小北的字节跳动青训营与LangChain系统安装和快速入门学习(持续更新中~~~)
前言
最近,字节跳动的青训营再次扬帆起航,作为第二次参与其中的小北,深感荣幸能借此机会为那些尚未了解青训营的友友们带来一些详细介绍。青训营不仅是一个技术学习与成长的摇篮,更是一个连接未来与梦想的桥梁~
 小北的青训营 X MarsCode 技术训练营——AI 加码,字节跳动青训营入营考核解答(持续更新中~~~)-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/143384787?sharetype=blogdetail&sharerId=143384787&sharerefer=PC&sharesource=Zhiyilang&spm=1011.2480.3001.8118
小北的青训营 X MarsCode 技术训练营——AI 加码,字节跳动青训营入营考核解答(持续更新中~~~)-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/143384787?sharetype=blogdetail&sharerId=143384787&sharerefer=PC&sharesource=Zhiyilang&spm=1011.2480.3001.8118![]() https://blog.csdn.net/Zhiyilang/article/details/143384787?sharetype=blogdetail&sharerId=143384787&sharerefer=PC&sharesource=Zhiyilang&spm=1011.2480.3001.8118
https://blog.csdn.net/Zhiyilang/article/details/143384787?sharetype=blogdetail&sharerId=143384787&sharerefer=PC&sharesource=Zhiyilang&spm=1011.2480.3001.8118
小北的字节跳动青训营与 LangChain 实战课:探索 AI 技术的新边界(持续更新中~~~)-CSDN博客https://blog.csdn.net/Zhiyilang/article/details/143454165?spm=1001.2014.3001.5502 https://blog.csdn.net/Zhiyilang/article/details/143454165?spm=1001.2014.3001.5502哈喽哈喽,这里是是zyll~,北浊.欢迎来到小北的 LangChain 实战课学习笔记!
https://blog.csdn.net/Zhiyilang/article/details/143454165?spm=1001.2014.3001.5502哈喽哈喽,这里是是zyll~,北浊.欢迎来到小北的 LangChain 实战课学习笔记!
在这个充满变革的时代,技术的每一次进步都在推动着世界的快速发展。字节跳动的青训营,作为技术人才培养的重要平台,再次扬帆起航,为怀揣梦想的技术爱好者们提供了一个学习和成长的摇篮。作为青训营的一员,小北深感荣幸能够借此机会,为大家详细介绍青训营的精彩内容,并分享 LangChain 实战课的学习心得,希望能够帮助大家更好地理解和应用最前沿的 AI 技术。
在我们开始正式的学习之前,先做一些基本知识储备。虽然大语言模型的使用非常简单,但是如果我们通过API来进行应用开发,那么还是有些基础知识应该先了解了解,比如什么是大模型,怎么安装LangChain,OpenAI的API有哪些类型,以及常用的开源大模型从哪里下载等等。
大语言模型解析与LangChain应用入门
在当今的人工智能领域,大语言模型(Large Language Model, LLM)无疑是最热门的技术之一。本文将深入探讨大语言模型的基本原理,并介绍如何利用LangChain这一强大的工具来开发基于大语言模型的应用。
什么是大语言模型?
