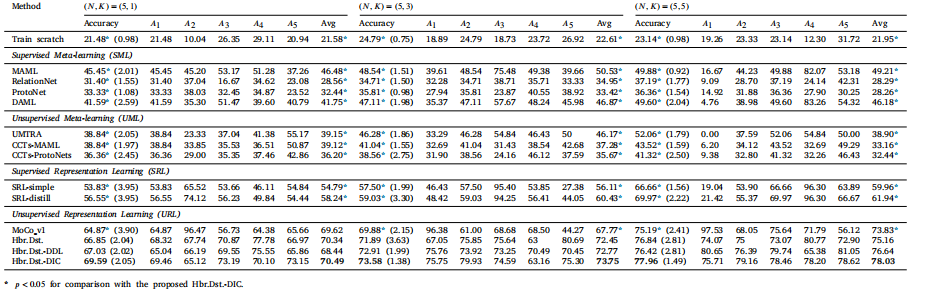
Table 6Evaluation results (in %) and comparison with SOTA FSL methods on the OCT dataset (ResNet-12 backbone). Standard deviation of the accuracy is parenthesized. 𝐴1–𝐴5 correspondto central serous chorioretinopathy, macular telangiectasia, macular hole, Stargardt disease, and retinitis pigmentosa, respectively
表 6在 OCT 数据集上与最新少样本学习 (FSL) 方法的评估结果(以 % 表示)和比较(ResNet-12 主干网络)。准确率的标准差用括号表示。𝐴1–𝐴5 分别对应中心性浆液性脉络膜视网膜病变、黄斑毛细血管扩张症、黄斑裂孔、Stargardt 病和视网膜色素变性。

Table 7Ablation study on different components of the proposed method (with ResNet-12 backbone and adaptive hard labels on the ISIC dataset). Format: mean (standard deviation).
表 7关于所提出方法不同组件的消融研究(在 ISIC 数据集上使用 ResNet-12 主干网络和自适应硬标签)。格式:平均值(标准差)。

Table 8Performance comparison of alternative strategies of applying the distilled student model (with the ResNet-12 backbone and adaptive hard labels) on the ISIC dataset. ‘‘Direct’’means directly using the student model 𝐹 ′ = 𝑓𝑐 ′ (𝑓𝑞 ′ ), and ‘‘LR’’ means replacing 𝑓**𝑐 ′ with a logistic regression classifier fit to the support set. Format: mean (standard deviation).
表 8在 ISIC 数据集上应用蒸馏学生模型的不同策略的性能比较(ResNet-12 主干网络和自适应硬标签)。“直接”指直接使用学生模型 𝐹 ′ = 𝑓𝑐 ′ (𝑓𝑞 ′ ),“LR”指用拟合支持集的逻辑回归分类器替换 𝑓**𝑐 ′。格式:平均值(标准差)。

Table 9Performance comparison with different choices of the pseudo labels on the ISIC dataset (based on Hbr.Dst.-DIC with the ResNet-12 backbone).Format: mean (standard deviation).
表 9在 ISIC 数据集上不同伪标签选择的性能比较(基于 Hbr.Dst.-DIC,使用 ResNet-12 主干网络)。格式:平均值(标准差)。
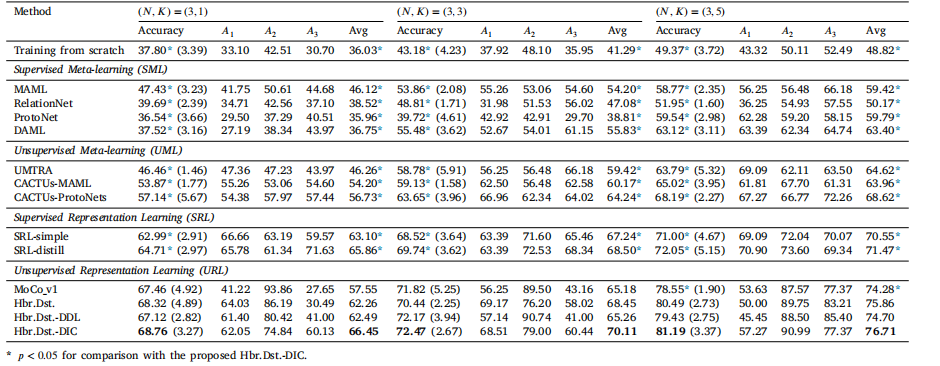
Table 10Evaluation results (in %) and comparison with SOTA FSL methods on the ISIC dataset with SENet (Hu et al., 2018) as the backbone. Standard deviation of the accuracy isparenthesized. 𝐴1 , 𝐴2 , and 𝐴3 correspond to dermatofibroma, actinic keratosis, and vascular lesion, respectively.
表 10在 ISIC 数据集上使用 SENet (Hu 等, 2018) 作为主干网络的评估结果(以 % 表示)和与最新少样本学习 (FSL) 方法的比较。准确率的标准差用括号表示。𝐴1、𝐴2 和 𝐴3 分别对应皮肤纤维瘤、日光性角化病和血管病变。
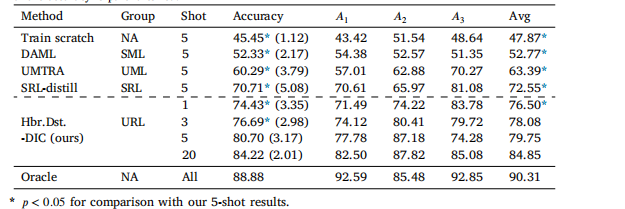
Table 11Performance (in %) comparison with the Oracle model (i.e., trained with hundreds of rare disease samples)on the ISIC dataset (ResNet-12 backbone). The best-performing method in each genre of FSL methods (SML:supervised meta-learning; UML: unsupervised meta-learning; SRL: supervised representation learning; andURL: unsupervised representation learning) is included, too (NA: not applicable). Note that our 1-shot resultsare superior to the 5-shot results of others, so we do not include their lower-shot results. Standard deviationof the accuracy is parenthesized.
表 11在 ISIC 数据集上与 Oracle 模型(即,使用数百个稀有疾病样本训练的模型)的性能比较(以 % 表示,ResNet-12 主干网络)。表中也包含每类 FSL 方法(SML:有监督元学习;UML:无监督元学习;SRL:有监督表示学习;URL:无监督表示学习)中表现最好的方法(NA:不适用)。请注意,我们的 1-shot 结果优于其他方法的 5-shot 结果,因此未包含其他方法的较低 shot 结果。准确率的标准差用括号表示。