大语言模型是一种利用深度学习技术,特别是神经网络,来理解和生成人类语言的模型。这些模型的“大”主要体现在其参数数量上,通常可达数十亿甚至更多。这种庞大的参数规模使得大语言模型能够捕捉并生成高度复杂的语言模式。
大语言模型的工作原理可以类比为一个巨大的预测机器。在训练过程中,模型会接收大量的文本数据,并尝试预测给定文本序列的下一个词。通过不断地学习和调整参数,模型能够逐渐掌握语言中的词语和词组用法、含义以及它们如何组合形成意义。这种预测能力不仅基于词语的统计关系,还包括对上下文的理解,有时甚至能体现出对世界常识的认知。
然而,需要注意的是,大语言模型并不具备人类的情感、意识或真正的理解力。它们只是通过复杂的数学函数学习到的语言模式,因此有时可能会犯错误或生成不合理的内容。
LangChain简介
LangChain是一个全方位的、基于大语言模型预测能力的应用开发工具。它提供了灵活性和模块化特性,使得处理语言模型变得极其简便。无论你是新手还是经验丰富的开发者,都可以利用LangChain流畅地调用语言模型,并基于其预测或推理能力开发新的应用。
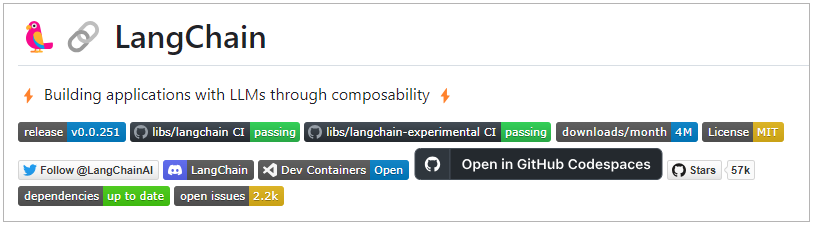
LangChain的预构建链功能就像乐高积木一样,允许你选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain还提供了模块化组件,允许你根据自己的需求定制和创建应用中的功能链条。
安装LangChain
LangChain的基本安装特别简单。
pip install langchain
这是安装 LangChain 的最低要求。这里我要提醒你一点,LangChain 要与各种模型、数据存储库集成,比如说最重要的OpenAI的API接口,比如说开源大模型库HuggingFace Hub,再比如说对各种向量数据库的支持。默认情况下,是没有同时安装所需的依赖项。
也就是说,当你 pip install langchain 之后,可能还需要 pip install openai、pip install chroma(一种向量数据库)……
用下面两种方法,我们就可以在安装 LangChain 的方法时,引入大多数的依赖项。
安装LangChain时包括常用的开源LLM(大语言模型) 库:
pip install langchain[llms]
安装完成之后,还需要更新到 LangChain 的最新版本,这样才能使用较新的工具。
pip install --upgrade langchain
如果你想从源代码安装,可以克隆存储库并运行:
pip install --upgrade langchain
小北个人觉得非常好的学习渠道也在这儿分享给友友们。
LangChain的学习资源
LangChain的GitHub社区非常活跃,你可以在这里找到大量的教程和最佳实践,也可以与其他开发者分享自己的经验和观点。此外,LangChain还提供了详尽的API文档,这是你在遇到问题时的重要参考。
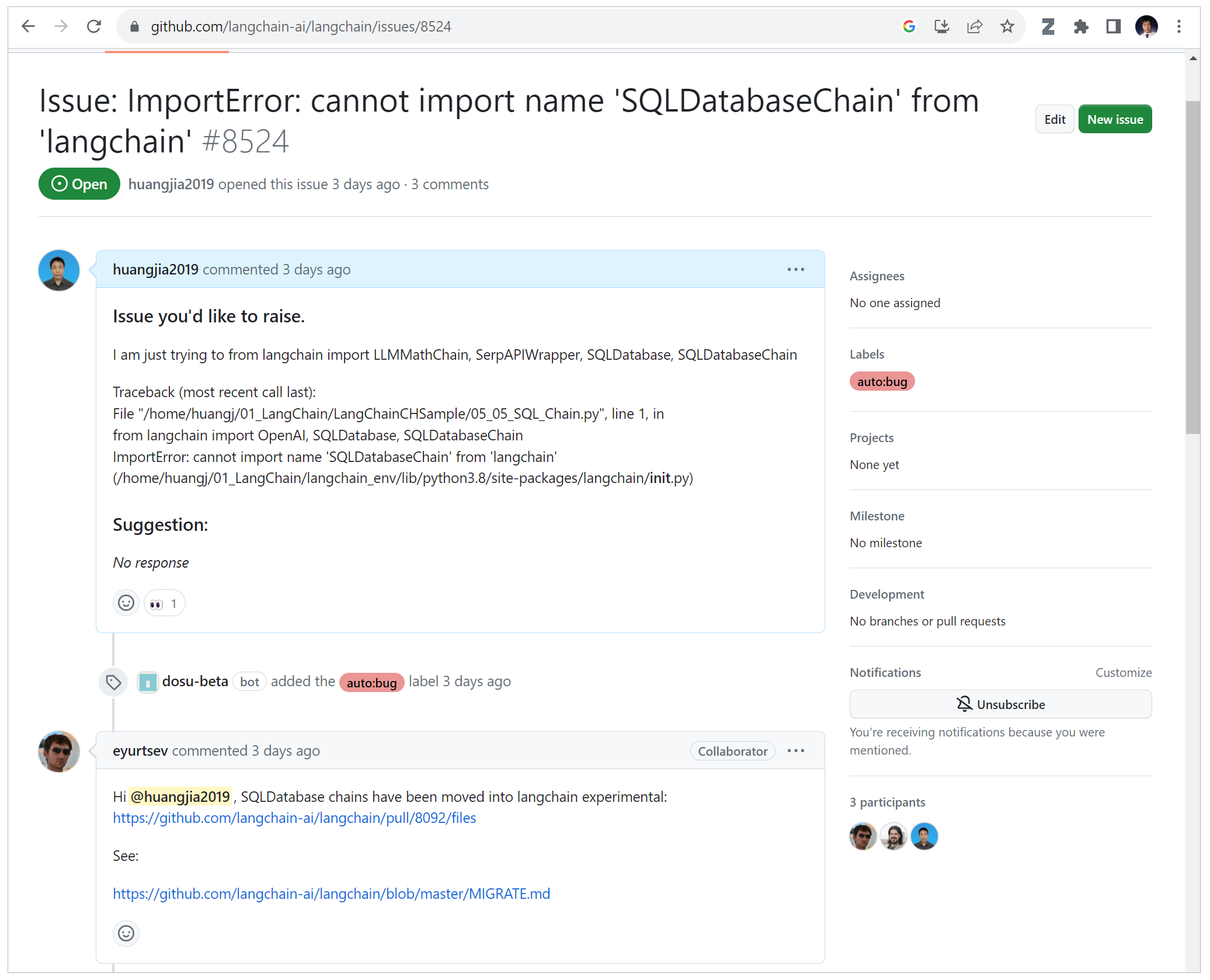
跟着LangChain其快速的更新步伐,你就能在这个领域取得显著的进步。
由于LangChain相对较新,有时你可能会发现文档中存在一些错误。在这种情况下,你可以考虑更新你的版本,或者在官方平台上提交一个问题反馈。通常,在LangChain的GitHub上开一个Issue,很快就可以得到解答。
OpenAI API简介
下面小北想说一说OpenAI的API。
关于ChatGPT和GPT-4,我想就没有必要赘言了,网上已经有太多资料了。但是要继续咱们的LangChain实战课,你需要对OpenAI的API有进一步的了解。因为,LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些API,搭建起来的一些框架、模块和接口。
因此,要了解LangChain的底层逻辑,需要了解大模型的API的基本设计思路。而目前接口最完备的、同时也是最强大的大语言模型,当然是OpenAI提供的GPT家族模型。
当然,要使用OpenAI API,你需要先用科学的方法进行注册,并得到一个API Key。
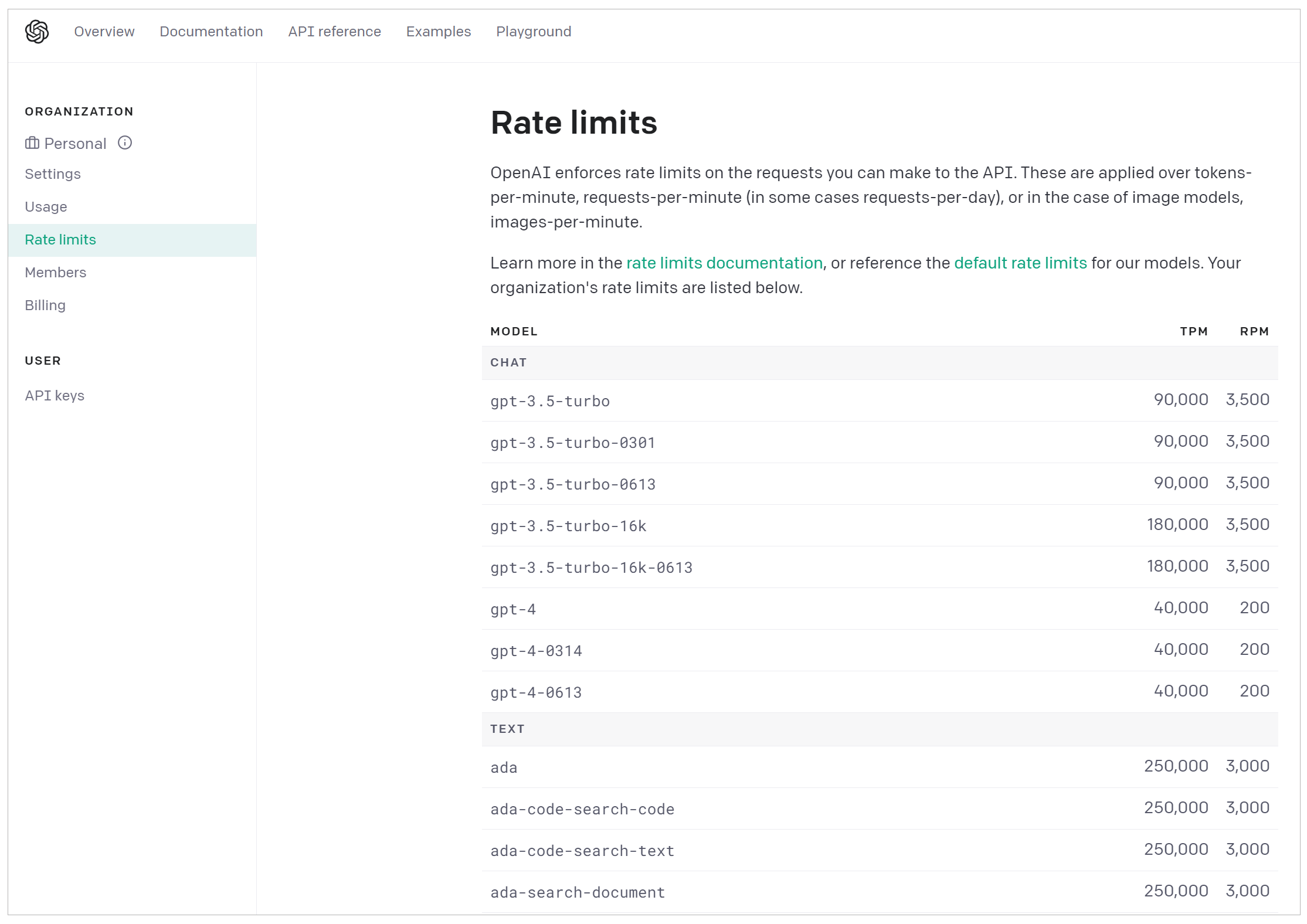
这里,我们需要重点说明的两类模型,就是图中的Chat Model和Text Model。这两类Model,是大语言模型的代表。当然,OpenAI还提供Image、Audio和其它类型的模型,目前它们不是LangChain所支持的重点,模型数量也比较少。
-
Chat Model,聊天模型,用于产生人类和AI之间的对话,代表模型当然是gpt-3.5-turbo(也就是ChatGPT)和GPT-4。当然,OpenAI还提供其它的版本,gpt-3.5-turbo-0613代表ChatGPT在2023年6月13号的一个快照,而gpt-3.5-turbo-16k则代表这个模型可以接收16K长度的Token,而不是通常的4K。(注意了,gpt-3.5-turbo-16k并未开放给我们使用,而且你传输的字节越多,花钱也越多)
-
Text Model,文本模型,在ChatGPT出来之前,大家都使用这种模型的API来调用GPT-3,文本模型的代表作是text-davinci-003(基于GPT3)。而在这个模型家族中,也有专门训练出来做文本嵌入的text-embedding-ada-002,也有专门做相似度比较的模型,如text-similarity-curie-001。
上面这两种模型,提供的功能类似,都是接收对话输入(input,也叫prompt),返回回答文本(output,也叫response)。但是,它们的调用方式和要求的输入格式是有区别的,这个我们等下还会进一步说明。
下面我们用简单的代码段说明上述两种模型的调用方式。先看比较原始的Text模型(GPT3.5之前的版本)。
调用 Text 模型
第1步,先注册好你的API Key。
第2步,用 pip install openai 命令来安装OpenAI库。
pip install openai第3步,导入 OpenAI API Key。
导入API Key有多种方式,其中之一是通过下面的代码:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
当然,这种把Key直接放在代码里面的方法最不可取,因为你一不小心共享了代码,密钥就被别人看到了,他就可以使用你的GPT-4资源!所以,建议你给自己的OpenAI账户设个上限,比如每月10美元啥的。
所以更好的方法是在操作系统中定义环境变量,比如在Linux系统的命令行中使用:
export OPENAI_API_KEY='你的Open API Key'
或者,你也可以考虑把环境变量保存在.env文件中,使用python-dotenv库从文件中读取它,这样也可以降低API密钥暴露在代码中的风险。第4步,导入OpenAI库,并创建一个Client。
from openai import OpenAI
client = OpenAI()
第5步,指定 gpt-3.5-turbo-instruct(也就是 Text 模型)并调用 completions 方法,返回结果。
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
temperature=0.5,
max_tokens=100,
prompt="请给我的花店起个名")
在使用OpenAI的文本生成模型时,你可以通过一些参数来控制输出的内容和样式。这里我总结为了一些常见的参数。

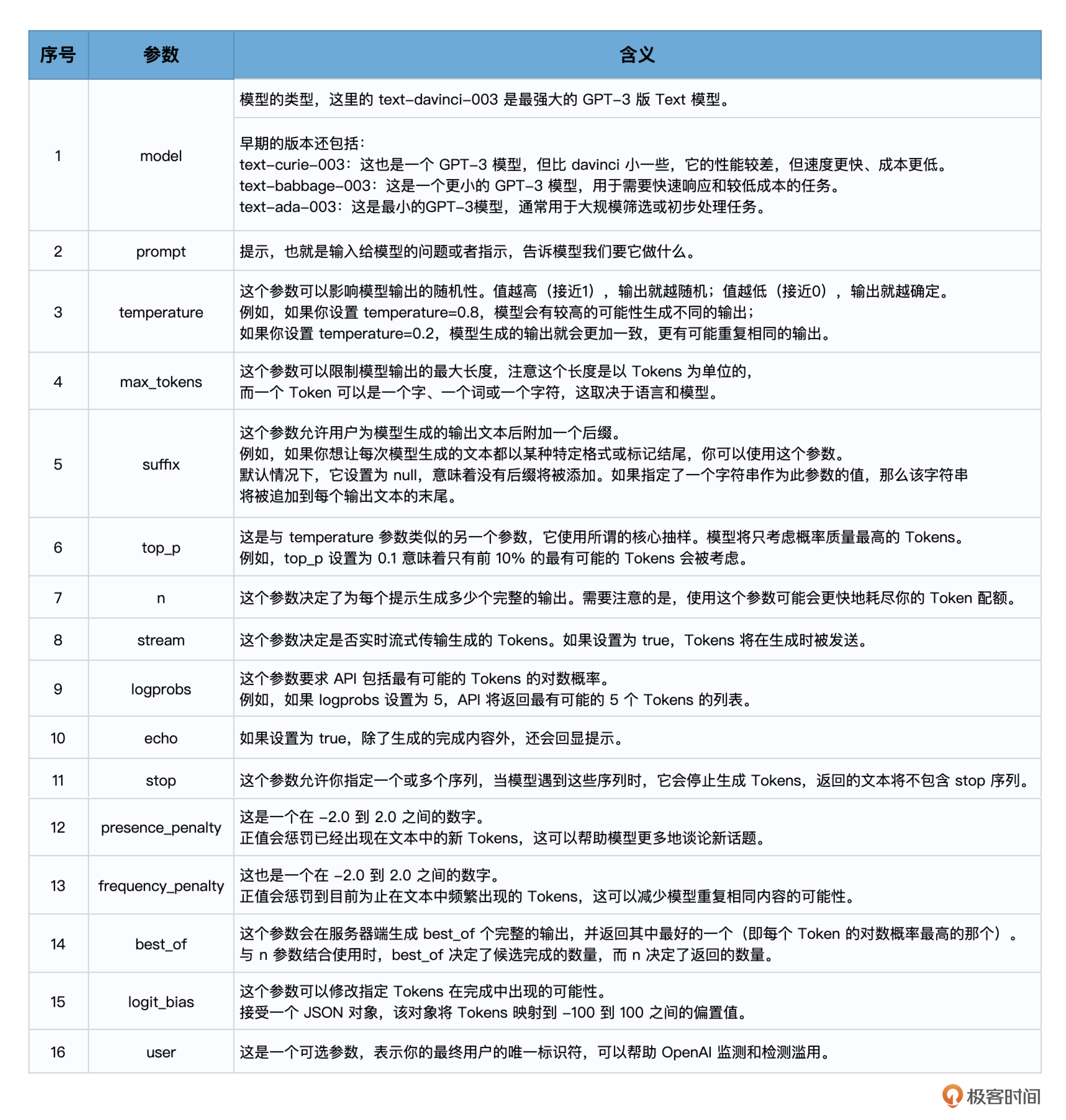
第6步,打印输出大模型返回的文字。
print(response.choices[0].text.strip())
当你调用OpenAI的Completion.create方法时,它会返回一个响应对象,该对象包含了模型生成的输出和其他一些信息。这个响应对象是一个字典结构,包含了多个字段。
在使用Text模型(如text-davinci-003)的情况下,响应对象的主要字段包括:

choices字段是一个列表,因为在某些情况下,你可以要求模型生成多个可能的输出。每个选择都是一个字典,其中包含以下字段:
- text:模型生成的文本。
- finish_reason:模型停止生成的原因,可能的值包括 stop(遇到了停止标记)、length(达到了最大长度)或 temperature(根据设定的温度参数决定停止)。
所以,response.choices[0].text.strip() 这行代码的含义是:从响应中获取第一个(如果在调用大模型时,没有指定n参数,那么就只有唯一的一个响应)选择,然后获取该选择的文本,并移除其前后的空白字符。这通常是你想要的模型的输出。至此,任务完成,模型的输出如下:
心动花庄、芳华花楼、轩辕花舍、簇烂花街、满园春色
不错。下面,让我们再来调用Chat模型(GPT-3.5和GPT-4)。
调用 Chat 模型
整体流程上,Chat模型和Text模型的调用是类似的,只是前面加了一个chat,然后输入(prompt)和输出(response)的数据格式有所不同。示例代码如下:
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a creative AI."},
{"role": "user", "content": "请给我的花店起个名"},
],
temperature=0.8,
max_tokens=60
)
这段代码中,除去刚才已经介绍过的temperature、max_tokens等参数之外,有两个专属于Chat模型的概念,一个是消息,一个是角色!
先说消息,消息就是传入模型的提示。此处的messages参数是一个列表,包含了多个消息。每个消息都有一个role(可以是system、user或assistant)和content(消息的内容)。系统消息设定了对话的背景(你是一个很棒的智能助手),然后用户消息提出了具体请求(请给我的花店起个名)。模型的任务是基于这些消息来生成回复。
再说角色,在OpenAI的Chat模型中,system、user和assistant都是消息的角色。每一种角色都有不同的含义和作用。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的AI助手。系统消息通常在对话开始时给出。
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用API发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
在使用Chat模型生成内容后,返回的响应,也就是response会包含一个或多个choices,每个choices都包含一个message。每个message也都包含一个role和content。role可以是system、user或assistant,表示该消息的发送者,content则包含了消息的实际内容。一个典型的response对象可能如下所示:
{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}
以下是各个字段的含义:
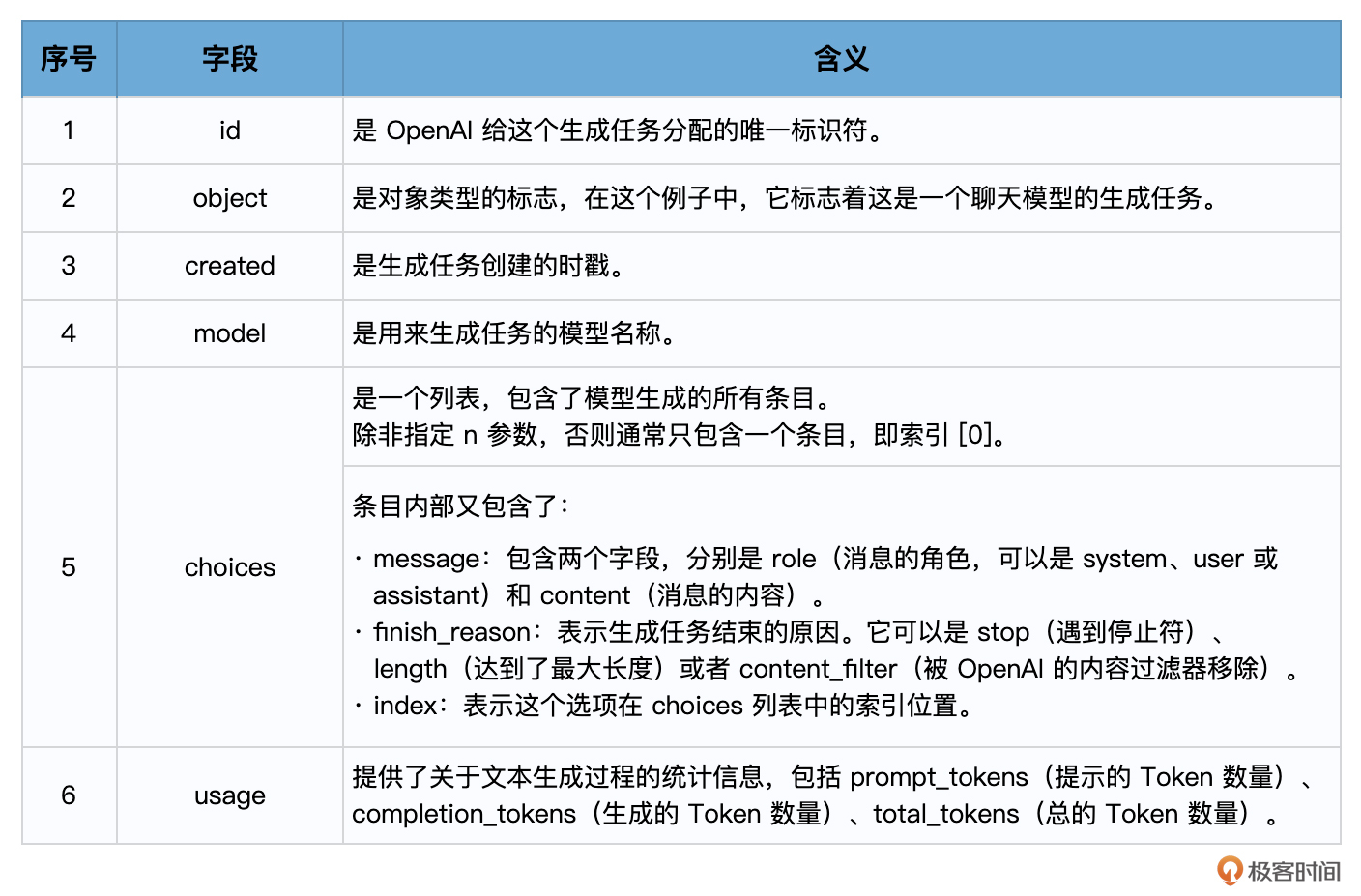
这就是response的基本结构,其实它和Text模型返回的响应结构也是很相似,只是choices字段中的Text换成了Message。你可以通过解析这个对象来获取你需要的信息。例如,要获取模型的回复,可使用 response['choices'][0]['message']['content']。
Chat模型 vs Text模型
Chat模型和Text模型都有各自的优点,其适用性取决于具体的应用场景。
相较于Text模型,Chat模型的设计更适合处理对话或者多轮次交互的情况。这是因为它可以接受一个消息列表作为输入,而不仅仅是一个字符串。这个消息列表可以包含system、user和assistant的历史信息,从而在处理交互式对话时提供更多的上下文信息。
这种设计的主要优点包括:
- 对话历史的管理:通过使用Chat模型,你可以更方便地管理对话的历史,并在需要时向模型提供这些历史信息。例如,你可以将过去的用户输入和模型的回复都包含在消息列表中,这样模型在生成新的回复时就可以考虑到这些历史信息。
- 角色模拟:通过system角色,你可以设定对话的背景,给模型提供额外的指导信息,从而更好地控制输出的结果。当然在Text模型中,你在提示中也可以为AI设定角色,作为输入的一部分。
然而,对于简单的单轮文本生成任务,使用Text模型可能会更简单、更直接。例如,如果你只需要模型根据一个简单的提示生成一段文本,那么Text模型可能更适合。从上面的结果看,Chat模型给我们输出的文本更完善,是一句完整的话,而Text模型输出的是几个名字。这是因为ChatGPT经过了对齐(基于人类反馈的强化学习),输出的答案更像是真实聊天场景。
好了,我们对OpenAI的API调用,理解到这个程度就可以了。毕竟我们主要是通过LangChain这个高级封装的框架来访问Open AI。
通过 LangChain 调用 Text 和 Chat 模型
最后,让我们来使用LangChain来调用OpenAI的Text和Chat模型,完成了这两个任务,我们今天的课程就可以结束了!
调用 Text 模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.llms import OpenAI
llm = OpenAI(
model="gpt-3.5-turbo-instruct",
temperature=0.8,
max_tokens=60,)
response = llm.predict("请给我的花店起个名")
print(response)
输出:
花之缘、芳华花店、花语心意、花风旖旎、芳草世界、芳色年华
 这只是一个对OpenAI API的简单封装:先导入LangChain的OpenAI类,创建一个LLM(大语言模型)对象,指定使用的模型和一些生成参数。使用创建的LLM对象和消息列表调用OpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。没有什么需要特别解释之处。
这只是一个对OpenAI API的简单封装:先导入LangChain的OpenAI类,创建一个LLM(大语言模型)对象,指定使用的模型和一些生成参数。使用创建的LLM对象和消息列表调用OpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。没有什么需要特别解释之处。
调用 Chat 模型
代码如下:
import os
os.environ["OPENAI_API_KEY"] = '你的Open API Key'
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model="gpt-4",
temperature=0.8,
max_tokens=60)
from langchain.schema import (
HumanMessage,
SystemMessage
)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="请给我的花店起个名")
]
response = chat(messages)
print(response)
这段代码也不难理解,主要是通过导入LangChain的ChatOpenAI类,创建一个Chat模型对象,指定使用的模型和一些生成参数。然后从LangChain的schema模块中导入LangChain的SystemMessage和HumanMessage类,创建一个消息列表。消息列表中包含了一个系统消息和一个人类消息。你已经知道系统消息通常用来设置一些上下文或者指导AI的行为,人类消息则是要求AI回应的内容。之后,使用创建的chat对象和消息列表调用ChatOpenAI类的__call__方法,进行文本生成。生成的结果被存储在response变量中。输出:
content='当然可以,叫做"花语秘境"怎么样?'
additional_kwargs={} example=False
 从响应内容“当然可以,叫做‘花语秘境’怎么样?”不难看出,GPT-4的创造力真的是胜过GPT-3,她给了我们这么有意境的一个店名,比我自己起的“易速鲜花”好多了。
从响应内容“当然可以,叫做‘花语秘境’怎么样?”不难看出,GPT-4的创造力真的是胜过GPT-3,她给了我们这么有意境的一个店名,比我自己起的“易速鲜花”好多了。
另外,无论是langchain.llms中的OpenAI(Text模型),还是langchain.chat_models中的ChatOpenAI中的ChatOpenAI(Chat模型),其返回的结果response变量的结构,都比直接调用OpenAI API来得简单一些。这是因为,LangChain已经对大语言模型的output进行了解析,只保留了响应中最重要的文字部分。
总结时刻
好了,今天课程的内容不少,我希望你理解OpenAI从Text模型到Chat模型的进化,以及什么时候你会选用Chat模型,什么时候会选用Text模型。另外就是这两种模型的最基本调用流程,掌握了这些内容,我们就可以继续后面的学习。
另外,大语言模型可不是OpenAI一家独大,知名的大模型开源社群HugginFace网站上面提供了很多开源模型供你尝试使用。就在我写这节课的时候,Meta的Llama-2最受热捧,而且通义千问(Qwen)则刚刚开源。这些趋势,你点击下面的图片就看得到。
两点提醒,一是这个领域进展太快,当你学这门课程的时候,流行的开源模型肯定变成别的了;二是这些新的开源模型,LangChain还不一定提供很好的接口,因此通过LangChain来使用最新的开源模型可能不容易。
不过LangChain作为最流行的LLM框架,新的开源模型被封装进来是迟早的事情。而且,LangChain的框架也已经定型,各个组件的设计都基本固定了。
思考题
最后给你留几个有难度的思考题,有些题目你可能现在没有答案,但是我希望你带着这些问题去继续学习后续课程。
从今天的两个例子看起来,使用LangChain并不比直接调用OpenAI API来得省事?而且也仍然需要OpenAI API才能调用GPT家族模型。那么LangChain的核心价值在哪里?至少从这两个示例中没看出来。针对这个问题,你仔细思考思考。
提示:这个问题没有标准答案,仁者见仁智者见智,等学完了课程,我们可以再回过头来回答一次。
LangChain支持的可绝不只有OpenAI模型,那么你能否试一试HuggingFace开源社区中的其它模型,看看能不能用。
提示:你要选择Text-Generation、Text-Text Generation和Question-Answer这一类的文本生成式模型。
from langchain import HuggingFaceHub
llm = HuggingFaceHub(model_id="bigscience/bloom-1b7")
上面我提到了生成式模型,那么,大语言模型除了文本生成式模型,还有哪些类别的模型?比如说有名的Bert模型,是不是文本生成式的模型?
提示:如果你没有太多NLP基础知识,建议你可以看一下专栏《零基础实战机器学习》和公开课《ChatGPT和预训练模型实战课》。
期待在留言区看到你的思考,如果你觉得内容对你有帮助,也欢迎分享给有需要的朋友!最后如果你学有余力,可以进一步学习下面的延伸阅读。
延伸阅读
- LangChain官方文档(Python版)(JavaScript版),这是你学习专栏的过程中,有任何疑惑都可以随时去探索的知识大本营。xiao'bei个人觉得,目前LangChain的文档还不够体系化,有些杂乱,讲解也不大清楚。但是,这是官方文档,会维护得越来越好。
- OpenAI API 官方文档,深入学习OpenAI API的地方。
- HuggingFace 官方网站,玩开源大模型的好地方。